Imaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
Pith reviewed 2026-06-28 09:54 UTC · model grok-4.3
The pith
Imaginative Perception Tokens improve spatial reasoning in vision-language models by supplying intermediate perceptual representations of unseen viewpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
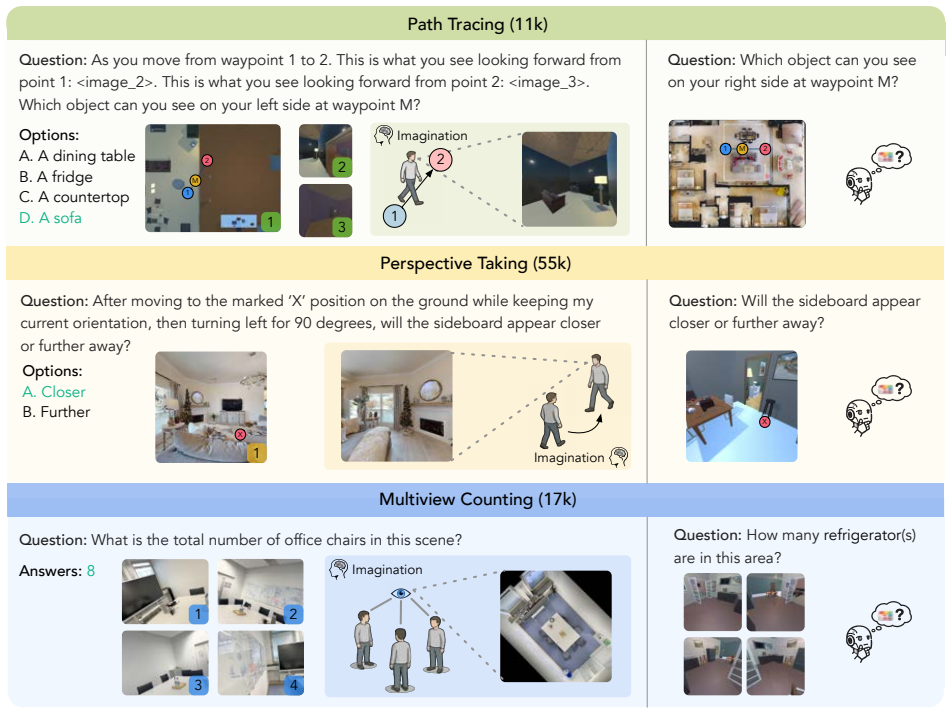
Training a unified vision-language model with supervision on imaginative perception tokens that externalize consistent inferences about unobserved viewpoints and occluded paths yields higher accuracy on spatial reasoning benchmarks than label-only or textual chain-of-thought training, reaching a 3.4 percent lift on multiview counting and competitive results with closed-source models on path tracing while producing interpretable intermediate representations.
What carries the argument
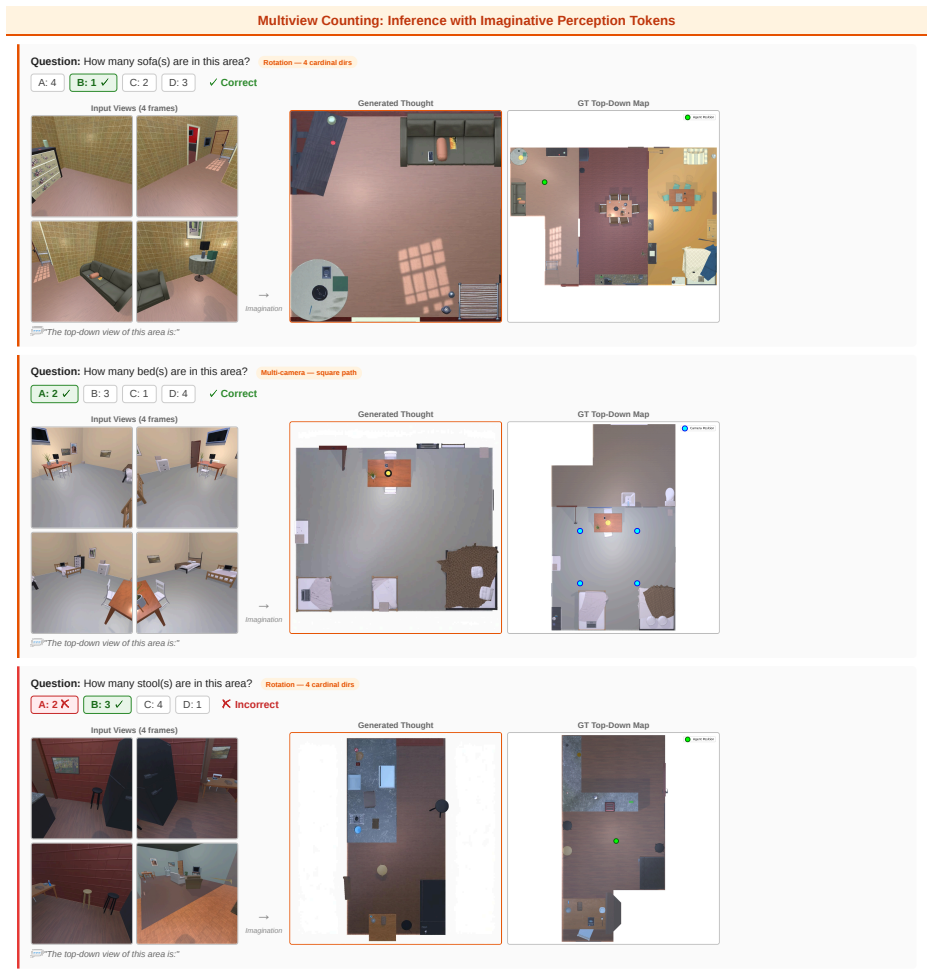
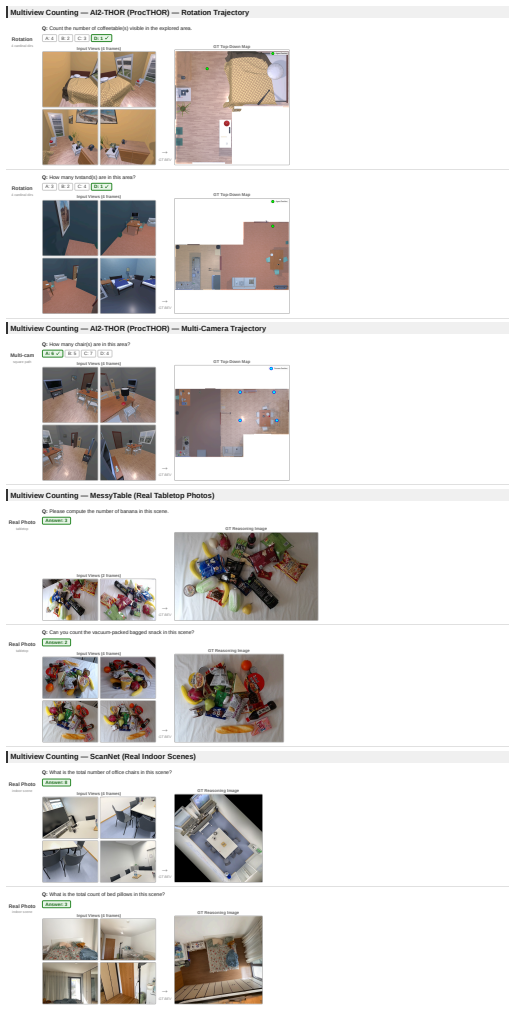
Imaginative Perception Tokens (IPT), intermediate perceptual representations that externalize what the model would perceive from alternative spatial configurations while staying consistent with the observed input.
If this is right
- Combining IPT supervision with label-only training produces additional accuracy gains beyond IPT alone.
- Textual chain-of-thought training can lower performance on spatial tasks because of a modality mismatch.
- IPT supervision improves generalization on problems that require inference about unobserved spatial structure.
- The learned IPT representations remain usable and beneficial without image generation during inference.
Where Pith is reading between the lines
- The same token-based supervision could be tested on other tasks that require mental simulation, such as navigation or object manipulation planning.
- If IPTs prove transferable across model sizes, they might allow smaller open models to close the gap with closed-source systems on spatial benchmarks.
- Future datasets could vary the degree of occlusion or viewpoint shift to measure how much imaginative content is needed for the gains to appear.
Load-bearing premise
The ground-truth imaginations in the constructed datasets can be learned as consistent intermediate representations that transfer to better task performance without creating inconsistencies or requiring image generation at inference.
What would settle it
Run the same backbone model with and without IPT supervision on a fresh spatial-reasoning benchmark where imaginative elements are explicitly controlled; if accuracy does not rise or falls, the claim is falsified.
Figures






read the original abstract
Vision language models (VLMs) excel at many tasks but still struggle with spatial reasoning when critical information is not directly observable. Many such problems require imaginative perception: inferring what would be seen from an unseen viewpoint, tracing paths through occluded spaces, or integrating partial observations into a coherent spatial representation. We introduce Imaginative Perception Tokens (IPT), intermediate perceptual representations that externalize what a VLM would perceive under alternative spatial configurations while remaining consistent with the observed input. To study this capability, we formulate three tasks, Perspective Taking (PET), Path Tracing (PT), and Multiview Counting (MVC), and construct datasets of approximately 20K examples with ground truth imaginations, answers, and evaluation benchmarks. Using the unified VLM BAGEL as the backbone, IPT supervision consistently improves spatial reasoning and often outperforms textual chain of thought training, even without generating images at inference time. On MVC, IPT improves accuracy by 3.4% and achieves competitive performance with strong closed-source models on PT. We further find that combining IPT and label-only supervision yields additional gains, whereas textual chain of thought can substantially degrade performance, suggesting a modality mismatch when spatial computation is forced through language. Overall, IPT provides a principled supervision signal for reasoning about unobserved spatial structure, improving generalization while producing interpretable intermediate representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Imaginative Perception Tokens (IPT) serve as effective intermediate perceptual representations for VLMs on spatial reasoning tasks requiring inference about unobserved viewpoints or structures. Using the BAGEL backbone and newly constructed ~20K-example datasets for Perspective Taking (PET), Path Tracing (PT), and Multiview Counting (MVC) with ground-truth imaginations, IPT supervision yields consistent accuracy gains (e.g., +3.4% on MVC) that often exceed textual chain-of-thought training, even when IPTs and images are not emitted at inference time. Combining IPT with label-only supervision provides further benefits while textual CoT can degrade performance.
Significance. If the empirical results hold under rigorous controls, the work supplies a modality-matched supervision signal for perceptual spatial reasoning that avoids forcing spatial computation through language, with potential to improve generalization and interpretability in VLMs. The construction of new tasks and datasets with stated ground truth, plus direct comparisons showing CoT degradation, are positive contributions that could influence future multimodal training paradigms.
major comments (3)
- [Abstract and §5] Abstract and §5 (Experiments): The reported 3.4% MVC accuracy gain and competitive PT performance lack any mention of the precise baseline configuration (e.g., whether it matches the IPT training schedule, number of epochs, or data order), error bars across multiple seeds, or statistical significance testing. Without these, it is impossible to determine whether the delta is attributable to IPT supervision or to uncontrolled training differences versus the textual-CoT baseline that reportedly degrades performance.
- [§3 and §4] §3 (Dataset Construction) and §4 (IPT Supervision): The central claim requires that the ~20K ground-truth imaginations are internally consistent with the observed inputs and produce usable intermediate representations that transfer at inference without image generation. The manuscript provides no quantitative checks (e.g., consistency metrics across generated imaginations or ablation removing the perceptual loss) to rule out the possibility that gains arise from an auxiliary loss rather than altered spatial computation inside the model.
- [§5] §5 (Results): The claim that IPT supervision 'consistently improves' and 'often outperforms' textual CoT is load-bearing, yet the text does not report per-task breakdowns, failure-case analysis, or controls for dataset construction artifacts that could confound the modality-mismatch interpretation. This weakens the generalization argument.
minor comments (2)
- [§4] Notation for IPT integration (e.g., how tokens are inserted into the transformer layers) is introduced without an accompanying diagram or equation, making the implementation details harder to reproduce.
- [Abstract] The abstract states 'approximately 20K examples' but does not break down the split across PET/PT/MVC or report validation/test sizes, which should be added for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications from the manuscript and commit to revisions that strengthen the empirical claims without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and §5] Abstract and §5 (Experiments): The reported 3.4% MVC accuracy gain and competitive PT performance lack any mention of the precise baseline configuration (e.g., whether it matches the IPT training schedule, number of epochs, or data order), error bars across multiple seeds, or statistical significance testing. Without these, it is impossible to determine whether the delta is attributable to IPT supervision or to uncontrolled training differences versus the textual-CoT baseline that reportedly degrades performance.
Authors: The baselines in §5 were configured to match the IPT training schedule exactly, including identical epoch counts, batch sizes, and data ordering as stated in the experimental setup. We acknowledge the absence of error bars and significance tests. In the revised version we will report means and standard deviations across three random seeds and include paired statistical tests to confirm the reported deltas (including the 3.4% MVC gain) are robust. revision: yes
-
Referee: [§3 and §4] §3 (Dataset Construction) and §4 (IPT Supervision): The central claim requires that the ~20K ground-truth imaginations are internally consistent with the observed inputs and produce usable intermediate representations that transfer at inference without image generation. The manuscript provides no quantitative checks (e.g., consistency metrics across generated imaginations or ablation removing the perceptual loss) to rule out the possibility that gains arise from an auxiliary loss rather than altered spatial computation inside the model.
Authors: Dataset construction in §3 enforces consistency by design through explicit geometric rules that align imagined views with observed inputs; the ~20K examples were filtered to satisfy these constraints. We agree that explicit quantitative validation would be valuable. The revision will add consistency metrics (e.g., spatial agreement scores between generated imaginations and ground-truth relations) and an ablation that removes the perceptual loss term while retaining the same auxiliary structure, to isolate the contribution of the modality-matched supervision. revision: yes
-
Referee: [§5] §5 (Results): The claim that IPT supervision 'consistently improves' and 'often outperforms' textual CoT is load-bearing, yet the text does not report per-task breakdowns, failure-case analysis, or controls for dataset construction artifacts that could confound the modality-mismatch interpretation. This weakens the generalization argument.
Authors: Section 5 already presents task-specific results (PET, PT, MVC) and notes the degradation under textual CoT, but we accept that fuller breakdowns and artifact controls would strengthen the argument. The revision will expand §5 with complete per-task tables, a dedicated failure-case analysis, and controls that re-train on shuffled or artifact-removed splits to verify that gains are not driven by dataset construction biases. revision: yes
Circularity Check
No circularity: empirical gains on new tasks with external ground truth
full rationale
The paper introduces IPT via new task formulations (PET/PT/MVC) and ~20K-example datasets that supply independent ground-truth imaginations and answers. Performance deltas (e.g., +3.4% on MVC) are measured on held-out evaluation benchmarks against textual-CoT baselines. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation; the central claim is a standard empirical comparison of supervision signals whose correctness is externally falsifiable on the stated benchmarks. This matches the default expectation of a non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption IPT representations can be learned as consistent intermediate perceptual signals from the input data.
invented entities (1)
-
Imaginative Perception Tokens (IPT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Mahtab Bigverdi, Zelun Luo, Cheng-Yu Hsieh, Ethan Shen, Dongping Chen, Linda G. Shapiro, and Ranjay Krishna. Per- ception tokens enhance visual reasoning in multimodal lan- guage models.arXiv preprint arXiv:2412.03548, 2024
-
[3]
Ellis Brown, Jihan Yang, Shusheng Yang, Rob Fergus, and Saining Xie. Benchmark designers should “train on the test set” to expose exploitable non-visual shortcuts.arXiv preprint arXiv:2511.04655, 2025
-
[4]
Messytable: Instance association in multiple camera views
Zhongang Cai, Junzhe Zhang, Daxuan Ren, Cunjun Yu, Haiyu Zhao, Shuai Yi, Chai Kiat Yeo, and Chen Change Loy. Messytable: Instance association in multiple camera views. InEuropean Conference on Computer Vision, pages 1–16. Springer, 2020
2020
-
[5]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Matterport3d: Learning from rgb-d data in indoor environments, 2017
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Hal- ber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3d: Learning from rgb-d data in indoor environments, 2017
2017
-
[7]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Winson Han, Ali Farhadi, and Ranjay Krishna. Molmo2: Open weights and data for vision-language m...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner
Angela Dai, Angel X. Chang, Manolis Savva, Maciej Hal- ber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes, 2017
2017
-
[10]
Procthor: Large-scale embodied ai using procedural genera- tion, 2022
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. Procthor: Large-scale embodied ai using procedural genera- tion, 2022
2022
-
[11]
Smith, Hannaneh Hajishirzi, Ross Girshick, Ali Farhadi, and Aniruddha Kembhavi
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tri- pathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison- Burch, Andrew Head, Rose Hendrix, Favyen Bastani, Eli VanderBilt, Nathan Lambert, Y...
2025
-
[12]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Counting stacked objects
Corentin Dumery, Noa Ett ´e, Aoxiang Fan, Ren Li, Jingyi Xu, Hieu Le, and Pascal Fua. Counting stacked objects. In ICCV, 2025
2025
-
[14]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[15]
Jiawei Gu, Yunzhuo Hao, Huichen Will Wang, Linjie Li, Michael Qizhe Shieh, Yejin Choi, Ranjay Krishna, and Yu Cheng. ThinkMorph: Emergent properties in multimodal interleaved chain-of-thought reasoning.arXiv preprint arXiv:2510.27492, 2025
-
[16]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering, 2023
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Os- tendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering, 2023
2023
-
[17]
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Osten- dorf, Luke Zettlemoyer, Noah A. Smith, and Ranjay Kr- ishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.arXiv preprint arXiv:2406.09403, 2024
-
[18]
What’s “up” with vision-language models? Investigating their strug- gle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s “up” with vision-language models? Investigating their strug- gle with spatial reasoning. InProceedings of the Confer- ence on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[19]
Egohumans: An egocen- tric 3d multi-human benchmark, 2023
Rawal Khirodkar, Aayush Bansal, Lingni Ma, Richard New- combe, Minh V o, and Kris Kitani. Egohumans: An egocen- tric 3d multi-human benchmark, 2023
2023
-
[20]
AI2-THOR: An Interactive 3D Environment for Visual AI
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imag- 9 ine while reasoning in space: Multimodal visualization-of- thought.arXiv preprint arXiv:2501.07542, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Linnan Li, Xiaoyu Chen, Peng Chen, et al. ViewSpatial- Bench: Evaluating multi-perspective spatial under- standing of vision-language models.arXiv preprint arXiv:2505.21500, 2025
-
[23]
Visual spatial reasoning.arXiv preprint arXiv:2205.00363, 2022
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.arXiv preprint arXiv:2205.00363, 2022
-
[24]
de Melo, and Alan Yuille
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso M. de Melo, and Alan Yuille. 3DSR- Bench: A comprehensive 3D spatial reasoning benchmark. InICCV, 2025
2025
-
[25]
Habitat: A Platform for Embodied AI Research
Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A Platform for Embodied AI Research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[26]
Thinking with images
OpenAI. Thinking with images. OpenAI Blog, 2025
2025
-
[27]
Habitat 3.0: A co-habitat for humans, avatars and robots, 2023
Xavi Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Ruslan Partsey, Jimmy Yang, Ruta Desai, Alexan- der William Clegg, Michal Hlavac, Tiffany Min, Theo Gervet, Vladim ´ır V ondruˇs, Vincent-Pierre Berges, John Turner, Oleksandr Maksymets, Zsolt Kira, Mrinal Kalakr- ishnan, Jitendra Malik, Devendra Singh Chaplot, Unnat Jain, Dhruv Batra, Akshar...
2023
-
[28]
Mull-Tokens: Modality-Agnostic Latent Thinking
Arijit Ray, Ahmed Abdelkader, Chengzhi Mao, Bryan A. Plummer, Kate Saenko, Ranjay Krishna, Leonidas Guibas, and Wen-Sheng Chu. Mull-tokens: Modality-agnostic latent thinking.arXiv preprint arXiv:2512.10941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kem- bhavi, Bryan A. Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko. Sat: Dynamic spatial aptitude training for multimodal language models, 2025
2025
-
[30]
Habitat 2.0: Training home assistants to rearrange their habitat
Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, Devendra Chaplot, Oleksandr Maksymets, Aaron Gokaslan, Vladimir V ondrus, Sameer Dharur, Franziska Meier, Woj- ciech Galuba, Angel Chang, Zsolt Kira, Vladlen Koltun, Ji- tendra Malik, Manolis Savva, and Dhruv Batra. Habitat 2.0: Training home as...
2021
-
[31]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.arXiv preprint arXiv:2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, De- qing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingk...
2025
-
[34]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show- o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How mul- timodal large language models see, remember, and recall spaces.arXiv preprint arXiv:2412.14171, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
SpatialSense: An adversarially crowdsourced benchmark for spatial rela- tion recognition
Kaiyu Yang, Olga Russakovsky, and Jia Deng. SpatialSense: An adversarially crowdsourced benchmark for spatial rela- tion recognition. InICCV, 2019
2019
-
[37]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
2024
-
[38]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wen- qian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
-
[39]
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence
Sihan Yang, Runsen Xu, Yiman Xie, et al. MMSI-Bench: A benchmark for multi-image spatial intelligence.arXiv preprint arXiv:2505.23764, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine mental imagery: Empower multi- modal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Seeing from another perspective: Evaluating multi-view understanding in mllms
Chun-Hsiao Yeh, Chenyu Wang, Shengbang Tong, Ta-Ying Cheng, Ruoyu Wang, Tianzhe Chu, Yuexiang Zhai, Yubei Chen, Shenghua Gao, and Yi Ma. Seeing from another perspective: Evaluating multi-view understanding in mllms. arXiv preprint arXiv:2504.15280, 2025
-
[42]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023
2023
-
[43]
Spa- tial mental modeling from limited views.arXiv preprint arXiv:2506.21458, 2025
Baiqiao Yin, Qineng Wang, Pingyue Zhang, et al. Spa- tial mental modeling from limited views.arXiv preprint arXiv:2506.21458, 2025
-
[44]
Theory of space: Can foundation models construct spatial beliefs through active exploration? InInternational Conference on Learning Rep- resentations (ICLR), 2026
Pingyue Zhang, Zihan Huang, Yue Wang, Jieyu Zhang, Letian Xue, Zihan Wang, Qineng Wang, Keshigeyan Chan- drasegaran, Ruohan Zhang, Yejin Choi, Ranjay Krishna, Ji- ajun Wu, Li Fei-Fei, and Manling Li. Theory of space: Can foundation models construct spatial beliefs through active exploration? InInternational Conference on Learning Rep- resentations (ICLR),...
2026
-
[45]
left” or “right
Training Details and Hyperparameters 7.1. Training Setup We fine-tune BAGEL-7B-MoT [12] using PyTorch FSDP (Fully Sharded Data Parallel) withbf16mixed precision on 8 NVIDIA A100 80 GB GPUs. Table 7 summarizes the key hyperparameters. System prompts.All training modes share one of two sys- tem prompts prepended to every input: •Thinking prompt(used for IPT...
-
[46]
Which object can you see on your{side}at way- point M1?
Data Curation Details 8.1. Path Tracing We generate path tracing data from two sources: AI2- THOR (synthetic) and Matterport3D (real-world). 8.1.1. AI2-THOR Scene selection.We use 120 standard iTHOR [20] scenes spanning four room types (kitchens, living rooms, bed- rooms, bathrooms), with 30 scenes per type, split into train (20), val (5), and test (5) pe...
-
[47]
Determine which image is the reference point in the question
-
[48]
If the reference is the second image, invert the direction in the answer
-
[49]
right”→“left
Using the final motion FROM first TO second, create a generation prompt. INVERSION EXAMPLES: •“right”→“left” •“left”→“right” •“front”→“back” •“back”→“front” •“front left”→“back right” •“back right”→“front left” Your output should start with “generate” and describe viewing the scene from the new camera position after applying the motion from the first imag...
-
[50]
Table 10 provides the full per-split breakdown for both AI2-THOR (EgoDir, Path, PathArr) and different-environment (Real, Real+Arr) benchmarks
Additional Results Table 2 in the main paper reports path tracing accu- racy averaged across input settings. Table 10 provides the full per-split breakdown for both AI2-THOR (EgoDir, Path, PathArr) and different-environment (Real, Real+Arr) benchmarks
-
[51]
X” and the ground-truth novel viewpoint after moving to “X
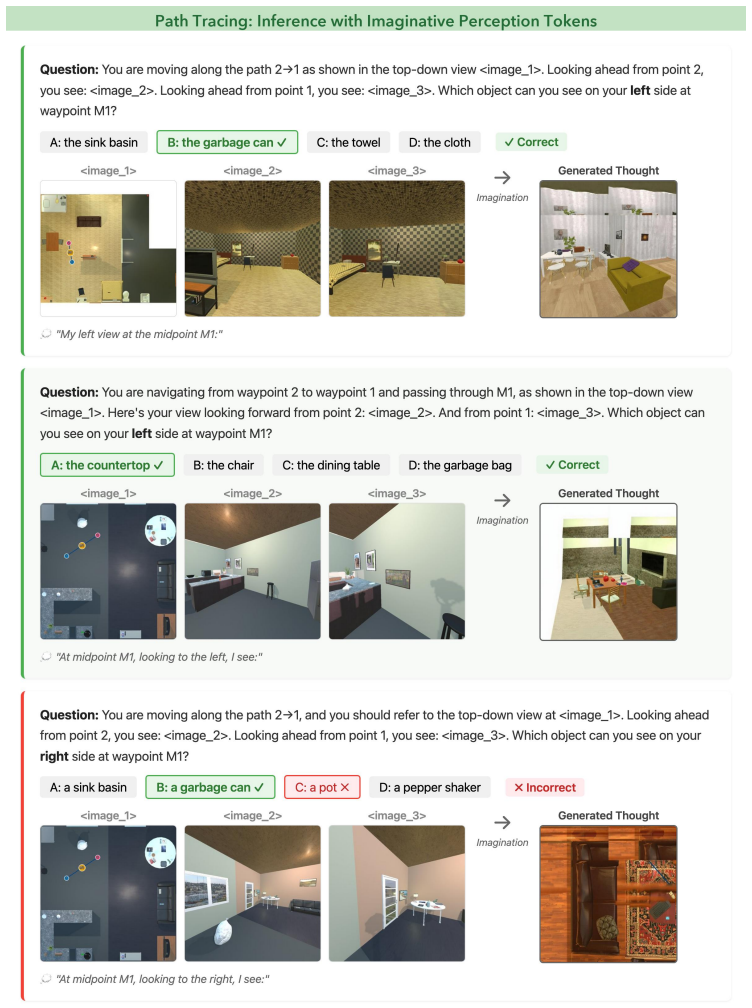
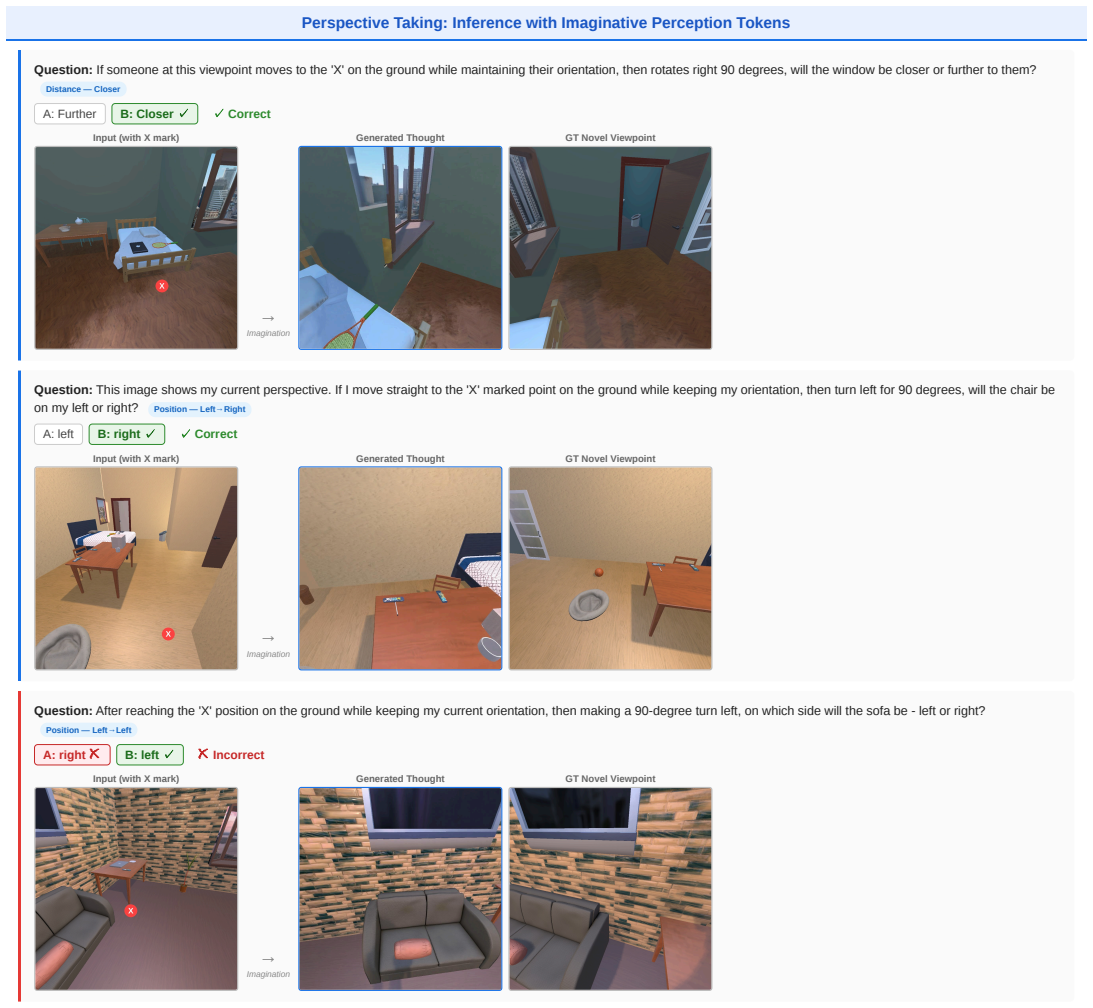
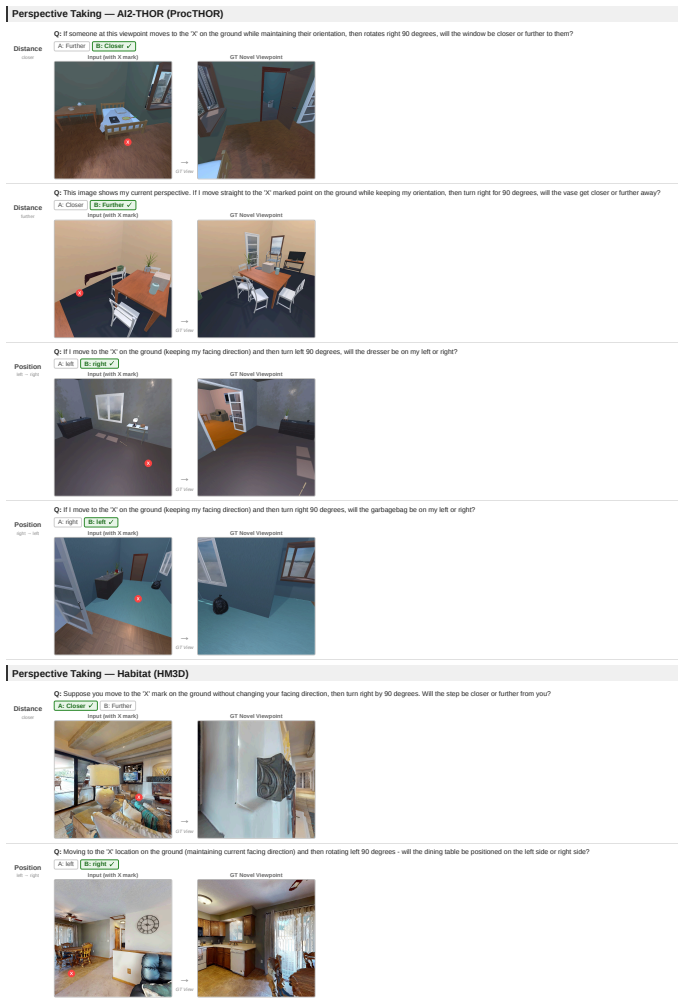
Visualizations 10.1. Path Tracing Inference with imaginative perception.Figure 4 shows examples of path tracing inference with imaginative percep- tion tokens in the EgoDir setting. Path tracing presents a particularly challenging imagination target: the model must synthesize a first-person sideview at midpointM 1 from a top-down map and two egocentric en...
-
[52]
The top-down view of this area is:
Imaginative Token Exploration with Dif- ferent VLMs Prior to adopting unified models like BAGEL for imagi- native perception token generation, we investigated adding 9 Table 10.Path tracing per-split results.Accuracy (%) broken down by input setting. The main paper reports the average across these splits. For our models, accuracy reports the maximum betwe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.