GuidedBridge: Training-freely Improving Bridge Models with Prior Guidance
Pith reviewed 2026-06-28 10:42 UTC · model grok-4.3
The pith
A weak unseen prior contrasted with the seen prior improves bridge model performance without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
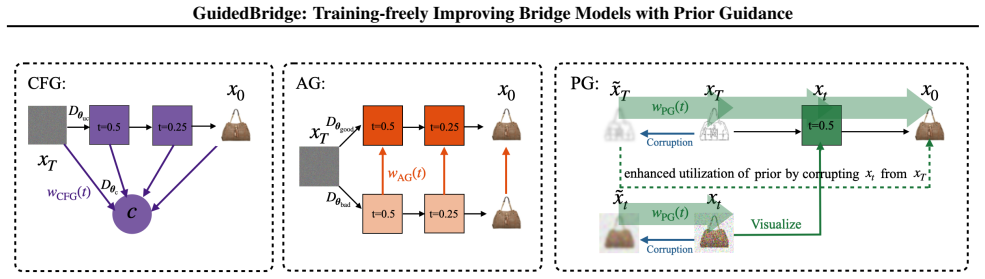
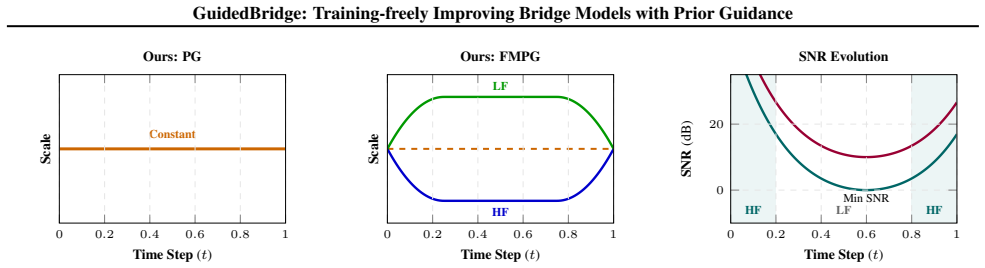
Prior Guidance (PG) introduces a weak prior unseen during bridge pre-training, hindering prior exploitation and degrading the denoising result. Contrasting it with the seen prior via a scaling factor highlights and enhances prior exploitation. Frequency-modulated prior guidance (FMPG) tailors the guidance scale to low- and high-frequency bands coherent with bridge generative dynamics. For in-painting, a cascaded CFG-FMPG first generates a noisy hidden representation via CFG then exploits it as a generative prior with FMPG.
What carries the argument
Prior Guidance, which scales the difference between denoising results from a seen prior and a weak unseen prior to enhance exploitation in the bridge process.
If this is right
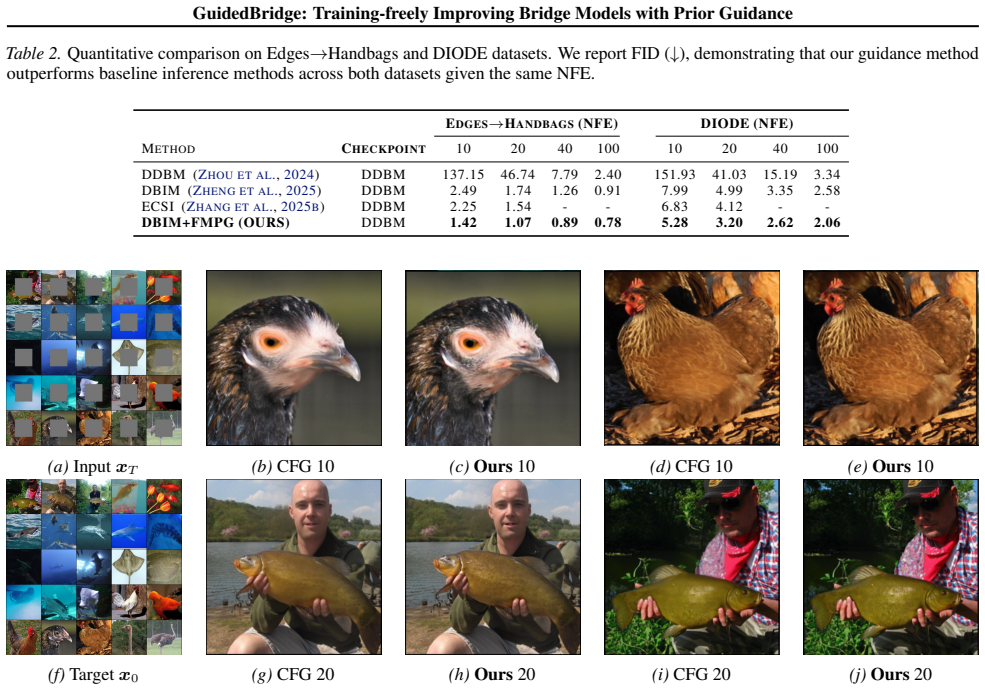
- PG methods improve pre-trained bridge models across diverse image translation tasks.
- FMPG adjusts guidance scales to match the frequency bands in bridge generative dynamics.
- CFG-FMPG combines CFG and FMPG strengths for in-painting while preserving inference speed.
Where Pith is reading between the lines
- The contrast approach could extend to creating guidance signals in other data-to-data or conditional generation settings.
- Frequency-specific scaling might help in tasks where generative steps have varying frequency content.
- Selecting different weak priors could be tested to optimize the degradation contrast for specific domains.
Load-bearing premise
A weak prior unseen during pre-training produces a sufficiently degraded denoising result whose contrast with the seen prior reliably enhances exploitation without new artifacts or instabilities.
What would settle it
Running the scaling procedure on a pre-trained bridge model for an image translation task and observing no quality gain or added artifacts would show the contrast mechanism does not work as claimed.
Figures







read the original abstract
Guidance methods, such as classifier-free guidance (CFG) and auto-guidance (AG), have advanced noise-to-data generation in diffusion models. Recently, bridge models have introduced a data-to-data generative process that can exploit an instructive clean prior. In this work, inspired by previous methods creating quality difference between denoising results as guidance, we propose a training-free bridge guidance method, termed Prior Guidance (PG). Specifically, we introduce a weak prior, which is unseen during bridge pre-training, hindering prior exploitation and thereby degrading denoising result. Then, we contrast it with the seen prior to highlight and enhance prior exploitation via a scaling factor. Moreover, we analyze the underlying mechanism of prior exploitation in the bridge process and design frequency-modulated prior guidance (FMPG), which tailors the guidance scale to low- and high-frequency bands coherent with bridge generative dynamics. To address prior exploitation in image in-painting, we develop a cascaded framework, CFG-FMPG, which first generates a noisy hidden representation via CFG and then exploits it as a generative prior with FMPG, fulfilling their complementary strengths without compromising inference efficiency. Experiments demonstrate that our PG methods consistently improve pre-trained bridge models across diverse image translation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-free Prior Guidance (PG) method for bridge models that introduces a weak unseen prior to degrade the denoising result and then contrasts it with the seen prior via a scaling factor to enhance prior exploitation. It further develops Frequency-Modulated Prior Guidance (FMPG) by analyzing the mechanism of prior exploitation and tailoring the guidance scale to low- and high-frequency bands, plus a cascaded CFG-FMPG framework for inpainting that combines CFG and FMPG. The central claim is that these methods consistently improve pre-trained bridge models across diverse image translation tasks.
Significance. If the claimed improvements are robustly supported, the work would be significant for enabling practical enhancements to data-to-data bridge models without retraining or additional parameters. The training-free contrastive design and the frequency-modulated analysis represent strengths that extend guidance techniques from diffusion models to bridge models while preserving inference efficiency.
minor comments (1)
- [Abstract] Abstract: the statement that 'Experiments demonstrate that our PG methods consistently improve pre-trained bridge models across diverse image translation tasks' supplies no quantitative metrics, baselines, error bars, or controls, which is a presentation issue that reduces the abstract's informativeness even though the full experiments section presumably contains the supporting data.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the recognition of the training-free nature and frequency-modulated analysis as strengths, and the recommendation for minor revision. No specific major comments were provided in the report, so we have no point-by-point responses to address. We are pleased that the central claims regarding consistent improvements to pre-trained bridge models are viewed as potentially significant if robustly supported.
Circularity Check
No significant circularity detected
full rationale
The paper derives PG as a training-free contrast between a seen prior and a deliberately weak unseen prior, then analyzes bridge dynamics to motivate frequency-modulated scaling in FMPG and a cascaded CFG-FMPG for inpainting. These steps are presented as direct consequences of the stated mechanism analysis rather than reductions to fitted parameters, self-definitions, or load-bearing self-citations. Experimental gains on pre-trained models are reported separately and do not feed back into the construction of the guidance equations themselves. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bridge models can exploit an instructive clean prior in a data-to-data generative process.
Reference graph
Works this paper leans on
-
[1]
H., Jin, K
Ahn, D., Cho, H., Min, J., Jang, W., Kim, J., Kim, S., Park, H. H., Jin, K. H., and Kim, S. Self-rectifying diffusion sampling with perturbed-attention guidance. In Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., and Varol, G. (eds.), Computer Vision -- ECCV 2024, 2025
2024
-
[2]
Dynamic classifier-free diffusion guidance via online feedback
Anonymous. Dynamic classifier-free diffusion guidance via online feedback. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[4]
Bolton, A., Zhou, W., Chen, Z., Iacovides, G., and Mandic, D. P. Refinebridge: Generative bridge models improve financial forecasting by foundation models. In ICASSP, 2026
2026
-
[5]
Stochastic self-guidance for training-free enhancement of diffusion models
Chen, C., Zhu, J., Feng, X., Huang, N., Zhu, C., Wu, M., Mao, F., Wu, J., Chu, X., and Li, X. Stochastic self-guidance for training-free enhancement of diffusion models. In The Fourteenth International Conference on Learning Representations, 2026 a
2026
-
[6]
Normalized attention guidance: Universal negative guidance for diffusion models
Chen, D.-Y., Bandyopadhyay, H., Zou, K., and Song, Y.-Z. Normalized attention guidance: Universal negative guidance for diffusion models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[7]
Chen, T., Liu, G.-H., and Theodorou, E. A. Likelihood training of schrödinger bridge using forward-backward sdes theory. In ICLR, 2022 a
2022
-
[8]
Infergrad: Improving diffusion models for vocoder by considering inference in training
Chen, Z., Tan, X., Wang, K., Pan, S., Mandic, D., He, L., and Zhao, S. Infergrad: Improving diffusion models for vocoder by considering inference in training. In ICASSP, 2022 b
2022
-
[11]
P., and Zhu, J
Chen, Z., Miao, Y., Wang, L., Fan, L., Mandic, D. P., and Zhu, J. Versatile cardiovascular signal generation with a unified diffusion transformer. Nature Machine Intelligence, 8 0 (1): 0 6--19, 2026 b
2026
-
[12]
Omni2sound: Towards unified video-text-to-audio generation
Dai, Y., Chen, Z., Jiang, Y., Ke, Q., Cai, J., and Zhu, J. Omni2sound: Towards unified video-text-to-audio generation. In CVPR, 2026
2026
-
[13]
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 248--255, 2009. doi:10.1109/CVPR.2009.5206848
-
[14]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., Podell, D., Dockhorn, T., English, Z., and Rombach, R. Scaling rectified flow transformers for high-resolution image synthesis. In ICML, 2024
2024
-
[15]
On the guidance of flow matching
Feng, R., Yu, C., Deng, W., Hu, P., and Wu, T. On the guidance of flow matching. In Forty-second International Conference on Machine Learning, 2025
2025
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[17]
and Salimans, T
Ho, J. and Salimans, T. Classifier-free diffusion guidance. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[18]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp.\ 6840--6851. Curran Associates, Inc., 2020
2020
-
[19]
Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention
Hong, S. Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 66743--66772. Curran Associates, Inc., 2024
2024
-
[20]
Improving sample quality of diffusion models using self-attention guidance
Hong, S., Lee, G., Jang, W., and Kim, S. Improving sample quality of diffusion models using self-attention guidance. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), pp.\ 7428--7437, 2023
2023
-
[21]
B., Romero-Soriano, A., Drozdzal, M., Verbeek, J., and Alahari, K
Ifriqi, T. B., Romero-Soriano, A., Drozdzal, M., Verbeek, J., and Alahari, K. Entropy rectifying guidance for diffusion and flow models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[22]
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017
2017
-
[23]
Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation
Jiang, Y., Chen, Z., Ju, Z., Li, C., Dou, W., and Zhu, J. Freeaudio: Training-free timing planning for controllable long-form text-to-audio generation. In ACM Multimedia, 2025
2025
-
[24]
Elucidating the design space of diffusion-based generative models
Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp.\ 26565--26577. Curran Associates, Inc., 2022
2022
-
[25]
Guiding a diffusion model with a bad version of itself
Karras, T., Aittala, M., Kynk\" a \" a nniemi, T., Lehtinen, J., Aila, T., and Laine, S. Guiding a diffusion model with a bad version of itself. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Systems, volume 37, pp.\ 52996--53021. Curran Associates, Inc., 2024
2024
-
[26]
Binauralgrad: A two-stage conditional diffusion probabilistic model for binaural audio synthesis
Leng, Y., Chen, Z., Guo, J., Liu, H., Chen, J., Tan, X., Mandic, D., He, L., Li, X.-Y., Qin, T., Zhao, S., and Liu, T.-Y. Binauralgrad: A two-stage conditional diffusion probabilistic model for binaural audio synthesis. In NeurIPS, 2022
2022
-
[27]
Bridge-sr: Schrödinger bridge for efficient sr
Li, C., Chen, Z., Bao, F., and Zhu, J. Bridge-sr: Schrödinger bridge for efficient sr. In ICASSP, 2025 a
2025
-
[28]
Audio super-resolution with latent bridge models
Li, C., Chen, Z., Wang, L., and Zhu, J. Audio super-resolution with latent bridge models. In NeurIPS, 2025 b
2025
-
[29]
A., Nie, W., and Anandkumar, A
Liu, G.-H., Vahdat, A., Huang, D.-A., Theodorou, E. A., Nie, W., and Anandkumar, A. I ^2 sb: Image-to-image schr \"o dinger bridge. In International Conference on Machine Learning, pp.\ 21551--21568. PMLR, 2023 a
2023
-
[30]
A., and Chen, R
Liu, G.-H., Lipman, Y., Nickel, M., Karrer, B., Theodorou, E. A., and Chen, R. T. Generalized schrödinger bridge matching. In ICLR, 2024
2024
-
[31]
P., Wang, W., and Plumbley, M
Liu, H., Chen, Z., Yuan, Y., Mei, X., Liu, X., Mandic, D. P., Wang, W., and Plumbley, M. D. Audioldm: Text-to-audio generation with latent diffusion models. In ICML, 2023 b
2023
-
[32]
SDE dit: Guided image synthesis and editing with stochastic differential equations
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.-Y., and Ermon, S. SDE dit: Guided image synthesis and editing with stochastic differential equations. In International Conference on Learning Representations, 2022
2022
-
[33]
Respdiff: An end-to-end multi-scale rnn diffusion model for respiratory waveform estimation from ppg signals
Miao, Y., Chen, Z., Li, C., and Mandic, D. Respdiff: An end-to-end multi-scale rnn diffusion model for respiratory waveform estimation from ppg signals. In ICASSP, 2025
2025
-
[34]
Diffgap: A lightweight diffusion module in contrastive space for bridging cross-model gap
Mo, S., Chen, Z., Bao, F., and Zhu, J. Diffgap: A lightweight diffusion module in contrastive space for bridging cross-model gap. In ICASSP, 2025
2025
-
[35]
Models, C. D. B. Guande he and kaiwen zheng and jianfei chen and fan bao and jun zhu. In NeurIPS, 2024
2024
-
[36]
Dynamic classifier-free diffusion guidance via online feedback
Papalampidi, P., Wiles, O., Ktena, I., Shtedritski, A., Bugliarello, E., Kajic, I., Albuquerque, I., and Nematzadeh, A. Dynamic classifier-free diffusion guidance via online feedback. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[37]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In CVPR, 2022
2022
-
[38]
Sadat, S., Vontobel, T., Salehi, F., and Weber, R. M. Guidance in the frequency domain enables high-fidelity sampling at low cfg scales, 2025
2025
-
[39]
Improved techniques for training gans
Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., Chen, X., and Chen, X. Improved techniques for training gans. In Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
2016
-
[40]
Denoising diffusion implicit models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021 a
2021
-
[41]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In ICLR, 2021 b
2021
-
[42]
Dual diffusion implicit bridges for image-to-image translation
Su, X., Song, J., Meng, C., and Ermon, S. Dual diffusion implicit bridges for image-to-image translation. In The Eleventh International Conference on Learning Representations, 2023
2023
-
[43]
Z., Daniele, A
Vasiljevic, I., Kolkin, N., Zhang, S., Luo, R., Wang, H., Dai, F. Z., Daniele, A. F., Mostajabi, M., Basart, S., Walter, M. R., and Shakhnarovich, G. Diode: A dense indoor and outdoor depth dataset, 2019
2019
-
[44]
Audiomog: Guiding audio generation with mixture-of-guidance
Wang, J., Chen, Z., Yuan, B., Zheng, K., Li, C., Jiang, Y., and Zhu, J. Audiomog: Guiding audio generation with mixture-of-guidance. In ICME, 2026
2026
-
[45]
Towards a golden classifier-free guidance path via foresight fixed point iterations
Wang, K., Mao, J., Wu, T., and Xiang, Y. Towards a golden classifier-free guidance path via foresight fixed point iterations. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 a
2025
-
[46]
Tiva: Time-aligned video-to-audio generation
Wang, X., Wang, Y., Wu, Y., Song, R., Tan, X., Chen, Z., Xu, H., and Sui, G. Tiva: Time-aligned video-to-audio generation. In ACM MM, 2024
2024
-
[47]
Framebridge: Improving image-to-video generation with bridge models
Wang, Y., Chen, Z., Chen, X., Wei, Y., Zhu, J., and Chen, J. Framebridge: Improving image-to-video generation with bridge models. In ICML, 2025 b
2025
-
[49]
A., Shechtman, E., and Wang, O
Zhang, R., Isola, P., Efros, A. A., Shechtman, E., and Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018
2018
-
[50]
Zhang, S., Cheng, Y., and Steeg, G. V. Exploring the design space of diffusion bridge models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b
2025
-
[51]
Diffusion bridge implicit models
Zheng, K., He, G., Chen, J., Bao, F., and Zhu, J. Diffusion bridge implicit models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[52]
Denoising diffusion bridge models
Zhou, L., Lou, A., Khanna, S., and Ermon, S. Denoising diffusion bridge models. In International Conference on Learning Representations, 2024
2024
-
[53]
International Conference on Learning Representations , year=
Denoising Diffusion Bridge Models , author=. International Conference on Learning Representations , year=
-
[54]
ICLR , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. ICLR , year=
-
[55]
ICLR , year=
Generalized Schrödinger Bridge Matching , author=. ICLR , year=
-
[56]
ICLR , year=
Likelihood Training of Schrödinger Bridge using Forward-Backward SDEs Theory , author=. ICLR , year=
-
[57]
ICASSP , year=
Bridge-SR: Schrödinger Bridge for Efficient SR , author=. ICASSP , year=
-
[58]
NeurIPS , year=
Audio Super-Resolution with Latent Bridge Models , author=. NeurIPS , year=
-
[59]
ICASSP , year=
RefineBridge: Generative Bridge Models Improve Financial Forecasting by Foundation Models , author=. ICASSP , year=
-
[60]
ACM MM , year=
TiVA: Time-Aligned Video-to-Audio Generation , author=. ACM MM , year=
-
[61]
Nature Machine Intelligence , volume=
Versatile cardiovascular signal generation with a unified diffusion transformer , author=. Nature Machine Intelligence , volume=. 2026 , publisher=
2026
-
[62]
ICASSP , year=
DiffGAP: A Lightweight Diffusion Module in Contrastive Space for Bridging Cross-Model Gap , author=. ICASSP , year=
-
[63]
ICASSP , year=
RespDiff: An End-to-End Multi-scale RNN Diffusion Model for Respiratory Waveform Estimation from PPG Signals , author=. ICASSP , year=
-
[64]
ICME , year=
AudioMoG: Guiding Audio Generation with Mixture-of-Guidance , author=. ICME , year=
-
[65]
arXiv preprint arXiv:2212.14518 , year=
ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech , author=. arXiv preprint arXiv:2212.14518 , year=
-
[66]
arXiv preprint arXiv:2509.25275 , year=
VoiceBridge: General Speech Restoration with One-step Latent Bridge Models , author=. arXiv preprint arXiv:2509.25275 , year=
-
[67]
NeurIPS , year=
Guande He and Kaiwen Zheng and Jianfei Chen and Fan Bao and Jun Zhu , author=. NeurIPS , year=
-
[68]
Available: https://arxiv.org/abs/2312.03491
Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesis , author=. arXiv preprint arXiv:2312.03491 , year=
-
[69]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
ICML , year=
FrameBridge: Improving Image-to-Video Generation with Bridge Models , author=. ICML , year=
-
[71]
ICML , year=
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. ICML , year=
-
[72]
CVPR , year=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. CVPR , year=
-
[73]
ICML , year=
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models , author=. ICML , year=
-
[74]
ICASSP , year=
InferGrad: Improving Diffusion Models for Vocoder by Considering Inference in Training , author=. ICASSP , year=
-
[75]
NeurIPS , year=
BinauralGrad: A Two-Stage Conditional Diffusion Probabilistic Model for Binaural Audio Synthesis , author=. NeurIPS , year=
-
[76]
CVPR , year=
Omni2Sound: Towards Unified Video-Text-to-Audio Generation , author=. CVPR , year=
-
[77]
ACM Multimedia , year=
FreeAudio: Training-Free Timing Planning for Controllable Long-Form Text-to-Audio Generation , author=. ACM Multimedia , year=
-
[78]
I ^2 SB: Image-to-Image Schr
Liu, Guan-Horng and Vahdat, Arash and Huang, De-An and Theodorou, Evangelos A and Nie, Weili and Anandkumar, Anima , booktitle=. I ^2 SB: Image-to-Image Schr. 2023 , organization=
2023
-
[79]
NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
Classifier-Free Diffusion Guidance , author=. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
2021
-
[80]
Guiding a Diffusion Model with a Bad Version of Itself , volume =
Karras, Tero and Aittala, Miika and Kynk\". Guiding a Diffusion Model with a Bad Version of Itself , volume =. Advances in Neural Information Processing Systems , editor =
-
[81]
The Thirteenth International Conference on Learning Representations , year=
Diffusion Bridge Implicit Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[82]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =
-
[83]
Elucidating the Design Space of Diffusion-Based Generative Models , volume =
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , booktitle =. Elucidating the Design Space of Diffusion-Based Generative Models , volume =
-
[84]
The Eleventh International Conference on Learning Representations , year=
Dual Diffusion Implicit Bridges for Image-to-Image Translation , author=. The Eleventh International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.