UNIVID: Unified Vision-Language Model for Video Moderation
Pith reviewed 2026-06-27 22:54 UTC · model grok-4.3
The pith
UNIVID generates policy-aware captions from one vision-language model to replace over 1,000 specialized classifiers in video moderation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
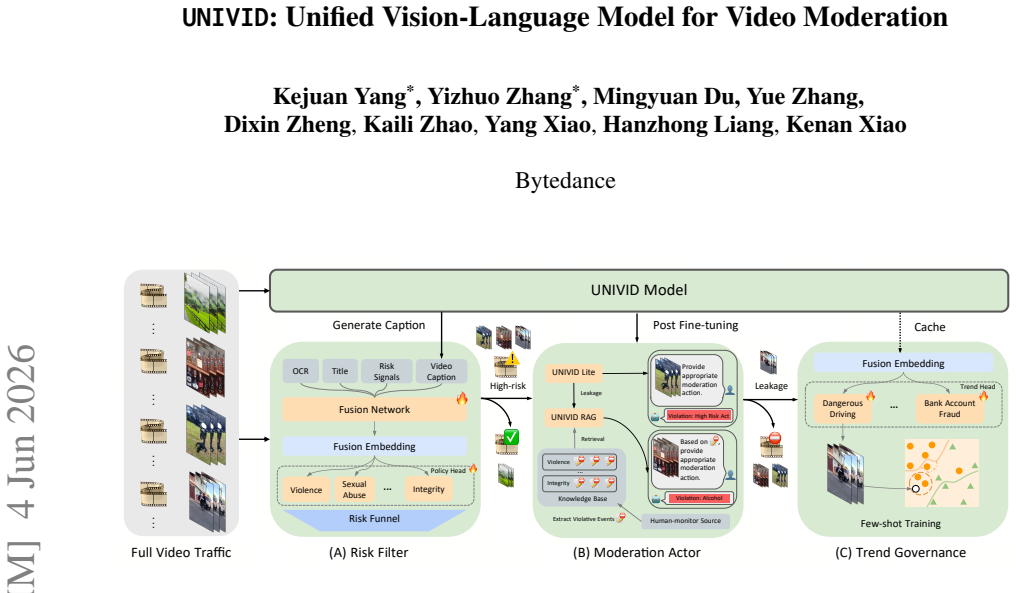
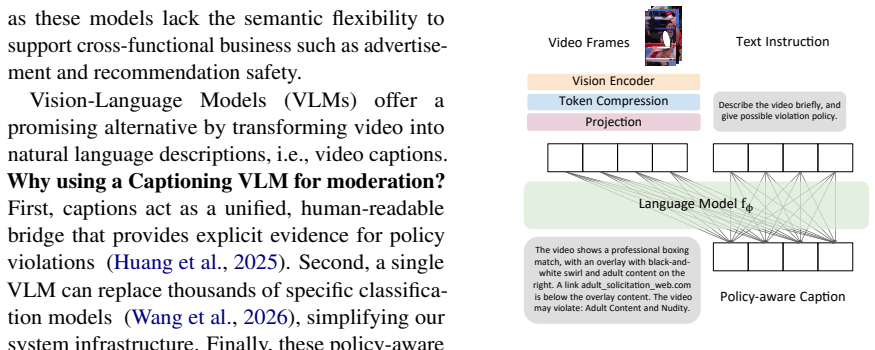
UNIVID generates policy-aware captions that serve as an interpretable intermediate representation for video moderation. A specialized training recipe that mixes expert human-refined labels with synthetic data aligns the model to target safety guidelines and avoids the refusal problems common in other vision-language models. When this model acts as the core captioner in a novel end-to-end moderation pipeline, violation leakage falls by 42.7 percent and overkill rate by 37.0 percent relative to earlier systems; simultaneously more than 1,000 policy-specific models are replaced by the single UNIVID backbone, recycling computation resources and cutting maintenance overhead.
What carries the argument
UNIVID, the unified vision-language model that produces policy-aware captions as the interpretable intermediate representation between raw video and final moderation decisions.
If this is right
- A single UNIVID backbone can perform the work previously requiring more than 1,000 separate policy-specific models.
- The end-to-end system achieves a 42.7 percent relative drop in violation leakage.
- The system achieves a 37.0 percent relative drop in overkill rate.
- Policy-aware captions enable human-verifiable decisions and multi-task reusability.
- Engineering maintenance overhead decreases because only one model needs updates and monitoring.
Where Pith is reading between the lines
- The captioning approach could be tested on image or text moderation pipelines to see whether the same accuracy and maintenance gains appear.
- Heavy reliance on synthetic data for alignment raises the question of how well the model would adapt if safety guidelines change frequently.
- Because captions are human-readable, they might allow faster root-cause analysis when moderation errors still occur.
Load-bearing premise
The specialized training data recipe that combines expert human-refined labels with synthetic data successfully aligns the model to the target safety guidelines without introducing new refusal behaviors or systematic biases.
What would settle it
A side-by-side evaluation on the same video corpus that shows no reduction in violation leakage or overkill rate when the UNIVID-based pipeline replaces the previous set of classifiers.
Figures



read the original abstract
Global-scale video moderation faces a dual challenge: the need for fine-grained multi-modal reasoning and the demand for interpretable outputs to support downstream enforcement. Traditional moderation systems often rely on fragmented black-box classifiers that are difficult to maintain and lack transparency. In this paper, we present UNIVID, a UNIfied VIsion-language model for video moDeration. Unlike standard classification models, UNIVID generates policy-aware captions that serve as an interpretable intermediate representation, enabling human-verifiable decisions and multi-task reusability. While existing open-source and commercial VLMs often suffer from safety-guardrail refusals and lack fine-grained policy alignment, we develop a specialized training data recipe that combines expert human-refined labels with synthetic data to align the model with our safety guidelines. By integrating UNIVID as the core captioner, we design a novel end-to-end video moderation system that reduces violation leakage by 42.7% and overkill rate by 37.0% relatively. Meanwhile, by replacing over 1,000 policy-specific models with a single UNIVID backbone, we recycled extensive computation resources while reducing engineering maintenance overhead. To our knowledge, this is one of the first reports of a high-efficiency captioning VLM successfully supporting industrial-scale moderation and cross-functional business.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces UNIVID, a unified vision-language model for video moderation that generates policy-aware captions as an interpretable intermediate representation rather than direct classifications. It describes a specialized training recipe combining expert human-refined labels with synthetic data to align the model to safety guidelines, and claims that integrating UNIVID into an end-to-end moderation pipeline yields relative reductions of 42.7% in violation leakage and 37.0% in overkill rate while replacing over 1,000 policy-specific models with a single backbone.
Significance. If the empirical claims hold under rigorous evaluation, the work could be significant for industrial-scale video moderation by demonstrating how a single captioning VLM can improve interpretability, reduce maintenance overhead, and consolidate compute resources. The focus on policy-aware outputs addresses a practical need for human-verifiable decisions in content moderation systems.
major comments (3)
- [Abstract, §5] Abstract and §5 (Experimental Results): The headline performance claims (42.7% leakage reduction, 37.0% overkill reduction) are stated without any description of the evaluation protocol, baseline systems, dataset sizes, statistical tests, or ablation studies, preventing assessment of whether the gains are attributable to UNIVID or to changes elsewhere in the pipeline.
- [§3.2] §3.2 (Training Data Recipe): The assertion that the expert-refined + synthetic data recipe aligns the model to safety guidelines without introducing new refusal behaviors or systematic biases is load-bearing for the central claims but is unsupported by any reported refusal-rate measurements on held-out policy edge cases or ablations isolating the synthetic component.
- [§4] §4 (System Integration): The claim of replacing >1,000 policy-specific models with a single UNIVID backbone is presented as a direct outcome, yet no details are given on how the downstream enforcement metrics were isolated from confounding pipeline modifications.
minor comments (2)
- [Abstract] Abstract: The terms 'violation leakage' and 'overkill rate' are introduced without explicit definitions or references to their computation, which reduces clarity for readers outside the immediate moderation domain.
- The manuscript would benefit from a dedicated limitations section discussing potential failure modes of the captioning approach on edge-case videos.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. The feedback identifies important areas where additional detail will strengthen the presentation of our results and methods. We address each major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Experimental Results): The headline performance claims (42.7% leakage reduction, 37.0% overkill reduction) are stated without any description of the evaluation protocol, baseline systems, dataset sizes, statistical tests, or ablation studies, preventing assessment of whether the gains are attributable to UNIVID or to changes elsewhere in the pipeline.
Authors: We agree that the current presentation of results lacks sufficient detail for independent assessment. In the revised manuscript we will expand §5 to describe the full evaluation protocol, including the sizes of the training and held-out test sets, the baseline systems (the prior ensemble of policy-specific classifiers), the statistical tests used, and ablation studies that isolate UNIVID’s contribution from other pipeline changes. These additions will make clear that the reported relative reductions are measured under controlled conditions. revision: yes
-
Referee: [§3.2] §3.2 (Training Data Recipe): The assertion that the expert-refined + synthetic data recipe aligns the model to safety guidelines without introducing new refusal behaviors or systematic biases is load-bearing for the central claims but is unsupported by any reported refusal-rate measurements on held-out policy edge cases or ablations isolating the synthetic component.
Authors: We acknowledge that explicit measurements of refusal rates and component ablations would provide stronger support for the training recipe. In the revision we will add refusal-rate statistics on held-out policy edge cases and an ablation that isolates the synthetic-data component, thereby documenting that the combined recipe improves policy alignment without introducing new refusal behaviors. revision: yes
-
Referee: [§4] §4 (System Integration): The claim of replacing >1,000 policy-specific models with a single UNIVID backbone is presented as a direct outcome, yet no details are given on how the downstream enforcement metrics were isolated from confounding pipeline modifications.
Authors: We will revise §4 to include a clearer description of the experimental controls used when measuring downstream enforcement metrics. Specifically, we will explain how the captioner was swapped into the existing pipeline while holding other components fixed, thereby isolating the effect of the single UNIVID backbone from other potential changes. revision: yes
Circularity Check
No circularity; empirical performance claims rest on measured outcomes
full rationale
The paper presents UNIVID as a trained VLM whose policy-aware captions are produced via a described data recipe (expert labels + synthetic data), then reports measured system-level improvements (42.7% leakage reduction, 37.0% overkill reduction) and resource savings from replacing >1000 models. These are framed as experimental results from integration, not quantities derived from equations or definitions that loop back to the same fitted values. No equations appear, no parameters are fitted then renamed as predictions, and no self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks: the gains are falsifiable measurements rather than tautological re-statements of the training procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2026 , title=
About Instagram , publisher=. 2026 , title=
2026
-
[2]
2026 , url=
YouTube , journal=. 2026 , url=
2026
-
[3]
Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
CPFD: Confidence-aware Privileged Feature Distillation for Short Video Classification , author=. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management , pages=
-
[4]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
Filter-And-Refine: A MLLM Based Cascade System for Industrial-Scale Video Content Moderation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
-
[5]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Embedding-based Retrieval in Multi-Modal Content Moderation , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[6]
Human Moderators: A Comparative Evaluation of Multimodal LLMs in Content Moderation for Brand Safety , author=
AI vs. Human Moderators: A Comparative Evaluation of Multimodal LLMs in Content Moderation for Brand Safety , author=. 2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW) , year=
2025
-
[7]
arXiv preprint arXiv:2505.23386 , year=
VModA: An Effective Framework for Adaptive NSFW Image Moderation , author=. arXiv preprint arXiv:2505.23386 , year=
-
[8]
Ai is removing bottlenecks to effective content moderation at scale , url=
Willner, Dave , year=. Ai is removing bottlenecks to effective content moderation at scale , url=. Tech Policy Press , publisher=
-
[9]
Knowledge-Based Systems , pages=
A comprehensive review of llm-based content moderation: Advancements, challenges, and future directions , author=. Knowledge-Based Systems , pages=. 2025 , publisher=
2025
-
[10]
2026 , url=
From Native Memes to Global Moderation: Cros-Cultural Evaluation of Vision-Language Models for Hateful Meme Detection , author=. 2026 , url=
2026
-
[11]
2025 , eprint=
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning , author=. 2025 , eprint=
2025
-
[12]
2025 , eprint=
LLaVAShield: Safeguarding Multimodal Multi-Turn Dialogues in Vision-Language Models , author=. 2025 , eprint=
2025
-
[13]
Sensors , volume=
VIPS: Learning-View-Invariant Feature for Person Search , author=. Sensors , volume=. 2025 , publisher=
2025
-
[14]
arXiv preprint arXiv:2505.15389 , year=
Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study , author=. arXiv preprint arXiv:2505.15389 , year=
-
[15]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Vlm as policy: Common-law content moderation framework for short video platform , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[16]
2023 , eprint=
EVA-CLIP: Improved Training Techniques for CLIP at Scale , author=. 2023 , eprint=
2023
-
[17]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Sigmoid loss for language image pre-training , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[18]
Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features , author=. arXiv preprint arXiv:2502.14786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2023 , url=
GPT-4V(ision) System Card , author=. 2023 , url=
2023
-
[20]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
ArXiv , year=
Mistral 7B , author=. ArXiv , year=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Reasoning-Enhanced Domain-Adaptive Pretraining of Multimodal Large Language Models for Short Video Content Governance , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[23]
2025 , pages=
Embedding-based Retrieval in Multi-Modal Content Moderation , author=. 2025 , pages=
2025
-
[24]
Tarsier: Recipes for training and evaluating large video description models,
Tarsier: Recipes for training and evaluating large video description models , author=. arXiv preprint arXiv:2407.00634 , year=
-
[25]
Social Network Analysis and Mining , year=
Detection and moderation of detrimental content on social media platforms: current status and future directions , author=. Social Network Analysis and Mining , year=
-
[26]
Big Data & Society ,year=
Algorithmic content moderation: Technical and political challenges in the automation of platform governance ,author=. Big Data & Society ,year=
-
[27]
Big Data & Society ,year=
Ethical scaling for content moderation: Extreme speech and the (in)significance of artificial intelligence ,author=. Big Data & Society ,year=
-
[28]
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems ,year=
Human-AI Collaboration via Conditional Delegation: A Case Study of Content Moderation ,author=. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems ,year=
2022
-
[29]
IEEE Access , year=
A Deep Learning-Based Approach for Inappropriate Content Detection and Classification of YouTube Videos , author=. IEEE Access , year=
-
[30]
Algorithms ,year=
Machine Learning- and Deep Learning-Based Multi-Model System for Hate Speech Detection on Facebook ,author=. Algorithms ,year=
-
[31]
Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
Validating Multimedia Content Moderation Software via Semantic Fusion , author=. Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
-
[32]
Advances in neural information processing systems , volume=
Flamingo: a visual language model for few-shot learning , author=. Advances in neural information processing systems , volume=
-
[33]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[34]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models , author=. arXiv preprint arXiv:2304.10592 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) , year=
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024) , year=
2024
-
[36]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Video-llava: Learning united visual representation by alignment before projection , author=. arXiv preprint arXiv:2311.10122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[38]
Llava-next: Improved reasoning, ocr, and world knowledge , author=
-
[39]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. arXiv preprint arXiv:2405.21075 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
MLVU: Benchmarking Multi-task Long Video Understanding
MLVU: A Comprehensive Benchmark for Multi-Task Long Video Understanding , author=. arXiv preprint arXiv:2406.04264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[42]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Train short, test long: Attention with linear biases enables input length extrapolation , author=. arXiv preprint arXiv:2108.12409 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Extending Context Window of Large Language Models via Positional Interpolation
Extending context window of large language models via positional interpolation , author=. arXiv preprint arXiv:2306.15595 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2401.01325 , year=
Llm maybe longlm: Self-extend llm context window without tuning , author=. arXiv preprint arXiv:2401.01325 , year=
-
[45]
Long Context Transfer from Language to Vision
Long Context Transfer from Language to Vision , author=. arXiv preprint arXiv:2406.16852 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
LongVILA: Scaling Long-Context Visual Language Models for Long Videos
Longvila: Scaling long-context visual language models for long videos , author=. arXiv preprint arXiv:2408.10188 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume=
Lgdn: Language-guided denoising network for video-language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
NeurIPS , year =
Self-Chained Image-Language Model for Video Localization and Question Answering , author =. NeurIPS , year =
-
[49]
European Conference on Computer Vision , year=
LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models , author=. European Conference on Computer Vision , year=
-
[50]
arXiv preprint arXiv:2402.14848 , year=
Same task, more tokens: the impact of input length on the reasoning performance of large language models , author=. arXiv preprint arXiv:2402.14848 , year=
-
[51]
arXiv preprint arXiv:2311.08046 , year=
Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding , author=. arXiv preprint arXiv:2311.08046 , year=
-
[52]
arXiv preprint arXiv:2312.17235 , year=
A simple llm framework for long-range video question-answering , author=. arXiv preprint arXiv:2312.17235 , year=
-
[53]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Retrieving-to-answer: Zero-shot video question answering with frozen large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[54]
arXiv preprint arXiv:2403.10517 , year=
Videoagent: Long-form video understanding with large language model as agent , author=. arXiv preprint arXiv:2403.10517 , year=
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Revisiting the" video" in video-language understanding , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
arXiv preprint arXiv:2301.11507 , year=
Semi-parametric video-grounded text generation , author=. arXiv preprint arXiv:2301.11507 , year=
-
[57]
IEEE Transactions on Multimedia , year=
Locate before answering: Answer guided question localization for video question answering , author=. IEEE Transactions on Multimedia , year=
-
[58]
arXiv preprint arXiv:2409.20018 , year=
Visual Context Window Extension: A New Perspective for Long Video Understanding , author=. arXiv preprint arXiv:2409.20018 , year=
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A simple recipe for contrastively pre-training video-first encoders beyond 16 frames , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[60]
2024 , eprint=
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , author=. 2024 , eprint=
2024
-
[61]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[62]
LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
2024 , eprint=
Video Instruction Tuning With Synthetic Data , author=. 2024 , eprint=
2024
-
[64]
Ilharco, Gabriel and Wortsman, Mitchell and Wightman, Ross and Gordon, Cade and Carlini, Nicholas and Taori, Rohan and Dave, Achal and Shankar, Vaishaal and Namkoong, Hongseok and Miller, John and Hajishirzi, Hannaneh and Farhadi, Ali and Schmidt, Ludwig , title =. doi:10.5281/zenodo.5143773 , url =
-
[65]
2023 , eprint=
Sigmoid Loss for Language Image Pre-Training , author=. 2023 , eprint=
2023
-
[66]
2023 , eprint=
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment , author=. 2023 , eprint=
2023
-
[67]
arXiv preprint arXiv:2106.03764 , year=
On the expressive power of self-attention matrices , author=. arXiv preprint arXiv:2106.03764 , year=
-
[68]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
OpenAI , bibsource =. CoRR , keywords =. doi:10.48550/ARXIV.2303.08774 , eprint =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[70]
arXiv preprint arXiv:2406.04325 , year=
ShareGPT4Video: Improving Video Understanding and Generation with Better Captions , author=. arXiv preprint arXiv:2406.04325 , year=
-
[71]
Advances in Neural Information Processing Systems , volume=
Egoschema: A diagnostic benchmark for very long-form video language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[72]
arXiv preprint arXiv:2312.04817 , year=
Movqa: A benchmark of versatile question-answering for long-form movie understanding , author=. arXiv preprint arXiv:2312.04817 , year=
-
[73]
2024 , eprint=
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model , author=. 2024 , eprint=
2024
-
[74]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Found a reason for me? weakly-supervised grounded visual question answering using capsules , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[75]
European Conference on Computer Vision , pages=
Weakly supervised grounding for vqa in vision-language transformers , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[76]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Where does it exist: Spatio-temporal video grounding for multi-form sentences , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Can i trust your answer? visually grounded video question answering , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[78]
TVQA: Localized, Compositional Video Question Answering
Tvqa: Localized, compositional video question answering , author=. arXiv preprint arXiv:1809.01696 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Honeybee: Locality-enhanced Projector for Multimodal LLM , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[80]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Making the v in vqa matter: Elevating the role of image understanding in visual question answering , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.