Learning Geometric Representations from Videos for Spatial Intelligent Multimodal Large Language Models
Pith reviewed 2026-06-28 02:11 UTC · model grok-4.3
The pith
Distilling four geometric targets from videos restructures MLLM latent space to create spatial intelligence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
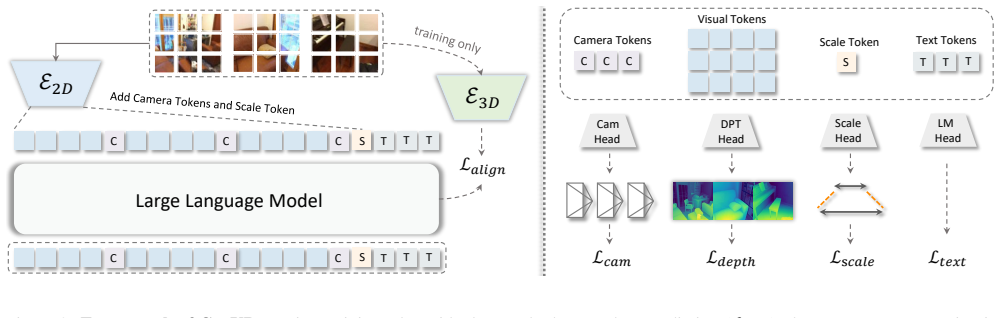
GeoVR learns geometric representations using purely 2D video sequences by distilling geometry knowledge from pre-trained 3D foundation models. This is accomplished through a multi-objective learning strategy driven by four complementary geometric targets: estimating inter-frame camera poses to embed varying viewpoint dynamics, regressing dense depth maps to anchor physical distances, predicting a metric scale factor for real-world calibration, and distilling multi-scale 3D features to align the intermediate feature space. Guided by these explicit physical and geometric constraints, the model's internal representations naturally develop strong 3D awareness and achieve state-of-the-art perform
What carries the argument
The multi-objective learning strategy driven by four complementary geometric targets distilled from pre-trained 3D models into the MLLM.
If this is right
- The model's internal representations naturally develop strong 3D awareness.
- GeoVR achieves state-of-the-art performance on spatial reasoning benchmarks.
- The approach establishes a new paradigm for endowing foundation models with spatial intelligence.
- It functions effectively even when large-scale 3D data is scarce.
Where Pith is reading between the lines
- The same targets could be used to add spatial consistency to video generation or editing models.
- The method may transfer to single-image inputs if the distilled features generalize beyond video sequences.
- Applications in robotics or AR could exploit the learned metric scale factor for calibrated outputs.
- Testing on held-out video domains would reveal whether the 3D awareness is robust to new camera motions.
Load-bearing premise
That distilling the four geometric targets from pre-trained 3D models into an MLLM via video will restructure its semantic latent space to produce genuine spatial intelligence rather than superficial feature alignment.
What would settle it
A spatial reasoning benchmark where the trained model shows no gain in cross-frame geometric consistency or 3D feature correlation compared with the base MLLM.
Figures




read the original abstract
Multimodal Large Language Models (MLLMs) excel at 2D semantic understanding but lack intrinsic 3D awareness, resulting in representations that fail to maintain geometric and spatial consistency across video frames. Given the scarcity of large-scale 3D data, we present GeoVR, a novel framework that learns geometric representations using purely 2D video sequences. This approach effectively restructures the semantic latent space within MLLMs to unlock spatial intelligence. Rather than employing superficial feature mixing, GeoVR reshapes the internal representations of the MLLM by distilling geometry knowledge from pre-trained 3D foundation models. This is accomplished through a multi-objective learning strategy driven by four complementary geometric targets: (1) estimating inter-frame camera poses to embed varying viewpoint dynamics, (2) regressing dense depth maps to anchor physical distances, (3) predicting a metric scale factor for real-world calibration, and (4) distilling multi-scale 3D features to align the intermediate feature space. Guided by these explicit physical and geometric constraints, the model's internal representations naturally develop strong 3D awareness. Extensive experiments on spatial reasoning benchmarks demonstrate that GeoVR achieves state-of-the-art performance, establishing a new paradigm for endowing foundation models with spatial intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GeoVR, a framework that distills geometric knowledge into MLLMs from 2D video sequences using four targets derived from pre-trained 3D foundation models: inter-frame camera pose estimation, dense depth map regression, metric scale factor prediction, and multi-scale 3D feature distillation. The central claim is that this multi-objective strategy restructures the MLLM's semantic latent space to produce intrinsic 3D awareness and spatial intelligence, yielding state-of-the-art results on spatial reasoning benchmarks.
Significance. If the four-target distillation can be shown to induce genuine internal restructuring for 3D awareness independent of the teacher models, the work would offer a practical route to spatial capabilities in MLLMs without requiring large-scale 3D data. The explicit use of complementary geometric constraints (pose, depth, scale, features) from video is a coherent design choice that merits further investigation.
major comments (3)
- [Abstract] Abstract: The claim that the approach 'restructures the semantic latent space within MLLMs to unlock spatial intelligence' and achieves SOTA performance is asserted without any reported baselines, ablation results, quantitative metrics, or representation diagnostics, making it impossible to assess whether the data support the central mechanism.
- [Method (four-target distillation)] Method description of the four-target strategy: No representation-level evidence (e.g., CCA between layers, linear probes on frozen backbone features, or controlled ablations isolating backbone changes from head training) is provided to demonstrate that the distillation produces internal 3D awareness rather than output-head alignment with the pre-trained teachers; this distinction is load-bearing for the claim of 'genuine' restructuring versus superficial imitation.
- [Experiments] Experiments section: The dependence on pre-trained 3D foundation models for all four targets is not accompanied by any analysis or controls showing that the resulting spatial reasoning is independent of those models' own training data and objectives, which directly affects whether the performance gains constitute a new derivation.
minor comments (1)
- [Abstract and Method] The abstract and method sections would benefit from explicit notation for the loss weights on the four geometric objectives to clarify the multi-objective optimization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence supporting our claims of internal representation restructuring. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the approach 'restructures the semantic latent space within MLLMs to unlock spatial intelligence' and achieves SOTA performance is asserted without any reported baselines, ablation results, quantitative metrics, or representation diagnostics, making it impossible to assess whether the data support the central mechanism.
Authors: We agree the abstract would be strengthened by explicit grounding. In the revision we will update the abstract to reference the specific SOTA margins, ablation results, and quantitative metrics reported in the experiments section. revision: yes
-
Referee: [Method (four-target distillation)] Method description of the four-target strategy: No representation-level evidence (e.g., CCA between layers, linear probes on frozen backbone features, or controlled ablations isolating backbone changes from head training) is provided to demonstrate that the distillation produces internal 3D awareness rather than output-head alignment with the pre-trained teachers; this distinction is load-bearing for the claim of 'genuine' restructuring versus superficial imitation.
Authors: The referee is correct that the manuscript currently relies on downstream task performance rather than direct representation diagnostics. We will add linear probe experiments on frozen backbone features and controlled ablations that isolate backbone changes from the prediction heads to provide this evidence in the revised method and experiments sections. revision: yes
-
Referee: [Experiments] Experiments section: The dependence on pre-trained 3D foundation models for all four targets is not accompanied by any analysis or controls showing that the resulting spatial reasoning is independent of those models' own training data and objectives, which directly affects whether the performance gains constitute a new derivation.
Authors: We acknowledge the absence of such controls. While complete independence from the teachers' training data is difficult to demonstrate without their original datasets, we will add a discussion of this point together with comparisons against direct teacher-model outputs and a note on the complementary nature of the four targets in the revised experiments section. revision: partial
Circularity Check
No circularity: derivation relies on external pre-trained models and empirical benchmarks
full rationale
The paper presents a distillation framework using four geometric targets from pre-trained 3D foundation models applied to video inputs for an MLLM. No equations, self-citations, or fitted parameters are shown reducing the claimed restructuring of latent space or SOTA benchmark results to the inputs by construction. The method is externally falsifiable via spatial reasoning benchmarks, and the pre-trained models constitute independent external support rather than a self-referential chain. This is a standard non-circular empirical approach.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weights for the four geometric objectives
axioms (2)
- domain assumption Distilling geometry from pre-trained 3D models via video will restructure MLLM representations to produce intrinsic 3D awareness rather than task-specific feature copying.
- domain assumption 2D video sequences contain sufficient viewpoint and depth signal to support metric-scale geometric learning when supervised by external 3D models.
Reference graph
Works this paper leans on
-
[1]
Scanqa: 3d question answering for spatial scene understanding
Daichi Azuma, Taiki Miyanishi, Shuhei Kurita, and Motoaki Kawanabe. Scanqa: 3d question answering for spatial scene understanding. Inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19129– 19139, 2022. 6
2022
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5- vl technical report.a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. SpatialVLM: Endowing Vision-Language Mod- els with Spatial Reasoning Capabilities.arXiv e-prints, art. arXiv:2401.12168, 2024. 2
-
[5]
Ll3da: Visual interactive instruction tuning for omni-3d understand- ing reasoning and planning
Sijin Chen, Xin Chen, Chi Zhang, Mingsheng Li, Gang Yu, Hao Fei, Hongyuan Zhu, Jiayuan Fan, and Tao Chen. Ll3da: Visual interactive instruction tuning for omni-3d understand- ing reasoning and planning. InCVPR, pages 26428–26438,
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long con- text, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
3d-llava: Towards generalist 3d lmms with omni superpoint transformer
Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Day- oub, and Ian Reid. 3d-llava: Towards generalist 3d lmms with omni superpoint transformer. InCVPR, pages 3772–3782,
-
[8]
Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014. 8
2014
-
[9]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Shijie Zhou, Dilin Wang, et al. Vlm-3r: Vision-language models aug- mented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279, 2025. 2, 5, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yondong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis.arXiv:2405.21075, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
3d-llm: Injecting the 3d world into large language models.NeurIPS, 36:20482– 20494, 2023
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models.NeurIPS, 36:20482– 20494, 2023. 1, 2, 6
2023
-
[12]
Wenbo Hu, Jingli Lin, Yilin Long, Yunlong Ran, Lihan Jiang, Yifan Wang, Chenming Zhu, Runsen Xu, Tai Wang, and Jiangmiao Pang. G2vlm: Geometry grounded vision language model with unified 3d reconstruction and spatial reasoning. arXiv preprint arXiv:2511.21688, 2025. 2
-
[13]
Chat-scene: Bridging 3d scene and large language models with object identifiers.NeurIPS, 37: 113991–114017, 2024
Haifeng Huang, Yilun Chen, Zehan Wang, Rongjie Huang, Runsen Xu, Tai Wang, Luping Liu, Xize Cheng, Yang Zhao, Jiangmiao Pang, et al. Chat-scene: Bridging 3d scene and large language models with object identifiers.NeurIPS, 37: 113991–114017, 2024. 6
2024
-
[14]
3drs: Mllms need 3d-aware representation supervision for scene understanding
Xiaohu Huang, Jingjing Wu, Qunyi Xie, and Kai Han. 3drs: Mllms need 3d-aware representation supervision for scene understanding. InNeurIPS, 2025. 2, 6
2025
-
[15]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d recon- struction.arXiv preprint arXiv:2509.13414, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017. 5
2017
-
[18]
Ground- ing image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Ground- ing image matching in 3d with mast3r. InEuropean Confer- ence on Computer Vision, 2024. 2
2024
-
[19]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv:2408.03326, 2024. 1, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengx- iang Ding, Donglin Wang, Long ZENG, and Haoang Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model. InThe Fourteenth Interna- tional Conference on Learning Representations, 2026. 2
2026
-
[21]
Spatialladder: Progressive training for spatial reasoning in vision-language models, 2025
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models, 2025. 6
2025
-
[22]
Thinking with Geometry: Active Geometry Integration for Spatial Reasoning
Haoyuan Li, Qihang Cao, Tao Tang, Kun Xiang, Zihan Guo, Jianhua Han, Hang Xu, and Xiaodan Liang. Thinking with geometry: Active geometry integration for spatial reasoning. arXiv preprint arXiv:2602.06037, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Mvbench: A comprehensive multi-modal video understand- ing benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understand- ing benchmark. InCVPR, 2024. 1
2024
-
[24]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 1, 2, 3, 4, 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
GeoAlign: Geometric Feature Realignment for MLLM Spatial Reasoning
Zhaochen Liu, Limeng Qiao, Guanglu Wan, and Tingting Jiang. Geoalign: Geometric feature realignment for mllm spatial reasoning.arXiv preprint arXiv:2604.12630, 2026. 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Sqa3d: Sit- uated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Sit- uated question answering in 3d scenes.arXiv preprint arXiv:2210.07474, 2022. 6
-
[27]
Spatiallm: Train- ing large language models for structured indoor modeling
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Train- ing large language models for structured indoor modeling. In NeurIPS, 2025. 1, 2
2025
-
[28]
Learning 3d object categories by looking around them
David Novotny, Diane Larlus, and Andrea Vedaldi. Learning 3d object categories by looking around them. InProceedings of the IEEE international conference on computer vision, pages 5218–5227, 2017. 5
2017
-
[29]
Vi- sion transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 4, 8
2021
-
[30]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Streambridge: Turning your offline video large language model into a proactive streaming assistant
Haibo Wang, Bo Feng, Zhengfeng Lai, Mingze Xu, Shiyu Li, Weifeng Ge, Afshin Dehghan, Meng Cao, and Ping Huang. Streambridge: Turning your offline video large language model into a proactive streaming assistant. InNeurIPS, 2025. 1
2025
-
[32]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 1, 2, 3, 4, 5, 7
2025
-
[33]
Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schönberger, Patrick Labatut, Piotr Bo- janowski, David Novotny, Andrea Vedaldi, and Christian Rupprecht. Vggt- Ω. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2026. 2, 3, 5, 7
2026
-
[34]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 20697–20709, 2024. 1, 2, 5
2024
-
[35]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
$\pi^3$: Permutation-equivariant visual geometry learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chun- hua Shen, and Tong He. $\pi^3$: Permutation-equivariant visual geometry learning. InThe Fourteenth International Conference on Learning Representations, 2026. 2
2026
-
[37]
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Diankun Wu, Fangfu Liu, Yi-Hsin Hung, and Yueqi Duan. Spatial-mllm: Boosting mllm capabilities in visual-based spatial intelligence.arXiv preprint arXiv:2505.23747, 2025. 1, 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Longvideobench: A benchmark for long-context interleaved video-language understanding.NeurIPS, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.NeurIPS, 2024. 1
2024
-
[39]
Slowfast-llava-1.5: A family of token-efficient video large language models for long-form video understand- ing
Mingze Xu, Mingfei Gao, Shiyu Li, Jiasen Lu, Zhe Gan, Zhengfeng Lai, Meng Cao, Kai Kang, Yinfei Yang, and Af- shin Dehghan. Slowfast-llava-1.5: A family of token-efficient video large language models for long-form video understand- ing. InCOLM, 2025. 1
2025
-
[40]
Pointllm: Empowering large language models to understand point clouds
Runsen Xu, Xiaolong Wang, Tai Wang, Yilun Chen, Jiang- miao Pang, and Dahua Lin. Pointllm: Empowering large language models to understand point clouds. InECCV, pages 131–147. Springer, 2024. 1, 2
2024
-
[41]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025. 1, 6
2025
-
[42]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wen- qian Wang, et al. Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025. 6
-
[43]
Cambrian-s: Towards spatial super- sensing in video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis L Brown II, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, et al. Cambrian-s: Towards spatial super- sensing in video. InThe Fourteenth International Conference on Learning Representations, 2025. 1, 5, 6
2025
-
[44]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chan- drasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025. 1
2025
-
[45]
SpatialStack: Layered Geometry-Language Fusion for 3D VLM Spatial Reasoning
Jiang Zhang, Shijie Zhou, Bangya Liu, Achuta Kadambi, and Zhiwen Fan. Spatialstack: Layered geometry-language fusion for 3d vlm spatial reasoning.arXiv preprint arXiv:2603.27437, 2026. 6
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
arXiv preprint arXiv:2511.23075 (2025)
Ruosen Zhao, Zhikang Zhang, Jialei Xu, Jiahao Chang, Dong Chen, Lingyun Li, Weijian Sun, and Zizhuang Wei. Space- mind: Camera-guided modality fusion for spatial reasoning in vision-language models.arXiv preprint arXiv:2511.23075,
-
[48]
arXiv preprint arXiv:2505.24625 (2025)
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625,
-
[49]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InCVPR, pages 8995–9006, 2025. 2, 6
2025
-
[50]
MLVU: Benchmarking Multi-task Long Video Understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Shitao Xiao, Xi Yang, Yongping Xiong, Bo Zhang, Tiejun Huang, and Zheng Liu. Mlvu: A comprehensive benchmark for multi-task long video understanding.arXiv:2406.04264, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities. InICCV, pages 4295–4305, 2025. 2, 6, 7
2025
-
[52]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.