BEAST3D: Animal behavioral analysis and neural encoding from multi-view video via Gaussian splatting
Pith reviewed 2026-06-28 11:22 UTC · model grok-4.3
The pith
BEAST3D learns viewpoint-invariant 3D features from unlabeled multi-view animal videos by predicting Gaussian splats that reconstruct held-out views and transfers them to pose estimation and neural encoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
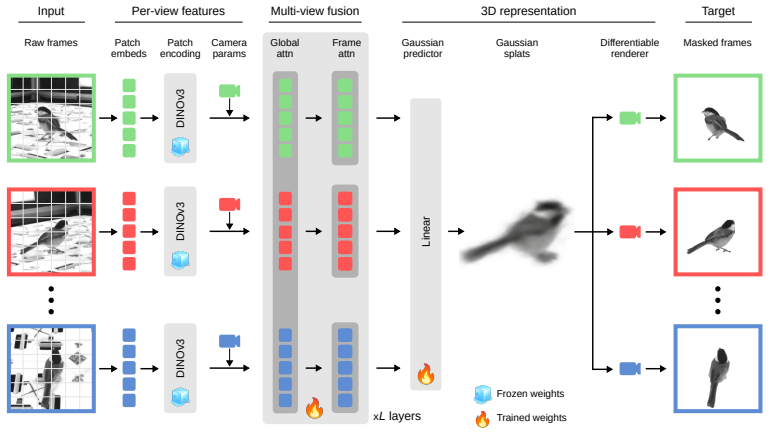
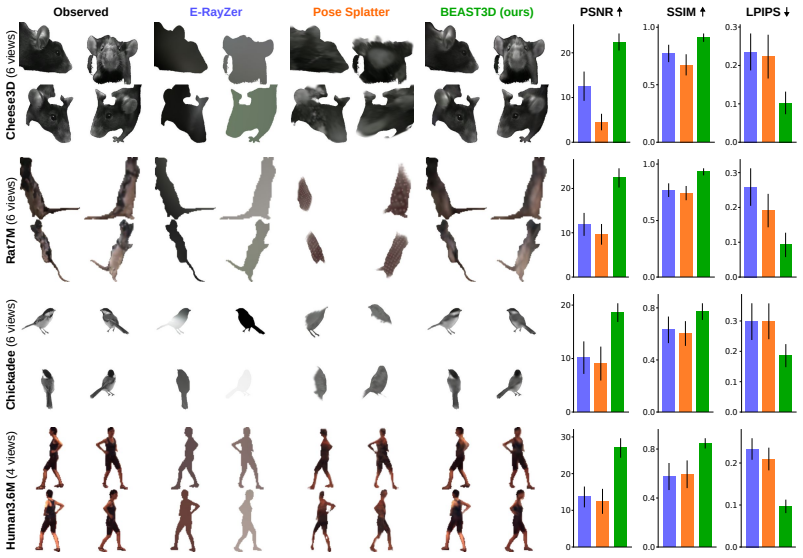
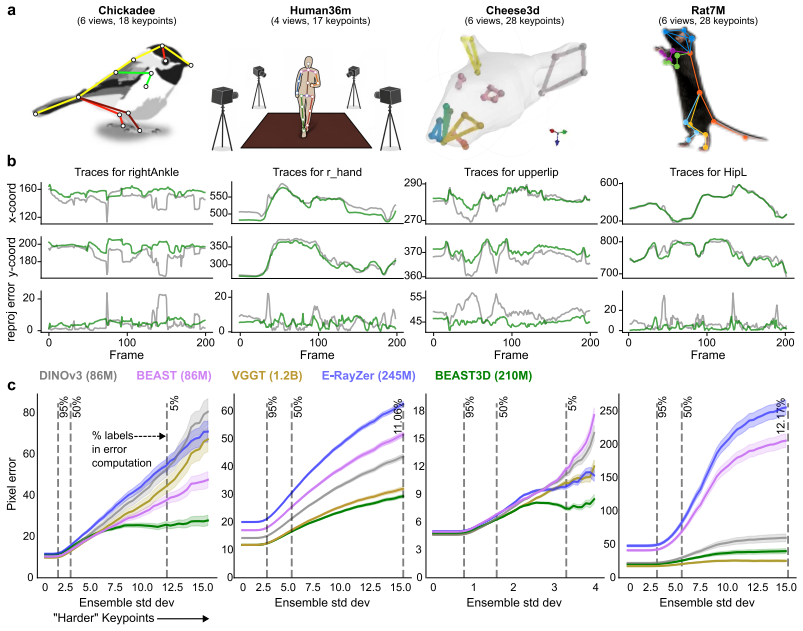
BEAST3D is a self-supervised pretraining framework that learns 3D visual representations from unlabeled, calibrated multi-view video by using a vision transformer to predict 3D Gaussian splats that reconstruct held-out views through differentiable rendering while simultaneously segmenting the animal from the background. It reconstructs 3D structure with as few as four views by conditioning directly on known camera parameters. Comprehensive evaluation across four species demonstrates that BEAST3D produces rich, viewpoint-invariant features that transfer effectively to novel view synthesis, multi-view pose estimation, and neural encoding.
What carries the argument
Vision transformer that predicts 3D Gaussian splats conditioned on known camera parameters and rendered differentiably to reconstruct held-out views while segmenting the animal.
If this is right
- Novel view synthesis becomes possible from sparse calibrated laboratory camera setups without dense overlap.
- Multi-view pose estimation yields sparse keypoint trajectories for behavioral analysis without manual annotation.
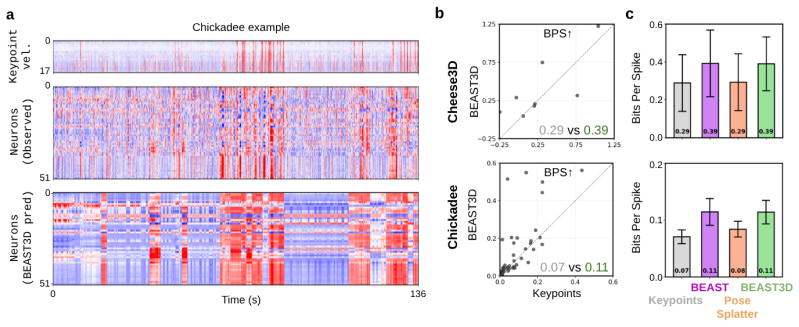
- Neural encoding can relate 3D behavioral features extracted from video directly to simultaneously recorded activity.
- The same pretrained model supports all three tasks after a single self-supervised stage on unlabeled data.
- The method applies across multiple animal species using the same training procedure.
Where Pith is reading between the lines
- The segmentation component may allow the features to remain stable in cluttered or changing lab backgrounds not present in training.
- If camera parameters are available, the same pretraining could be applied to other biological motion capture settings beyond the four species tested.
- Viewpoint invariance might permit combining data from different rig geometries without retraining the encoder.
- The approach could be tested for transfer to additional downstream tasks such as action classification or social interaction analysis.
Load-bearing premise
Features learned only by reconstructing held-out views will automatically carry information useful for predicting neural activity from 3D behavior.
What would settle it
On the neural encoding task, features from BEAST3D yield no higher prediction accuracy than features from a 2D image model or random vectors when tested on held-out sessions across the four species.
Figures

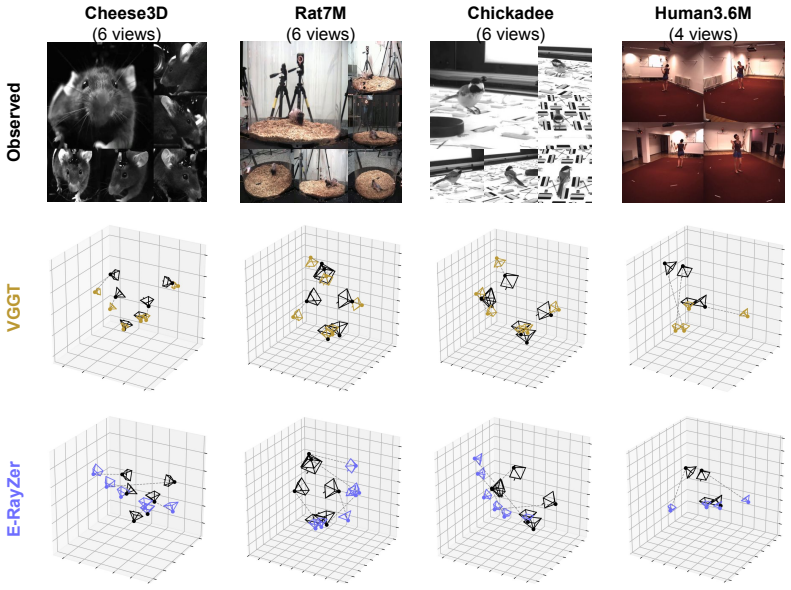
read the original abstract
Multi-view video recordings are increasingly used to capture the 3D movements of animals in experimental settings, yet extracting rich 3D representations from these recordings remains challenging. Supervised pose estimation requires extensive manual annotation, while general-purpose 3D reconstruction models trained on generic scene datasets fail on the specialized imagery and sparse-view setting of laboratory experiments. We address these limitations with BEAST3D, a self-supervised pretraining framework that learns 3D visual representations from unlabeled, calibrated multi-view video. BEAST3D uses a vision transformer to predict 3D Gaussian splats that reconstruct held-out views through differentiable rendering, while simultaneously segmenting the animal from the background. BEAST3D reconstructs 3D structure with as few as four views by conditioning directly on known camera parameters--unlike general-purpose models, which must estimate camera geometry from dense overlapping viewpoints that are seldom available in lab settings. Through comprehensive evaluation across four species, we demonstrate that BEAST3D produces rich, viewpoint-invariant features that transfer effectively to three downstream tasks: novel view synthesis, which validates the quality of the learned 3D representations; multi-view pose estimation, which provides the sparse keypoint trajectories widely used in behavioral analysis; and neural encoding, which relates 3D behavioral features to simultaneously recorded neural activity. BEAST3D thus establishes a versatile framework for behavioral analysis that leverages 3D structure in modern multi-view laboratory recordings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BEAST3D, a self-supervised framework that employs a vision transformer to predict 3D Gaussian splats from calibrated multi-view animal videos. The model reconstructs held-out views via differentiable rendering while segmenting the animal from the background, conditioning directly on known camera parameters. The central claim is that the resulting viewpoint-invariant features transfer effectively to three downstream tasks—novel view synthesis, multi-view pose estimation, and neural encoding—across four species, providing a versatile tool for behavioral analysis and relating 3D behavior to neural activity.
Significance. If the transfer claims are quantitatively validated, the approach could supply a practical pretraining strategy for 3D representations in sparse-view laboratory recordings where general-purpose models fail and annotations are costly. The explicit use of camera calibration for few-view reconstruction is a domain-appropriate strength. However, the absence of any reported metrics, baselines, or mechanistic details for the neural-encoding transfer leaves the broadest claim unsupported at present.
major comments (2)
- [Abstract] Abstract: The statement that BEAST3D 'produces rich, viewpoint-invariant features that transfer effectively' to neural encoding (and the other two tasks) across four species supplies no quantitative metrics, baselines, error bars, ablation results, or cross-validation details. This directly undermines assessment of the central versatility claim.
- [Abstract] Abstract / downstream-tasks paragraph: No mechanism is described for mapping the learned representations (raw splat parameters, ViT embeddings, or derived 3D keypoints) to neural data, nor is the neural modality (spikes, LFP, etc.), loss function, or metric (e.g., R², decoding accuracy) specified. Novel-view synthesis tests the reconstruction objective directly, but neural encoding requires an additional, unvalidated mapping.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the recommendation of major revision. The comments focus on the abstract's presentation of the versatility claim. We address each point below and will revise the abstract accordingly to improve self-containment while preserving its summary nature. The main text already contains the supporting evaluations, metrics, and methodological details for all tasks.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that BEAST3D 'produces rich, viewpoint-invariant features that transfer effectively' to neural encoding (and the other two tasks) across four species supplies no quantitative metrics, baselines, error bars, ablation results, or cross-validation details. This directly undermines assessment of the central versatility claim.
Authors: We agree that the abstract, due to length constraints, omits specific quantitative metrics and does not itself supply baselines or error bars. The main manuscript reports these details for novel-view synthesis and pose estimation (including baseline comparisons and cross-validation across the four species) and provides corresponding results for neural encoding. In revision we will add a concise clause to the abstract summarizing the key performance metrics that support the transfer claims. revision: yes
-
Referee: [Abstract] Abstract / downstream-tasks paragraph: No mechanism is described for mapping the learned representations (raw splat parameters, ViT embeddings, or derived 3D keypoints) to neural data, nor is the neural modality (spikes, LFP, etc.), loss function, or metric (e.g., R², decoding accuracy) specified. Novel-view synthesis tests the reconstruction objective directly, but neural encoding requires an additional, unvalidated mapping.
Authors: The abstract paragraph is intentionally high-level. The full manuscript describes the mapping (ViT embeddings of the predicted splats to neural recordings), the modality, the regression approach, and the evaluation metric in the methods and results sections, with validation on held-out data. We will insert a brief parenthetical description of the mapping and metric into the downstream-tasks sentence of the abstract to make the claim more self-contained. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core pipeline is a self-supervised reconstruction objective (predicting 3D Gaussians to render held-out views) whose loss is independent of the downstream neural-encoding task. No equation or claim reduces the neural-encoding performance to the reconstruction loss by construction, nor does any load-bearing step rely on a self-citation chain that itself lacks external verification. Camera calibration is treated as an external input, and the three downstream tasks are evaluated separately. This matches the default expectation of a non-circular empirical pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Leaving flatland: Advances in 3d behavioral measurement.Current Opinion in Neurobiology, 73:102522, 2022
Jesse D Marshall, Tianqing Li, Joshua H Wu, and Timothy W Dunn. Leaving flatland: Advances in 3d behavioral measurement.Current Opinion in Neurobiology, 73:102522, 2022
2022
-
[2]
Continuous whole-body 3d kinematic recordings across the rodent behavioral repertoire.Neuron, 109(3):420–437, 2021
Jesse D Marshall, Diego E Aldarondo, Timothy W Dunn, William L Wang, Gordon J Berman, and Bence P Ölveczky. Continuous whole-body 3d kinematic recordings across the rodent behavioral repertoire.Neuron, 109(3):420–437, 2021
2021
-
[3]
Barcoding of episodic memories in the hippocampus of a food-caching bird.Cell, 187(8):1922–1935, 2024
Selmaan N Chettih, Emily L Mackevicius, Stephanie Hale, and Dmitriy Aronov. Barcoding of episodic memories in the hippocampus of a food-caching bird.Cell, 187(8):1922–1935, 2024
1922
-
[4]
Application of a novel deep learning–based 3d videography workflow to bat flight.Annals of the new York Academy of Sciences, 1536(1):92–106, 2024
Jonas Håkansson, Brooke L Quinn, Abigail L Shultz, Sharon M Swartz, and Aaron J Corcoran. Application of a novel deep learning–based 3d videography workflow to bat flight.Annals of the new York Academy of Sciences, 1536(1):92–106, 2024
2024
-
[5]
Mapping the landscape of social behavior.Cell, 188(8):2249–2266, 2025
Ugne Klibaite, Tianqing Li, Diego Aldarondo, Jumana F Akoad, Bence P Ölveczky, and Timothy W Dunn. Mapping the landscape of social behavior.Cell, 188(8):2249–2266, 2025
2025
-
[6]
High- resolution in vivo kinematic tracking with customized injectable fluorescent nanoparticles
Emine Zeynep Ulutas, Amartya Pradhan, Dorothy Koveal, and Jeffrey E Markowitz. High- resolution in vivo kinematic tracking with customized injectable fluorescent nanoparticles. Science Advances, 11(40):eadu9136, 2025
2025
-
[7]
Deepfly3d, a deep learning-based approach for 3d limb and appendage tracking in tethered, adult drosophila.Elife, 8:e48571, 2019
Semih Günel, Helge Rhodin, Daniel Morales, João Campagnolo, Pavan Ramdya, and Pascal Fua. Deepfly3d, a deep learning-based approach for 3d limb and appendage tracking in tethered, adult drosophila.Elife, 8:e48571, 2019
2019
-
[8]
Automated markerless pose estimation in freely moving macaques with openmonkeystudio.Nature communications, 11(1):4560, 2020
Praneet C Bala, Benjamin R Eisenreich, Seng Bum Michael Yoo, Benjamin Y Hayden, Hyun Soo Park, and Jan Zimmermann. Automated markerless pose estimation in freely moving macaques with openmonkeystudio.Nature communications, 11(1):4560, 2020
2020
-
[9]
Geometric deep learning enables 3d kinematic profiling across species and environments
Timothy W Dunn, Jesse D Marshall, Kyle S Severson, Diego E Aldarondo, David GC Hilde- brand, Selmaan N Chettih, William L Wang, Amanda J Gellis, David E Carlson, Dmitriy Aronov, et al. Geometric deep learning enables 3d kinematic profiling across species and environments. Nature methods, 18(5):564–573, 2021
2021
-
[10]
Anipose: A toolkit for robust markerless 3d pose estimation.Cell reports, 36(13), 2021
Pierre Karashchuk, Katie L Rupp, Evyn S Dickinson, Sarah Walling-Bell, Elischa Sanders, Eiman Azim, Bingni W Brunton, and John C Tuthill. Anipose: A toolkit for robust markerless 3d pose estimation.Cell reports, 36(13), 2021
2021
-
[11]
Estimation of skeletal kinematics in freely moving rodents.Nature methods, 19(11):1500–1509, 2022
Arne Monsees, Kay-Michael V oit, Damian J Wallace, Juergen Sawinski, Edyta Charyasz, Klaus Scheffler, Jakob H Macke, and Jason ND Kerr. Estimation of skeletal kinematics in freely moving rodents.Nature methods, 19(11):1500–1509, 2022
2022
-
[12]
Multi-animal 3d social pose estimation, identification and behaviour embedding with a few-shot learning framework.Nature machine intelligence, 6(1):48–61, 2024
Yaning Han, Ke Chen, Yunke Wang, Wenhao Liu, Zhouwei Wang, Xiaojing Wang, Chuanliang Han, Jiahui Liao, Kang Huang, Shengyuan Cai, et al. Multi-animal 3d social pose estimation, identification and behaviour embedding with a few-shot learning framework.Nature machine intelligence, 6(1):48–61, 2024
2024
-
[13]
A real-time, multi-subject three-dimensional pose tracking system for the behavioral analysis of non-human primates.Cell Reports Methods, 5(2), 2025
Chaoqun Cheng, Zijian Huang, Ruiming Zhang, Guozheng Huang, Han Wang, Likai Tang, and Xiaoqin Wang. A real-time, multi-subject three-dimensional pose tracking system for the behavioral analysis of non-human primates.Cell Reports Methods, 5(2), 2025
2025
-
[14]
Lightning pose 3d: an uncertainty-aware framework for data-efficient multi-view animal pose estimation.bioRxiv, pages 2026–04, 2026
Lenny Aharon, Matthew R Whiteway, Karan Sikka, Keemin Lee, Yanchen Wang, Selmaan Chettih, Benjamin Midler, Ilana B Witten, Dmitriy Aronov, International Brain Laboratory, et al. Lightning pose 3d: an uncertainty-aware framework for data-efficient multi-view animal pose estimation.bioRxiv, pages 2026–04, 2026
2026
-
[15]
3d menagerie: Modeling the 3d shape and pose of animals
Silvia Zuffi, Angjoo Kanazawa, David W Jacobs, and Michael J Black. 3d menagerie: Modeling the 3d shape and pose of animals. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6365–6373, 2017. 11
2017
-
[16]
3d bird reconstruction: a dataset, model, and shape recovery from a single view
Marc Badger, Yufu Wang, Adarsh Modh, Ammon Perkes, Nikos Kolotouros, Bernd G Pfrommer, Marc F Schmidt, and Kostas Daniilidis. 3d bird reconstruction: a dataset, model, and shape recovery from a single view. InEuropean conference on computer vision, pages 1–17. Springer, 2020
2020
-
[17]
Armo: An articulated mesh approach for mouse 3d reconstruction.bioRxiv, pages 2023–02, 2023
James P Bohnslav, Mohammed Abdal Monium Osman, Akshay Jaggi, Sofia Soares, Caleb Weinreb, Sandeep Robert Datta, and Christopher D Harvey. Armo: An articulated mesh approach for mouse 3d reconstruction.bioRxiv, pages 2023–02, 2023
2023
-
[18]
Cheese3d enables sensitive detection and analysis of whole-face movement in mice.Nature Neuroscience, pages 1–12, 2026
Kyle Daruwalla, Irene Nozal Martin, Linghua Zhang, Diana Nagliˇc, Andrew Frankel, Catherine Rasgaitis, Rubin Zhao, Xinyan Zhang, Zainab Ahmad, Jeremy C Borniger, et al. Cheese3d enables sensitive detection and analysis of whole-face movement in mice.Nature Neuroscience, pages 1–12, 2026
2026
-
[19]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.IEEE transactions on pattern analysis and machine intelligence, 36(7):1325–1339, 2013
2013
-
[20]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[21]
E-rayzer: Self-supervised 3d reconstruction as spatial visual pre-training
Qitao Zhao, Hao Tan, Qianqian Wang, Sai Bi, Kai Zhang, Kalyan Sunkavalli, Shubham Tulsiani, and Hanwen Jiang. E-rayzer: Self-supervised 3d reconstruction as spatial visual pre-training. arXiv preprint arXiv:2512.10950, 2025
-
[22]
Pose splatter: A 3d gaussian splatting model for quantifying animal pose and appearance
Jack Goffinet, Youngjo Min, Carlo Tomasi, and David Carlson. Pose splatter: A 3d gaussian splatting model for quantifying animal pose and appearance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[23]
Coarse-to-fine animal pose and shape estimation.Advances in Neural Information Processing Systems, 34:11757–11768, 2021
Chen Li and Gim Hee Lee. Coarse-to-fine animal pose and shape estimation.Advances in Neural Information Processing Systems, 34:11757–11768, 2021
2021
-
[24]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
2022
-
[26]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[27]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[28]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, George Drettakis, et al. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023. 12
2023
-
[31]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
2021
-
[32]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024
2024
-
[33]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean conference on computer vision, pages 370–386. Springer, 2024
2024
-
[34]
Gs-lrm: Large reconstruction model for 3d gaussian splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, and Zexiang Xu. Gs-lrm: Large reconstruction model for 3d gaussian splatting. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
2024
-
[35]
Rayzer: A self-supervised large view synthesis model
Hanwen Jiang, Hao Tan, Peng Wang, Haian Jin, Yue Zhao, Sai Bi, Kai Zhang, Fujun Luan, Kalyan Sunkavalli, Qixing Huang, et al. Rayzer: A self-supervised large view synthesis model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4918–4929, 2025
2025
-
[36]
Julius Plücker. Xvii. on a new geometry of space.Philosophical Transactions of the Royal Society of London, (155):725–791, 1865
-
[37]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024
2024
-
[39]
Selfee, self-supervised features extraction of animal behaviors.Elife, 11:e76218, 2022
Yinjun Jia, Shuaishuai Li, Xuan Guo, Bo Lei, Junqiang Hu, Xiao-Hong Xu, and Wei Zhang. Selfee, self-supervised features extraction of animal behaviors.Elife, 11:e76218, 2022
2022
-
[40]
Felix B Mueller, Timo Lueddecke, Richard V ogg, and Alexander S Ecker. Domain-adaptive pretraining improves primate behavior recognition.arXiv preprint arXiv:2509.12193, 2025
-
[41]
Animal-jepa: Advancing animal behavior studies through joint embedding predictive architecture in video analysis
Chengjie Zheng, Tewodros Mulugeta Dagnew, Liuyue Yang, Wei Ding, Shiqian Shen, Changn- ing Wang, and Ping Chen. Animal-jepa: Advancing animal behavior studies through joint embedding predictive architecture in video analysis. In2024 IEEE International Conference on Big Data (BigData), pages 1909–1918. IEEE, 2024
1909
-
[42]
Animal behavioral analysis and neural encoding with transformer-based self-supervised pretraining
Yanchen Wang, Han Yu, Ari Blau, Yizi Zhang, Liam Paninski, Cole Lincoln Hurwitz, Matthew R Whiteway, et al. Animal behavioral analysis and neural encoding with transformer-based self-supervised pretraining. InThe Fourteenth International Conference on Learning Represen- tations, 2026
2026
-
[43]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, et al. gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025
2025
-
[45]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Fsgs: Real-time few-shot view synthesis using gaussian splatting
Zehao Zhu, Zhiwen Fan, Yifan Jiang, and Zhangyang Wang. Fsgs: Real-time few-shot view synthesis using gaussian splatting. InEuropean conference on computer vision, pages 145–163. Springer, 2024. 13
2024
-
[47]
Chen Yang, Sikuang Li, Jiemin Fang, Ruofan Liang, Lingxi Xie, Xiaopeng Zhang, Wei Shen, and Qi Tian. Gaussianobject: High-quality 3d object reconstruction from four views with gaussian splatting.arXiv preprint arXiv:2402.10259, 2024
-
[48]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600– 612, 2004
2004
-
[49]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[50]
Computational neuroethology: a call to action.Neuron, 104(1):11–24, 2019
Sandeep Robert Datta, David J Anderson, Kristin Branson, Pietro Perona, and Andrew Leifer. Computational neuroethology: a call to action.Neuron, 104(1):11–24, 2019
2019
-
[51]
Quantifying behavior to understand the brain.Nature neuroscience, 23(12):1537–1549, 2020
Talmo D Pereira, Joshua W Shaevitz, and Mala Murthy. Quantifying behavior to understand the brain.Nature neuroscience, 23(12):1537–1549, 2020
2020
-
[52]
Using deeplabcut for 3d markerless pose estimation across species and behaviors.Nature protocols, 14(7):2152–2176, 2019
Tanmay Nath, Alexander Mathis, An Chi Chen, Amir Patel, Matthias Bethge, and Macken- zie Weygandt Mathis. Using deeplabcut for 3d markerless pose estimation across species and behaviors.Nature protocols, 14(7):2152–2176, 2019
2019
-
[53]
Lightning pose: improved animal pose estimation via semi-supervised learning, bayesian ensembling and cloud-native open-source tools.Nature methods, 21(7):1316–1328, 2024
Dan Biderman, Matthew R Whiteway, Cole Hurwitz, Nicholas Greenspan, Robert S Lee, Ankit Vishnubhotla, Richard Warren, Federico Pedraja, Dillon Noone, Michael M Schartner, et al. Lightning pose: improved animal pose estimation via semi-supervised learning, bayesian ensembling and cloud-native open-source tools.Nature methods, 21(7):1316–1328, 2024
2024
-
[54]
Single-trial neural dynamics are dominated by richly varied movements.Nature neuroscience, 22(10):1677–1686, 2019
Simon Musall, Matthew T Kaufman, Ashley L Juavinett, Steven Gluf, and Anne K Churchland. Single-trial neural dynamics are dominated by richly varied movements.Nature neuroscience, 22(10):1677–1686, 2019
2019
-
[55]
Spontaneous behaviors drive multidimensional, brainwide activity
Carsen Stringer, Marius Pachitariu, Nicholas Steinmetz, Charu Bai Reddy, Matteo Carandini, and Kenneth D Harris. Spontaneous behaviors drive multidimensional, brainwide activity. Science, 364(6437):eaav7893, 2019
2019
-
[56]
Brain-wide analysis reveals movement encoding structured across and within brain areas.Nature Neuroscience, 29(1):147–158, 2026
Ziyue Aiden Wang, Balint Kurgyis, Susu Chen, Byungwoo Kang, Feng Chen, Yi Liu, Dave Liu, Karel Svoboda, Nuo Li, and Shaul Druckmann. Brain-wide analysis reveals movement encoding structured across and within brain areas.Nature Neuroscience, 29(1):147–158, 2026
2026
-
[57]
Facemap: a framework for modeling neural activity based on orofacial tracking.Nature neuroscience, 27(1):187–195, 2024
Atika Syeda, Lin Zhong, Renee Tung, Will Long, Marius Pachitariu, and Carsen Stringer. Facemap: a framework for modeling neural activity based on orofacial tracking.Nature neuroscience, 27(1):187–195, 2024
2024
-
[58]
Reproducibility of in vivo electrophysiological measurements in mice.Elife, 13:RP100840, 2025
International Brain Laboratory, Kush Banga, Julius Benson, Jai Bhagat, Dan Biderman, Daniel Birman, Niccolò Bonacchi, Sebastian A Bruijns, Kelly Buchanan, Robert AA Campbell, et al. Reproducibility of in vivo electrophysiological measurements in mice.Elife, 13:RP100840, 2025
2025
-
[59]
A brain-wide map of neural activity during complex behaviour.Nature, 645(8079):177– 191, 2025
International Brain Laboratory, Dora Angelaki, Brandon Benson, Julius Benson, Daniel Birman, Niccolò Bonacchi, Kcénia Bougrova, Sebastian A Bruijns, Matteo Carandini, Joana A Catarino, et al. A brain-wide map of neural activity during complex behaviour.Nature, 645(8079):177– 191, 2025
2025
-
[60]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[61]
Felix Pei, Joel Ye, David Zoltowski, Anqi Wu, Raeed H Chowdhury, Hansem Sohn, Joseph E O’Doherty, Krishna V Shenoy, Matthew T Kaufman, Mark Churchland, et al. Neural latents benchmark’21: evaluating latent variable models of neural population activity.arXiv preprint arXiv:2109.04463, 2021. 14
-
[62]
Latent structured models for human pose estimation
Catalin Ionescu, Fuxin Li, and Cristian Sminchisescu. Latent structured models for human pose estimation. In2011 International Conference on Computer Vision, pages 2220–2227. IEEE, 2011
2011
-
[63]
Query-key normalization for transformers
Alex Henry, Prudhvi Raj Dachapally, Shubham Shantaram Pawar, and Yuxuan Chen. Query-key normalization for transformers. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4246–4253, 2020
2020
-
[64]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. InEuropean conference on computer vision, pages 694–711. Springer, 2016
2016
-
[65]
Vitpose: Simple vision transformer baselines for human pose estimation.Advances in neural information processing systems, 35:38571–38584, 2022
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose: Simple vision transformer baselines for human pose estimation.Advances in neural information processing systems, 35:38571–38584, 2022
2022
-
[66]
Alexander Mathis, Pranav Mamidanna, Kevin M Cury, Taiga Abe, Venkatesh N Murthy, Mackenzie Weygandt Mathis, and Matthias Bethge. Deeplabcut: markerless pose estimation of user-defined body parts with deep learning.Nature neuroscience, 21(9):1281–1289, 2018. 15 Supplementary Material BEAST3D: Animal behavioral analysis and neural encoding from multi-view v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.