X-Stream: Exploring MLLMs as Multiplexers for Multi-Stream Understanding
Pith reviewed 2026-06-30 10:39 UTC · model grok-4.3
The pith
State-of-the-art multimodal large language models score only around 50 percent when required to reason across concurrent video streams.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
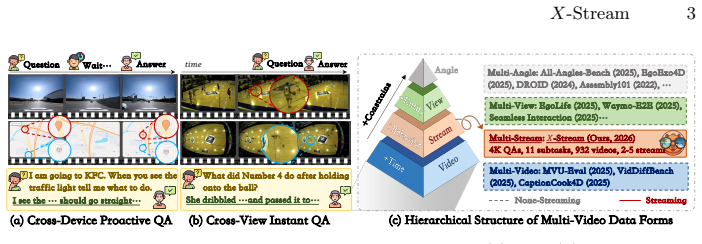
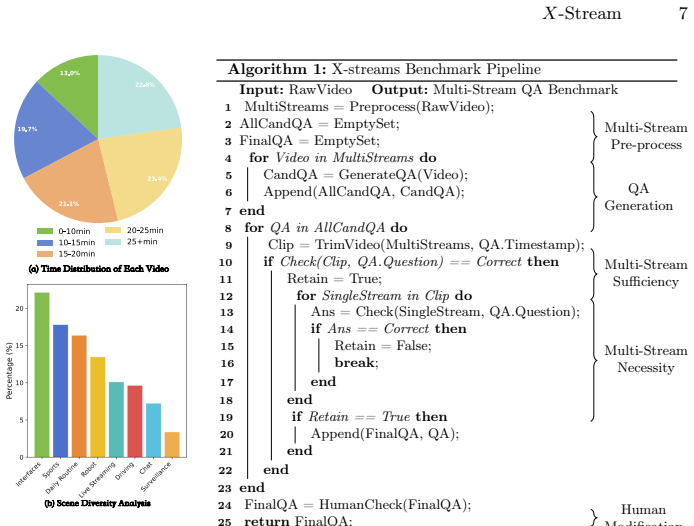
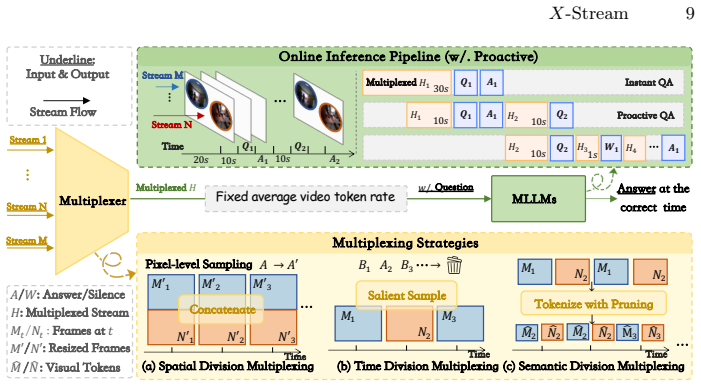
X-Stream supplies 4,220 QA pairs across 932 videos and 11 subtasks that evaluate online cross-stream reasoning in multi-window, multi-view, and multi-device scenarios. A dual-verification pipeline ensures each pair depends on multiple streams rather than any one alone. When current MLLMs are evaluated as naive multiplexers under Signal Multiplexing Theory, they reach only about 50 percent overall and show limited proactive behavior, revealing a concrete performance ceiling for existing multiplexing schemes.
What carries the argument
The X-Stream benchmark and its dual-verification pipeline, which together produce QA pairs that require simultaneous attention to several video streams, together with the explicit treatment of MLLMs as naive multiplexers evaluated through Signal Multiplexing Theory.
If this is right
- Existing single-stream benchmarks are insufficient for predicting performance in live multi-stream settings.
- Multiplexing schemes in current MLLMs must be redesigned to support proactive cross-stream selection.
- The dual-verification construction method can be reused to generate additional multi-stream datasets.
- Real-world systems for autonomous driving or multi-screen collaboration will need new evaluation protocols that include concurrent inputs.
Where Pith is reading between the lines
- Training regimes that expose models to synchronized multi-stream data during pre-training could raise the observed 50 percent ceiling.
- The same benchmark structure might be extended to audio or sensor streams to test whether the multiplexing limitation is modality-specific.
- If the performance gap persists across model scales, architectural changes such as explicit stream routers may become necessary rather than relying on scale alone.
Load-bearing premise
The dual-verification pipeline actually succeeds in making each QA pair depend on more than one stream rather than allowing models to answer from a single dominant stream.
What would settle it
An experiment in which an unmodified state-of-the-art MLLM scores well above 50 percent on the full set of 11 subtasks while still operating on the same 932 videos would directly contradict the reported performance ceiling.
Figures


read the original abstract
While video streaming understanding has made significant strides, real-world applications, such as live sports broadcasting, autonomous driving, and multi-screen collaboration, inherently demand continuous, multi-stream interactions. However, existing benchmarks are confined to single-stream paradigms, leaving a critical gap in evaluating online, cross-stream reasoning. To bridge this, we introduce X-Stream, the first benchmark dedicated to multi-stream streaming understanding. Comprising 4,220 rigorously curated QA pairs across 932 videos, X-Stream evaluates 11 subtasks across multi-window, multi-view, and multi-device scenarios. Crucially, our dataset is constructed using a novel dual-verification pipeline that prevents over-reliance on a single stream. Furthermore, we pioneer the conceptualization of multi-modal large language models (MLLMs) as naive multiplexers, systematically evaluating their performance through the lens of Signal Multiplexing Theory. Our extensive online inference experiments reveal a stark reality: state-of-the-art MLLMs struggle significantly with concurrent streams, achieving only about 50% score and exhibiting poor proactive ability. Ultimately, X-Stream exposes the trade-off of current multiplexing schemes, providing both a practical evaluation protocol and empirical guidance for next-generation multi-stream agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces X-Stream, the first benchmark for multi-stream streaming understanding in MLLMs. It comprises 4,220 QA pairs from 932 videos spanning 11 subtasks in multi-window, multi-view, and multi-device scenarios. A novel dual-verification pipeline is used during dataset construction to ensure questions require cross-stream reasoning rather than single-stream answers. The work frames MLLMs as naive multiplexers under Signal Multiplexing Theory and reports that state-of-the-art models achieve only ~50% accuracy with poor proactive ability on concurrent streams, exposing limitations in current multiplexing schemes and providing guidance for future multi-stream agents.
Significance. If the central empirical result holds and the benchmark questions are shown to require genuine multi-stream reasoning, the work would be significant: it fills a documented gap between existing single-stream video benchmarks and real-world applications (live sports, autonomous driving, multi-screen collaboration) that demand continuous cross-stream interaction. The framing via multiplexing theory and the online inference protocol could supply a reusable evaluation standard and concrete failure modes for next-generation MLLM agents.
major comments (2)
- [dataset construction paragraph] Dataset-construction paragraph: the assertion that the dual-verification pipeline 'prevents over-reliance on a single stream' is load-bearing for the headline claim that the observed ~50% score reflects multiplexing failure rather than ordinary video-understanding difficulty. No quantitative check (single-stream oracle accuracy, ablation removing one stream, or inter-annotator agreement conditioned on stream count) is described, so it remains possible that retained questions remain answerable from any individual stream.
- [results / online inference experiments] Results section (online inference experiments): the claim that SOTA MLLMs 'struggle significantly with concurrent streams' and exhibit 'poor proactive ability' rests on the 4,220 QA pairs being information-theoretically dependent on multiple streams. Without the missing single-stream controls or ablation, the performance gap cannot be attributed specifically to multiplexing rather than task hardness.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for quantitative validation that our benchmark questions require genuine cross-stream reasoning. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [dataset construction paragraph] Dataset-construction paragraph: the assertion that the dual-verification pipeline 'prevents over-reliance on a single stream' is load-bearing for the headline claim that the observed ~50% score reflects multiplexing failure rather than ordinary video-understanding difficulty. No quantitative check (single-stream oracle accuracy, ablation removing one stream, or inter-annotator agreement conditioned on stream count) is described, so it remains possible that retained questions remain answerable from any individual stream.
Authors: We agree that the dual-verification pipeline claim requires quantitative support to rule out single-stream solvability. In the revised manuscript we will add (i) single-stream oracle accuracy results on the full 4,220 QA pairs and (ii) ablations that remove one stream at inference time, together with inter-annotator agreement broken down by number of streams. These controls will directly demonstrate that retained questions cannot be answered from any individual stream alone. revision: yes
-
Referee: [results / online inference experiments] Results section (online inference experiments): the claim that SOTA MLLMs 'struggle significantly with concurrent streams' and exhibit 'poor proactive ability' rests on the 4,220 QA pairs being information-theoretically dependent on multiple streams. Without the missing single-stream controls or ablation, the performance gap cannot be attributed specifically to multiplexing rather than task hardness.
Authors: We acknowledge that the attribution of the ~50% performance and poor proactive ability specifically to multiplexing limitations depends on confirming multi-stream dependency. The single-stream oracle and ablation experiments described in the response to the first comment will be added to the results section, allowing us to isolate the effect of concurrent streams from general task difficulty. revision: yes
Circularity Check
No circularity: benchmark construction and evaluation are independent of self-citations or fitted inputs.
full rationale
The paper introduces X-Stream as a new benchmark with 4,220 QA pairs built via a described dual-verification pipeline and evaluates off-the-shelf MLLMs on it. No equations, parameters, or derivations appear in the abstract or described sections. No self-citation is invoked to justify uniqueness, multiplexing theory, or the pipeline itself. The central empirical claim (SOTA models at ~50%) is a direct measurement on the new data, not a reduction to prior fitted values or author-defined constructs. This is a standard benchmark paper with self-contained content against external models.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.22554 (2025) 4, 5, 22, 29
Agrawal, V., Akinyemi, A., Alvero, K., Behrooz, M., Buffalini, J., Carlucci, F.M., Chen, J., Chen, J., Chen, Z., Cheng, S., et al.: Seamless interaction: Dyadic audio- visual motion modeling and large-scale dataset. arXiv preprint arXiv:2506.22554 (2025) 4, 5, 22, 29
-
[2]
System card, Anthropic (Sep 2025), https : / / www - cdn
Anthropic: Claude sonnet 4.5 system card. System card, Anthropic (Sep 2025), https : / / www - cdn . anthropic . com / 963373e433e489a87a10c823c52a0a013e9172dd.pdf2
2025
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
arXiv preprint arXiv:2503.07860 (2025) 4, 8
Burgess, J., Wang, X., Zhang, Y., Rau, A., Lozano, A., Dunlap, L., Darrell, T., Yeung-Levy, S.: Video action differencing. arXiv preprint arXiv:2503.07860 (2025) 4, 8
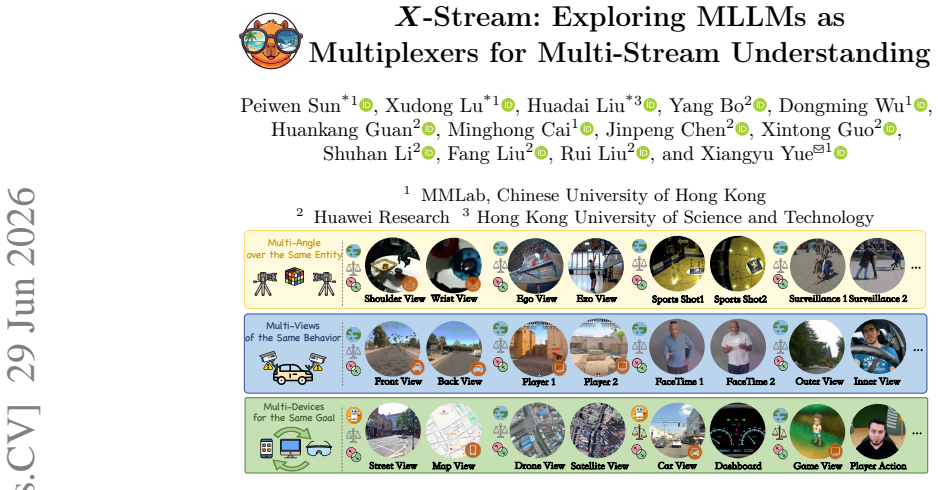
-
[6]
Available at Volcengine ARK Platform (2026) 11, 12
ByteDance: Doubao-seed-1.8. Available at Volcengine ARK Platform (2026) 11, 12
2026
-
[7]
https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild- tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0 Model Card.pdf (2026), accessed: 2026- 02-26 3
ByteDance Seed Team: Seed2.0 model card: Towards intelligence frontier for real-world complexity. https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild- tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0 Model Card.pdf (2026), accessed: 2026- 02-26 3
2026
-
[8]
Chavdarova, T., Baqué, P., Bouquet, S., Maksai, A., Jose, C., Bagautdinov, T., Lettry, L., Fua, P., Van Gool, L., Fleuret, F.: Wildtrack: A multi-camera hd dataset for dense unscripted pedestrian detection–supplementary material– 22, 29
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, J., Lv, Z., Wu, S., Lin, K.Q., Song, C., Gao, D., Liu, J.W., Gao, Z., Mao, D., Shou, M.Z.: Videollm-online: Online video large language model for streaming video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18407–18418 (2024) 2, 4, 11, 12 16 P. Sun et al
2024
-
[10]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Chen, J., Zeng, Z., Lin, Y., Li, W., Ma, Z., Shou, M.Z.: Livecc: Learning video llm with streaming speech transcription at scale. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29083–29095 (2025) 8
2025
-
[11]
Advances in Neural Information Processing Systems37, 28662–28673 (2024) 3
Chen, J.J., Liao, Y.C., Lin, H.C., Yu, Y.C., Chen, Y.C., Wang, F.: Rextime: A benchmark suite for reasoning-across-time in videos. Advances in Neural Information Processing Systems37, 28662–28673 (2024) 3
2024
-
[12]
IEEE Transactions on Affective Computing13(2), 651–665 (2019) 22, 29
Chen, X., Niu, L., Veeraraghavan, A., Sabharwal, A.: Faceengage: Robust estimation of gameplay engagement from user-contributed (youtube) videos. IEEE Transactions on Affective Computing13(2), 651–665 (2019) 22, 29
2019
-
[13]
arXiv preprint arXiv:2503.11495 (2025) 3
Cheng, Z., Hu, J., Liu, Z., Si, C., Li, W., Gong, S.: V-star: Benchmarking video-llms on video spatio-temporal reasoning. arXiv preprint arXiv:2503.11495 (2025) 3
-
[14]
Moshi: a speech-text foundation model for real-time dialogue
Défossez, A., Mazaré, L., Orsini, M., Royer, A., Pérez, P., Jégou, H., Grave, E., Zeghidour, N.: Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037 (2024) 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fan, H., Qiao, Y., Zhen, Y., Zhao, T., Fan, B., Wang, Q.: All-day multi-camera multi- target tracking. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 16892–16901 (2025) 22, 29
2025
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fu, C., Dai, Y., Luo, Y., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24108–24118 (2025) 3
2025
-
[17]
Available at Google DeepMind Model Cards (2025) 2, 3, 11, 12
Google DeepMind: Gemini 3 pro model card. Available at Google DeepMind Model Cards (2025) 2, 3, 11, 12
2025
-
[18]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Grauman, K., Westbury, A., Torresani, L., Kitani, K., Malik, J., Afouras, T., Ashutosh, K., Baiyya, V., Bansal, S., Boote, B., et al.: Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19383–19400 (2024) 4, 22, 29
2024
-
[19]
ProMQA-Assembly: Multimodal Procedural QA Dataset on Assembly
Hasegawa, K., Imrattanatrai, W., Asada, M., Holm, S., Wang, Y., Zhou, V., Fukuda, K., Mitamura, T.: Promqa-assembly: Multimodal procedural qa dataset on assembly. arXiv preprint arXiv:2509.02949 (2025) 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
John Wiley & Sons, Inc., New York, 4th edn
Haykin, S.: Communication Systems. John Wiley & Sons, Inc., New York, 4th edn. (2001) 9
2001
-
[21]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture
Jain, A., Koppula, H.S., Soh, S., Raghavan, B., Singh, A., Saxena, A.: Brain4cars: Car that knows before you do via sensory-fusion deep learning architecture. arXiv preprint arXiv:1601.00740 (2016) 22, 29
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M.K., Chen, L.Y., Ellis, K., et al.: Droid: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945 (2024) 22, 29
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
LongSpace: Exploring Long-Horizon Spatial Memory from Perception to Recall in Video
Lang, S., Liu, J., He, H., Sun, P., Chen, Y., Liu, T., Yang, L., Guo, L., Zhang, H.: Longspace: Exploring long-horizon spatial memory from perception to recall in video. arXiv preprint arXiv:2606.05677 (2026) 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [25]
-
[26]
arXiv preprint arXiv:2601.22575 (2026) 4, 5, 8, 11
Lu, X., Guan, H., Bo, Y., Chen, J., Guo, X., Li, S., Liu, F., Sun, P., Li, X., Zhang, W., et al.: Phostream: Benchmarking real-world streaming for omnimodal assistants in mobile scenarios. arXiv preprint arXiv:2601.22575 (2026) 4, 5, 8, 11
-
[27]
Niu, J., Li, Y., Miao, Z., Ge, C., Zhou, Y., He, Q., Dong, X., Duan, H., Ding, S., Qian, R., et al.: Ovo-bench: How far is your video-llms from real-world online video understanding? In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18902–18913 (2025) 4, 8
2025
-
[28]
OpenAI: Gpt realtime,https://developers.openai.com/api/docs/models/gpt- realtime4
-
[29]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Park,S.Y., Cui,C.,Ma, Y.,Moradipari,A., Gupta,R.,Han, K.,Wang,Z.:Nuplanqa: A large-scale dataset and benchmark for multi-view driving scene understanding in multi-modal large language models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8066–8076 (2025) 4
2025
-
[30]
arXiv preprint arXiv:2511.07250 (2025) 4, 8
Peng, T., Wang, H., Zhang, Y., Wang, Z., Wang, Z., Chang, G., Yang, J., Li, S., Wang, Y., Wang, X., et al.: Mvu-eval: Towards multi-video understanding evaluation for multimodal llms. arXiv preprint arXiv:2511.07250 (2025) 4, 8
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qian, R., Ding, S., Dong, X., Zhang, P., Zang, Y., Cao, Y., Lin, D., Wang, J.: Dispider: Enabling video llms with active real-time interaction via disentangled perception, decision, and reaction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24045–24055 (2025) 2, 4, 11, 12
2025
-
[32]
Qwen Team: Qwen3.5: Towards native multimodal agents (February 2026),https: //qwen.ai/blog?id=qwen3.53
2026
-
[33]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 10
2021
-
[34]
A Commute in Data: The comma2k19 Dataset
Schafer,H.,Santana, E.,Haden,A., Biasini,R.:Acommutein data:Thecomma2k19 dataset. arXiv preprint arXiv:1812.05752 (2018) 5, 22, 23, 29
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Sener, F., Chatterjee, D., Shelepov, D., He, K., Singhania, D., Wang, R., Yao, A.: Assembly101: A large-scale multi-view video dataset for understanding procedural activities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21096–21106 (2022) 4
2022
-
[36]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al.: Openai gpt-5 system card. arXiv preprint arXiv:2601.03267 (2025) 2, 3, 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
SpaceVista: All-Scale Visual Spatial Reasoning from mm to km
Sun, P., Lang, S., Wu, D., Ding, Y., Feng, K., Liu, H., Ye, Z., Liu, R., Liu, Y.H., Wang, J., et al.: Spacevista: All-scale visual spatial reasoning from mm to km. arXiv preprint arXiv:2510.09606 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
In: The Fourteenth International Conference on Learning Representations 10
Tang, C., Ek, S., Koch, D., Mullins, R.D., Weddell, A.S., Chauhan, J.: Surge: Surprise-guided token reduction for efficient video understanding with vlms. In: The Fourteenth International Conference on Learning Representations 10
-
[39]
arXiv preprint arXiv:2506.13654 (2025) 4
Tian, S., Wang, R., Guo, H., Wu, P., Dong, Y., Wang, X., Yang, J., Zhang, H., Zhu, H., Liu, Z.: Ego-r1: Chain-of-tool-thought for ultra-long egocentric video reasoning. arXiv preprint arXiv:2506.13654 (2025) 4
-
[40]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025) 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 3 18 P. Sun et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, X., Kwon, T., Rad, M., Pan, B., Chakraborty, I., Andrist, S., Bohus, D., Feniello, A., Tekin, B., Frujeri, F.V., et al.: Holoassist: an egocentric human interaction dataset for interactive ai assistants in the real world. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20270–20281 (2023) 4
2023
-
[43]
arXiv preprint arXiv:2512.06810 (2025) 4, 8, 11, 12
Wang, Y., Liu, S., Wang, D., Xu, N., Wan, G., Zhang, H., Zhao, D.: Mmduet2: Enhancing proactive interaction of video mllms with multi-turn reinforcement learning. arXiv preprint arXiv:2512.06810 (2025) 4, 8, 11, 12
-
[44]
arXiv preprint arXiv:2507.09313 (2025) 4, 5, 8
Wang, Y., Meng, X., Wang, Y., Zhang, H., Zhao, D.: Proactivevideoqa: A com- prehensive benchmark evaluating proactive interactions in video large language models. arXiv preprint arXiv:2507.09313 (2025) 4, 5, 8
-
[45]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Y., Wang, Y., Chen, B., Wu, T., Zhao, D., Zheng, Z.: Omnimmi: A com- prehensive multi-modal interaction benchmark in streaming video contexts. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18925–18935 (2025) 4, 8
2025
-
[46]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Wu, D., Liu, F., Hung, Y.H., Duan, Y.: Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence. arXiv preprint arXiv:2505.23747 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
In: Proceedings of the AAAI conference on artificial intelligence
Wu, D., Han, W., Liu, Y., Wang, T., Xu, C.z., Zhang, X., Shen, J.: Language prompt for autonomous driving. In: Proceedings of the AAAI conference on artificial intelligence. vol. 39, pp. 8359–8367 (2025) 4
2025
-
[48]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wu, D., Wang, T., Zhang, Y., Zhang, X., Shen, J.: Onlinerefer: A simple online baseline for referring video object segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2761–2770 (2023) 4
2023
-
[49]
arXiv preprint arXiv:2512.03405 (2025) 4
Wu, J., Li, S., Bian, Z., Chen, J., Wen, R., Ping, A., He, Y., Wang, J., Zhang, Y., Liu, J.: Vidic: Video difference captioning. arXiv preprint arXiv:2512.03405 (2025) 4
-
[50]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Wu, Z., Chen, X., Pan, Z., Liu, X., Liu, W., Dai, D., Gao, H., Ma, Y., Wu, C., Wang, B., et al.: Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding. arXiv preprint arXiv:2412.10302 (2024) 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Streaming Video Instruction Tuning
Xia, J., Chen, P., Zhang, M., Sun, X., Zhou, K.: Streaming video instruction tuning. arXiv preprint arXiv:2512.21334 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
arXiv preprint arXiv:2503.08221 (2025) 4
Xiao, J., Huang, N., Qiu, H., Tao, Z., Yang, X., Hong, R., Wang, M., Yao, A.: Egoblind: Towards egocentric visual assistance for the blind people. arXiv preprint arXiv:2503.08221 (2025) 4
-
[53]
Xu, J., Guo, Z., He, J., Hu, H., He, T., Bai, S., Chen, K., Wang, J., Fan, Y., Dang, K., Zhang, B., Wang, X., Chu, Y., Lin, J.: Qwen2.5-omni technical report (2025), https://arxiv.org/abs/2503.2021511
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Xu, J., Guo, Z., Hu, H., Chu, Y., Wang, X., He, J., Wang, Y., Shi, X., He, T., Zhu, X., Lv, Y., Wang, Y., Guo, D., Wang, H., Ma, L., Zhang, P., Zhang, X., Hao, H., Guo, Z., Yang, B., Zhang, B., Ma, Z., Wei, X., Bai, S., Chen, K., Liu, X., Wang, P., Yang, M., Liu, D., Ren, X., Zheng, B., Men, R., Zhou, F., Yu, B., Yang, J., Yu, L., Zhou, J., Lin, J.: Qwen3...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Xu, R., Lin, H., Jeon, W., Feng, H., Zou, Y., Sun, L., Gorman, J., Tolstaya, E., Tang, S., White, B., et al.: Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125 (2025) 4, 8, 22, 29
-
[56]
StreamingVLM: Real-Time Understanding for Infinite Video Streams
Xu, R., Xiao, G., Chen, Y., He, L., Peng, K., Lu, Y., Han, S.: Streamingvlm: Real-time understanding for infinite video streams. arXiv preprint arXiv:2510.09608 (2025) 4, 8 X-Stream 19
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
arXiv preprint arXiv:2405.11936 (2024) 22, 29
Xu, W., Yao, Y., Cao, J., Wei, Z., Liu, C., Wang, J., Peng, M.: Uav-visloc: A large-scale dataset for uav visual localization. arXiv preprint arXiv:2405.11936 (2024) 22, 29
-
[58]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Liu, S., Guo, H., Dong, Y., Zhang, X., Zhang, S., Wang, P., Zhou, Z., Xie, B., Wang, Z., et al.: Egolife: Towards egocentric life assistant. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28885–28900 (2025) 4, 5, 8, 22, 29
2025
-
[59]
arXiv preprint arXiv:2502.10810 (2025) 4
Yang, Z., Hu, Y., Du, Z., Xue, D., Qian, S., Wu, J., Yang, F., Dong, W., Xu, C.: Svbench: A benchmark with temporal multi-turn dialogues for streaming video understanding. arXiv preprint arXiv:2502.10810 (2025) 4
-
[60]
Yeh, C.H., Wang, C., Tong, S., Cheng, T.Y., Wang, R., Chu, T., Zhai, Y., Chen, Y., Gao, S., Ma, Y.: Seeing from another perspective: Evaluating multi-view under- standing in mllms. arXiv preprint arXiv:2504.15280 (2025) 4
-
[61]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Yu, T., Wang, Z., Wang, C., Huang, F., Ma, W., He, Z., Cai, T., Chen, W., Huang, Y., Zhao, Y., et al.: Minicpm-v 4.5: Cooking efficient mllms via architecture, data, and training recipe. arXiv preprint arXiv:2509.18154 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
In: Pro- ceedings of the AAAI Conference on Artificial Intelligence
Yu, Z., Xu, D., Yu, J., Yu, T., Zhao, Z., Zhuang, Y., Tao, D.: Activitynet-qa: A dataset for understanding complex web videos via question answering. In: Pro- ceedings of the AAAI Conference on Artificial Intelligence. pp. 9127–9134 (2019) 3
2019
-
[63]
https://sites.uclouvain.be/ispgroup/Softwares/DeepSport, refs: 3, 4, 7 22, 29
Zandycke, G.V.: DeepSport – Image and Signal Processing Group (UCL) softwares. https://sites.uclouvain.be/ispgroup/Softwares/DeepSport, refs: 3, 4, 7 22, 29
-
[64]
arXiv preprint arXiv:2506.10967 (2025) 10
Zhang, Q., Liu, M., Li, L., Lu, M., Zhang, Y., Pan, J., She, Q., Zhang, S.: Beyond attention or similarity: Maximizing conditional diversity for token pruning in mllms. arXiv preprint arXiv:2506.10967 (2025) 10
-
[65]
arXiv preprint arXiv:2510.14560 (2025) 8 20 P
Zhang, Y., Shi, C., Wang, Y., Yang, S.: Eyes wide open: Ego proactive video-llm for streaming video. arXiv preprint arXiv:2510.14560 (2025) 8 20 P. Sun et al. In this supplementary material, we provide two key components. • we release a preview version of theevaluation codein the attached com- pressed file. • we includeadditional informationfor the reader...
-
[66]
Cross-stream Interference Noise Filtering Target stream A + distracting stream B→ answer from A In a split-screen setting, identify what the blue-haired girl in Stream 2 needs to do while ignoring visually salient but irrelevant actions in Stream 1. Contradiction Suppression Relevant cue in A + misleading cue in B→ robust answer Determine whether pressing...
-
[67]
Multi-stream Cooperation Complementary Reasoning Clue in A + clue in B→ answer Did the driver looking at the phone (Inner) cause the lane deviation (Outer)? Multi-stream Evidence Aggregation Partial evidence from A and B→joint conclusion Detect an abnormal event only after combining surveillance footage from two different viewpoints
-
[68]
Cross-stream Reference Cross-view Localization Object/entity in A→ corresponding object/entity in B Where is the screw seen in the robotic arm view located in the global view? Temporal / Event Alignment Event in A↔event or state in B What facial expression (Player) was caused by the character’s death (Game)?
-
[69]
Single-stream Understanding Stream-specific Perception Query specifies one stream within a multi-stream context→ answer from that stream In Stream 2, what is the woman holding when she enters the room? Local Grounding in Context Grounding/ counting/ recognition in A while other streams are present In Stream 1, how many buttons are visible on the control p...
-
[70]
Different angle of the same object Robotics(shoulder + wrist view) Manipulation failure diag- nosis Why did the robot fail to insert the plug? The shoulder view shows that the arm reached the socket area, while the wrist view reveals that the plug was slightly misaligned. Egocentric video(ego + exo view) Referring expression resolu- tion Which ingredient ...
-
[71]
Different views of the same behavior Autonomous driving (front + rear view) Causal explanation of driv- ing decisions Why did the vehicle avoid changing lanes despite an open front view? The forward camera shows a clear lane, whereas the rear camera reveals a fast-approaching ambulance in the blind spot. Collaborative gaming (player 1 + player 2 view) Tea...
-
[72]
Different devices of the same goal Geo-localization (street view + map) Visual entity linking What is the name of the company located in the blue build- ing? The street view identifies the building, and the map stream links its location to the corresponding business entry. Aerial inspection (drone + satellite view) Structural condition assess- ment Is the...
-
[73]
Qwen3-VL:28 ×28 pixel patches per token with token merging.3) GPT-5: 85 tokens/frame + 170 tokens per 512×512 tile. Since these mechanisms require different adjustments, speeding and resizing videos are necessary compromises to establish a baseline.rn and rn (Cmax=250) depend on the pixel dimensions to ensure: 1) GPT: a maximum edge of512; 2) Qwen:511×383...
-
[74]
What is the person doing in Stream A when the door opens in Stream B?
Pseudo Reference Invalid T emporal Anchoring Occurs when the target action is continuous or static, rendering the cross-stream temporal constraint meaningless. Since the answer is invariant to time, the specific timestamp from the reference stream becomes redundant. Query:"What is the person doing in Stream A when the door opens in Stream B?" Issue:The pe...
-
[75]
Identify the object held by the person
Pseudo Coop. Information Redundancy Happens when streams share overlapping fields of view or semantic content. The model can resolve the query using a single stream alone, bypassing the need for genuine multi-view fusion or collaboration. Query:"Identify the object held by the person." Issue:Due to overlapping views, the object is clearly visible in Strea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.