P²-DPO: Grounding Hallucination in Perceptual Processing via Calibration Direct Preference Optimization
Pith reviewed 2026-06-28 11:11 UTC · model grok-4.3
The pith
P²-DPO reduces hallucinations in vision-language models by training on self-generated on-policy preference pairs and a calibration loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
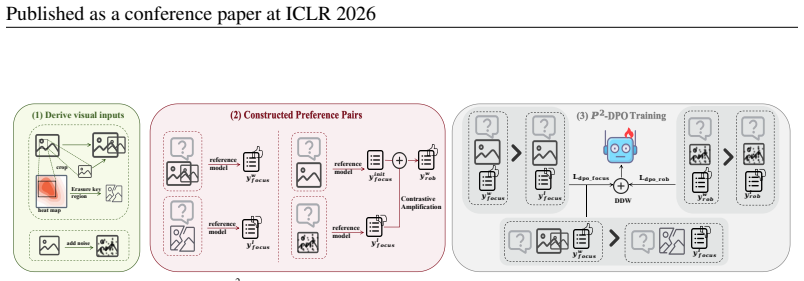
P²-DPO is a novel training paradigm in which the model generates and learns from its own on-policy preference pairs that target the perceptual bottleneck in attended regions and insufficient Visual Robustness against image degradation. It introduces an on-policy preference pairs construction method for Focus-and-Enhance perception and Visual Robustness, along with a Calibration Loss to precisely align visual signals with the causal generation of text. This allows it to outperform strong baselines relying on costly human feedback while using comparable training data and cost.
What carries the argument
on-policy preference pair construction targeting Focus-and-Enhance perception and Visual Robustness, combined with Calibration Loss to align visual signals with text generation
Load-bearing premise
The self-generated on-policy preference pairs are of sufficient quality and lack new biases that would prevent the Calibration Loss from properly aligning visual signals with text generation.
What would settle it
Running the same benchmarks with self-generated pairs and finding no outperformance or even worse results compared to human feedback baselines would falsify the claim that this approach is effective.
Figures




read the original abstract
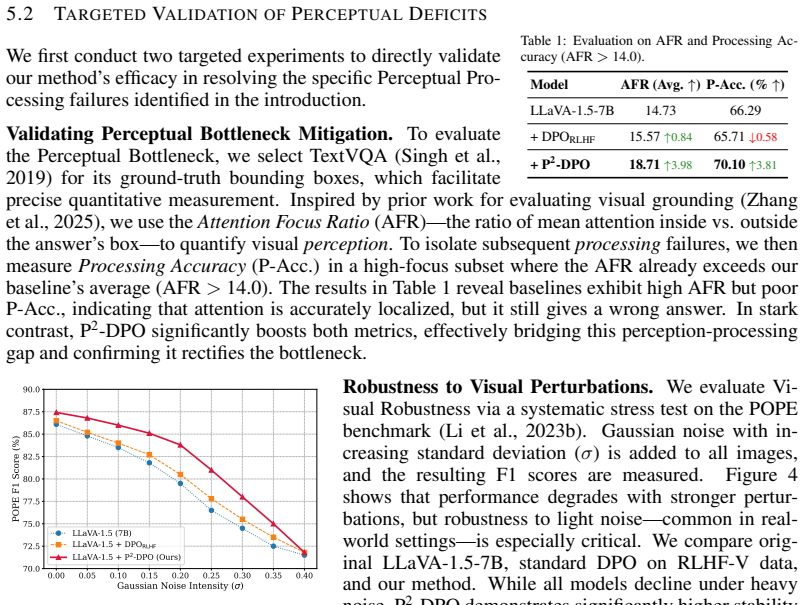
Hallucination has recently garnered significant research attention in Large Vision-Language Models (LVLMs). Direct Preference Optimization (DPO) aims to learn directly from the corrected preferences provided by humans, thereby addressing the hallucination issue. Despite its success, this paradigm has yet to specifically target the perceptual bottleneck in attended regions or address insufficient Visual Robustness against image degradation. Furthermore, existing preference pairs are often vision-agnostic and their inherently off-policy nature limits their effectiveness in guiding model learning. To address these challenges, we propose Perceptual Processing Direct Preference Optimization (P$^2$-DPO), a novel training paradigm in which the model generates and learns from its own preference pairs, thereby directly addressing the identified visual bottlenecks while inherently avoiding the issues of vision-agnostic and off-policy data. It introduces: (1) an on-policy preference pairs construction method targeting Focus-and-Enhance perception and Visual Robustness, and (2) a well-designed Calibration Loss to precisely align visual signals with the causal generation of text. Experimental results demonstrate that with a comparable amount of training data and cost, P$^2$-DPO outperforms strong baselines that rely on costly human feedback on benchmarks. Furthermore, evaluations on Attention Region Fidelity (ARF) and image degradation scenarios validate the effectiveness of P$^2$-DPO in addressing perceptual bottleneck in attended regions and improving Visual Robustness against degraded inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces P²-DPO, a direct preference optimization variant for large vision-language models (LVLMs) that constructs on-policy preference pairs via Focus-and-Enhance and Visual Robustness targeting methods, paired with a Calibration Loss to align visual signals with causal text generation. It claims that, with comparable training data and cost, P²-DPO outperforms strong human-feedback DPO baselines on standard benchmarks and validates effectiveness via Attention Region Fidelity (ARF) and image degradation evaluations.
Significance. If substantiated, the approach would be significant for reducing reliance on costly human annotations in preference optimization while directly targeting perceptual bottlenecks that contribute to hallucinations and improving robustness to degraded visual inputs in LVLMs.
major comments (2)
- [Abstract] Abstract: The central claims of outperformance over human-feedback baselines and validation on ARF/degradation tests are asserted without any quantitative results, ablation details, dataset sizes, statistical significance, or error analysis, which are load-bearing for evaluating whether the on-policy method succeeds.
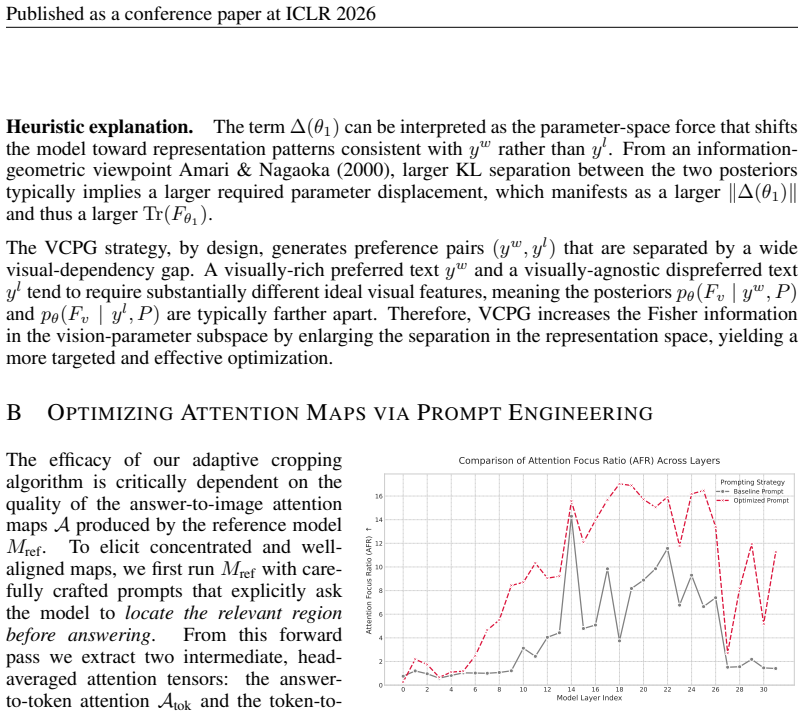
- [Method] Method (likely §3): The on-policy preference pair construction and Calibration Loss are presented as breaking circularity and aligning signals, but no equations, independent validation, or controls are referenced to demonstrate that self-generated pairs do not reinforce the model's existing perceptual errors or attention failures.
minor comments (2)
- [Abstract] Abstract: The acronym ARF is expanded on first use but its precise measurement protocol is not defined here or referenced.
- [Abstract] Notation: The superscript in P²-DPO is rendered with LaTeX but the full expansion 'Perceptual Processing Direct Preference Optimization' appears only after the acronym; define on first occurrence for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance over human-feedback baselines and validation on ARF/degradation tests are asserted without any quantitative results, ablation details, dataset sizes, statistical significance, or error analysis, which are load-bearing for evaluating whether the on-policy method succeeds.
Authors: We agree the abstract would be strengthened by including key quantitative highlights. In the revised version we will add concise references to benchmark improvements, training data volume, ablation outcomes, and statistical significance drawn from the experiments section while remaining within length limits. revision: yes
-
Referee: [Method] Method (likely §3): The on-policy preference pair construction and Calibration Loss are presented as breaking circularity and aligning signals, but no equations, independent validation, or controls are referenced to demonstrate that self-generated pairs do not reinforce the model's existing perceptual errors or attention failures.
Authors: Section 3 presents the on-policy construction (Focus-and-Enhance and Visual Robustness targeting) and Calibration Loss with the governing equations. The ARF metric and image-degradation evaluations function as independent controls showing improved attention alignment and robustness rather than error reinforcement. We will add explicit cross-references to these equations and controls in the revised text. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper proposes P²-DPO with on-policy preference pair construction and a Calibration Loss, claiming these address perceptual bottlenecks better than human feedback baselines. The provided abstract and context contain no equations, self-citations, or derivations that reduce the central claims (e.g., superior performance or alignment) to the inputs by construction, nor any load-bearing uniqueness theorems or fitted parameters renamed as predictions. Experimental validation on ARF and degradation benchmarks is presented as independent evidence, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions underlying Direct Preference Optimization for aligning model outputs with preferences
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education
Clancey, William J. Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education. Proceedings of the Eighth International Joint Conference on Artificial Intelligence (IJCAI-83)
-
[5]
Classification Problem Solving
Clancey, William J. Classification Problem Solving. Proceedings of the Fourth National Conference on Artificial Intelligence
-
[6]
, title =
Robinson, Arthur L. , title =. 1980 , doi =. https://science.sciencemag.org/content/208/4447/1019.full.pdf , journal =
1980
-
[7]
New Ways to Make Microcircuits Smaller---Duplicate Entry
Robinson, Arthur L. New Ways to Make Microcircuits Smaller---Duplicate Entry. Science
-
[8]
Clancey and Glenn Rennels , abstract =
Diane Warner Hasling and William J. Clancey and Glenn Rennels , abstract =. Strategic explanations for a diagnostic consultation system , journal =. 1984 , issn =. doi:https://doi.org/10.1016/S0020-7373(84)80003-6 , url =
-
[9]
and Rennels, Glenn R
Hasling, Diane Warner and Clancey, William J. and Rennels, Glenn R. and Test, Thomas. Strategic Explanations in Consultation---Duplicate. The International Journal of Man-Machine Studies
-
[10]
Poligon: A System for Parallel Problem Solving
Rice, James. Poligon: A System for Parallel Problem Solving
-
[11]
Transfer of Rule-Based Expertise through a Tutorial Dialogue
Clancey, William J. Transfer of Rule-Based Expertise through a Tutorial Dialogue
-
[12]
The Engineering of Qualitative Models
Clancey, William J. The Engineering of Qualitative Models
-
[13]
2017 , eprint=
Attention Is All You Need , author=. 2017 , eprint=
2017
-
[14]
Pluto: The 'Other' Red Planet
NASA. Pluto: The 'Other' Red Planet
-
[18]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mitigating object hallucinations in large vision-language models through visual contrastive decoding , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[36]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Wu, Penghao and Xie, Saining , booktitle=
-
[39]
Advances in neural information processing systems , volume=
Mome: Mixture of multimodal experts for generalist multimodal large language models , author=. Advances in neural information processing systems , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Controlmllm: Training-free visual prompt learning for multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
International Conference on Artificial Intelligence and Statistics , pages=
A general theoretical paradigm to understand learning from human preferences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
2024
-
[42]
arXiv preprint arXiv:2310.07704 , year=
Ferret: Refer and ground anything anywhere at any granularity , author=. arXiv preprint arXiv:2310.07704 , year=
-
[43]
RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback , author=
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback , author=. 2024 , eprint=
2024
-
[44]
arXiv preprint arXiv:2409.19605 , year=
The crucial role of samplers in online direct preference optimization , author=. arXiv preprint arXiv:2409.19605 , year=
-
[46]
CoRR , year=
The instinctive bias: Spurious images lead to hallucination in mllms , author=. CoRR , year=
-
[49]
proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Monkey: Image resolution and text label are important things for large multi-modal models , author=. proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
Advances in Neural Information Processing Systems , volume=
Direct preference-based policy optimization without reward modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
arXiv preprint physics/0004057 , year=
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
-
[54]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[55]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
MoExtend: Tuning New Experts for Modality and Task Extension , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 4: Student Research Workshop) , pages=
-
[56]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[57]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning that matters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Cogagent: A visual language model for gui agents , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[59]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[65]
2000 , publisher=
Methods of information geometry , author=. 2000 , publisher=
2000
-
[68]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[69]
Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
Transformers: State-of-the-art natural language processing , author=. Proceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations , pages=
2020
-
[72]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mitigating hallucinations in large vision-language models via dpo: On-policy data hold the key , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[73]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[74]
Deep variational information bottleneck
Alexander A Alemi, Ian Fischer, Joshua V Dillon, and Kevin Murphy. Deep variational information bottleneck. arXiv preprint arXiv:1612.00410, 2016
Pith/arXiv arXiv 2016
-
[75]
Methods of information geometry, volume 191
Shun-ichi Amari and Hiroshi Nagaoka. Methods of information geometry, volume 191. American Mathematical Soc., 2000
2000
-
[76]
Direct preference-based policy optimization without reward modeling
Gaon An, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-Min Kim, and Hyun Oh Song. Direct preference-based policy optimization without reward modeling. Advances in Neural Information Processing Systems, 36: 0 70247--70266, 2023
2023
-
[77]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. In International Conference on Artificial Intelligence and Statistics, pp.\ 4447--4455. PMLR, 2024
2024
-
[78]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025
Pith/arXiv arXiv 2025
-
[79]
Erasing concepts from text-to-image diffusion models with few-shot unlearning
Masane Fuchi and Tomohiro Takagi. Erasing concepts from text-to-image diffusion models with few-shot unlearning. arXiv preprint arXiv:2405.07288, 2: 0 1, 2024
arXiv 2024
-
[80]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp...
2024
-
[81]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[82]
The instinctive bias: Spurious images lead to hallucination in mllms
Tianyang Han, Qing Lian, Rui Pan, Renjie Pi, Jipeng Zhang, Shizhe Diao, Yong Lin, and Tong Zhang. The instinctive bias: Spurious images lead to hallucination in mllms. CoRR, 2024
2024
-
[83]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 14281--14290, 2024
2024
-
[84]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[85]
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43 0 (2): 0 1--55, 2025
2025
-
[86]
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. Rlaif vs. rlhf: Scaling reinforcement learning from human feedback with ai feedback, 2024. URL https://arxiv.org/abs/2309.00267
Pith/arXiv arXiv 2024
-
[87]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng, Hang Zhang, Guanzheng Chen, Xin Li, Shijian Lu, Chunyan Miao, and Lidong Bing. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 13872--13882, 2024
2024
-
[88]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pp.\ 19730--19742. PMLR, 2023 a
2023
-
[89]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023 b
Pith/arXiv arXiv 2023
-
[90]
Monkey: Image resolution and text label are important things for large multi-modal models
Zhang Li, Biao Yang, Qiang Liu, Zhiyin Ma, Shuo Zhang, Jingxu Yang, Yabo Sun, Yuliang Liu, and Xiang Bai. Monkey: Image resolution and text label are important things for large multi-modal models. In proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 26763--26773, 2024
2024
-
[91]
Moe-llava: Mixture of experts for large vision-language models
Bin Lin, Zhenyu Tang, Yang Ye, Jiaxi Cui, Bin Zhu, Peng Jin, Jinfa Huang, Junwu Zhang, Yatian Pang, Munan Ning, et al. Moe-llava: Mixture of experts for large vision-language models. arXiv preprint arXiv:2401.15947, 2024
Pith/arXiv arXiv 2024
-
[92]
A survey on hallucination in large vision-language models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, and Wei Peng. A survey on hallucination in large vision-language models. arXiv preprint arXiv:2402.00253, 2024 a
Pith/arXiv arXiv 2024
-
[93]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 26296--26306, 2024 b
2024
-
[94]
Aligning large language models with human preferences through representation engineering
Wenhao Liu, Xiaohua Wang, Muling Wu, Tianlong Li, Changze Lv, Zixuan Ling, Jianhao Zhu, Cenyuan Zhang, Xiaoqing Zheng, and Xuanjing Huang. Aligning large language models with human preferences through representation engineering. arXiv preprint arXiv:2312.15997, 2023
arXiv 2023
-
[95]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[96]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 0 27730--27744, 2022
2022
-
[97]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36: 0 53728--53741, 2023
2023
-
[98]
Proximal policy optimization algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[99]
Mome: Mixture of multimodal experts for generalist multimodal large language models
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Mome: Mixture of multimodal experts for generalist multimodal large language models. Advances in neural information processing systems, 37: 0 42048--42070, 2024
2024
-
[100]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 8317--8326, 2019
2019
-
[101]
Aligning large multimodal models with factually augmented rlhf
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, et al. Aligning large multimodal models with factually augmented rlhf. arXiv preprint arXiv:2309.14525, 2023
Pith/arXiv arXiv 2023
-
[102]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liangyan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, and Trevor Darrell. Aligning large multimodal models with factually augmented RLHF . In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics: ACL 2024, ...
-
[103]
Llama: Open and efficient foundation language models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
Pith/arXiv arXiv 2023
-
[104]
mdpo: Conditional preference optimization for multimodal large language models
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mdpo: Conditional preference optimization for multimodal large language models. arXiv preprint arXiv:2406.11839, 2024
arXiv 2024
-
[105]
Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation
Junyang Wang, Yuhang Wang, Guohai Xu, Jing Zhang, Yukai Gu, Haitao Jia, Jiaqi Wang, Haiyang Xu, Ming Yan, Ji Zhang, et al. Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397, 2023 a
Pith/arXiv arXiv 2023
-
[106]
Aligning large language models with human: A survey
Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang, Lifeng Shang, Xin Jiang, and Qun Liu. Aligning large language models with human: A survey. arXiv preprint arXiv:2307.12966, 2023 b
arXiv 2023
-
[107]
Controlmllm: Training-free visual prompt learning for multimodal large language models
Mingrui Wu, Xinyue Cai, Jiayi Ji, Jiale Li, Oucheng Huang, Gen Luo, Hao Fei, Guannan Jiang, Xiaoshuai Sun, and Rongrong Ji. Controlmllm: Training-free visual prompt learning for multimodal large language models. Advances in Neural Information Processing Systems, 37: 0 45206--45234, 2024
2024
-
[108]
V? : Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V? : Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp.\ 13084--13094, June 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.