MIRAGE: Mobile Agents with Implicit Reasoning and Generative World Models
Pith reviewed 2026-06-28 06:19 UTC · model grok-4.3
The pith
MIRAGE lets mobile agents reason in continuous latent space by distilling chain-of-thought traces and aligning them to future screenshots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIRAGE transfers explicit reasoning into compact hidden states and aligns those states with future screenshots via a generative world-model objective, so that inference-time reasoning occurs entirely in continuous latent space and produces fewer decoded tokens while matching or exceeding the performance of explicit chain-of-thought supervised fine-tuning.
What carries the argument
Latent reasoning vectors learned from textual traces and aligned with future screenshots through the generative objective.
If this is right
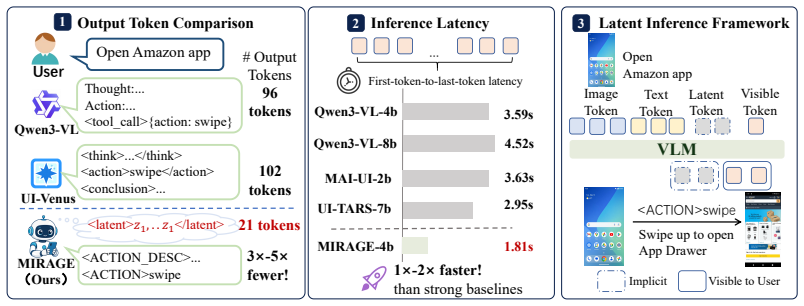
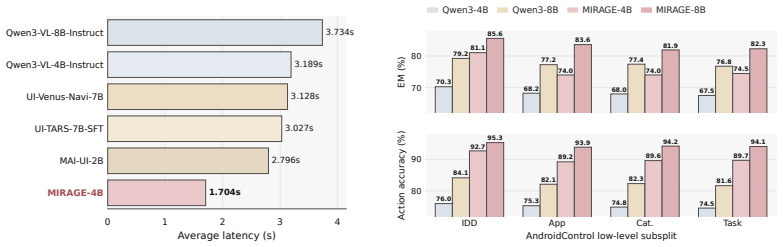
- On AndroidWorld the 4B ablation matches explicit chain-of-thought supervised fine-tuning while using a 3-5x lower decoded-token budget.
- MIRAGE improves a comparable instruction-tuned baseline by 10.2 points on AndroidWorld.
- On AndroidControl the method improves action grounding while generating over 75 percent fewer tokens.
Where Pith is reading between the lines
- The same compression of reasoning into latent vectors could be tested on web or desktop agents where screenshot sequences are also available.
- If the world-model alignment proves helpful, longer-horizon tasks may benefit most because the agent anticipates state changes before choosing actions.
- Lower visible token output could reduce the amount of human-written reasoning traces needed for supervision.
Load-bearing premise
That continuous latent reasoning vectors learned from visible textual traces are sufficient to replace explicit reasoning and that alignment with future screenshots meaningfully improves downstream action selection.
What would settle it
An ablation in which removing the generative alignment objective causes the latent-only agent to fall below the accuracy of explicit chain-of-thought fine-tuning on the same AndroidWorld or AndroidControl tasks.
Figures
read the original abstract
Mobile agents are increasingly expected to operate everyday applications from screenshots and language goals, where reliable control requires reasoning over screen affordances, multi-step navigation, and future state changes. However, many agents externalize this computation as long textual chains of thought, which slows interaction, increases supervision cost, and complicates deployment. We introduce MIRAGE, a framework that learns continuous latent reasoning representations from visible textual reasoning traces. MIRAGE transfers explicit reasoning into compact hidden states, enabling the agent to reason internally without decoding long rationales. It also incorporates a generative world-model objective: latent reasoning vectors are aligned with future screenshots, encouraging the agent to anticipate upcoming interface states before acting. This turns hidden computation into both a compressed thought representation and a forward-looking model of environment dynamics. At inference time, MIRAGE reasons in continuous latent space, reducing token generation while improving execution efficiency. On AndroidWorld, MIRAGE matches explicit chain-of-thought supervised fine-tuning in the 4B ablation with a 3-5x lower decoded-token budget and improves a comparable instruction-tuned baseline by 10.2 points; on AndroidControl, it improves action grounding while generating over 75% fewer tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MIRAGE, a framework for mobile agents operating on screenshots and language goals. It learns continuous latent reasoning representations from visible textual reasoning traces, transfers explicit reasoning into compact hidden states, and adds a generative world-model objective that aligns latent vectors with future screenshots. At inference, the agent reasons in latent space, yielding 3-5x lower decoded-token budgets while matching explicit CoT supervised fine-tuning on AndroidWorld (4B ablation) and a 10.2-point gain over an instruction-tuned baseline; on AndroidControl it improves action grounding with >75% fewer tokens.
Significance. If the empirical claims hold under full controls, the work demonstrates a practical route to compressing agent reasoning into continuous latent states while retaining (or improving) task performance. The dual use of latent vectors for both compressed thought and forward environment prediction is a concrete technical contribution that could reduce latency and supervision costs in deployed mobile agents.
minor comments (3)
- [Abstract and §4] Abstract and §4: the 4B ablation and AndroidControl token-reduction numbers are reported without accompanying standard deviations or number of runs; adding these would strengthen the efficiency claims.
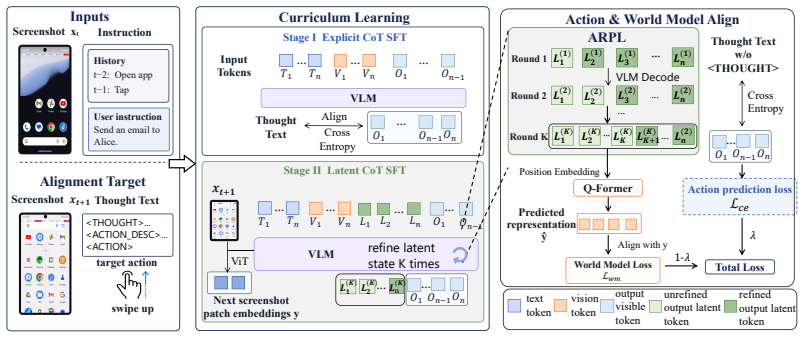
- [§3.2] §3.2: the precise form of the generative alignment loss (e.g., whether it is a reconstruction, contrastive, or next-frame prediction objective) is referenced but not written out; an explicit equation would aid reproducibility.
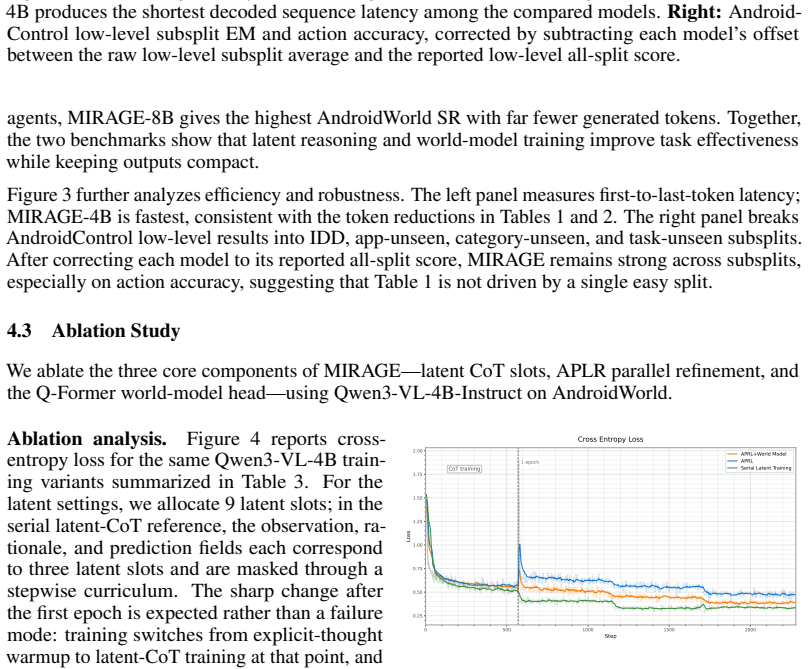
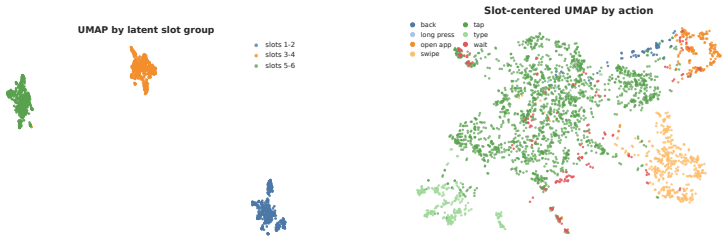
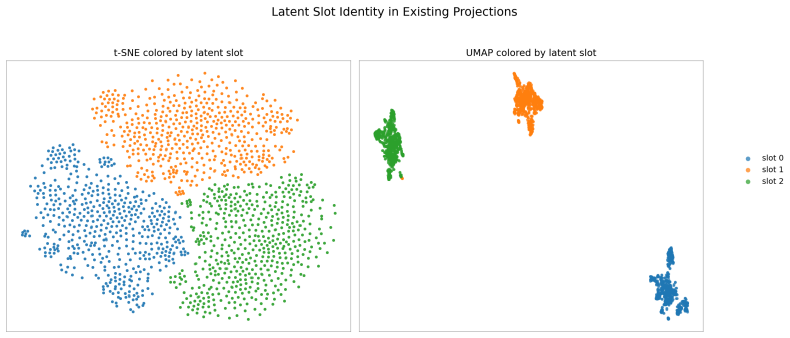
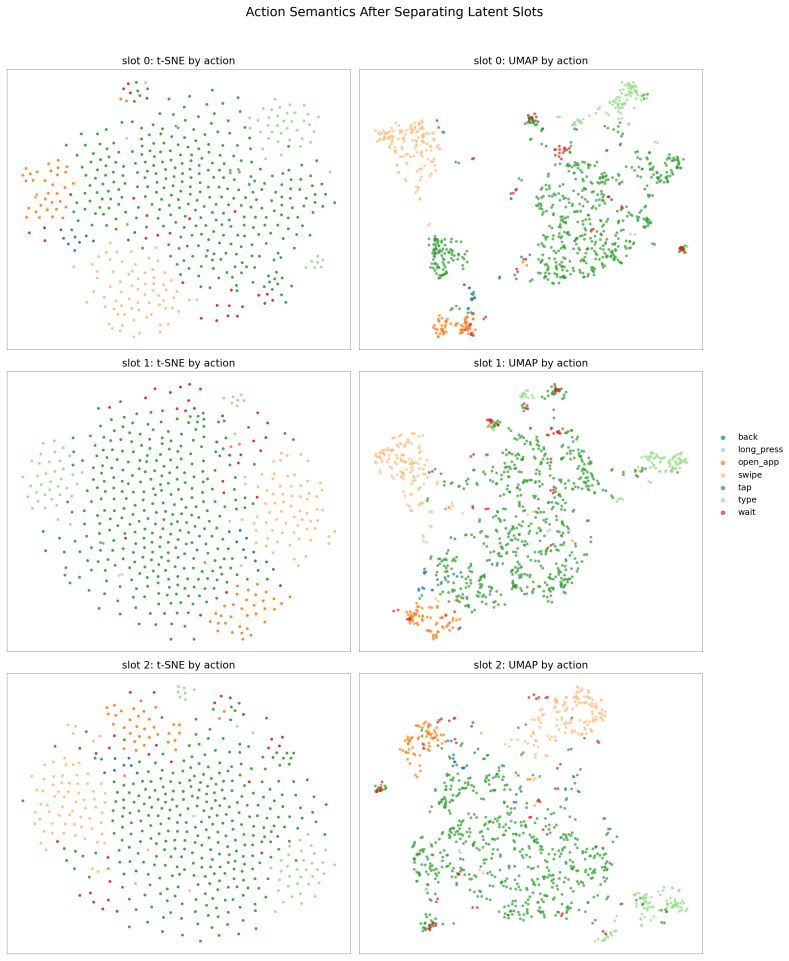
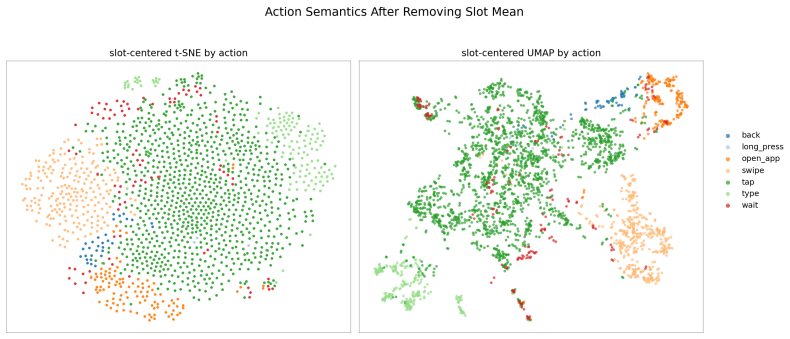
- [Figure 3 and Table 2] Figure 3 and Table 2: axis labels and legend entries use inconsistent abbreviations for the latent-reasoning and world-model variants; harmonizing notation would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. The summary accurately reflects the core ideas and empirical results of MIRAGE. No specific major comments appear in the report, so we have no point-by-point rebuttals to provide. We will incorporate any minor suggestions during revision.
Circularity Check
No significant circularity
full rationale
The provided manuscript text (abstract plus framework description) contains no equations, parameter-fitting procedures, self-citations, or derivation steps that reduce any claimed prediction or result to its inputs by construction. The core claims concern an architectural transfer of explicit reasoning traces into latent vectors plus a generative alignment objective; these are presented as design choices whose empirical outcomes (token reduction, accuracy gains) are evaluated externally rather than derived tautologically. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Hanzhang Zhou, Xu Zhang, Panrong Tong, Jianan Zhang, Liangyu Chen, Quyu Kong, Chenglin Cai, Chen Liu, Yue Wang, Jingren Zhou, et al. Mai-ui technical report: Real-world centric foundation gui agents.arXiv preprint arXiv:2512.22047, 2025
-
[3]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, et al. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Seeclick: Harnessing gui grounding for advanced visual gui agents
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9313–9332, 2024
2024
-
[5]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[6]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[7]
On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
2024
-
[8]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Mary- beth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Mobile-Agent: Autonomous Multi-Modal Mobile Device Agent with Visual Perception
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[11]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. arXiv preprint arXiv:2310.02226, 2023
-
[13]
Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
Eric Zelikman, Georges Harik, Yijia Shao, Varuna Jayasiri, Nick Haber, and Noah D Goodman. Quiet-star: Language models can teach themselves to think before speaking.arXiv preprint arXiv:2403.09629, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
arXiv preprint at arXiv:2311.01460 , year=
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
-
[15]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[18]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[19]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Yuanze Hu, Zhaoxin Fan, Xinyu Wang, Gen Li, Ye Qiu, Zhichao Yang, Wenjun Wu, Kejian Wu, Yifan Sun, Xiaotie Deng, et al. Tinyalign: Boosting lightweight vision-language models by mitigating modal alignment bottlenecks.arXiv preprint arXiv:2505.12884, 2025
-
[21]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[22]
Vimo: A generative visual gui world model for app agents
Dezhao Luo, Bohan Tang, Kang Li, Georgios Papoudakis, Jifei Song, Shaogang Gong, Jianye Hao, Jun Wang, and Kun Shao. Vimo: A generative visual gui world model for app agents. arXiv preprint arXiv:2504.13936, 2025
-
[23]
Mobiledreamer: Generative sketch world model for gui agent
Yilin Cao, Yufeng Zhong, Zhixiong Zeng, Liming Zheng, Jing Huang, Haibo Qiu, Peng Shi, Wenji Mao, and Wan Guanglu. Mobiledreamer: Generative sketch world model for gui agent. arXiv preprint arXiv:2601.04035, 2026
-
[24]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Run Luo, Lu Wang, Wanwei He, Longze Chen, Jiaming Li, and Xiaobo Xia. Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning
Zhengxi Lu, Yuxiang Chai, Yaxuan Guo, Xi Yin, Liang Liu, Hao Wang, Han Xiao, Shuai Ren, Pengxiang Zhao, Guangyi Liu, et al. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 17608–17616, 2026
2026
-
[29]
Showui: One vision-language-action model for gui visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weix- ian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language-action model for gui visual agent. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19498–19508, 2025
2025
-
[30]
Zhangxuan Gu, Zhengwen Zeng, Zhenyu Xu, Xingran Zhou, Shuheng Shen, Yunfei Liu, Beitong Zhou, Changhua Meng, Tianyu Xia, Weizhi Chen, et al. Ui-venus technical report: Building high-performance ui agents with rft.arXiv preprint arXiv:2508.10833, 2025
-
[31]
Zhen Yang, Zi-Yi Dou, Di Feng, Forrest Huang, Anh Nguyen, Keen You, Omar Attia, Yuhao Yang, Michael Feng, Haotian Zhang, et al. Ferret-ui lite: Lessons from building small on-device gui agents.arXiv preprint arXiv:2509.26539, 2025. 12
-
[32]
parallel
Yuxiang Chai, Siyuan Huang, Yazhe Niu, Han Xiao, Liang Liu, Guozhi Wang, Dingyu Zhang, Shuai Ren, and Hongsheng Li. Amex: Android multi-annotation expo dataset for mobile gui agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2138–2156, 2025. A Additional Method Details Q-Former target construction.The world-model target ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.