Clustered Self-Assessment: A Simple yet Effective Method for Uncertainty Quantification in Large Language Models
Pith reviewed 2026-06-28 09:59 UTC · model grok-4.3
The pith
Clustering sampled LLM generations into semantic groups and scoring them via multiple-choice probabilities yields stronger uncertainty estimates than entropy baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
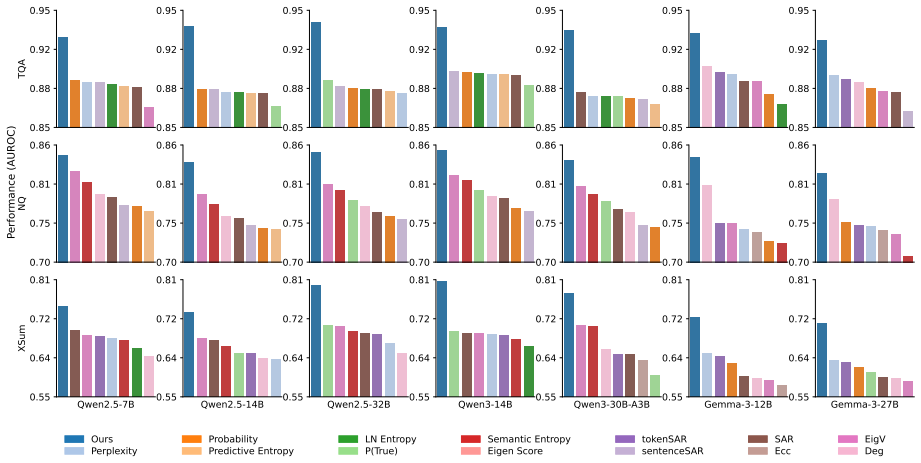
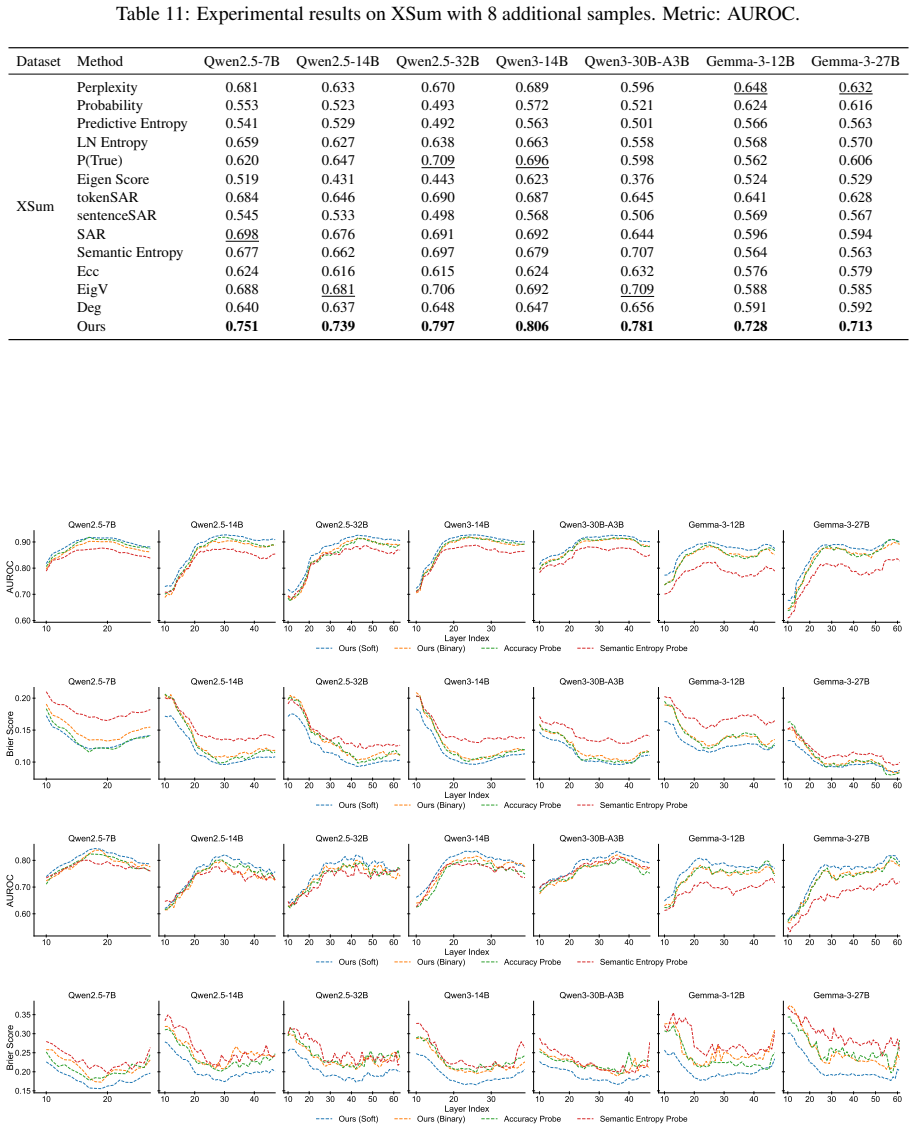
The central claim is that grouping sampled generations into semantically distinct clusters, converting those clusters into answer options within a multiple-choice question, and using the LLM-assigned probability for each option produces a confidence estimate that reliably quantifies uncertainty and outperforms existing baseline methods across multiple models and datasets.
What carries the argument
Semantic clustering of generations converted into multiple-choice options whose LLM probabilities serve as direct confidence estimates.
If this is right
- Effective uncertainty estimates require only two additional samples beyond the original generation.
- The approach supplies more interpretable confidence values than indirect entropy calculations.
- The same procedure applies without modification to different LLMs and task types.
- Direct use of the model's option probabilities leverages its self-assessment capacity more fully than post-hoc signals.
Where Pith is reading between the lines
- The clustering step could be replaced by embedding-based similarity measures to reduce dependence on manual semantic grouping.
- Combining the resulting scores with external fact-checking tools might produce hybrid reliability systems for high-stakes domains.
- The method might extend to open-ended generation tasks if clusters are defined over partial sequences rather than full answers.
- Real-time deployment could flag low-confidence responses for human review without retraining the underlying model.
Load-bearing premise
Semantic clustering must produce distinct and unbiased options whose probabilities accurately reflect the model's true uncertainty instead of depending on cluster boundaries or prompt formatting.
What would settle it
An experiment on a held-out dataset where the method's option probabilities fail to predict actual answer correctness better than entropy baselines would falsify the central claim.
Figures



read the original abstract
Large language models (LLMs) demonstrate remarkable performance across diverse tasks, but they often generate responses that appear plausible while being factually incorrect. This problem is compounded by the lack of explicit uncertainty estimates, which makes it difficult for users to judge the reliability of model outputs. Existing uncertainty quantification methods typically rely on indirect signals, such as entropy across sampled generations. These signals can be difficult to interpret and do not fully leverage the model's ability to assess its own uncertainty. We propose a simple yet effective self-assessment method for uncertainty quantification in LLMs. Our approach groups sampled generations into semantically distinct clusters, converts them into answer options in a structured multiple-choice question, and uses the probability assigned by the LLM to each option as a confidence estimate. Experiments across multiple models and datasets show that our method consistently outperforms baseline approaches. Notably, it achieves competitive performance with as few as two additional samples, demonstrating both its effectiveness and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Clustered Self-Assessment (CSA), a method for uncertainty quantification in LLMs. Multiple generations are sampled, grouped into semantically distinct clusters, reformulated as options in a structured multiple-choice question, and the LLM-assigned probabilities to those options are taken as confidence estimates. Experiments across models and datasets are reported to show consistent outperformance over baselines, with competitive results using as few as two additional samples.
Significance. If the results hold, CSA provides a simple and sample-efficient alternative to entropy-based UQ by directly eliciting option probabilities from the model in a controlled format. The low sample requirement is a practical strength for deployment scenarios where additional inference cost must be minimized.
major comments (1)
- [Experiments] The central claim that LLM probabilities on the clustered options constitute a valid uncertainty signal requires that semantic clustering yields unbiased distinctions and that the MCQ reformulation preserves the model's original probability distribution. No ablation on clustering granularity, similarity metric, or prompt template is reported in the experiments, so it remains possible that reported gains arise from formatting artifacts rather than improved uncertainty quantification (see skeptic note on prompt bias).
minor comments (1)
- [Abstract] The abstract states that generations are 'grouped into semantically distinct clusters' without naming the clustering algorithm or distance metric; this detail should be added to the method description for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The major comment raises a valid point about the need for additional validation in the experiments, which we address below.
read point-by-point responses
-
Referee: [Experiments] The central claim that LLM probabilities on the clustered options constitute a valid uncertainty signal requires that semantic clustering yields unbiased distinctions and that the MCQ reformulation preserves the model's original probability distribution. No ablation on clustering granularity, similarity metric, or prompt template is reported in the experiments, so it remains possible that reported gains arise from formatting artifacts rather than improved uncertainty quantification (see skeptic note on prompt bias).
Authors: We agree that the absence of ablations on clustering granularity, similarity metrics, and prompt templates leaves open the possibility that some observed gains could arise from formatting effects rather than the core uncertainty signal. The manuscript does not currently report such ablations. In the revised version we will add experiments that vary the number of clusters and similarity thresholds, test alternative embedding-based similarity metrics, and evaluate multiple MCQ prompt templates. These results will be included to assess whether the probability assignments remain stable and whether performance advantages persist across these variations. revision: yes
Circularity Check
No circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper describes an empirical procedure: sample generations, cluster them semantically, reformat as multiple-choice options, and use the LLM's assigned probabilities as confidence scores. No equations, parameter fittings, or derivation chains are present that could reduce to self-definition, fitted inputs called predictions, or self-citation load-bearing steps. The abstract and method rely on experimental validation across models and datasets rather than any constructed equivalence or imported uniqueness. This is a standard non-circular empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic clustering of sampled generations produces distinct and unbiased answer options
Reference graph
Works this paper leans on
-
[1]
Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. 2024. https://openreview.net/forum?id=Zj12nzlQbz INSIDE : LLM s' internal states retain the power of hallucination detection . In The Twelfth International Conference on Learning Representations
2024
-
[2]
Jiuhai Chen and Jonas Mueller. 2024. https://doi.org/10.18653/v1/2024.acl-long.283 Quantifying uncertainty in answers from any language model and enhancing their trustworthiness . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5186--5200, Bangkok, Thailand. Association for Computat...
-
[3]
Siddartha Devic, Tejas Srinivasan, Jesse Thomason, Willie Neiswanger, and Vatsal Sharan. 2025. From calibration to collaboration: Llm uncertainty quantification should be more human-centered. arXiv preprint arXiv:2506.07461
arXiv 2025
-
[4]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. 2024. https://doi.org/10.18653/v1/2024.acl-long.276 Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational...
-
[5]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy. Nature, 630(8017):625--630
2024
-
[6]
Marina Fomicheva, Shuo Sun, Lisa Yankovskaya, Fr \'e d \'e ric Blain, Francisco Guzm \'a n, Mark Fishel, Nikolaos Aletras, Vishrav Chaudhary, and Lucia Specia. 2020. https://doi.org/10.1162/tacl_a_00330 Unsupervised quality estimation for neural machine translation . Transactions of the Association for Computational Linguistics, 8:539--555
-
[7]
Jiatong Han, Jannik Kossen, Muhammed Razzak, Lisa Schut, Shreshth A Malik, and Yarin Gal. 2024. https://openreview.net/forum?id=Zd0XLr6JKn Semantic entropy probes: Robust and cheap hallucination detection in LLM s . In ICML 2024 Workshop on Foundation Models in the Wild
2024
-
[8]
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. https://openreview.net/forum?id=XPZIaotutsD Deberta: Decoding-enhanced bert with disentangled attention . In International Conference on Learning Representations
2021
-
[9]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. https://doi.org/10.1145/3703155 A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions . ACM Trans. Inf. Syst., 43(2)
-
[10]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. https://doi.org/10.1145/3571730 Survey of hallucination in natural language generation . ACM Comput. Surv., 55(12)
-
[11]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. https://doi.org/10.18653/v1/P17-1147 T rivia QA : A large scale distantly supervised challenge dataset for reading comprehension . In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601--1611, Vancouver, Canada. Assoc...
-
[12]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221
Pith/arXiv arXiv 2022
-
[13]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. https://openreview.net/forum?id=VD-AYtP0dve Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation . In The Eleventh International Conference on Learning Representations
2023
-
[14]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. https://doi.org/10.1162/tacl_a_00276 Natural questions: A benchma...
-
[15]
Moxin Li, Wenjie Wang, Fuli Feng, Fengbin Zhu, Qifan Wang, and Tat-Seng Chua. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.693 Think twice before trusting: Self-detection for large language models through comprehensive answer reflection . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 11858--11875, Miami, Florida,...
-
[16]
Chin-Yew Lin. 2004. https://aclanthology.org/W04-1013/ ROUGE : A package for automatic evaluation of summaries . In Text Summarization Branches Out, pages 74--81, Barcelona, Spain. Association for Computational Linguistics
2004
-
[17]
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. https://openreview.net/forum?id=DWkJCSxKU5 Generating with confidence: Uncertainty quantification for black-box large language models . Transactions on Machine Learning Research
2024
-
[18]
Dennis V Lindley. 1956. On a measure of the information provided by an experiment. The Annals of Mathematical Statistics, 27(4):986--1005
1956
-
[19]
J MacQueen. 1967. Some methods for classification and analysis of multivariate observations. In Proceedings ofthe 5th Berkeley symposium on mathematical statisticsand probability, volume 1, pages 281--297. University of California press Oakland, CA, USA
1967
-
[20]
Andrey Malinin and Mark Gales. 2021. https://openreview.net/forum?id=jN5y-zb5Q7m Uncertainty estimation in autoregressive structured prediction . In International Conference on Learning Representations
2021
-
[21]
Hardt, M., Recht, B., and Singer, Y
Shashi Narayan, Shay B. Cohen, and Mirella Lapata. 2018. https://doi.org/10.18653/v1/D18-1206 Don ' t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1797--1807, Brussels, Belgium. Association for Co...
-
[22]
OpenAI. 2025. Introducing gpt‑4.1 in the api. Accessed 14 Apr. 2025. https://openai.com/index/gpt-4-1/
2025
-
[23]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. 2011. Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12:2825--2830
2011
-
[24]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
Pith/arXiv arXiv 2025
-
[25]
Nils Reimers and Iryna Gurevych. 2019. https://doi.org/10.18653/v1/D19-1410 Sentence- BERT : Sentence embeddings using S iamese BERT -networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982--3992, Hong Kong, Chi...
-
[26]
Andrea Santilli, Miao Xiong, Michael Kirchhof, Pau Rodriguez, Federico Danieli, Xavier Suau, Luca Zappella, Sinead Williamson, and Adam Golinski. 2024. https://openreview.net/forum?id=jGtL0JFdeD On the protocol for evaluating uncertainty in generative question-answering tasks . In Neurips Safe Generative AI Workshop 2024
2024
-
[27]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
Pith/arXiv arXiv 2025
-
[28]
Roman Vashurin, Ekaterina Fadeeva, Artem Vazhentsev, Lyudmila Rvanova, Daniil Vasilev, Akim Tsvigun, Sergey Petrakov, Rui Xing, Abdelrahman Sadallah, Kirill Grishchenkov, Alexander Panchenko, Timothy Baldwin, Preslav Nakov, Maxim Panov, and Artem Shelmanov. 2025. https://doi.org/10.1162/tacl_a_00737 Benchmarking uncertainty quantification methods for larg...
-
[29]
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. 2024. https://openreview.net/forum?id=gjeQKFxFpZ Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s . In The Twelfth International Conference on Learning Representations
2024
-
[30]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.