Controllable Dynamic 3D Shape Generation via 3D Trajectories and Text
Pith reviewed 2026-06-28 06:20 UTC · model grok-4.3
The pith
T2Mo generates dynamic 3D shapes whose motions follow input 3D trajectories while matching text semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
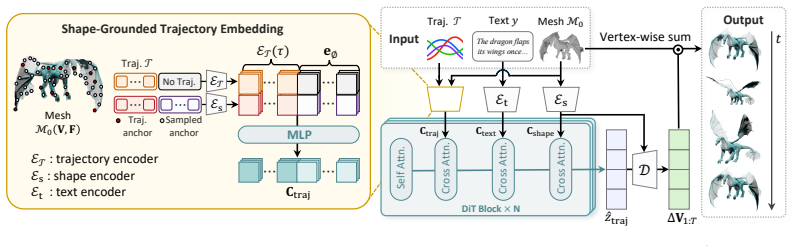
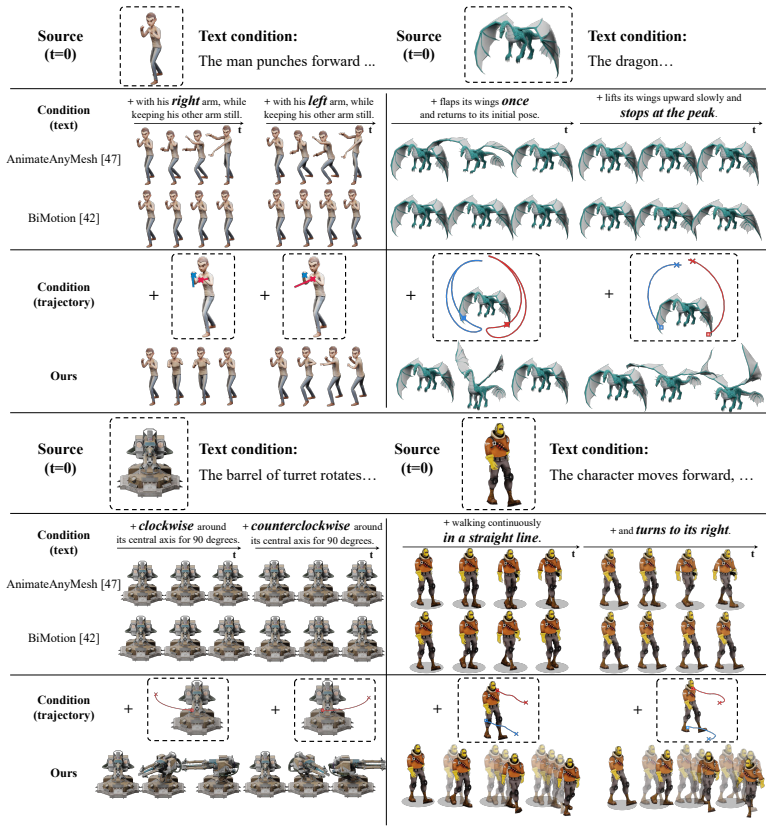
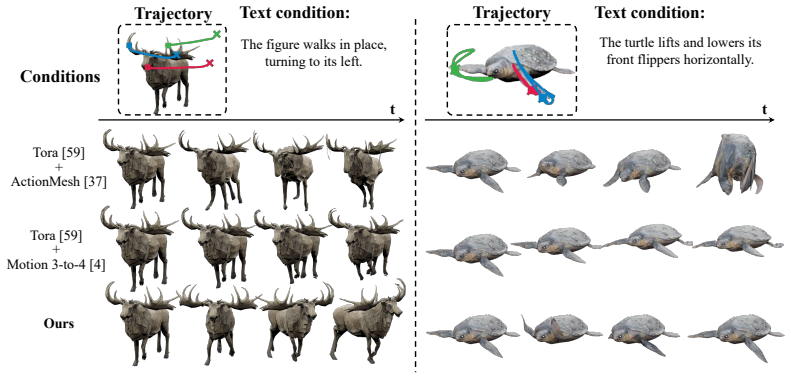
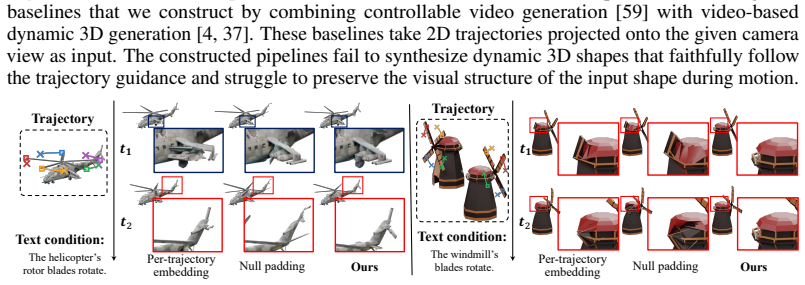
T2Mo is a feed-forward framework for controllable dynamic 3D shape generation conditioned on 3D trajectories and text. It generates object motions that spatially adhere to the given trajectories while globally reflecting the text semantics. To handle arbitrary trajectory configurations, a shape-grounded trajectory embedding maps the input set into a shape-aware token set that covers the entire object. Quantitative and qualitative comparisons against text-based baselines and cascaded video-based baselines show higher faithfulness to the combined prompts along with greater expressiveness while maintaining motion quality.
What carries the argument
shape-grounded trajectory embedding, which converts any set of 3D trajectories into a shape-aware token set covering the full object
If this is right
- Motions follow the supplied 3D trajectories at every point.
- Motions also carry the global semantic content of the text prompt.
- The same model works across dense, sparse, and uneven trajectory inputs.
- Results exceed text-only generation and cascaded video pipelines in both faithfulness and expressiveness.
- Motion quality remains comparable to prior methods while adding explicit spatial control.
Where Pith is reading between the lines
- The same conditioning approach could support interactive 3D editing tools where users drag paths and refine text descriptions in real time.
- Robotics planning systems might use the model to translate natural-language task descriptions plus required end-effector paths into object motion sequences.
- The embedding technique could be tested on other sparse 3D signals such as keypoint constraints or partial surface deformations.
- Integration with physics engines would allow checking whether the generated motions remain physically plausible under the combined trajectory and text constraints.
Load-bearing premise
The shape-grounded trajectory embedding can turn arbitrary, possibly sparse or uneven trajectory sets into tokens that cover the whole object without artifacts or loss of motion fidelity.
What would settle it
Run the model on sparse, uneven trajectories and measure whether generated point paths stay within a small distance of the input trajectories; large systematic deviations or user preference for a baseline method would falsify the claim.
Figures

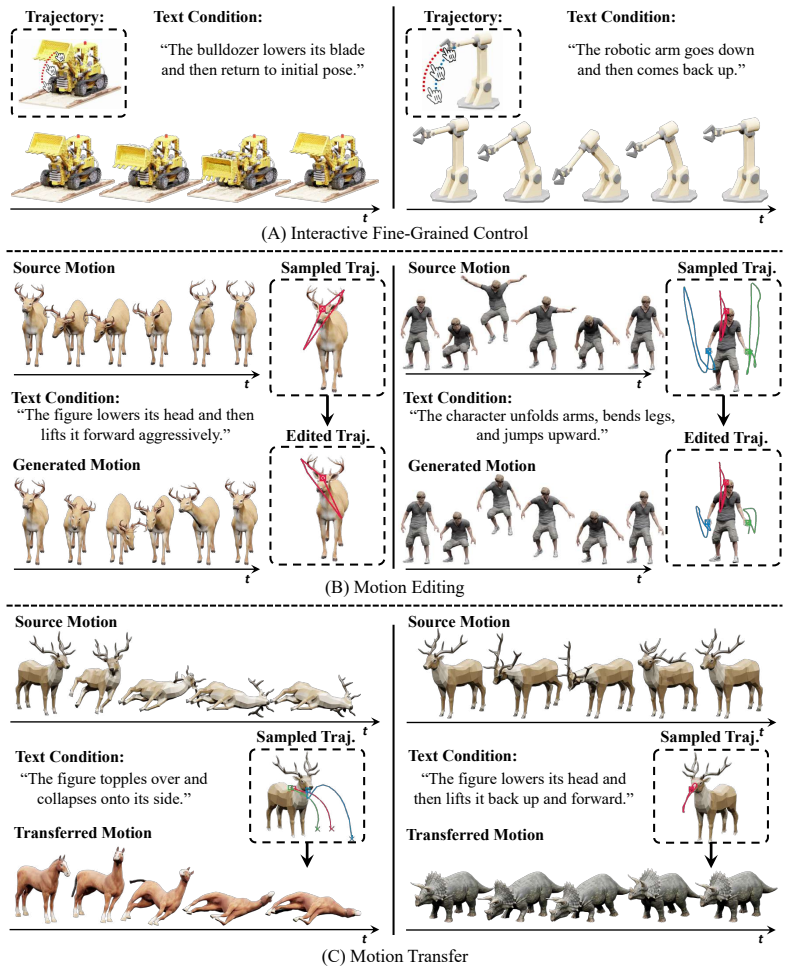
read the original abstract
We introduce T2Mo, a feed-forward framework for controllable dynamic 3D shape generation conditioned on 3D trajectories and text. Due to the inherent ambiguity of language, generating precisely intended motions using text alone remains challenging. To address this, we adopt 3D trajectories as controllable spatial guidance, specifying the exact paths along which selected points should move. By combining both, T2Mo generates object motions that spatially adhere to the given trajectories while globally reflecting the text semantics. To robustly handle trajectory inputs with arbitrary configurations, ranging from dense to sparse and unevenly distributed, we further propose a shape-grounded trajectory embedding that maps an input trajectory set into a shape-aware token set covering the entire object. We conduct extensive comparisons against text-based baselines and cascaded video-based baselines that combine trajectory-guided video generation with video-to-dynamic mesh generation. Quantitative and qualitative evaluations, along with user studies, demonstrate that our approach produces motions that more faithfully follow the given prompts with higher expressiveness while preserving motion quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces T2Mo, a feed-forward framework for controllable dynamic 3D shape generation conditioned on 3D trajectories and text. It proposes a shape-grounded trajectory embedding to map arbitrary (dense to sparse, uneven) trajectory sets into shape-aware token sets covering the object. The central claim is that the resulting motions spatially adhere to the trajectories while reflecting text semantics, outperforming text-based baselines and cascaded video-based baselines in faithfulness, expressiveness, and motion quality, as demonstrated by quantitative metrics, qualitative results, and user studies.
Significance. If the central claims hold after addressing the embedding details, the work would advance controllable 3D generation by combining precise spatial guidance from trajectories with semantic control from text. The feed-forward design and explicit handling of arbitrary trajectory configurations represent practical strengths for applications in animation and design. The inclusion of both quantitative comparisons and user studies strengthens the evaluation if the metrics are clearly defined and the baselines are fairly constructed.
major comments (1)
- [Method (shape-grounded trajectory embedding)] The shape-grounded trajectory embedding (method section): the central claim that motions 'spatially adhere to the given trajectories' while outperforming baselines depends on this embedding reliably converting arbitrary trajectory sets into a shape-aware token set that covers the entire object without artifacts or fidelity loss. The abstract states the mapping occurs but supplies no mechanism details on shape grounding, tokenization strategy, or handling of uncovered regions for sparse/uneven inputs; without ablations or analysis on such cases, the faithfulness advantage cannot be substantiated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below and agree that additional details and analysis are warranted to fully substantiate the claims.
read point-by-point responses
-
Referee: [Method (shape-grounded trajectory embedding)] The shape-grounded trajectory embedding (method section): the central claim that motions 'spatially adhere to the given trajectories' while outperforming baselines depends on this embedding reliably converting arbitrary trajectory sets into a shape-aware token set that covers the entire object without artifacts or fidelity loss. The abstract states the mapping occurs but supplies no mechanism details on shape grounding, tokenization strategy, or handling of uncovered regions for sparse/uneven inputs; without ablations or analysis on such cases, the faithfulness advantage cannot be substantiated.
Authors: We agree that the current description in Section 3.2 provides only a high-level overview of the shape-grounded trajectory embedding and does not include sufficient implementation specifics on the grounding mechanism, tokenization strategy, or explicit handling of sparse/uneven inputs and uncovered regions. To address this, the revised manuscript will expand the method section with these details, including how the embedding produces a shape-aware token set that covers the object. We will also add targeted ablations and analysis on sparse and uneven trajectory configurations to demonstrate robustness and support the faithfulness claims. revision: yes
Circularity Check
No circularity: learned feed-forward model with no derivations or self-defined reductions
full rationale
The provided abstract and context present T2Mo as a learned feed-forward neural framework. The shape-grounded trajectory embedding is introduced as a proposed architectural component that maps trajectories to tokens, but no equations, fitted parameters, predictions, or derivation chains are shown that reduce outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are referenced. The central claims rest on empirical comparisons and user studies rather than any mathematical reduction. This is the normal case of a self-contained learned model without circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[2]
4d-fy: Text-to-4d generation using hybrid score distillation sampling
Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B Lindell. 4d-fy: Text-to-4d generation using hybrid score distillation sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7996–8006, 2024
2024
-
[3]
Sherwin Bahmani, Xian Liu, Wang Yifan, Ivan Skorokhodov, Victor Rong, Ziwei Liu, Xihui Liu, Jeong Joon Park, Sergey Tulyakov, Gordon Wetzstein, Andrea Tagliasacchi, and David B. Lindell. Tc4d: Trajectory-conditioned text-to-4d generation. In Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Rus- sakovsky, Torsten Sattler, and Gül Varol, editors,Computer Visi...
2024
-
[4]
Springer Nature Switzerland
-
[5]
Motion 3-to-4: 3d motion reconstruction for 4d synthesis.arXiv preprint arXiv:2601.14253, 2026
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, and Anpei Chen. Motion 3-to-4: 3d motion reconstruction for 4d synthesis.arXiv preprint arXiv:2601.14253, 2026
-
[6]
Ruihang Chu, Yefei He, Zhekai Chen, Shiwei Zhang, Xiaogang Xu, Bin Xia, Dingdong Wang, Hongwei Yi, Xihui Liu, Hengshuang Zhao, et al. Wan-move: Motion-controllable video generation via latent trajectory guidance.arXiv preprint arXiv:2512.08765, 2025
-
[7]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
2023
-
[8]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rom- bach. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024. URLhttps...
2024
-
[9]
Xiao Fu, Xian Liu, Xintao Wang, Sida Peng, Menghan Xia, Xiaoyu Shi, Ziyang Yuan, Pengfei Wan, Di Zhang, and Dahua Lin. 3dtrajmaster: Mastering 3d trajectory for multi-entity motion in video generation. arXiv preprint arXiv:2412.07759, 2024
-
[10]
Junyao Gao, Jiaxing Li, Wenran Liu, Yanhong Zeng, Fei Shen, Kai Chen, Yanan Sun, and Cairong Zhao. Charactershot: Controllable and consistent 4d character animation.arXiv preprint arXiv:2508.07409, 2025
-
[11]
Motion prompting: Controlling video generation with motion trajectories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez- Guevara, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. Motion prompting: Controlling video generation with motion trajectories. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CV...
2025
-
[12]
Motionlab: Unified human motion generation and editing via the motion-condition-motion paradigm
Ziyan Guo, Zeyu Hu, De Wen Soh, and Na Zhao. Motionlab: Unified human motion generation and editing via the motion-condition-motion paradigm. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13869–13879, 2025
2025
-
[13]
Flex3D: Feed-forward 3D generation with flexible reconstruction model and input view curation
Junlin Han, Jianyuan Wang, Andrea Vedaldi, Philip Torr, and Filippos Kokkinos. Flex3D: Feed-forward 3D generation with flexible reconstruction model and input view curation. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference...
2025
-
[14]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Debiasing scores and prompts of 2d diffusion for view-consistent text-to-3d generation.Advances in Neural Information Processing Systems, 36: 11970–11987, 2023
Susung Hong, Donghoon Ahn, and Seungryong Kim. Debiasing scores and prompts of 2d diffusion for view-consistent text-to-3d generation.Advances in Neural Information Processing Systems, 36: 11970–11987, 2023
2023
-
[16]
Hanzhuo Huang, Yuan Liu, Ge Zheng, Jiepeng Wang, Zhiyang Dou, and Sibei Yang. Mvtokenflow: High-quality 4d content generation using multiview token flow.arXiv preprint arXiv:2502.11697, 2025. 10
-
[17]
Animax: Animating the inanimate in 3d with joint video-pose diffusion models
Zehuan Huang, Haoran Feng, Yang-Tian Sun, Yuan-Chen Guo, Yan-Pei Cao, and Lu Sheng. Animax: Animating the inanimate in 3d with joint video-pose diffusion models. InProceedings of the SIGGRAPH Asia 2025 Conference Papers, pages 1–13, 2025
2025
-
[18]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[19]
Animate3d: Animating any 3d model with multi-view video diffusion.Advances in Neural Information Processing Systems, 37: 125879–125906, 2024
Yanqin Jiang, Chaohui Yu, Chenjie Cao, Fan Wang, Weiming Hu, and Jin Gao. Animate3d: Animating any 3d model with multi-view video diffusion.Advances in Neural Information Processing Systems, 37: 125879–125906, 2024
2024
-
[20]
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Mesh4d: 4d mesh reconstruc- tion and tracking from monocular video.arXiv preprint arXiv:2601.05251, 2026
-
[21]
Trajevae: Controllable human motion generation from trajectories
Kacper Kania, Marek Kowalski, et al. Trajevae: Controllable human motion generation from trajectories. arXiv preprint arXiv:2104.00351, 2021
-
[22]
Guided motion dif- fusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion dif- fusion for controllable human motion synthesis. InProceedings of the IEEE/CVF international conference on computer vision, pages 2151–2162, 2023
2023
-
[23]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[24]
Hunyuan3D 2.5: Towards High-Fidelity 3D Assets Generation with Ultimate Details
Zeqiang Lai, Yunfei Zhao, Haolin Liu, Zibo Zhao, Qingxiang Lin, Huiwen Shi, Xianghui Yang, Mingxin Yang, Shuhui Yang, Yifei Feng, et al. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details.arXiv preprint arXiv:2506.16504, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Craftsman3d: High-fidelity mesh generation with 3d native diffusion and interactive geometry refiner
Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, and Xiaoxiao Long. Craftsman3d: High-fidelity mesh generation with 3d native diffusion and interactive geometry refiner. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 5307–5317, 2025
2025
-
[26]
arXiv preprint arXiv:2505.07747 (2025) 2, 3, 4, 6, 8, 21, 30
Weiyu Li, Xuanyang Zhang, Zheng Sun, Di Qi, Hao Li, Wei Cheng, Weiwei Cai, Shihao Wu, Jiarui Liu, Zihao Wang, et al. Step1x-3d: Towards high-fidelity and controllable generation of textured 3d assets. arXiv preprint arXiv:2505.07747, 2025
-
[27]
Articulated kinematics distillation from video diffusion models
Xuan Li, Qianli Ma, Tsung-Yi Lin, Yongxin Chen, Chenfanfu Jiang, Ming-Yu Liu, and Donglai Xiang. Articulated kinematics distillation from video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17571–17581, 2025
2025
-
[28]
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.arXiv preprint arXiv:2502.06608, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation.Advances in Neural Information Processing Systems, 37:21377– 21400, 2024
Zhiqi Li, Yiming Chen, and Peidong Liu. Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation.Advances in Neural Information Processing Systems, 37:21377– 21400, 2024
2024
-
[30]
Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models
Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, and Karsten Kreis. Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8576–8588, 2024
2024
-
[31]
Trailblazer: Trajectory control for diffusion- based video generation
Wan-Duo Kurt Ma, John P Lewis, and W Bastiaan Kleijn. Trailblazer: Trajectory control for diffusion- based video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[32]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[33]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Distilling multi-view diffusion models into 3d generators.arXiv preprint arXiv:2504.00457, 2025
Hao Qin, Luyuan Chen, Ming Kong, Mengxu Lu, and Qiang Zhu. Distilling multi-view diffusion models into 3d generators.arXiv preprint arXiv:2504.00457, 2025. 11
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, Proceedings of the 38th International Conference on Machine...
2021
-
[36]
Kimodo: Scaling controllable human motion generation
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, et al. Kimodo: Scaling controllable human motion generation. arXiv preprint arXiv:2603.15546, 2026
-
[37]
L4gm: Large 4d gaussian reconstruction model.Advances in Neural Information Processing Systems, 37:56828–56858, 2024
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung W Kim, et al. L4gm: Large 4d gaussian reconstruction model.Advances in Neural Information Processing Systems, 37:56828–56858, 2024
2024
-
[38]
Remy Sabathier, David Novotny, Niloy J Mitra, and Tom Monnier. Actionmesh: Animated 3d mesh generation with temporal 3d diffusion.arXiv preprint arXiv:2601.16148, 2026
-
[39]
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Shengming Yin, Wengang Zhou, Jing Liao, and Houqiang Li. Eg4d: Explicit generation of 4d object without score distillation.arXiv preprint arXiv:2405.18132, 2024
-
[40]
Tlcontrol: Trajectory and language control for human motion synthesis
Weilin Wan, Zhiyang Dou, Taku Komura, Wenping Wang, Dinesh Jayaraman, and Lingjie Liu. Tlcontrol: Trajectory and language control for human motion synthesis. InEuropean Conference on Computer Vision, pages 37–54. Springer, 2024
2024
-
[41]
Levitor: 3d trajectory oriented image-to-video synthesis
Hanlin Wang, Hao Ouyang, Qiuyu Wang, Wen Wang, Ka Leong Cheng, Qifeng Chen, Yujun Shen, and Limin Wang. Levitor: 3d trajectory oriented image-to-video synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12490–12500, 2025
2025
-
[42]
Jiawei Wang, Yuchen Zhang, Jiaxin Zou, Yan Zeng, Guoqiang Wei, Liping Yuan, and Hang Li. Boximator: Generating rich and controllable motions for video synthesis.arXiv preprint arXiv:2402.01566, 2024
-
[43]
Bimotion: B-spline motion for text-guided dynamic 3d character generation
Miaowei Wang, Qingxuan Yan, Zhi Cao, Yayuan Li, Oisin Mac Aodha, Jason J Corso, and Amir Vaxman. Bimotion: B-spline motion for text-guided dynamic 3d character generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10152–10164, 2026
2026
-
[44]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.Advances in neural information processing systems, 36:8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.Advances in neural information processing systems, 36:8406–8441, 2023
2023
-
[45]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[46]
Cat4d: Create anything in 4d with multi-view video diffusion models
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26057–26068, 2025
2025
-
[47]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. In European Conference on Computer Vision, pages 331–348. Springer, 2024
2024
-
[48]
Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation
Zijie Wu, Chaohui Yu, Fan Wang, and Xiang Bai. Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13557–13568, October 2025
2025
-
[49]
AnimateAnyMesh++: A Flexible 4D Foundation Model for High-Fidelity Text-Driven Mesh Animation
Zijie Wu, Chaohui Yu, Fan Wang, and Xiang Bai. Animateanymesh++: A flexible 4d foundation model for high-fidelity text-driven mesh animation, 2026. URLhttps://arxiv.org/abs/2604.26917
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Structured 3d latents for scalable and versatile 3d generation
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21469–21480, 2025
2025
-
[51]
Kevin Xie, Amirmojtaba Sabour, Jiahui Huang, Despoina Paschalidou, Greg Klar, Umar Iqbal, Sanja Fidler, and Xiaohui Zeng. Videopanda: Video panoramic diffusion with multi-view attention.arXiv preprint arXiv:2504.11389, 2025. 12
-
[52]
Omnicontrol: Control any joint at any time for human motion generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. InInternational Conference on Learning Representations, volume 2024, pages 28176–28194, 2024
2024
-
[53]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Jiraphon Yenphraphai, Ashkan Mirzaei, Jianqi Chen, Jiaxu Zou, Sergey Tulyakov, Raymond A Yeh, Peter Wonka, and Chaoyang Wang. Shapegen4d: Towards high quality 4d shape generation from videos.arXiv preprint arXiv:2510.06208, 2025
-
[55]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Drag- nuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
4real: Towards photorealistic 4d scene generation via video diffusion models.Advances in Neural Information Processing Systems, 37:45256–45280, 2024
Heng Yu, Chaoyang Wang, Peiye Zhuang, Willi Menapace, Aliaksandr Siarohin, Junli Cao, Laszlo A Jeni, Sergey Tulyakov, and Hsin-Ying Lee. 4real: Towards photorealistic 4d scene generation via video diffusion models.Advances in Neural Information Processing Systems, 37:45256–45280, 2024
2024
-
[57]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
2023
-
[58]
4diffusion: Multi- view video diffusion model for 4d generation.Advances in Neural Information Processing Systems, 37: 15272–15295, 2024
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, and Yu Qiao. 4diffusion: Multi- view video diffusion model for 4d generation.Advances in Neural Information Processing Systems, 37: 15272–15295, 2024
2024
-
[59]
Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high-quality 3d assets.ACM Transactions on Graphics (TOG), 43(4):1–20, 2024
2024
-
[60]
The bulldozer lowers its blade and then return to initial pose
Zhenghao Zhang, Junchao Liao, Menghao Li, ZuoZhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2063–2073, June 2025. 13 Appendix A Implementation details Training details.Inspired...
2063
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.