MorphoQuant: Modality-Aware Quantization for Omni-modal Large Language Models
Pith reviewed 2026-06-28 07:14 UTC · model grok-4.3
The pith
MorphoQuant lets 4-bit omni-modal LLMs surpass 16-bit accuracy on ScienceQA by absorbing modality-specific outliers into biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
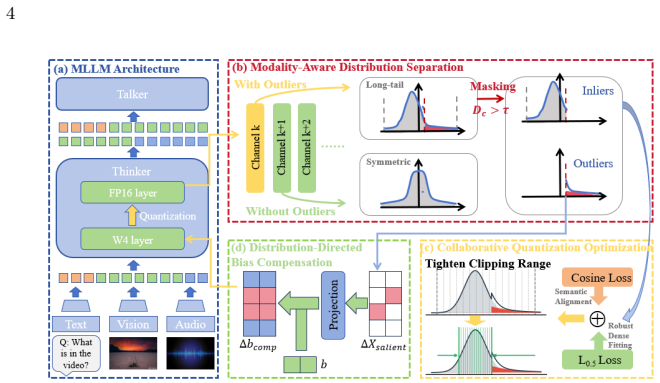
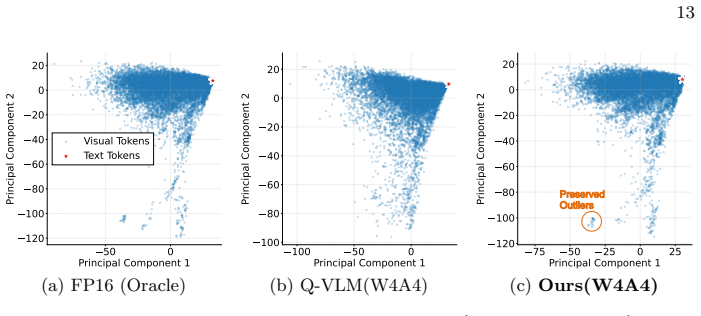
MorphoQuant is a modality-aware post-training quantization framework that preserves cross-modal morphology in omni-modal LLMs by using Distribution-Aware Bias Compensation to selectively absorb long-tailed outliers into channel-wise biases and Morphology-Directed Quantization Function Optimization to co-optimize the quantization grid with the bias mask, thereby enabling W4A4 models to outperform both state-of-the-art W4A4 methods and the W4A16 baseline on ScienceQA while maintaining performance across MMMU and Video-MME.
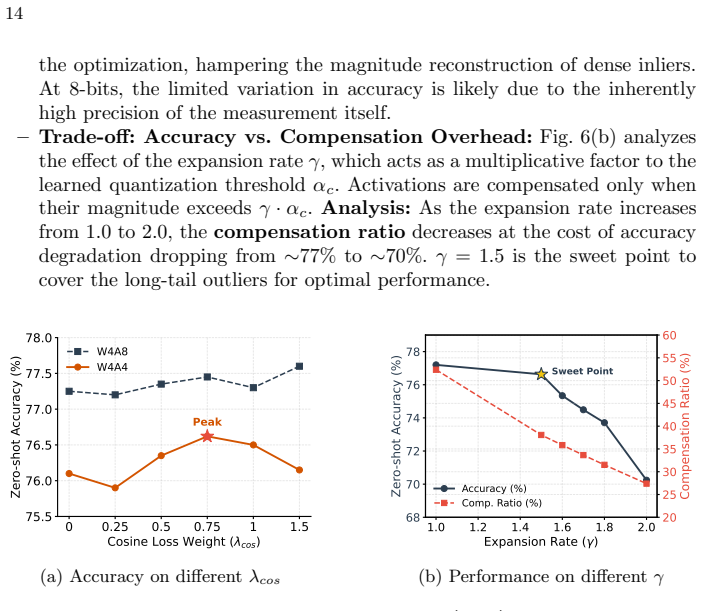
What carries the argument
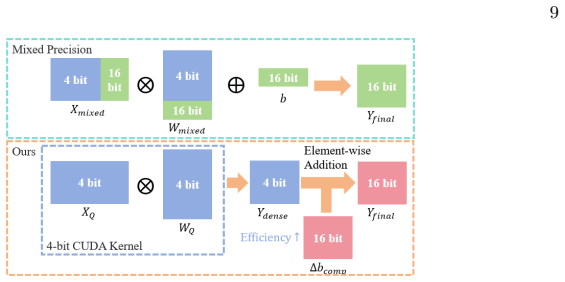
Distribution-Aware Bias Compensation (DABC) that absorbs long-tailed outliers into channel-wise biases, paired with Morphology-Directed Quantization Function Optimization (MDQFO) that aligns the quantization grid to those biases across modalities.
If this is right
- W4A4 quantization reaches 76.63 percent on ScienceQA and exceeds the W4A16 baseline.
- The same W4A4 setting outperforms prior state-of-the-art 4-bit methods on MMMU and Video-MME.
- Cross-modal distribution heterogeneity is mitigated without retraining the base model.
- The accuracy-efficiency trade-off improves for any omni-modal LLM that exhibits similar per-modality outlier patterns.
Where Pith is reading between the lines
- The same bias-absorption step could be tested on other multimodal architectures that mix vision, audio, and text to check whether the modality-specific handling generalizes.
- If the method scales to even lower bit widths, it would directly reduce memory footprint for on-device omni-modal inference.
- The co-optimization of grid and bias mask suggests that future quantizers may need joint search procedures rather than independent per-tensor scaling.
Load-bearing premise
Absorbing long-tailed outliers into channel-wise biases and co-optimizing the quantization grid will preserve cross-modal morphology and discretization accuracy without creating new errors or modality-specific degradation.
What would settle it
If the W4A4 MorphoQuant model scores below the W4A16 baseline on ScienceQA when re-run on the same Qwen2.5-Omni checkpoint and evaluation protocol, the central performance claim is falsified.
Figures

read the original abstract
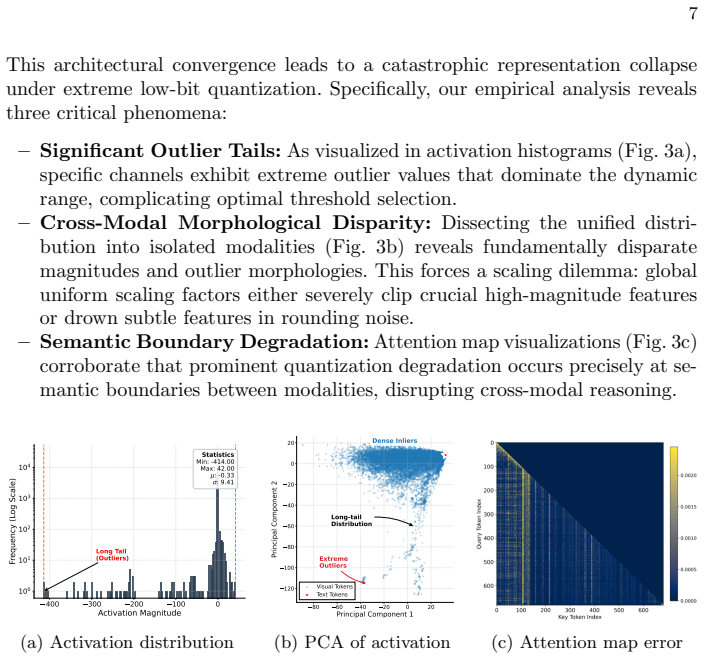
Conventional Post-Training Quantization (PTQ) methods struggle with 4-bit Omni-modal Large Language Models (OLLMs) due to the extreme distribution heterogeneity and disparate outlier patterns across modalities. To address this, we propose MorphoQuant, a modality-aware PTQ framework engineered to preserve cross-modal morphology and mitigate outlier loss. Specifically, we introduce Distribution-Aware Bias Compensation (DABC), which selectively absorbs long-tailed outliers into channel-wise biases. This mechanism safeguards outlier magnitudes while maintaining high-precision discretization for dense inliers, thereby preserving accurate discretization across diverse modal distribution. Complementing this, we propose Morphology-Directed Quantization Function Optimization (MDQFO) to co-optimize the quantization grid with the bias mask, ensuring fine-grained alignment across modalities. Extensive evaluations on Qwen2.5-Omni across benchmarks like MMMU and Video-MME demonstrate our approach's superiority. Notably, our W4A4 model achieves 76.63% on ScienceQA, significantly outperforming SOTA W4A4 methods and surprisingly surpassing the W4A16 baseline, which fully demonstrates the exceptional accuracy-efficiency trade-off of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MorphoQuant, a modality-aware post-training quantization (PTQ) framework for omni-modal large language models. It introduces Distribution-Aware Bias Compensation (DABC) to selectively absorb long-tailed outliers into channel-wise biases and Morphology-Directed Quantization Function Optimization (MDQFO) to co-optimize the quantization grid with the bias mask. The central empirical claim is that the resulting W4A4 model on Qwen2.5-Omni reaches 76.63% on ScienceQA, outperforming both prior SOTA W4A4 methods and the W4A16 baseline while also showing gains on MMMU and Video-MME.
Significance. If the DABC/MDQFO mechanisms can be shown to preserve inlier discretization fidelity and cross-modal interactions without introducing new modality-specific errors, the work would be significant for practical deployment of omni-modal LLMs. The reported outperformance of a 4-bit model over a 16-bit baseline is a strong result if the supporting formulations, ablations, and error analysis are provided.
major comments (2)
- [Abstract] Abstract: the headline claim that W4A4 reaches 76.63% on ScienceQA and surpasses the W4A16 baseline is load-bearing for the accuracy-efficiency argument, yet the abstract supplies no explicit update rule for the bias mask in DABC, no objective function for MDQFO, and no derivation showing that outlier absorption is norm-preserving; without these the observed gain cannot be attributed to improved quantization rather than an artifact of bias injection.
- [Method] Method section (DABC/MDQFO): the assumption that selectively absorbing long-tailed outliers into channel-wise biases and co-optimizing the grid preserves cross-modal morphology and accurate inlier discretization is central but unsupported by any stated proof, norm-preservation argument, or ablation isolating the contribution of each component from potential side-effects.
minor comments (2)
- [Abstract] Abstract: the terms 'cross-modal morphology' and 'modality-aware' are used without operational definition or reference to prior usage.
- [Abstract] Abstract: 'W4A4' and 'W4A16' should be defined on first use rather than assumed known.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the theoretical foundations and empirical isolation of our proposed components. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that W4A4 reaches 76.63% on ScienceQA and surpasses the W4A16 baseline is load-bearing for the accuracy-efficiency argument, yet the abstract supplies no explicit update rule for the bias mask in DABC, no objective function for MDQFO, and no derivation showing that outlier absorption is norm-preserving; without these the observed gain cannot be attributed to improved quantization rather than an artifact of bias injection.
Authors: We agree the abstract's brevity omits explicit equations. The bias-mask update rule appears in Eq. (2), the MDQFO objective in Eq. (4), and the norm-preservation argument via selective absorption is derived in Sec. 3.1. Ablations in Sec. 4.3 and error analysis in Sec. 4.4 attribute gains to the mechanisms rather than bias artifacts. We will revise the abstract to reference these elements concisely while preserving length constraints. revision: partial
-
Referee: [Method] Method section (DABC/MDQFO): the assumption that selectively absorbing long-tailed outliers into channel-wise biases and co-optimizing the grid preserves cross-modal morphology and accurate inlier discretization is central but unsupported by any stated proof, norm-preservation argument, or ablation isolating the contribution of each component from potential side-effects.
Authors: The manuscript already provides component-wise ablations (Table 2, Fig. 5) isolating DABC and MDQFO contributions, plus modality-specific error breakdowns in Sec. 4.4 showing preserved inlier fidelity and cross-modal consistency. While a formal proof is absent, we will add a short norm-preservation derivation based on the bias-compensation formulation and expand the ablation discussion to explicitly rule out side-effects. revision: yes
Circularity Check
No circularity: claims rest on empirical benchmarks, not self-referential definitions or fitted inputs
full rationale
The paper introduces DABC and MDQFO as new PTQ components for handling modality-specific distributions and outliers in OLLMs, then reports concrete benchmark numbers (e.g., W4A4 at 76.63% on ScienceQA). No equation or step is shown to define a quantity in terms of itself, rename a fitted parameter as a prediction, or rely on a self-citation chain whose prior result is unverified. The derivation chain consists of proposed algorithmic mechanisms whose validity is asserted via external evaluation rather than by construction from the target metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., et al.: Qwen3-omni technical report. arXiv preprint arXiv:2509.17765 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V.I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al.: Gemini 1.5: Unlocking multimodal un- derstanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Visual Intelligence 3(1) (2025) 27
Jin, Y., Li, J., Gu, T., Liu, Y., Zhao, B., Lai, J., Gan, Z., Wang, Y., Wang, C., Tan, X., et al.: Efficient multimodal large language models: A survey. Visual Intelligence 3(1) (2025) 27
2025
-
[5]
arXiv preprint arXiv:2404.07214 (2024)
Ghosh, A., Acharya, A., Saha, S., Jain, V., Chadha, A.: Exploring the frontier of vision-language models: A survey of current methodologies and future directions. arXiv preprint arXiv:2404.07214 (2024)
-
[6]
Findings of the association for computational linguistics: ACL 2024 (2024) 13590– 13618
Caffagni, D., Cocchi, F., Barsellotti, L., Moratelli, N., Sarto, S., Baraldi, L., Cornia, M., Cucchiara, R.: The revolution of multimodal large language models: A survey. Findings of the association for computational linguistics: ACL 2024 (2024) 13590– 13618
2024
-
[7]
IEEE Transactions on Pattern Analysis and Machine Intelligence45(10) (2023) 12113–12132
Xu, P., Zhu, X., Clifton, D.A.: Multimodal learning with transformers: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence45(10) (2023) 12113–12132
2023
-
[8]
IEEE Access (2025)
Bhuyan, M.S.M., Hossain, E., Sathi, K.A., Hossain, M.A., Dewan, M.A.A.: Bvqa: connecting language and vision through multimodal attention for open-ended ques- tion answering. IEEE Access (2025)
2025
-
[9]
arXiv preprint arXiv:2505.05108 (2025)
Feng, Z., Xue, R., Yuan, L., Yu, Y., Ding, N., Liu, M., Gao, B., Sun, J., Zheng, X., Wang, G.: Multi-agent embodied ai: Advances and future directions. arXiv preprint arXiv:2505.05108 (2025)
-
[10]
arXiv preprint arXiv:2508.08706 (2025)
Cheng, Z., Zhang, Y., Zhang, W., Li, H., Wang, K., Song, L., Zhang, H.: Omnivtla: Vision-tactile-language-action model with semantic-aligned tactile sensing. arXiv preprint arXiv:2508.08706 (2025)
-
[11]
Artificial Intelligence Review58(12) (2025) 403
Liu, Y., Cao, J., Liu, C., Ding, K., Jin, L.: Datasets for large language models: A comprehensive survey. Artificial Intelligence Review58(12) (2025) 403
2025
-
[12]
arXiv preprint arXiv:2408.08632 (2024)
Li, J., Lu, W., Fei, H., Luo, M., Dai, M., Xia, M., Jin, Y., Gan, Z., Qi, D., Fu, C., et al.: A survey on benchmarks of multimodal large language models. arXiv preprint arXiv:2408.08632 (2024)
-
[13]
Advances in Neural Information Processing Systems 36(2023) 26650–26685
Yin, Z., Wang, J., Cao, J., Shi, Z., Liu, D., Li, M., Huang, X., Wang, Z., Sheng, L., Bai, L., et al.: Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. Advances in Neural Information Processing Systems 36(2023) 26650–26685
2023
-
[14]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Ye, W., Wu, Q., Lin, W., Zhou, Y.: Fit and prune: Fast and training-free visual token pruning for multi-modal large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. Volume 39. (2025) 22128–22136
2025
-
[15]
arXiv preprint arXiv:2401.16160 (2024)
Chen, S., Jie, Z., Ma, L.: Llava-mole: Sparse mixture of lora experts for mitigating data conflicts in instruction finetuning mllms. arXiv preprint arXiv:2401.16160 (2024)
-
[16]
arXiv preprint arXiv:2401.00625 (2024) 16
Bai, G., Chai, Z., Ling, C., Wang, S., Lu, J., Zhang, N., Shi, T., Yu, Z., Zhu, M., Zhang, Y., et al.: Beyond efficiency: A systematic survey of resource-efficient large language models. arXiv preprint arXiv:2401.00625 (2024) 16
-
[17]
In: Inter- national conference on machine learning, PMLR (2023) 38087–38099
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., Han, S.: Smoothquant: Accu- rate and efficient post-training quantization for large language models. In: Inter- national conference on machine learning, PMLR (2023) 38087–38099
2023
-
[18]
Proceedings of machine learning and systems6 (2024) 87–100
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.M., Wang, W.C., Xiao, G., Dang, X., Gan, C., Han, S.: Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of machine learning and systems6 (2024) 87–100
2024
-
[19]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Xie, J., Zhang, Y., Lin, M., Cao, L., Ji, R.: Advancing multimodal large lan- guage models with quantization-aware scale learning for efficient adaptation. In: Proceedings of the 32nd ACM International Conference on Multimedia. (2024) 10582–10591
2024
-
[21]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Yu, J., Zhou, S., Yang, D., Li, S., Wang, S., Hu, X., Xu, C., Xu, Z., Shu, C., Yuan, Z.: Mquant: Unleashing the inference potential of multimodal large language models via static quantization. In: Proceedings of the 33rd ACM International Conference on Multimedia. (2025) 1783–1792
2025
-
[22]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Wang, C., Wang, Z., Xu, X., Tang, Y., Zhou, J., Lu, J.: Towards accurate post- training quantization for diffusion models. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. (2024) 16026–16035
2024
-
[23]
Advances in Neural Information Processing Systems37(2024) 114553–114573
Wang, C., Wang, Z., Xu, X., Tang, Y., Zhou, J., Lu, J.: Q-vlm: Post-training quantization for large vision-language models. Advances in Neural Information Processing Systems37(2024) 114553–114573
2024
-
[24]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report (2025)
2025
-
[25]
Visual Intelligence2(1) (2024) 36
Huang, W., Zheng, X., Ma, X., Qin, H., Lv, C., Chen, H., Luo, J., Qi, X., Liu, X., Magno, M.: An empirical study of llama3 quantization: From llms to mllms. Visual Intelligence2(1) (2024) 36
2024
-
[26]
int8 (): 8-bit matrix multiplication for transformers at scale
Dettmers, T., Lewis, M., Belkada, Y., Zettlemoyer, L.: Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems35(2022) 30318–30332
2022
-
[27]
arXiv preprint arXiv:2306.03078 (2023)
Dettmers, T., Svirschevski, R., Egiazarian, V., Kuznedelev, D., Frantar, E., Ashk- boos, S., Borzunov, A., Hoefler, T., Alistarh, D.: Spqr: A sparse-quantized repre- sentation for near-lossless llm weight compression. arXiv preprint arXiv:2306.03078 (2023)
-
[28]
Proceedings of Machine Learning and Systems6(2024) 196–209
Zhao, Y., Lin, C.Y., Zhu, K., Ye, Z., Chen, L., Zheng, S., Ceze, L., Krishnamurthy, A., Chen, T., Kasikci, B.: Atom: Low-bit quantization for efficient and accurate llm serving. Proceedings of Machine Learning and Systems6(2024) 196–209
2024
-
[29]
Ad- vances in neural information processing systems35(2022) 27168–27183
Yao, Z., Yazdani Aminabadi, R., Zhang, M., Wu, X., Li, C., He, Y.: Zeroquant: Efficient and affordable post-training quantization for large-scale transformers. Ad- vances in neural information processing systems35(2022) 27168–27183
2022
-
[30]
arXiv preprint arXiv:2006.16669 (2020)
Wu, D., Tang, Q., Zhao, Y., Zhang, M., Fu, Y., Zhang, D.: Easyquant: Post-training quantization via scale optimization. arXiv preprint arXiv:2006.16669 (2020)
-
[31]
Huang, W., Liu, Y., Qin, H., Li, Y., Zhang, S., Liu, X., Magno, M., Qi, X.: Billm: Pushing the limit of post-training quantization for llms. arXiv preprint arXiv:2402.04291 (2024)
-
[32]
Advances in neural information processing systems36 (2023) 10088–10115 17
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: Qlora: Efficient fine- tuning of quantized llms. Advances in neural information processing systems36 (2023) 10088–10115 17
2023
-
[33]
Shao, W., Chen, M., Zhang, Z., Xu, P., Zhao, L., Li, Z., Zhang, K., Gao, P., Qiao, Y., Luo, P.: Omniquant: Omnidirectionally calibrated quantization for large language models. arXiv preprint arXiv:2308.13137 (2023)
-
[34]
SpinQuant: LLM quantization with learned rotations
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Krishnamoorthi, R., Chan- dra, V., Tian, Y., Blankevoort, T.: Spinquant: Llm quantization with learned rotations. arXiv preprint arXiv:2405.16406 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery15(3) (2025) e70036
Shinde, G., Ravi, A., Dey, E., Sakib, S., Rampure, M., Roy, N.: A survey on efficient vision-language models. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery15(3) (2025) e70036
2025
-
[36]
Bi-vlm: Pushing ultra-low precision post-training quantization boundaries in vision-language models
Wang, X., Huang, J., Abdalla, R., Zhang, C., Xian, R., Manocha, D.: Bi-vlm: Push- ing ultra-low precision post-training quantization boundaries in vision-language models. arXiv preprint arXiv:2509.18763 (2025)
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, S., Hu, Y., Ning, X., Liu, X., Hong, K., Jia, X., Li, X., Yan, Y., Ran, P., Dai, G., et al.: Mbq: Modality-balanced quantization for large vision-language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. (2025) 4167–4177
2025
-
[38]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Wei, X., Zhang, Y., Li, Y., Zhang, X., Gong, R., Guo, J., Liu, X.: Outlier suppres- sion+: Accurate quantization of large language models by equivalent and effective shifting and scaling. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. (2023) 1648–1665
2023
-
[39]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language- aware vision transformer for referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. (2022) 18155– 18165
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.