LiftQuant: Continuous Bit-Width LLM via Dimensional Lifting and Projection
Pith reviewed 2026-06-30 11:14 UTC · model grok-4.3
The pith
LiftQuant achieves continuous non-integer bit-widths for LLMs by lifting weight vectors to a higher dimension, applying 1-bit quantization there, and projecting the result back to the original space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
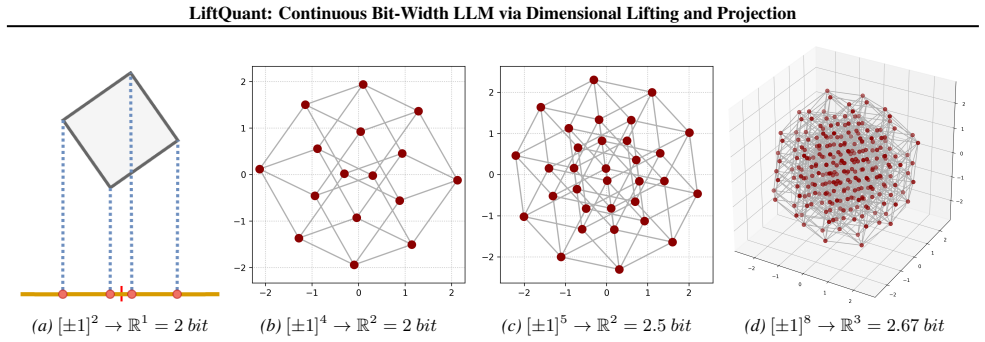
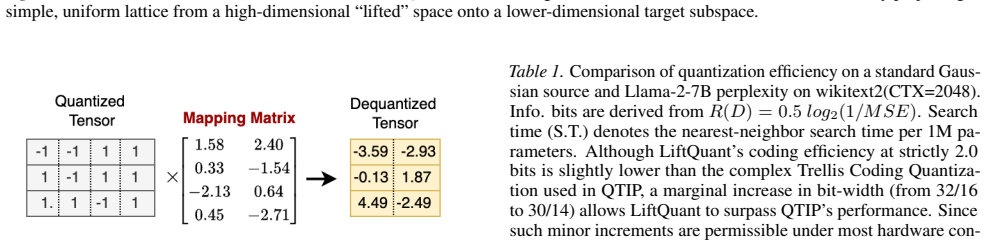
The paper establishes that low-dimensional weight vectors can be approximated by first embedding them in a higher-dimensional space, replacing each coordinate with a 1-bit value drawn from a uniform lattice, and then projecting the lifted vector back to the original dimension; the ratio of the two dimensions directly sets the effective bit-width, which can therefore be chosen quasi-continuously. This lift-then-project step generates a non-uniform yet structured codebook that retains the representational power of vector quantization, while the decoding operations remain limited to linear maps and 1-bit uniform quantizers.
What carries the argument
The lift-then-project mechanism, whose effective bit-width equals the ratio of lifted dimension to original dimension.
If this is right
- Bit-width can be set to any rational value determined by the dimension ratio rather than only integers.
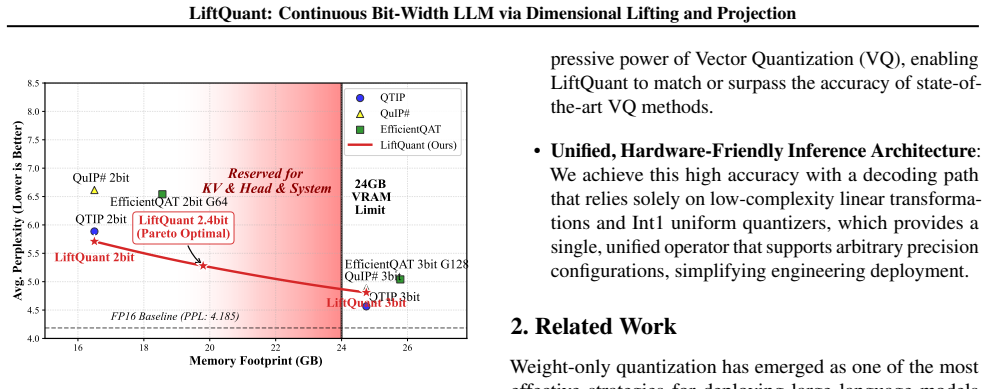
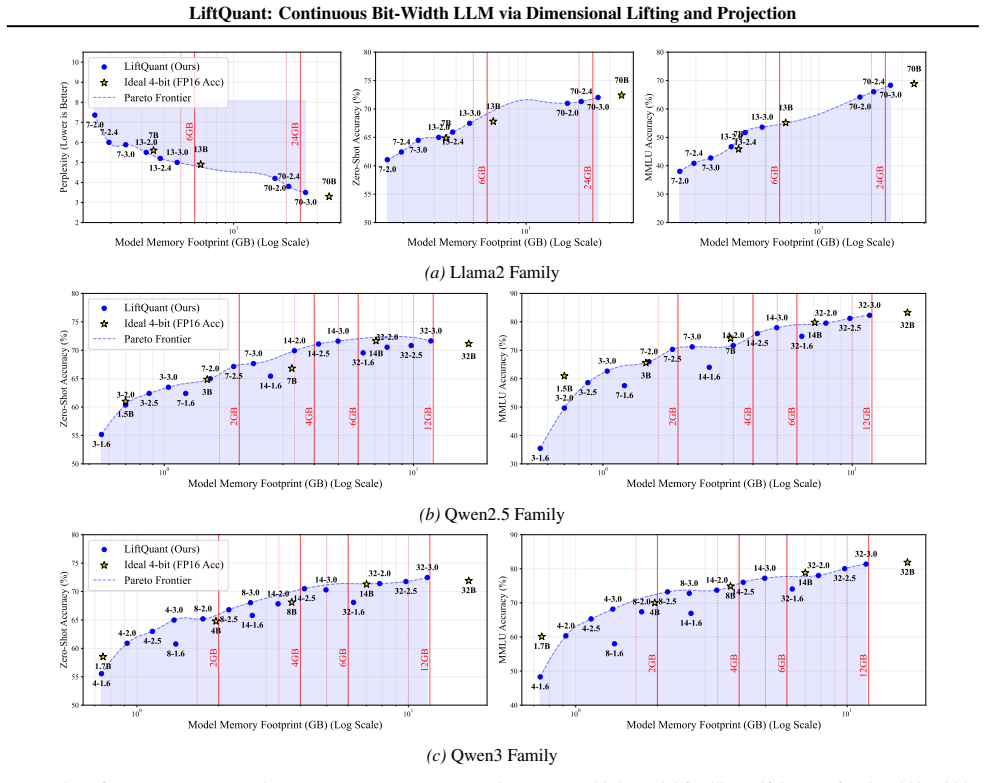
- A 70B model fits inside a 24 GB GPU at 2.4 bits and exceeds the accuracy of 2-bit baselines on the same hardware.
- The decode path requires only linear transformations and 1-bit uniform quantizers, preserving hardware compatibility.
- The generated codebook is non-uniform and structured, matching the expressiveness of vector quantization without its typical overhead.
- Memory budgets can be matched exactly instead of forcing the model into the next lower integer bit-width.
Where Pith is reading between the lines
- The same dimension-ratio control could be applied to vision or multimodal models to achieve fine-grained memory fitting on edge hardware.
- Because the lifted lattice is always 1-bit, the method might combine with existing integer quantization pipelines without new low-level kernels.
- If the projection fidelity scales with dimension ratio, one could derive an explicit error bound that predicts the minimal lift needed for a target accuracy drop.
Load-bearing premise
Projecting the higher-dimensional 1-bit lattice points back to the original space preserves enough of the original weight vectors' geometry that downstream model accuracy stays competitive.
What would settle it
Measure whether a 70B-parameter model quantized to exactly 2.4 bits with LiftQuant attains higher zero-shot or few-shot accuracy on standard LLM benchmarks than any published 2-bit method when both are constrained to run inside a 24 GB GPU memory envelope.
Figures
read the original abstract
Existing quantization methods are fundamentally limited by rigid, integer-based bit-widths (e.g., 2, 3-bit), resulting in a ``deployment gap" where Large Language Models cannot be optimally fitted to specific memory budgets. To bridge this gap, we introduce LiftQuant, a novel framework that enables continuous bit-width control for true Pareto-optimal deployment. The core innovation is a ``lift-then-project" mechanism which approximates low-dimensional weight vectors by projecting a simple 1-bit lattice from a higher-dimensional ``lifted" space. Crucially, the effective bit-width is determined simply by the ratio of the lifted dimension to the original dimension, which allows the bit-width to be tuned quasi-continuous as the dimension is a flexible structural parameter. This projection generates a structured yet non-uniform codebook, capturing the expressive power of Vector Quantization (VQ). While beneficial over VQ, LiftQuant's decoding path relies solely on linear transformations and 1-bit uniform quantizers, retaining hardware-friendly nature. This flexibility is transformative: LiftQuant enables a 70B LLM to be compressed to 2.4 bits to precisely fit a 24GB GPU, where its performance significantly surpasses state-of-the-art 2-bit models fitted on the same device. Our code and ckpt is available at https://github.com/Heliulu/LiftQuant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LiftQuant, a quantization framework for LLMs enabling continuous (quasi-continuous) bit-widths via a lift-then-project mechanism: low-dimensional weights are approximated by lifting to a higher-dimensional space, applying a simple 1-bit lattice, and projecting back. The effective bit-width is defined directly as the structural ratio of lifted to original dimension. The abstract asserts that this yields a structured non-uniform codebook with VQ-like expressiveness while remaining hardware-friendly (linear transforms + 1-bit uniform quantizers), and specifically claims that a 70B model can be compressed to exactly 2.4 bits to fit a 24GB GPU with performance significantly exceeding state-of-the-art 2-bit baselines on the same device.
Significance. If the lift-then-project approximation can be shown to preserve sufficient fidelity for 70B-scale weights without hidden capacity loss, the method would address a genuine deployment gap by allowing Pareto-optimal fitting to arbitrary memory budgets rather than discrete bit-widths. The hardware-friendly decoding path is a practical strength. However, the absence of any error analysis, projection construction details, or performance data in the manuscript text prevents assessment of whether the non-uniform codebook actually captures the required expressiveness.
major comments (2)
- [Abstract] Abstract (performance claim): the assertion that the 2.4-bit 70B model 'significantly surpasses state-of-the-art 2-bit models fitted on the same device' is presented without any quantitative results, perplexity numbers, task scores, ablation studies, or error bounds. This directly undermines evaluation of the central claim that the projection from the lifted 1-bit lattice approximates original weight vectors with fidelity sufficient to avoid degradation at 70B scale.
- [Abstract] Abstract (mechanism): the lift-then-project operation is described at a high level but supplies no explicit construction of the linear transforms, no bound on approximation error relative to vector quantization, and no analysis showing that the resulting codebook remains expressive for the empirical distribution of LLM weights. Without these, it is impossible to verify that the dimension-ratio definition of bit-width produces a faithful approximation rather than an uncontrolled capacity reduction.
minor comments (1)
- [Abstract] Abstract: 'Our code and ckpt is available' contains a subject-verb agreement error ('is' should be 'are').
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract (performance claim): the assertion that the 2.4-bit 70B model 'significantly surpasses state-of-the-art 2-bit models fitted on the same device' is presented without any quantitative results, perplexity numbers, task scores, ablation studies, or error bounds. This directly undermines evaluation of the central claim that the projection from the lifted 1-bit lattice approximates original weight vectors with fidelity sufficient to avoid degradation at 70B scale.
Authors: The referee correctly notes that the abstract states a performance claim without accompanying numbers. The current manuscript text does not embed the supporting quantitative results (perplexity, task scores) directly alongside the abstract claim. We will revise the abstract to include key quantitative highlights drawn from the experimental evaluations, ensuring the claim is substantiated within the summary itself. revision: yes
-
Referee: [Abstract] Abstract (mechanism): the lift-then-project operation is described at a high level but supplies no explicit construction of the linear transforms, no bound on approximation error relative to vector quantization, and no analysis showing that the resulting codebook remains expressive for the empirical distribution of LLM weights. Without these, it is impossible to verify that the dimension-ratio definition of bit-width produces a faithful approximation rather than an uncontrolled capacity reduction.
Authors: We agree that the abstract description is high-level and that explicit construction details, error bounds relative to VQ, and expressiveness analysis are absent from the manuscript text. The methods section provides a conceptual description of the lifting and projection but does not include the requested formal analysis. In revision we will expand the mechanism description with explicit linear transform construction and add a dedicated analysis subsection addressing approximation error and codebook properties for LLM weight distributions. revision: yes
Circularity Check
No circularity; bit-width defined structurally by dimension ratio with independent empirical claims
full rationale
The paper's central mechanism defines effective bit-width explicitly as the structural ratio of lifted dimension to original dimension, which is a definitional choice for achieving continuous control rather than a fitted or predicted quantity derived from performance data. No load-bearing step reduces by construction to self-citation, ansatz smuggling, or tautological equivalence (e.g., no 'prediction' of approximation fidelity that is forced by the input definition itself). The lift-then-project is presented as an innovation whose downstream performance superiority is asserted empirically, without the derivation chain collapsing to its own inputs. This is the most common honest outcome for papers whose core contribution is a new parameterization rather than a closed-form derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- lifted dimension
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[10]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[11]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[12]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
ArXiv , year=
Qwen Technical Report , author=. ArXiv , year=
-
[14]
ArXiv , year=
The Llama 3 Herd of Models , author=. ArXiv , year=
-
[15]
ArXiv , year=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. ArXiv , year=
-
[16]
ArXiv , year=
DeepSeek-V3 Technical Report , author=. ArXiv , year=
-
[17]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
ArXiv , year=
Up or Down? Adaptive Rounding for Post-Training Quantization , author=. ArXiv , year=
-
[19]
ArXiv , year=
BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction , author=. ArXiv , year=
-
[20]
2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
NoisyQuant: Noisy Bias-Enhanced Post-Training Activation Quantization for Vision Transformers , author=. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2023
-
[21]
ArXiv , year=
FBQuant: FeedBack Quantization for Large Language Models , author=. ArXiv , year=
-
[22]
ArXiv , year=
Outlier Suppression+: Accurate quantization of large language models by equivalent and optimal shifting and scaling , author=. ArXiv , year=
-
[23]
ArXiv , year=
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models , author=. ArXiv , year=
-
[24]
ArXiv , year=
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs , author=. ArXiv , year=
-
[25]
ArXiv , year=
SpinQuant: LLM quantization with learned rotations , author=. ArXiv , year=
-
[26]
ArXiv , year=
OstQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting , author=. ArXiv , year=
-
[27]
ArXiv , year=
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models , author=. ArXiv , year=
-
[28]
ArXiv , year=
AffineQuant: Affine Transformation Quantization for Large Language Models , author=. ArXiv , year=
-
[29]
Pointer Sentinel Mixture Models
Pointer sentinel mixture models , author=. arXiv preprint arXiv:1609.07843 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. arXiv preprint arXiv:1905.10044 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[32]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[33]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[34]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. arXiv preprint arXiv:1809.02789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[36]
SocialIQA: Commonsense Reasoning about Social Interactions
Socialiqa: Commonsense reasoning about social interactions , author=. arXiv preprint arXiv:1904.09728 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[37]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[38]
arXiv preprint arXiv:2410.09426 , year=
Flatquant: Flatness matters for llm quantization , author=. arXiv preprint arXiv:2410.09426 , year=
-
[39]
Proceedings of Machine Learning and Systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of Machine Learning and Systems , volume=
-
[40]
Advances in Neural Information Processing Systems , volume=
Duquant: Distributing outliers via dual transformation makes stronger quantized llms , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks , author=. arXiv preprint arXiv:2402.04396 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Quip: 2-bit quantization of large language models with guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
ArXiv , year=
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers , author=. ArXiv , year=
-
[44]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[45]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[46]
fast-hadamard-transform
Tri Dao. fast-hadamard-transform. 2023 , note =
2023
-
[47]
Vptq: Extreme low-bit vector post-training quantization for large language models,
Vptq: Extreme low-bit vector post-training quantization for large language models , author=. arXiv preprint arXiv:2409.17066 , year=
-
[48]
Extreme compression of large language models via additive quantization , author=. arXiv preprint arXiv:2401.06118 , year=
-
[49]
arXiv preprint arXiv:2407.11062 , year=
Efficientqat: Efficient quantization-aware training for large language models , author=. arXiv preprint arXiv:2407.11062 , year=
-
[50]
Advances in neural information processing systems , volume=
Qlora: Efficient finetuning of quantized llms , author=. Advances in neural information processing systems , volume=
-
[51]
arXiv preprint arXiv:2402.04291 , year=
Billm: Pushing the limit of post-training quantization for llms , author=. arXiv preprint arXiv:2402.04291 , year=
-
[52]
Ptq1. 61: Push the real limit of extremely low-bit post-training quantization methods for large language models , author=. arXiv preprint arXiv:2502.13179 , year=
-
[53]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[54]
18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
Ladder: Enabling efficient \ Low-Precision \ deep learning computing through hardware-aware tensor transformation , author=. 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24) , pages=
-
[55]
Advances in Neural Information Processing Systems , volume=
Qtip: Quantization with trellises and incoherence processing , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
arXiv preprint arXiv:2310.16836 , year=
Llm-fp4: 4-bit floating-point quantized transformers , author=. arXiv preprint arXiv:2310.16836 , year=
-
[57]
Alternating Multi-bit Quantization for Recurrent Neural Networks
Alternating multi-bit quantization for recurrent neural networks , author=. arXiv preprint arXiv:1802.00150 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
arXiv preprint arXiv:2506.03781 , year=
Unifying Uniform and Binary-coding Quantization for Accurate Compression of Large Language Models , author=. arXiv preprint arXiv:2506.03781 , year=
-
[59]
Journal of Machine Learning Research , volume=
Bitnet: 1-bit pre-training for large language models , author=. Journal of Machine Learning Research , volume=
-
[60]
arXiv preprint arXiv:2509.20214 , year=
Q-Palette: Fractional-Bit Quantizers Toward Optimal Bit Allocation for Efficient LLM Deployment , author=. arXiv preprint arXiv:2509.20214 , year=
-
[61]
The annals of statistics , pages=
Asymptotics of graphical projection pursuit , author=. The annals of statistics , pages=. 1984 , publisher=
1984
-
[62]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[63]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.