Differentiable Efficient Operator Search
Pith reviewed 2026-06-28 07:28 UTC · model grok-4.3
The pith
Manually designed token-reduction operators are special cases of a single differentiable search space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
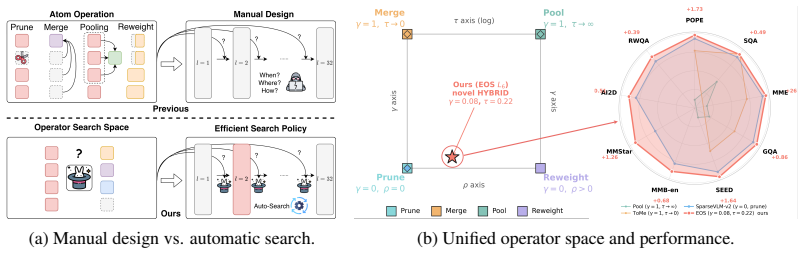
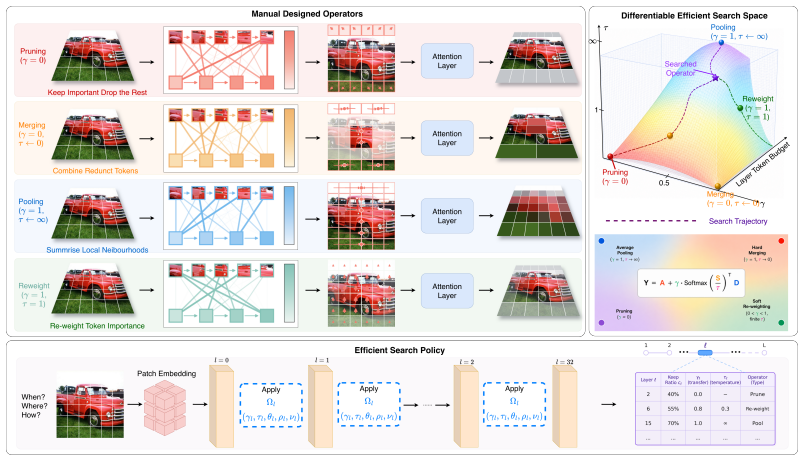
Token-reduction operators in efficient multimodal foundation models can be interpreted as distinct regimes of a shared operator space, so a differentiable search over layer activation, retention budget, and operator behavior can optimize performance under budget constraints, recover hand-designed baselines, and discover hybrid operators with competitive trade-offs.
What carries the argument
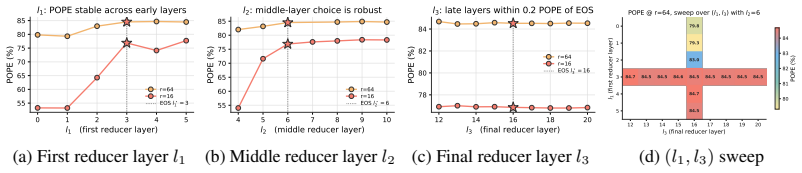
The parameterization of a shared operator space for joint differentiable optimization of token reduction location, count, and processing method.
If this is right
- Hand-designed operators like pruning and pooling are recovered as special cases of the search.
- Hybrid operators beyond manual designs can be found automatically.
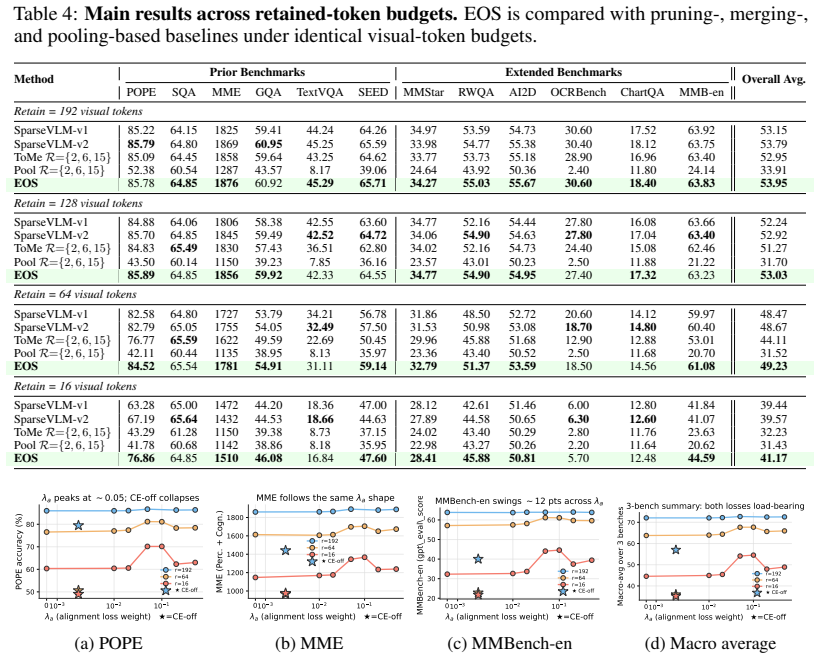
- The approach maintains competitive accuracy even with aggressive reduction of visual tokens.
- Efficient multimodal inference can be achieved by optimizing the operator search rather than designing operators by hand.
Where Pith is reading between the lines
- Similar unification might apply to other model efficiency techniques if they can be cast as parameter regimes.
- The method could be extended to search over combinations with other efficiency methods like attention approximations.
- Results on multimodal benchmarks suggest potential for application in other domains with high token counts, such as long-context language models.
Load-bearing premise
All relevant token reduction strategies can be represented as points within one continuous differentiable parameter space.
What would settle it
A direct comparison on multimodal benchmarks where the best manually designed operator consistently outperforms any searched operator at equivalent computational cost would falsify the utility of the shared space approach.
Figures

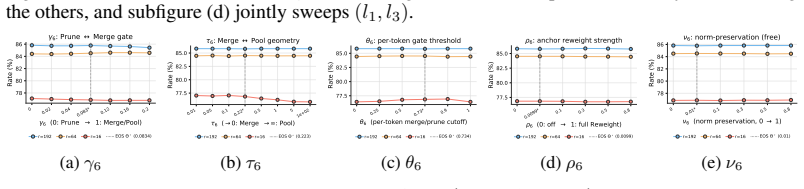
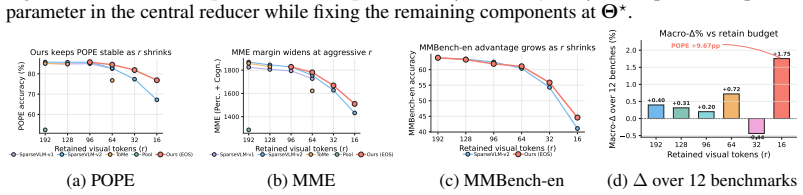
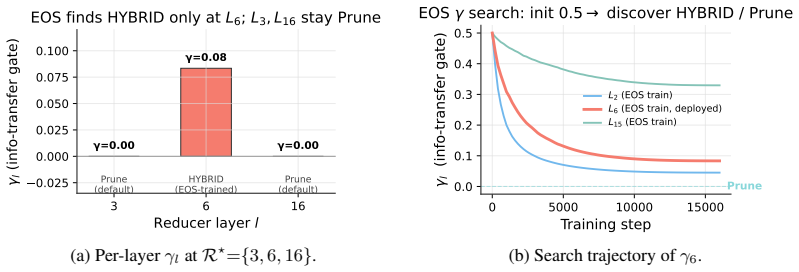
read the original abstract
Efficient multimodal foundation models often rely on manually designed token-reduction operators, such as pruning, merging, pooling, and adaptive reweighting. Although these operators appear different, we show that they can be interpreted as distinct regimes of a shared operator space. Based on this view, we introduce Efficient Operator Search, a differentiable framework that jointly searches where to reduce tokens, how many tokens to retain, and how reduced token information should be processed. The proposed search space parameterizes layer activation, retention budget, and operator behavior, while the search policy optimizes task performance under one-sided budget and cost constraints. This formulation recovers representative hand-designed baselines as special cases and further discovers hybrid operators beyond isolated manual designs. Experiments on multimodal benchmarks show that the searched operators achieve competitive accuracy-efficiency trade-offs, especially under aggressive visual-token reduction. These results suggest that efficient multimodal inference can be reframed from manual operator design to differentiable operator search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that manually designed token-reduction operators (pruning, merging, pooling, adaptive reweighting) in efficient multimodal foundation models are distinct regimes of a shared operator space. It introduces Differentiable Efficient Operator Search, a framework that jointly optimizes layer activation, retention budget, and operator behavior under one-sided budget and cost constraints. The approach recovers hand-designed baselines as special cases, discovers hybrid operators, and yields competitive accuracy-efficiency trade-offs on multimodal benchmarks, especially under aggressive visual-token reduction.
Significance. If the shared parameterization rigorously recovers the manual operators as special cases and the discovered hybrids improve upon them, the work would reframe efficient multimodal inference as an automated differentiable search problem rather than manual design. The joint optimization of location, budget, and behavior under constraints is a potentially useful formulation if the unification holds.
major comments (2)
- [Abstract] Abstract: the central unification claim that 'this formulation recovers representative hand-designed baselines as special cases' is load-bearing but unsupported by any equations, explicit limiting cases, or parameterization details (e.g., no demonstration that a particular retention-budget value exactly reproduces token merging or that the operator-behavior variable reproduces adaptive reweighting). Without this embedding, the search may explore a new space rather than extending a common one.
- [Abstract] Abstract: the experimental claim that 'searched operators achieve competitive accuracy-efficiency trade-offs' is stated without any quantitative numbers, specific benchmarks, baselines, or ablation results, preventing assessment of whether the gains are meaningful or whether the search actually improves upon the recovered baselines.
minor comments (1)
- [Abstract] Abstract: the phrase 'one-sided budget and cost constraints' is used without definition or clarification of what 'one-sided' denotes in the optimization policy.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree the abstract should more explicitly support its central claims and will revise accordingly. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central unification claim that 'this formulation recovers representative hand-designed baselines as special cases' is load-bearing but unsupported by any equations, explicit limiting cases, or parameterization details (e.g., no demonstration that a particular retention-budget value exactly reproduces token merging or that the operator-behavior variable reproduces adaptive reweighting). Without this embedding, the search may explore a new space rather than extending a common one.
Authors: Section 3 of the manuscript defines the shared operator space via continuous parameters for layer activation, retention budget, and operator behavior (including the reweighting function). Specific limiting values recover the baselines exactly (e.g., budget=1 with identity reweighting for no reduction; budget approaching 0 with merging-style aggregation). We will add a concise statement of these limiting cases and a pointer to the equations in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the experimental claim that 'searched operators achieve competitive accuracy-efficiency trade-offs' is stated without any quantitative numbers, specific benchmarks, baselines, or ablation results, preventing assessment of whether the gains are meaningful or whether the search actually improves upon the recovered baselines.
Authors: The abstract is a high-level summary; quantitative results (accuracy/FLOPs on VQAv2, GQA, MM-Vet; comparisons to manual baselines and ablations) appear in Sections 4–5. We will incorporate the key numerical trade-offs into the abstract to make the experimental claim self-contained. revision: yes
Circularity Check
No circularity: framework explicitly constructs shared space to include baselines as special cases; recovery is definitional design, not hidden reduction.
full rationale
The abstract states the parameterization is built to recover hand-designed operators as special cases, which is an explicit modeling choice rather than a derivation that reduces to fitted inputs or self-citations. No equations are shown that would make performance predictions equivalent to the search inputs by construction. No self-citation chains or uniqueness theorems from prior author work are invoked as load-bearing. The central claim rests on the differentiability of the search and empirical results, which are independent of the unification premise. This matches the default expectation of a self-contained framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[3]
Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
2024
-
[4]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
2019
-
[6]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InEuropean conference on computer vision, pages 235–251. Springer, 2016
2016
-
[8]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed- bench: Benchmarking multimodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[11]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023
2023
-
[12]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[13]
Global compression commander: Plug-and-play inference acceleration for high-resolution large vision-language models
Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, and Honggang Chen. Global compression commander: Plug-and-play inference acceleration for high-resolution large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 7350–7358, 2026
2026
-
[14]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[15]
Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024. 10
2024
-
[16]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in neural information processing systems, 35: 2507–2521, 2022
2022
-
[17]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
2022
-
[18]
Neural architecture retrieval.arXiv preprint arXiv:2307.07919, 2023
Xiaohuan Pei, Yanxi Li, Minjing Dong, and Chang Xu. Neural architecture retrieval.arXiv preprint arXiv:2307.07919, 2023
-
[19]
Xiaohuan Pei, Tao Huang, and Chang Xu. Cross-self kv cache pruning for efficient vision- language inference.arXiv preprint arXiv:2412.04652, 2024
-
[20]
Xiaohuan Pei, Yuxing Chen, Siyu Xu, Yunke Wang, Yuheng Shi, and Chang Xu. Action- aware dynamic pruning for efficient vision-language-action manipulation.arXiv preprint arXiv:2509.22093, 2025
-
[21]
Rethinking causal mask attention for vision-language inference.arXiv preprint arXiv:2505.18605, 2025
Xiaohuan Pei, Tao Huang, YanXiang Ma, and Chang Xu. Rethinking causal mask attention for vision-language inference.arXiv preprint arXiv:2505.18605, 2025
-
[22]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
2025
-
[23]
Yuheng Shi, Xiaohuan Pei, Minjing Dong, and Chang Xu. Catching the details: Self-distilled roi predictors for fine-grained mllm perception.arXiv preprint arXiv:2509.16944, 2025
-
[24]
Q-Zoom: Query-Aware Adaptive Perception for Efficient Multimodal Large Language Models
Yuheng Shi, Xiaohuan Pei, Linfeng Wen, Minjing Dong, and Chang Xu. Q-zoom: Query- aware adaptive perception for efficient multimodal large language models.arXiv preprint arXiv:2604.06912, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
2019
-
[26]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
2025
-
[31]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024. 11 A Technical appendices and supplementary material This appendix expands on four aspect...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.