LongSpace: Exploring Long-Horizon Spatial Memory from Perception to Recall in Video
Pith reviewed 2026-06-28 02:13 UTC · model grok-4.3
The pith
LongSpace adds 3D cues to early layers and layer-aware memory to let video MLLMs retrieve past spatial layouts from long sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
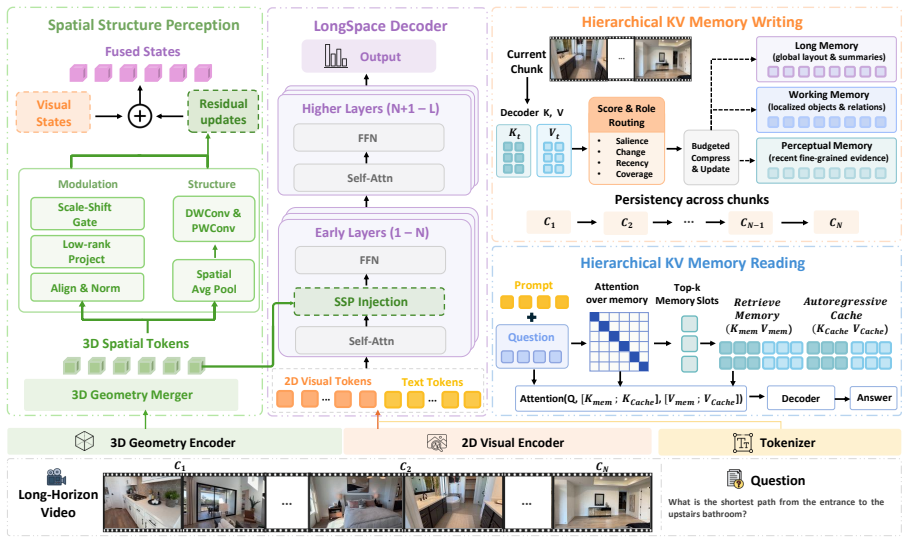
LongSpace models long videos as sequential chunks, incorporates 3D structural cues into early decoder layers, and constructs layer-aware memory for question-guided retrieval, producing measurable gains on long-video spatial understanding tasks.
What carries the argument
Layer-aware memory that stores spatial information per decoder layer and enables question-guided retrieval from earlier chunks.
If this is right
- Video MLLMs become able to answer questions about previously seen layouts and viewpoint changes without re-observing them.
- Autonomous driving and robotic navigation pipelines can draw on recalled spatial relations instead of only the live camera feed.
- Explicit memory mechanisms become a necessary component for any long-horizon video model rather than an optional add-on.
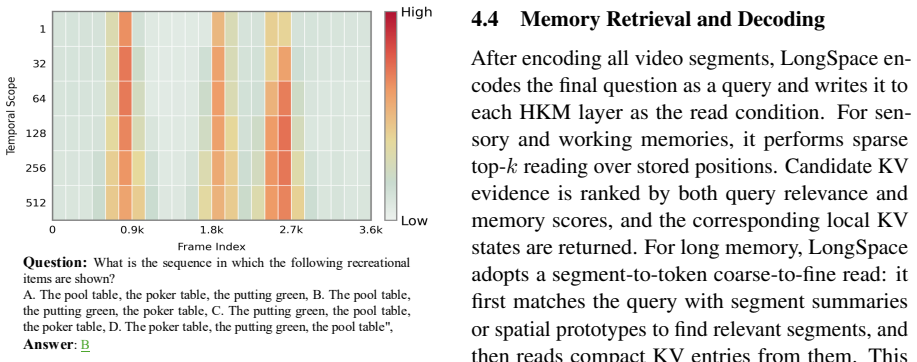
- Benchmark scores on room-tour tasks improve when retrieval is conditioned on both the question and the layer of origin.
Where Pith is reading between the lines
- The same chunk-plus-early-cue pattern could be tested on temporal or causal reasoning benchmarks that also require recall of distant events.
- If the memory bank scales linearly with video length, longer real-world streams such as full building tours would remain computationally tractable.
- Replacing the 3D cue extractor with other structural signals such as optical flow or depth maps would test whether the benefit is specific to 3D geometry or any consistent spatial prior.
Load-bearing premise
The observed gains come from genuine retrieval of stored spatial structure rather than the model learning superficial correlations present in the benchmark videos.
What would settle it
An ablation that removes the 3D cues and layer-aware memory while keeping total parameters and training data fixed shows no drop in accuracy on LongSpace-Bench or other spatial reasoning sets.
Figures






read the original abstract
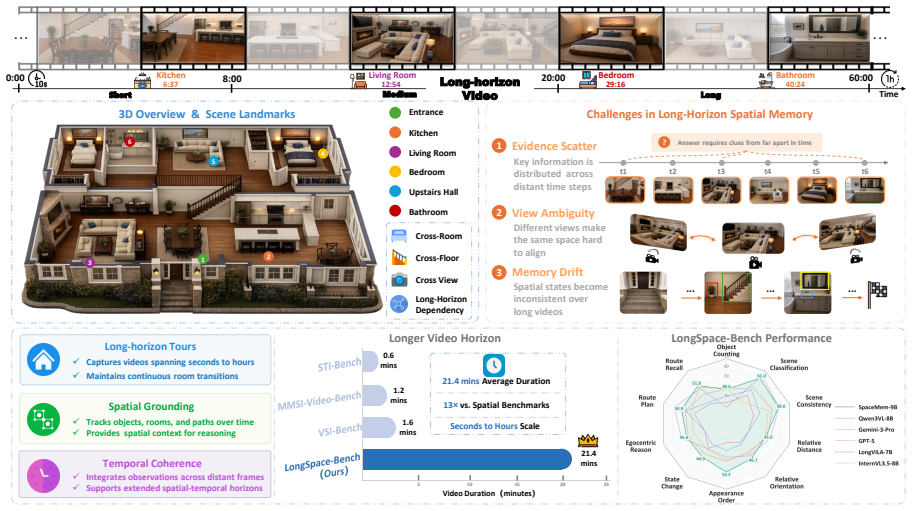
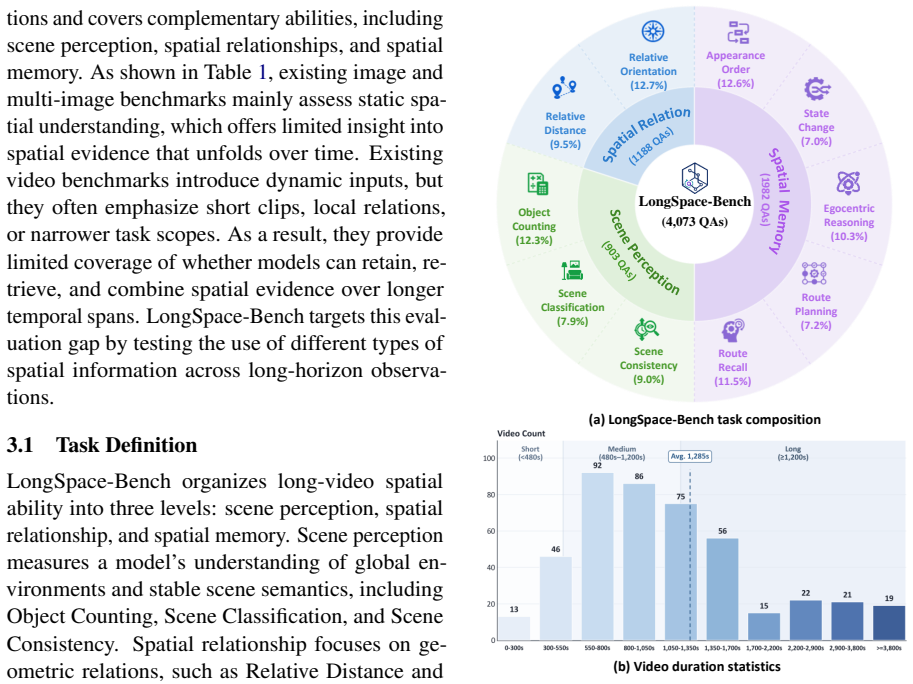
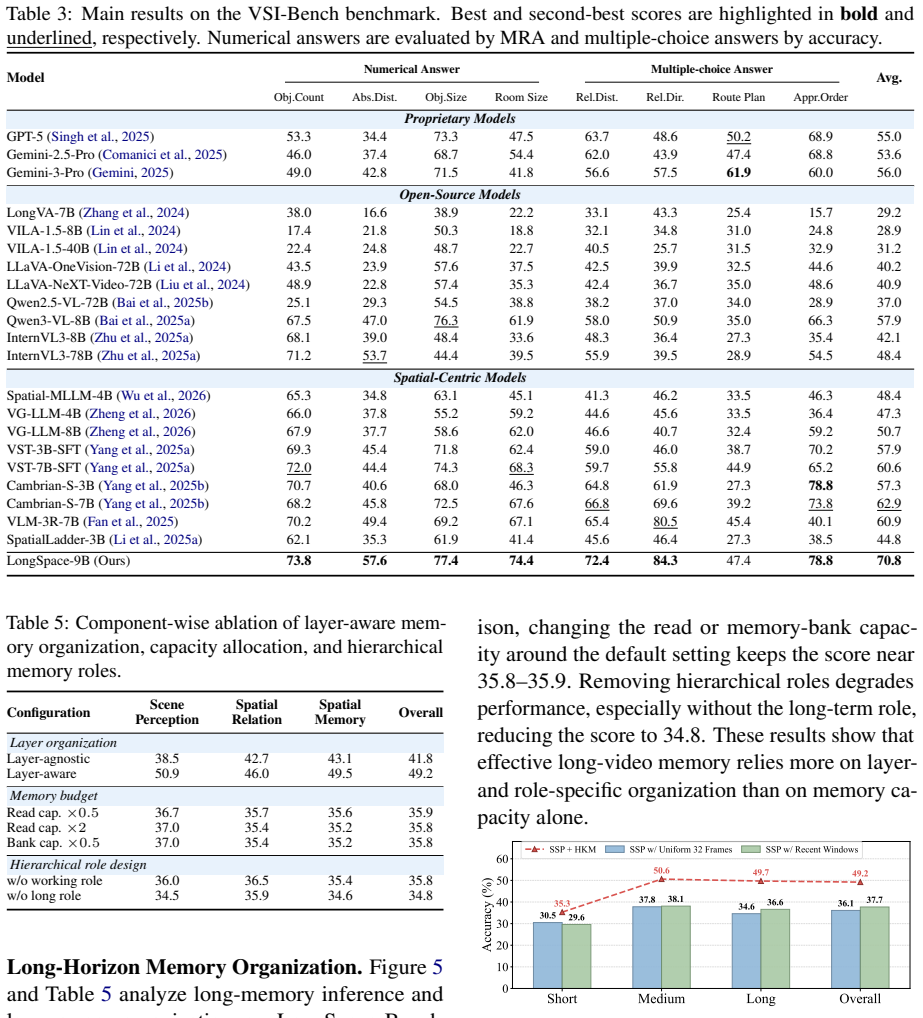
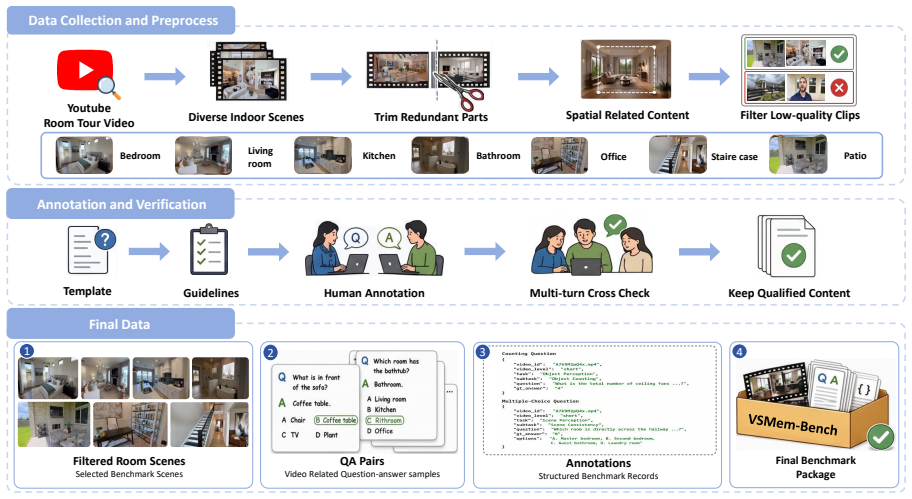
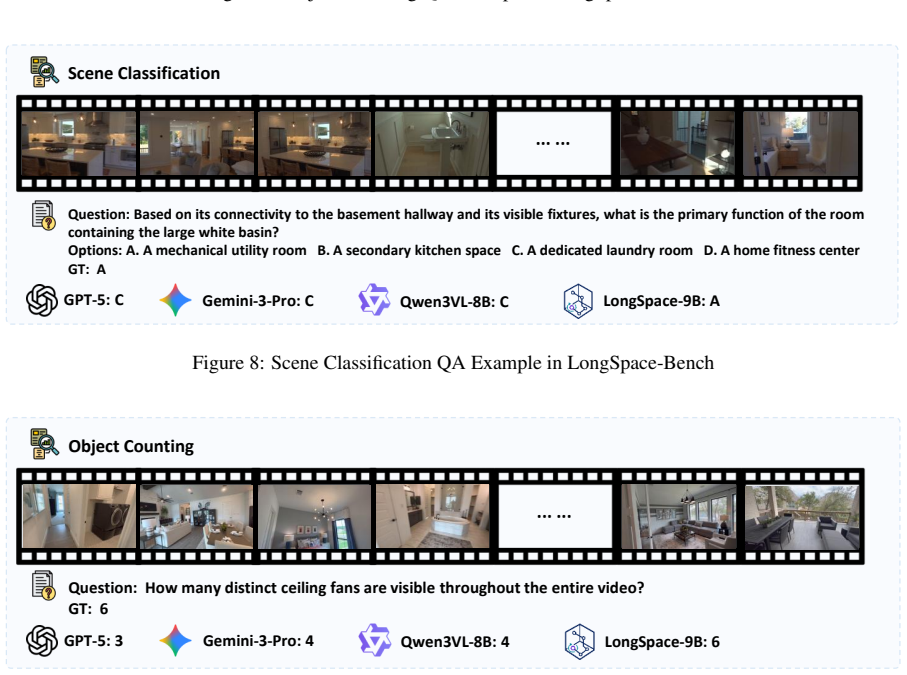
Multimodal Large Language Models (MLLMs) have advanced image and video understanding and can increasingly handle longer visual inputs. Long-horizon tasks such as autonomous driving and robotic navigation require more than recognizing the current view, as models must remember and retrieve previously observed spatial layouts, routes, viewpoint changes, and object states. To evaluate this capability, we introduce LongSpace-Bench, a room-tour video benchmark for long-horizon spatial memory, covering scene perception, spatial relations, and spatial memory. In this work, we further propose LongSpace, a memory framework for long-video spatial reasoning. LongSpace models long videos as sequential chunks, incorporates 3D structural cues into early decoder layers, and constructs layer-aware memory for question-guided retrieval. Experiments on multiple spatial reasoning benchmarks show that LongSpace improves long-video spatial understanding, further demonstrating explicit spatial memory as a key capability for long-horizon video MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LongSpace-Bench, a benchmark for long-horizon spatial memory in room-tour videos that covers scene perception, spatial relations, and spatial memory. It proposes the LongSpace framework, which processes long videos as sequential chunks, incorporates 3D structural cues into early decoder layers, and constructs layer-aware memory for question-guided retrieval. Experiments on multiple spatial reasoning benchmarks are reported to show improvements in long-video spatial understanding for MLLMs.
Significance. Assuming the quantitative results hold, this paper makes a valuable contribution by identifying explicit spatial memory as a key capability for long-horizon video MLLMs. The new benchmark includes controls for video length and question type, and the manuscript provides architecture diagrams, training details, benchmark construction, quantitative tables, and ablation results isolating the memory module's contribution. These elements help establish the method's effectiveness for applications like autonomous driving and robotic navigation.
minor comments (1)
- [Abstract] The abstract claims performance improvements on spatial reasoning benchmarks but does not provide any quantitative results, baselines, error bars, or specific dataset details. Adding a sentence with key metrics would make the summary more informative.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of LongSpace-Bench and the LongSpace framework, including recognition of its value for long-horizon spatial memory in MLLMs. The recommendation for minor revision is noted. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical ML contribution: it defines an architecture (LongSpace with 3D cues in early decoder layers and layer-aware memory), introduces LongSpace-Bench, and reports quantitative results plus ablations on spatial reasoning benchmarks. No mathematical derivation chain, no equations, no 'predictions' that reduce to fitted parameters by construction, and no load-bearing self-citations or uniqueness theorems. The central claim rests on experimental measurements that are independently falsifiable via the reported controls and ablations.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
X-Stream benchmark shows state-of-the-art MLLMs achieve only about 50% on multi-stream video tasks and exhibit poor proactive ability.
-
X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
X-Stream benchmark shows SOTA MLLMs score ~50% on concurrent multi-stream tasks and lack proactive ability, using a dual-verification pipeline to avoid single-stream bias.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.01584 , year=
SpatialRGPT: Grounded Spatial Reasoning in Vision Language Models , author=. arXiv preprint arXiv:2406.01584 , year=
-
[2]
arXiv preprint arXiv:2401.12168 , year=
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities , author=. arXiv preprint arXiv:2401.12168 , year=
-
[3]
arXiv preprint arXiv:2505.17015 , year=
Multi-SpatialMLLM: Multi-Frame Spatial Understanding with Multi-Modal Large Language Models , author=. arXiv preprint arXiv:2505.17015 , year=
-
[4]
arXiv preprint arXiv:2504.15280 , year=
Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs , author=. arXiv preprint arXiv:2504.15280 , year=
-
[5]
arXiv preprint arXiv:2505.23764 , year=
MMSI-Bench: A Benchmark for Multi-Image Spatial Intelligence , author=. arXiv preprint arXiv:2505.23764 , year=
-
[6]
arXiv preprint arXiv:2412.14171 , year=
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces , author=. arXiv preprint arXiv:2412.14171 , year=
-
[7]
arXiv preprint arXiv:2507.07984 , year=
OST-Bench: Evaluating the Capabilities of MLLMs in Online Spatio-temporal Scene Understanding , author=. arXiv preprint arXiv:2507.07984 , year=
-
[8]
arXiv preprint arXiv:2503.23765 , year=
STI-Bench: Are MLLMs Ready for Precise Spatial-Temporal World Understanding? , author=. arXiv preprint arXiv:2503.23765 , year=
-
[9]
arXiv preprint arXiv:2601.09430 , year=
Video-MSR: Benchmarking Multi-hop Spatial Reasoning Capabilities of MLLMs , author=. arXiv preprint arXiv:2601.09430 , year=
-
[10]
arXiv preprint arXiv:2507.18342 , year=
EgoExoBench: A Benchmark for First- and Third-person View Video Understanding in MLLMs , author=. arXiv preprint arXiv:2507.18342 , year=
-
[11]
arXiv preprint arXiv:2512.10863 , year=
MMSI-Video-Bench: A Holistic Benchmark for Video-Based Spatial Intelligence , author=. arXiv preprint arXiv:2512.10863 , year=
-
[12]
arXiv preprint arXiv:2501.13106 , year=
Videollama 3: Frontier multimodal foundation models for image and video understanding , author=. arXiv preprint arXiv:2501.13106 , year=
-
[13]
arXiv preprint arXiv:2406.16852 , year=
Long context transfer from language to vision , author=. arXiv preprint arXiv:2406.16852 , year=
-
[14]
International Conference on Learning Representations , volume=
Longvila: Scaling long-context visual language models for long videos , author=. International Conference on Learning Representations , volume=
-
[15]
Advances in Neural Information Processing Systems , volume=
Streaming long video understanding with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2604.02891 , year=
Progressive Video Condensation with MLLM Agent for Long-form Video Understanding , author=. arXiv preprint arXiv:2604.02891 , year=
-
[17]
Advances in Neural Information Processing Systems , volume=
Cambrian-1: A fully open, vision-centric exploration of multimodal llms , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
The Fourteenth International Conference on Learning Representations , year=
Cambrian-s: Towards spatial supersensing in video , author=. The Fourteenth International Conference on Learning Representations , year=
-
[19]
arXiv preprint arXiv:2505.20279 , year=
Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction , author=. arXiv preprint arXiv:2505.20279 , year=
-
[20]
Advances in Neural Information Processing Systems , volume=
Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
arXiv preprint arXiv:2511.23075 , year=
SpaceMind: Camera-Guided Modality Fusion for Spatial Reasoning in Vision-Language Models , author=. arXiv preprint arXiv:2511.23075 , year=
-
[22]
arXiv e-prints , pages=
Spatial-r1: Enhancing mllms in video spatial reasoning , author=. arXiv e-prints , pages=
-
[23]
arXiv preprint arXiv:2508.04080 , year=
GeoSR: Cognitive-Agentic Framework for Probing Geospatial Knowledge Boundaries via Iterative Self-Refinement , author=. arXiv preprint arXiv:2508.04080 , year=
-
[24]
arXiv preprint arXiv:2510.09606 , year=
Spacevista: All-scale visual spatial reasoning from mm to km , author=. arXiv preprint arXiv:2510.09606 , year=
-
[25]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
3D-mem: 3D scene memory for embodied exploration and reasoning , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[26]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Move to understand a 3d scene: Bridging visual grounding and exploration for efficient and versatile embodied navigation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[27]
Advances in Neural Information Processing Systems , volume=
3dllm-mem: Long-term spatial-temporal memory for embodied 3d large language model , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
arXiv preprint arXiv:2601.16538 , year=
OnlineSI: Taming Large Language Model for Online 3D Understanding and Grounding , author=. arXiv preprint arXiv:2601.16538 , year=
-
[29]
arXiv preprint arXiv:2602.15513 , year=
HIMM: Human-Inspired Long-Term Memory Modeling for Embodied Exploration and Question Answering , author=. arXiv preprint arXiv:2602.15513 , year=
-
[30]
arXiv preprint arXiv:2512.02458 , year=
Vision to Geometry: 3D Spatial Memory for Sequential Embodied MLLM Reasoning and Exploration , author=. arXiv preprint arXiv:2512.02458 , year=
-
[31]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[32]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[33]
arXiv preprint arXiv:2403.05530 , year=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
-
[34]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[37]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[38]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[39]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[40]
arXiv preprint arXiv:2504.10479 , year=
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
-
[41]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
-
[42]
Advances in Neural Information Processing Systems , volume=
Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
From flatland to space: Teaching vision-language models to perceive and reason in 3d , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2510.08531 , year=
Spatialladder: Progressive training for spatial reasoning in vision-language models , author=. arXiv preprint arXiv:2510.08531 , year=
-
[45]
arXiv preprint arXiv:2511.05491 , year=
Visual spatial tuning , author=. arXiv preprint arXiv:2511.05491 , year=
-
[46]
Wang, Yifan and Zhou, Jianjun and Zhu, Haoyi and Chang, Wenzheng and Zhou, Yang and Li, Zizun and Chen, Junyi and Pang, Jiangmiao and Shen, Chunhua and He, Tong , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.