Identifying Gems from Roman RAPIDly
Pith reviewed 2026-06-28 07:11 UTC · model grok-4.3
The pith
Machine learning models trained on simulated transients can classify real versus bogus detections for the Roman Space Telescope.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
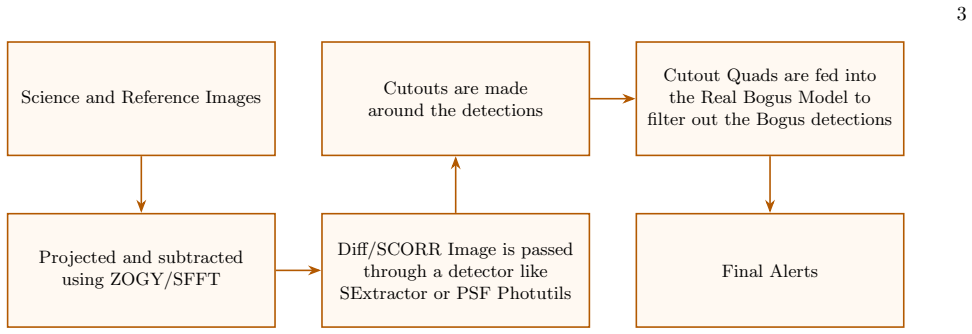
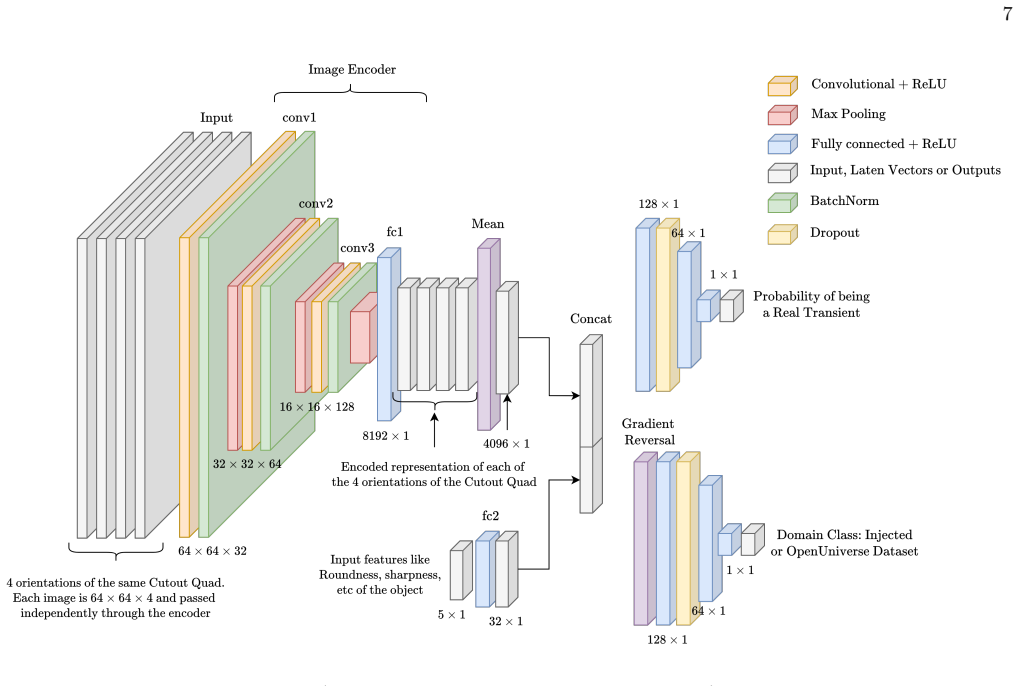
We present the RuBR model and general methodology for distinguishing genuine transient and variable detections from spurious (bogus) detections within the RAPID pipeline. We present three models using this methodology: RuBR_comb trained and tested on combined locally injected and OpenUniverse2024 transients, RuBR_loc trained on locally injected transients and tested on OpenUniverse2024 transients, and RuBR_DA that combines locally injected transients with a fraction of OpenUniverse2024 transients in domain-adaptation mode for training. This paves the way for strategies to adapt the RuBR_comb model to real observations in the absence of any ground-truth labels during the early phases of the R
What carries the argument
The RuBR family of machine learning classifiers, trained on features from simulated transient injections to perform real-bogus classification on difference images.
If this is right
- Reliable automated alerts for transients can be issued soon after Roman launch.
- Domain-adaptation training allows the model to be updated using early unlabeled real data.
- The approach scales to the millions of transients expected from Roman's wide-field surveys.
- Classification remains effective even while image differencing improvements continue.
Where Pith is reading between the lines
- The same simulation-plus-adaptation pattern may apply to other upcoming surveys that start without labeled real data.
- Performance could be further tested by injecting additional types of artifacts into the training simulations.
- Combining the classifier with improved difference imaging might reduce the overall false-positive rate beyond what either achieves alone.
Load-bearing premise
Simulated transients capture enough of the noise, artifacts, and detection characteristics that will appear in actual Roman observations.
What would settle it
Measuring the RuBR models' accuracy on the first set of real Roman difference images against human-labeled ground truth would directly test whether performance matches the simulated results.
Figures

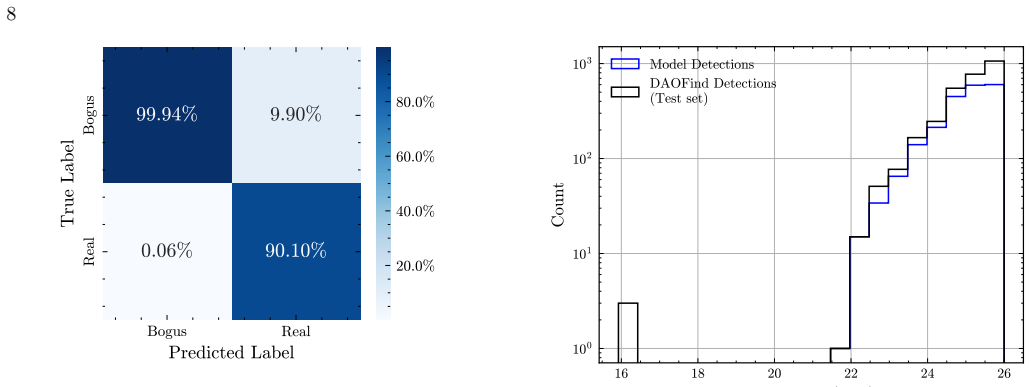
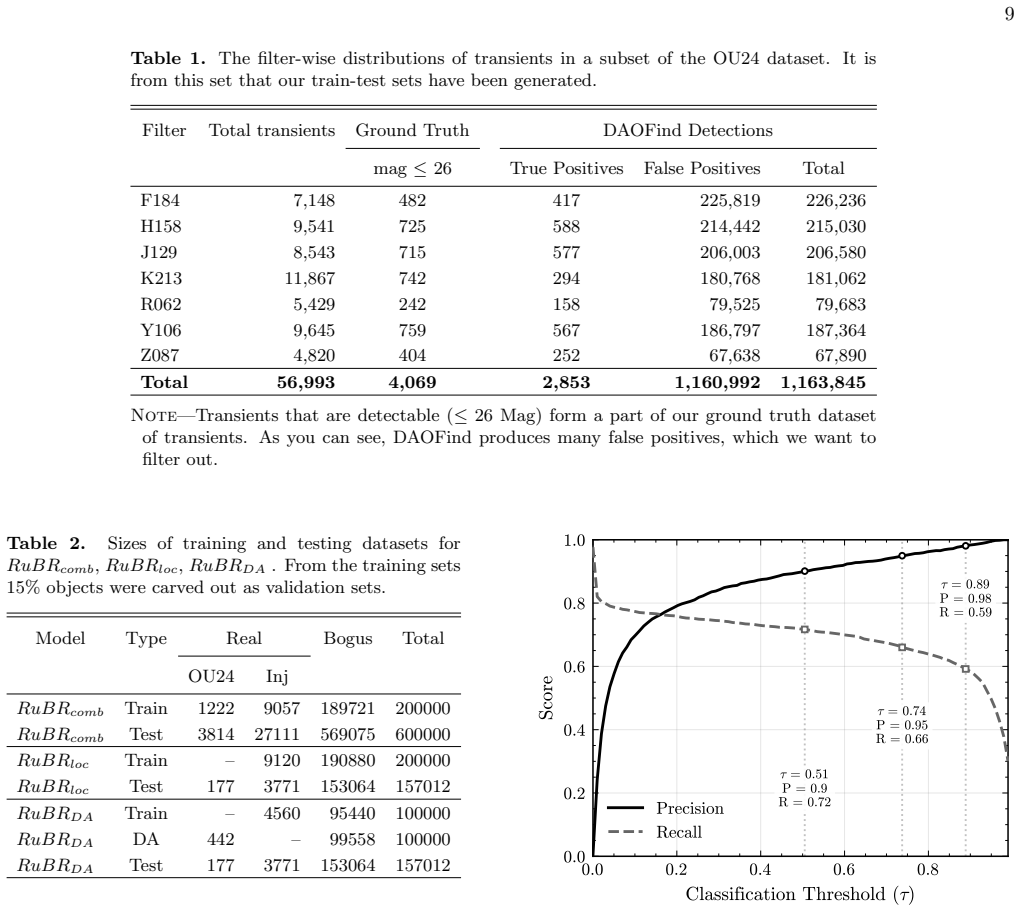
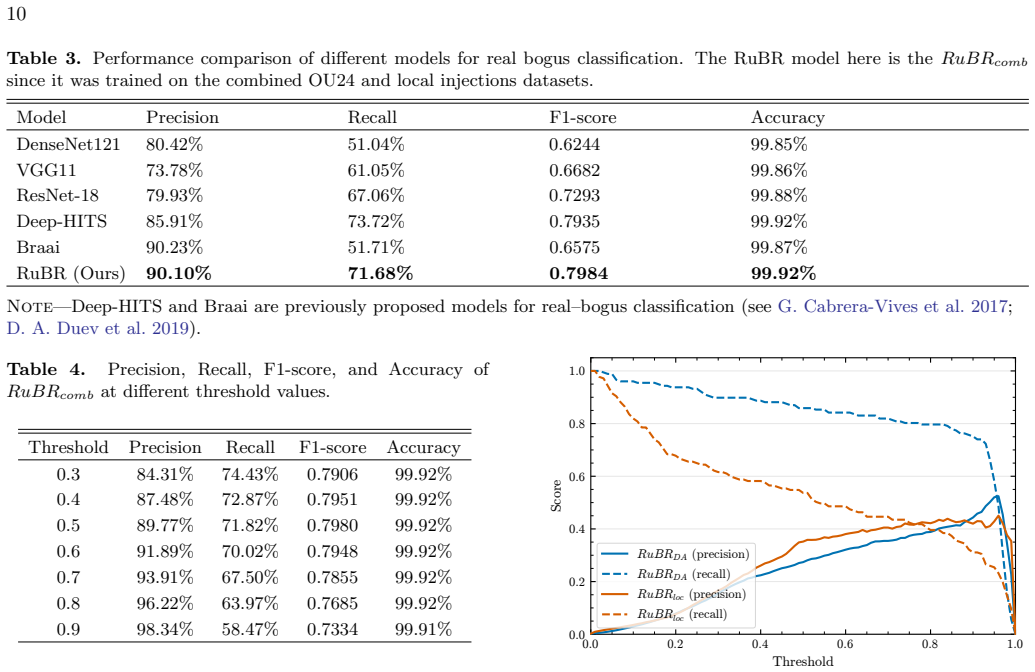
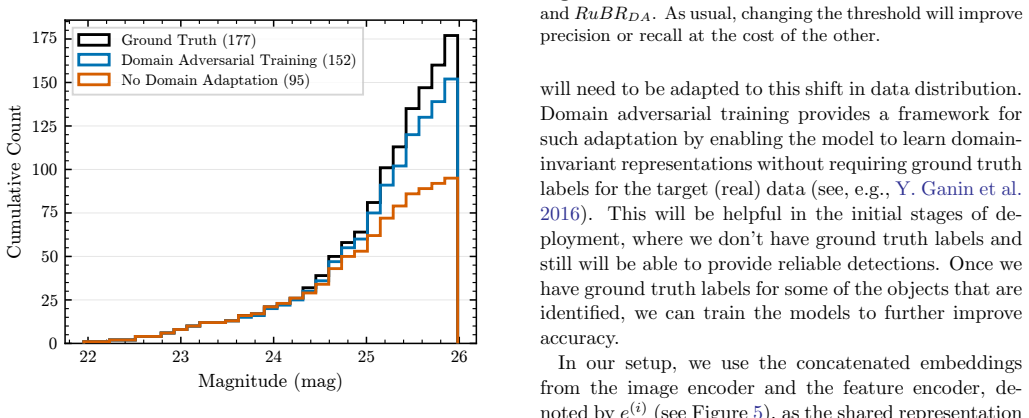
read the original abstract
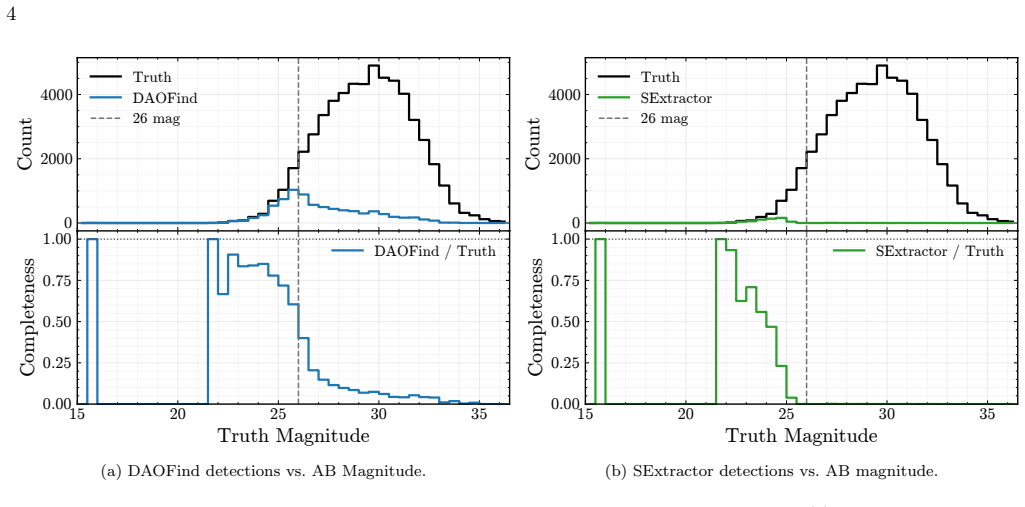
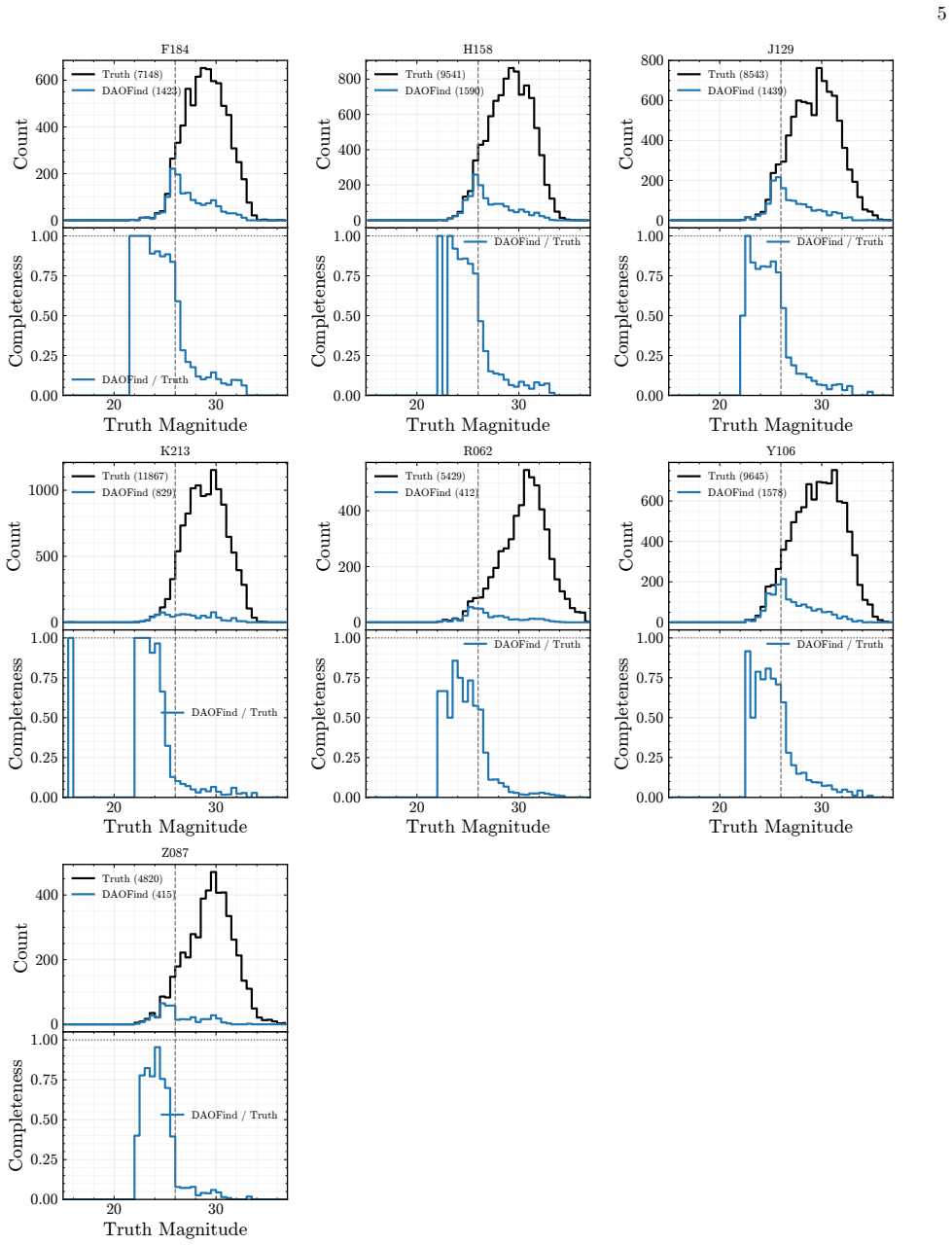
The Nancy Grace Roman Space Telescope (Roman), set for launch as early as September 2026, will conduct wide-field infrared imaging surveys with unprecedented spatial resolution and cadence, enabling the discovery of millions of astronomical transients. Hence, it is necessary to have automated pipelines for generating alerts in place so that the telescope can begin discovering reliable transients and variable objects soon after it is launched. However, no real Roman data currently exist, making the development of such pipelines difficult. In this work, we present a machine learning model $RuBR$ and a general methodology for distinguishing genuine transient and variable detections from spurious (bogus) detections within the RAPID pipeline. In particular, we present three models using this methodology: $RuBR_{comb}$ trained and tested on combined locally injected and OpenUniverse2024 transients, $RuBR_{loc}$ trained on locally injected transients and tested on OpenUniverse2024 transients, and $RuBR_{DA}$ that combines locally injected transients with a fraction of OpenUniverse2024 transients in domain-adaptation mode for training. This paves the way for strategies to adapt the $RuBR_{comb}$ model to real observations in the absence of any ground-truth labels during the early phases of the Roman mission. While the image differencing pipeline continues to be improved, our experimental results demonstrate the effectiveness of the proposed approach and its promise for robust real-bogus classification in the Roman era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the RuBR model and associated methodology for real-bogus classification of astronomical transients within the RAPID pipeline for the Nancy Grace Roman Space Telescope. It defines three variants—RuBR_comb (trained/tested on combined locally injected and OpenUniverse2024 simulations), RuBR_loc (trained on local injections, tested on OpenUniverse2024), and RuBR_DA (domain-adaptation variant mixing the two)—and argues that these enable strategies for adapting to real Roman data in the absence of ground-truth labels during early mission phases. The central claim is that the experimental results on simulations demonstrate effectiveness and promise for robust classification in the Roman era.
Significance. If the domain-adaptation approach can be shown to bridge simulated training to real observations, the work would provide a practical starting point for alert-generation pipelines ahead of the Roman launch, addressing a genuine operational gap for wide-field transient surveys. The label-free adaptation framing is a constructive contribution to sim-to-real transfer in astronomy ML.
major comments (2)
- [Results section] Results section (and Abstract): All reported performance is obtained exclusively on simulated datasets (locally injected transients and OpenUniverse2024); no quantitative proxy validation, ablation on unmodeled instrumental effects, or sensitivity tests to real-data artifacts are supplied to support the generalization claim that underpins the promise for “robust real-bogus classification in the Roman era.”
- [Methodology / Domain Adaptation] Domain-adaptation description (RuBR_DA): The training protocol that mixes locally injected transients with a fraction of OpenUniverse2024 “in domain-adaptation mode” is not accompanied by the precise adaptation objective, pseudo-labeling strategy, or hyper-parameter choices, making it impossible to evaluate whether the method can be applied when no ground-truth labels exist at all.
minor comments (2)
- [Abstract] Abstract: The phrase “our experimental results demonstrate the effectiveness” is stated without any numerical metrics, confidence intervals, or architecture details, which reduces clarity for readers.
- [Throughout] Notation: Inconsistent rendering of model names (RuBR vs. $RuBR_{comb}$) appears across the abstract and main text; a single consistent style would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, indicating revisions where appropriate to improve clarity and completeness.
read point-by-point responses
-
Referee: [Results section] Results section (and Abstract): All reported performance is obtained exclusively on simulated datasets (locally injected transients and OpenUniverse2024); no quantitative proxy validation, ablation on unmodeled instrumental effects, or sensitivity tests to real-data artifacts are supplied to support the generalization claim that underpins the promise for “robust real-bogus classification in the Roman era.”
Authors: We agree that all quantitative evaluations are performed on simulated data, as no real Roman observations exist prior to launch. The cross-simulation tests (RuBR_loc generalizing from local injections to OpenUniverse2024, and RuBR_DA) demonstrate robustness to differing simulation characteristics, which we present as an initial proxy for real-data performance. We will revise the Results section and Abstract to include explicit caveats on this point and add a dedicated Limitations subsection in the Discussion that outlines planned sensitivity analyses and validation once early Roman data are available. This addresses the concern without overstating current evidence. revision: yes
-
Referee: [Methodology / Domain Adaptation] Domain-adaptation description (RuBR_DA): The training protocol that mixes locally injected transients with a fraction of OpenUniverse2024 “in domain-adaptation mode” is not accompanied by the precise adaptation objective, pseudo-labeling strategy, or hyper-parameter choices, making it impossible to evaluate whether the method can be applied when no ground-truth labels exist at all.
Authors: We thank the referee for noting this gap in detail. RuBR_DA implements adversarial domain adaptation via a gradient reversal layer, with the objective combining supervised classification loss on the source domain and an adversarial domain loss (weight λ = 0.5) to align feature distributions. Pseudo-labels for the target domain (OpenUniverse2024) are generated iteratively from model predictions exceeding a confidence threshold of 0.8 and refreshed each epoch. Hyperparameters include Adam optimizer with learning rate 1e-4, batch size 32, and 10 adaptation epochs. We will add a new subsection to the Methodology section with the full loss formulation, pseudo-labeling algorithm, and all hyperparameter values to ensure reproducibility and applicability in fully label-free settings. revision: yes
Circularity Check
No circularity; empirical results on external simulations are independent of model fitting
full rationale
The paper trains and evaluates RuBR models exclusively on simulated transient datasets (locally injected transients and OpenUniverse2024), using standard cross-testing and domain-adaptation splits. Performance metrics on held-out simulation data constitute ordinary ML validation and do not reduce to any fitted parameter or self-defined quantity by construction. No equations, self-citations, or ansatzes are invoked that would make the reported effectiveness tautological. The forward-looking claim about real Roman data is explicitly noted as untested and is not derived from the current results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated transients from local injection and OpenUniverse2024 accurately represent the statistical properties of real Roman observations
Reference graph
Works this paper leans on
-
[1]
2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, https://www.tensorflow.org/
Abadi, M., Agarwal, A., Barham, P., et al. 2015, TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, https://www.tensorflow.org/
2015
-
[2]
Alard, C., & Lupton, R. H. 1998, The Astrophysical Journal, 503, 325, doi: 10.1086/305984 15 Astropy Collaboration, Robitaille, T. P., Tollerud, E. J., et al. 2013, A&A, 558, A33, doi: 10.1051/0004-6361/201322068 Astropy Collaboration, Price-Whelan, A. M., Sip˝ ocz, B. M., et al. 2018, AJ, 156, 123, doi: 10.3847/1538-3881/aabc4f Astropy Collaboration, Pri...
-
[4]
1996, A&AS, 117, 393, doi: 10.1051/aas:1996164
Bertin, E., & Arnouts, S. 1996, A&AS, 117, 393, doi: 10.1051/aas:1996164
-
[5]
Bishop, C. M. 2006, Pattern recognition and machine learning (Springer), doi: 10.1007/978-0-387-31073-2
-
[6]
Boureau, Y.-L., Ponce, J., & LeCun, Y. 2010, in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 111–118, doi: 10.5555/3104322.3104338
-
[7]
2025, astropy/photutils: 2.3.0, 2.3.0 Zenodo, doi: 10.5281/zenodo.17129028
Bradley, L., Sip˝ ocz, B., Robitaille, T., et al. 2025, astropy/photutils: 2.3.0, 2.3.0 Zenodo, doi: 10.5281/zenodo.17129028
-
[8]
2017, The Astrophysical Journal, 836, 97, doi: 10.3847/1538-4357/836/1/97
Maureira, J.-C. 2017, The Astrophysical Journal, 836, 97, doi: 10.3847/1538-4357/836/1/97
-
[9]
2022, Roman User Documentation (RDox),, Nancy Grace Roman Space Telescope User Documentation Website
Cosentino, R., Desjardins, T., Otor, J., et al. 2022, Roman User Documentation (RDox),, Nancy Grace Roman Space Telescope User Documentation Website
2022
-
[10]
Duev, D. A., Mahabal, A., Masci, F. J., et al. 2019, Monthly Notices of the Royal Astronomical Society, 489, 3582, doi: 10.1093/mnras/stz2357
-
[11]
Domain-Adversarial Training of Neural Networks
Ganin, Y., Ustinova, E., Ajakan, H., et al. 2016, Journal of machine learning research, 17, 1, doi: 10.48550/arXiv.1505.07818
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1505.07818 2016
-
[12]
Harris, C. R., Millman, K. J., van der Walt, S. J., et al. 2020, Nature, 585, 357, doi: 10.1038/s41586-020-2649-2
-
[13]
Multilayer feedforward networks are universal approximators , journal =
Hornik, K., Stinchcombe, M., & White, H. 1989, Neural networks, 2, 359, doi: 10.1016/0893-6080(89)90020-8
-
[14]
2023, Measuring Type Ia Supernovae Discovered in the Roman High Latitude Time Domain Survey, https://asd.gsfc.nasa
Hounsell, R., Scolnic, D., Brout, D., et al. 2023, Measuring Type Ia Supernovae Discovered in the Roman High Latitude Time Domain Survey, https://asd.gsfc.nasa. gov/roman/wps 2023/files/029 Hounsell HLTDS.pdf
2023
-
[15]
2022, The Astrophysical Journal, 936, 157, doi: 10.3847/1538-4357/ac7394
Hu, L., Wang, L., Chen, X., & Yang, J. 2022, The Astrophysical Journal, 936, 157, doi: 10.3847/1538-4357/ac7394
-
[16]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Ioffe, S., & Szegedy, C. 2015, in Proceedings of Machine Learning Research, Vol. 37, Proceedings of the 32nd International Conference on Machine Learning, ed. F. Bach & D. Blei (Lille, France: PMLR), 448–456, doi: 10.48550/arXiv.1502.03167
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1502.03167 2015
-
[17]
2023, A Sweet Spot for Tidal Disruption Events with the Roman Space Telescope, https://asd.gsfc.nasa.gov/ roman/wps 2023/files/026 Karmen HLTDS.pdf
Karmen, M., Gezari, S., Gomez, S., Guolo, M., & Norman, C. 2023, A Sweet Spot for Tidal Disruption Events with the Roman Space Telescope, https://asd.gsfc.nasa.gov/ roman/wps 2023/files/026 Karmen HLTDS.pdf
2023
-
[18]
Kingma, D. P. 2014, arXiv preprint arXiv:1412.6980, doi: 10.48550/arXiv.1412.6980
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2014
-
[19]
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. 2002a, Proceedings of the IEEE, 86, 2278, doi: 10.1109/5.726791
-
[20]
Mahabal, A., Rebbapragada, U., Walters, R., et al. 2019, Publications of the Astronomical Society of the Pacific, 131, 038002, doi: 10.1088/1538-3873/aaf3fa
-
[21]
Nair, V., & Hinton, G. E. 2010, in Proceedings of the 27th international conference on machine learning (ICML-10), 807–814
2010
-
[22]
Collaboration, The Roman HLIS Project Infrastructure, et al. 2025, Monthly Notices of the Royal Astronomical Society, 544, 3799, doi: 10.1093/mnras/staf1833 pandas development team, T. 2020, pandas-dev/pandas: Pandas, latest Zenodo, doi: 10.5281/zenodo.3509134
-
[23]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Paszke, A., Gross, S., Massa, F., et al. 2019, Advances in neural information processing systems, 32, doi: 10.48550/arXiv.1912.01703
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1912.01703 2019
-
[24]
2011, Journal of Machine Learning Research, 12, 2825
Pedregosa, F., Varoquaux, G., Gramfort, A., et al. 2011, Journal of Machine Learning Research, 12, 2825
2011
-
[25]
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. 1986, nature, 323, 533, doi: 10.1038/323533a0
-
[26]
Stetson, P. B. 1987, Publications of the Astronomical Society of the Pacific, 99, 191, doi: 10.1086/131977
-
[27]
Zackay, B., Ofek, E. O., & Gal-Yam, A. 2016, The Astrophysical Journal, 830, 27, doi: 10.3847/0004-637X/830/1/27
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.