WRIT: Write-Read Intensive Trajectory Synthesis for Multi-Turn User-Facing Agents
Pith reviewed 2026-06-28 14:16 UTC · model grok-4.3
The pith
WRIT synthesizes trajectories stressing both write count and evidence burden so a 4B model beats GPT-5.1 no-think on multi-turn agent benchmarks with 2K examples and lower token use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
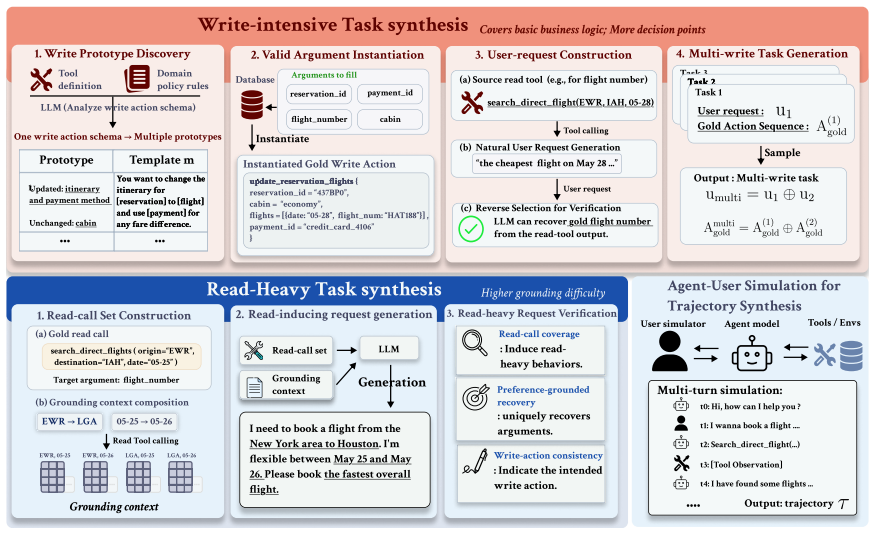
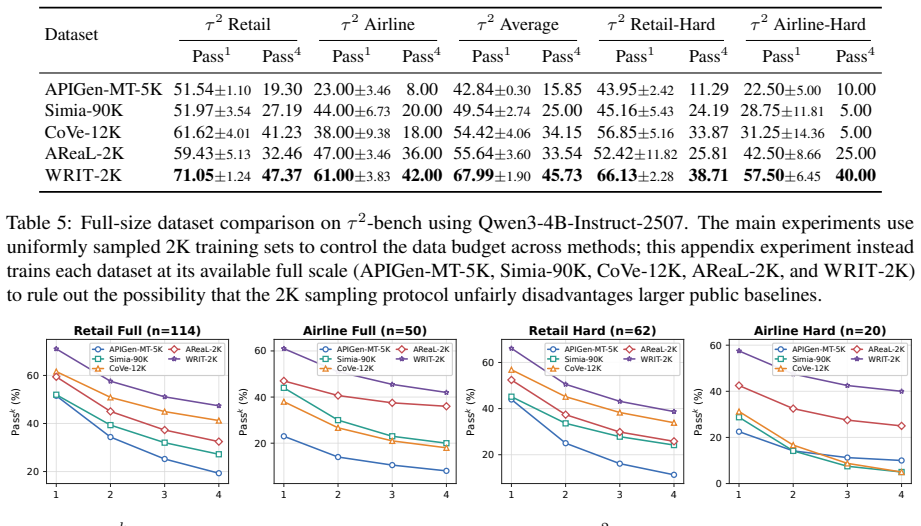
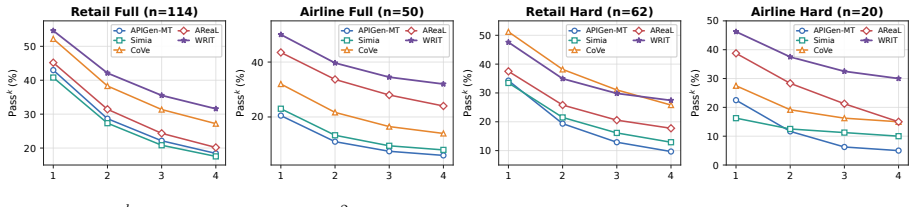
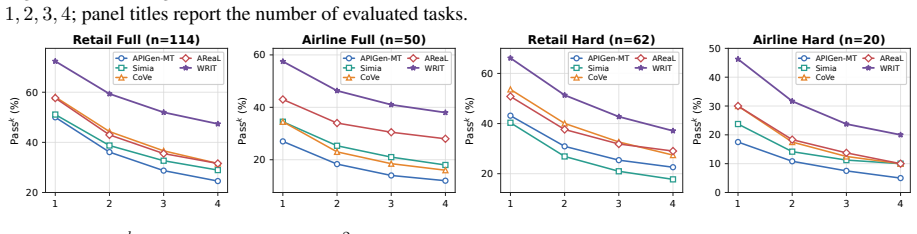
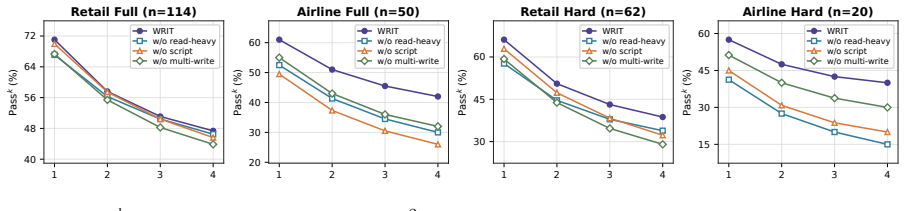
WRIT first creates write-intensive and read-heavy tasks, then diversifies user behavior instructions, and finally simulates agent-user interactions in an executable environment to yield complete training trajectories. The resulting data trains agents for both longer sequential execution and robust decision making under high information load. A 4B model trained on only 2K such trajectories outperforms GPT-5.1 no-think on τ²-bench while substantially reducing inference-time token usage.
What carries the argument
WRIT pipeline that generates tasks along two axes (write-decision count and per-decision evidence burden), diversifies instructions, and simulates interactions to produce trajectories.
If this is right
- Agents learn to gather and compare substantial read-tool evidence before committing to write arguments.
- Compact supervised fine-tuning data can encode part of what would otherwise require expensive test-time reasoning.
- Inference token consumption drops because evidence-grounded decisions become internalized behavior.
- Performance gains appear on benchmarks that test multi-turn intent inference and tool use under incomplete information.
Where Pith is reading between the lines
- The same two-axis synthesis could be applied to single-turn agents if read burden is isolated as the dominant variable.
- Domains with high-stakes decisions under partial information, such as medical or legal assistants, might benefit from analogous read-write balancing.
- If simulation fidelity is high, the approach points toward cheaper data pipelines that reduce dependence on frontier-model test-time compute for agent deployment.
Load-bearing premise
The simulated agent-user interactions produce trajectories whose distribution matches real user behavior and tool responses sufficiently for performance gains to transfer.
What would settle it
If a 4B model trained on WRIT trajectories fails to outperform the GPT-5.1 no-think baseline when evaluated on a held-out collection of real human multi-turn dialogues, the transfer claim does not hold.
Figures
read the original abstract
Multi-turn user-facing agents must infer user intent from incomplete requests, collect missing information through dialogue and tools, and execute valid actions. A training trajectory records this process as an interleaved sequence of user messages, agent responses, tool calls, etc. Synthesizing sufficiently complex trajectory has become a central route to train agents: existing pipelines often increase difficulty by composing multiple user requests into longer tasks, producing write-intensive trajectories that train sequential execution. We argue that a single write decision can itself be difficult when the agent must gather and compare substantial read-tool evidence before its arguments become identifiable, a challenge that write-intensive data alone cannot address. Guided by this insight, we propose WRIT (\uline{W}rite-\uline{R}ead \uline{I}ntensive \uline{T}rajectory Synthesis), a pipeline for synthesizing multi-turn agent training trajectories along two complexity axes: the number of write decisions in a task and the evidence burden of each individual decision. WRIT first generates write-intensive and read-heavy tasks. It then diversifies user behavior instructions to reflect realistic conversational variation, and finally simulates agent-user interactions in an executable environment to produce complete training trajectories. The resulting data trains agents not only for longer task execution, but also for robust, evidence-grounded decision making under high information load. With only 2K synthesized trajectories, a 4B model trained on WRIT outperforms GPT-5.1 no-think on $\tau^2$-bench and substantially reduces inference-time token usage, showing that compact SFT data can convert part of expensive test-time reasoning into efficient agent behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes WRIT, a pipeline to synthesize multi-turn agent trajectories along two axes: number of write decisions and evidence burden per decision. It generates write-intensive and read-heavy tasks, diversifies user behavior instructions, and simulates complete agent-user interactions in an executable environment to produce training data. The central claim is that fine-tuning a 4B model on only 2K such trajectories yields better performance than GPT-5.1 no-think on τ²-bench while reducing inference-time token usage.
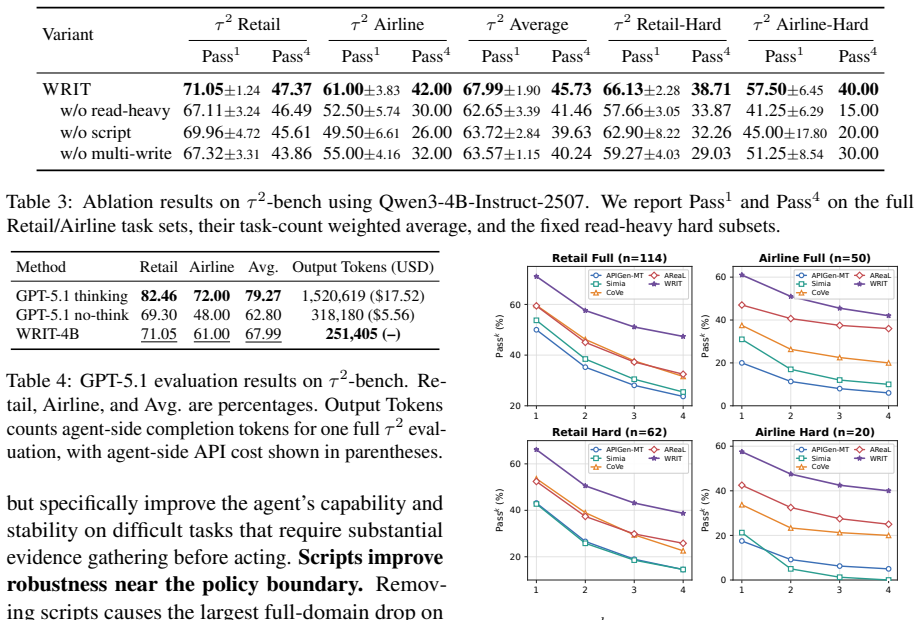
Significance. If the empirical result holds after proper validation, the work would show that compact, targeted SFT data can convert expensive test-time reasoning into efficient learned behavior for evidence-grounded multi-turn agents, offering a practical route to improve agent performance without scaling model size or inference compute.
major comments (2)
- [Abstract] Abstract: the performance claim that a 4B model trained on 2K WRIT trajectories outperforms GPT-5.1 no-think on τ²-bench is presented with no experimental details, baseline comparisons, statistical tests, run counts, or description of how τ²-bench was executed, so the central empirical result cannot be evaluated.
- [WRIT pipeline description] WRIT pipeline (final simulation step): the headline result requires that simulated trajectories reproduce the joint distribution of user intents, repairs, and tool responses in τ²-bench, yet no calibration against real logs, sampling from observed distributions, or matching of trajectory statistics (turn length, tool-call entropy) is reported; this assumption is load-bearing for transfer.
minor comments (1)
- [Abstract] The underlining used for the WRIT acronym expansion may not render reliably across formats; consider standard emphasis.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We respond to each major point below, indicating planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claim that a 4B model trained on 2K WRIT trajectories outperforms GPT-5.1 no-think on τ²-bench is presented with no experimental details, baseline comparisons, statistical tests, run counts, or description of how τ²-bench was executed, so the central empirical result cannot be evaluated.
Authors: We agree that the abstract presents the headline result concisely and omits the supporting experimental details. The full description of the evaluation protocol, including how τ²-bench was executed, all baselines, run counts, and statistical tests, appears in Section 4 and Appendix C. We will revise the abstract to include a brief clause referencing the evaluation setup so readers can locate the supporting evidence immediately. revision: yes
-
Referee: [WRIT pipeline description] WRIT pipeline (final simulation step): the headline result requires that simulated trajectories reproduce the joint distribution of user intents, repairs, and tool responses in τ²-bench, yet no calibration against real logs, sampling from observed distributions, or matching of trajectory statistics (turn length, tool-call entropy) is reported; this assumption is load-bearing for transfer.
Authors: The final simulation step generates trajectories inside an executable environment whose task structure is defined by the same write-decision and evidence-burden axes used to create the benchmark tasks. While we did not report explicit calibration to external user logs or quantitative matching of statistics such as tool-call entropy, the generation procedure is intentionally aligned with τ²-bench requirements. We will add a short limitations paragraph in Section 3.3 discussing this design choice and its implications for transfer. revision: partial
Circularity Check
No circularity: empirical synthesis and benchmarking pipeline is self-contained
full rationale
The paper describes a data-generation pipeline (task generation, instruction diversification, environment simulation) followed by SFT and external benchmarking on τ²-bench. No equations, fitted parameters, or self-citations are invoked to derive the headline performance numbers; the 2K-trajectory result is an observed training outcome, not a quantity forced by construction from the synthesis steps themselves. The distributional-match assumption is an unvalidated modeling choice but does not create a definitional or self-referential reduction inside the reported claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthesizing trajectories with controlled complexity improves downstream agent performance on benchmarks
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
arXiv preprint arXiv:2511.01824 , year=
Simulating Environments with Reasoning Models for Agent Training , author=. arXiv preprint arXiv:2511.01824 , year=
-
[3]
arXiv preprint arXiv:2603.01940 , year=
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification , author=. arXiv preprint arXiv:2603.01940 , year=
-
[4]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. arXiv preprint arXiv:2506.07982 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Effective Red-Teaming of Policy-Adherent Agents , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=. 2025 , publisher=
2025
-
[6]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents , author=. arXiv preprint arXiv:2601.20144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pages=
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding , author=. Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP , pages=. 2018 , doi=
2018
-
[9]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
SQuAD: 100,000+ Questions for Machine Comprehension of Text , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=. 2016 , doi=
2016
-
[10]
arXiv preprint arXiv:2507.22034 , year=
UserBench: An Interactive Gym Environment for User-Centric Agents , author=. arXiv preprint arXiv:2507.22034 , year=
-
[11]
Zhao, Weikang and Wang, Xili and Ma, Chengdi and Kong, Lingbin and Yang, Zhaohua and Tuo, Mingxiang and Shi, Xiaowei and Zhai, Yitao and Cai, Xunliang , journal=
-
[12]
Qin, Tian and Bai, Felix and Hu, Ting-Yao and Vemulapalli, Raviteja and Koppula, Hema Swetha and Xu, Zhiyang and Jin, Bowen and Cemri, Mert and Lu, Jiarui and Wang, Zirui and Cao, Meng , journal=
-
[13]
Beyond Itinerary Planning-A Real-World Benchmark for Multi-Turn and Tool-Using Travel Tasks
Beyond Itinerary Planning: A Real-World Benchmark for Multi-Turn and Tool-Using Travel Tasks , author=. arXiv preprint arXiv:2512.22673 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2510.18170 , year=
AgentChangeBench: A Multi-Dimensional Evaluation Framework for Goal-Shift Robustness in Conversational AI , author=. arXiv preprint arXiv:2510.18170 , year=
-
[15]
Xu, Zhangchen and Soria, Adriana Meza and Tan, Shawn and Roy, Anurag and Agrawal, Ashish Sunil and Poovendran, Radha and Panda, Rameswar , journal=
-
[16]
Zeng, Xingshan and Liu, Weiwen and Wang, Lingzhi and Li, Liangyou and Mi, Fei and Wang, Yasheng and Shang, Lifeng and Jiang, Xin and Liu, Qun , journal=
-
[17]
Wang, Zhenting and Chang, Qi and Patel, Hemani and Biju, Shashank and Wu, Cheng-En and Liu, Quan and Ding, Aolin and Rezazadeh, Alireza and Shah, Ankit and Bao, Yujia and Siow, Eugene , journal=
-
[18]
Burdisso, Sergio and Baroudi, S. arXiv preprint arXiv:2506.10622 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
arXiv preprint arXiv:2504.04736 , year=
Synthetic Data Generation and Multi-Step Reinforcement Learning for Reasoning and Tool Use , author=. arXiv preprint arXiv:2504.04736 , year=
-
[20]
arXiv preprint arXiv:2601.22607 , year=
From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents , author=. arXiv preprint arXiv:2601.22607 , year=
-
[21]
Multi-Turn Reinforcement Learning for Tool-Calling Agents with Iterative Reward Calibration
Multi-Turn Reinforcement Learning for Tool-Calling Agents with Iterative Reward Calibration , author=. arXiv preprint arXiv:2604.02869 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Lu, Jiarui and Holleis, Thomas and Zhang, Yizhe and Aumayer, Bernhard and Nan, Feng and Bai, Felix and Ma, Shuang and Ma, Shen and Li, Mengyu and Yin, Guoli and Wang, Zirui and Pang, Ruoming , journal=
-
[23]
and Kapanipathi, Pavan , journal=
Basu, Kinjal and Abdelaziz, Ibrahim and Kate, Kiran and Agarwal, Mayank and Crouse, Maxwell and Rizk, Yara and Bradford, Kelsey and Munawar, Asim and Kumaravel, Sadhana and Goyal, Saurabh and Wang, Xin and Lastras, Luis A. and Kapanipathi, Pavan , journal=
-
[24]
Chen, Chen and Hao, Xinlong and Liu, Weiwen and Huang, Xu and Zeng, Xingshan and Yu, Shuai and Li, Dexun and Wang, Shuai and Gan, Weinan and Huang, Yuefeng and Liu, Wulong and Wang, Xinzhi and Lian, Defu and Yin, Baoqun and Wang, Yasheng and Liu, Wu , journal=
-
[25]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[27]
arXiv preprint arXiv:2509.13311 , year=
Towards General Agentic Intelligence via Environment Scaling , author=. arXiv preprint arXiv:2509.13311 , year=
-
[28]
Gorilla: Large Language Model Connected with Massive APIs
Gorilla: Large Language Model Connected with Massive APIs , author=. arXiv preprint arXiv:2305.15334 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Li, Minghao and Song, Feifan and Yu, Bowen and Yu, Haiyang and Li, Zhoujun and Huang, Fei and Li, Yongbin , booktitle=
-
[30]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle=
-
[31]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year=
Budzianowski, Pawe. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , year=
2018
-
[32]
Proceedings of the AAAI Conference on Artificial Intelligence , year=
Towards Scalable Multi-Domain Conversational Agents: The Schema-Guided Dialogue Dataset , author=. Proceedings of the AAAI Conference on Artificial Intelligence , year=
-
[33]
Taskmaster-1: Toward a realistic and diverse dialog dataset , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[34]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Identifying the Risks of LM Agents with an LM-Emulated Sandbox , author=. arXiv preprint arXiv:2309.15817 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents , author=. arXiv preprint arXiv:2412.14470 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases , author=. arXiv preprint arXiv:2306.05301 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2407.03502 , year=
Agentinstruct: Toward generative teaching with agentic flows , author=. arXiv preprint arXiv:2407.03502 , year=
-
[38]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , address=. 2024 , url=
2024
-
[42]
International Conference on Learning Representations , volume=
Webarena: A realistic web environment for building autonomous agents , author=. International Conference on Learning Representations , volume=
-
[43]
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yao and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , journal=
-
[44]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Workarena: How capable are web agents at solving common knowledge work tasks? , author=. arXiv preprint arXiv:2403.07718 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Appworld: A controllable world of apps and people for benchmarking interactive coding agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , journal=
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , journal=
-
[47]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal=
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal=
-
[48]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
Multi-trait User Simulation with Adaptive Decoding for Conversational Task Assistants , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
2024
-
[49]
Simulating User Diversity in Task-Oriented Dialogue Systems using Large Language Models , author=. arXiv preprint arXiv:2502.12813 , year=
-
[50]
Computer Speech & Language , volume=
Prompting Large Language Models for User Simulation in Task-Oriented Dialogue Systems , author=. Computer Speech & Language , volume=. 2025 , publisher=
2025
-
[51]
IEEE Transactions on Computational Social Systems , volume=
Are Current Task-Oriented Dialogue Systems Able to Satisfy Impolite Users? , author=. IEEE Transactions on Computational Social Systems , volume=. 2025 , doi=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.