Evidence Graph Consistency in Retrieval-Augmented Generation: A Model-Dependent Analysis of Hallucination Detection
Pith reviewed 2026-06-30 10:49 UTC · model grok-4.3
The pith
Evidence graph consistency detects hallucinations in Llama-2 but reverses direction in GPT and Mistral models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
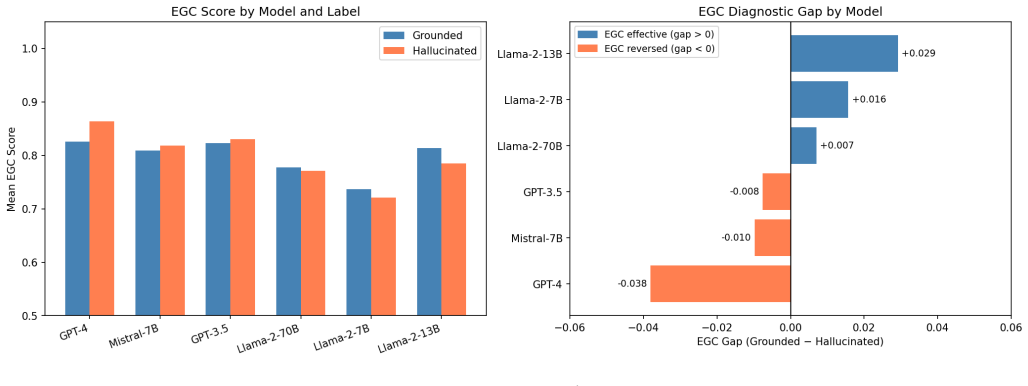
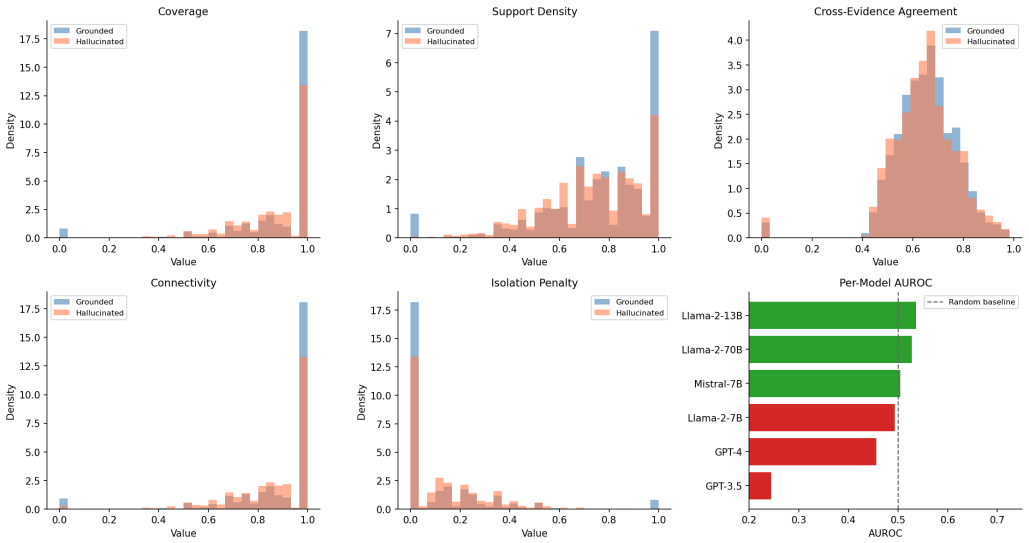
The authors construct a local evidence graph for each response and compute five structural consistency measures as potential hallucination indicators. On the full question-answering split of RAGTruth, these measures align with the expected direction for hallucinations in Llama-2 models but exhibit systematic reversal in GPT-4, GPT-3.5, and Mistral-7B. The reversal indicates qualitatively different hallucination patterns across model families and shows that embedding-based graph consistency cannot function as a model-independent detection signal.
What carries the argument
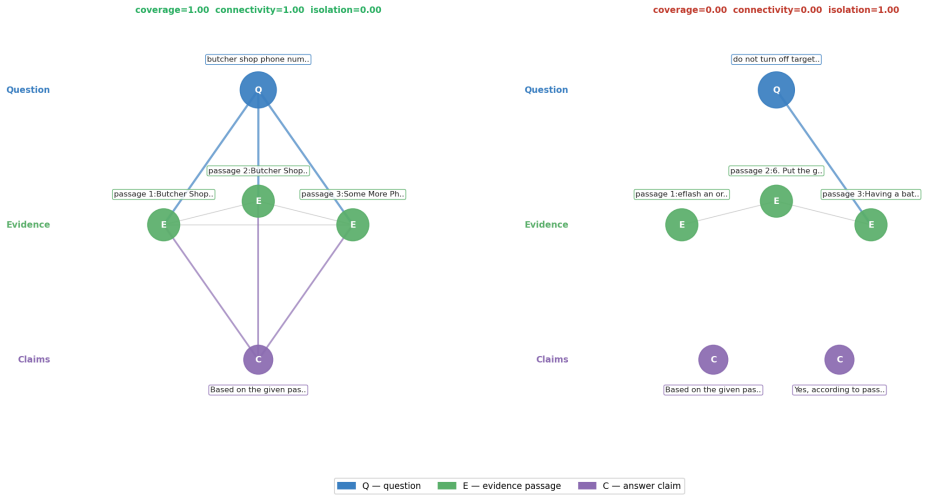
The Evidence Graph Consistency (EGC) framework, which builds a local evidence graph per response and derives five structural consistency measures from the connections between evidence pieces and answer claims.
If this is right
- Hallucination detection methods based on graph consistency must be validated separately for each model family rather than assumed to transfer.
- Qualitatively different hallucination patterns exist between the Llama-2 family and the GPT/Mistral families.
- Embedding-based structural signals from evidence graphs lose diagnostic value when applied across model families.
- RAG systems using multiple model families require family-specific hallucination checks rather than a single shared detector.
Where Pith is reading between the lines
- Model providers could publish family-specific calibration data for graph-based detectors to improve reliability.
- The reversal might stem from differences in how models integrate retrieved evidence during generation, which could be tested by comparing attention patterns over evidence.
- Alternative graph definitions that weight claims by model-generated probability might reduce the observed model dependence.
Load-bearing premise
The way the local evidence graph is built and the five consistency measures are calculated does not itself create different connection patterns depending on which model family generated the answer.
What would settle it
Re-running the same graph construction and five measures on responses from a new collection of models that includes both Llama-style and GPT-style families and finding no reversal or model-family split would falsify the claim that the behavior is model-dependent.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) reduces but does not eliminate hallucination in large language models. Existing detection methods rely on flat similarity between generated answers and retrieved passages, ignoring structural relationships among evidence pieces and answer claims. We propose Evidence Graph Consistency (EGC), a framework that constructs a local evidence graph per response and computes five structural consistency measures as hallucination indicators. Evaluated on the full question answering split of RAGTruth across six LLMs (5,767 responses), EGC reveals a consistent model-family split: graph consistency features show the expected diagnostic direction for hallucinations in Llama-2 models but exhibit systematic reversal in GPT-4, GPT-3.5, and Mistral-7B. This reversal suggests qualitatively different hallucination patterns across model families and indicates that embedding-based graph consistency cannot serve as a model-independent hallucination detection signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Evidence Graph Consistency (EGC), a framework that builds a local evidence graph per RAG response and derives five structural consistency measures to detect hallucinations. Evaluated on the full QA split of RAGTruth (5,767 responses across six LLMs), EGC exhibits the expected diagnostic direction for Llama-2 models but a systematic reversal for GPT-4, GPT-3.5, and Mistral-7B, leading to the conclusion that embedding-based graph consistency cannot serve as a model-independent hallucination signal and that hallucination patterns differ qualitatively across model families.
Significance. If the reported reversal is robust to the graph-construction pipeline, the result would be significant for hallucination detection research: it supplies concrete empirical evidence against model-agnostic assumptions in current RAG verification methods and motivates family-specific detectors. The evaluation on a public benchmark with a large response count is a strength.
major comments (2)
- [Abstract] Abstract: the central claim of a model-family reversal rests on the five structural consistency measures being computed identically across LLMs. No verification is supplied that claim extraction, relation detection, or edge formation steps are invariant to known model-family differences in output length, fluency, and sentence structure; if these steps embed such differences, the reversal could be an artifact of the measurement pipeline rather than evidence of distinct hallucination mechanisms.
- [Evaluation] Evaluation section (implied by the 5,767-response count): the manuscript reports the split but does not describe the exact statistical procedure used to establish that the reversal is systematic across the three non-Llama families (e.g., per-measure sign tests, family-level interaction terms, or correction for multiple comparisons). Without these details the load-bearing claim that the pattern is qualitative rather than noise remains under-supported.
minor comments (2)
- [Abstract] The abstract refers to 'embedding-based graph consistency' without clarifying whether the graph edges themselves are embedding-driven or purely syntactic; this notation should be made explicit in the methods.
- The paper would benefit from a short table listing the five structural consistency measures with their precise definitions and formulas.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments identify areas where additional verification and statistical detail would strengthen the manuscript. We address each point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a model-family reversal rests on the five structural consistency measures being computed identically across LLMs. No verification is supplied that claim extraction, relation detection, or edge formation steps are invariant to known model-family differences in output length, fluency, and sentence structure; if these steps embed such differences, the reversal could be an artifact of the measurement pipeline rather than evidence of distinct hallucination mechanisms.
Authors: We agree that explicit verification of pipeline invariance is necessary to support the claim that the observed reversal reflects model-family differences in hallucination mechanisms rather than measurement artifacts. The current pipeline applies a uniform embedding-based similarity threshold for edge formation and a fixed claim-extraction procedure to all responses. In the revised version we will add a dedicated subsection that reports (i) average graph statistics (node count, edge density) broken down by model family, (ii) a sensitivity analysis varying the similarity threshold, and (iii) a qualitative comparison of extracted claims from Llama-2 versus GPT-family outputs. These additions will either confirm invariance or quantify any residual model-specific effects. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the 5,767-response count): the manuscript reports the split but does not describe the exact statistical procedure used to establish that the reversal is systematic across the three non-Llama families (e.g., per-measure sign tests, family-level interaction terms, or correction for multiple comparisons). Without these details the load-bearing claim that the pattern is qualitative rather than noise remains under-supported.
Authors: We acknowledge that the manuscript currently presents the directional reversal descriptively without formal statistical tests. In the revision we will add an explicit statistical analysis subsection that reports (a) per-measure sign tests comparing correlation signs between Llama-2 and the other three families, (b) a family-level interaction term in a mixed-effects model treating model family as a factor, and (c) Bonferroni correction for the five measures. The results of these tests will be included in a new table and discussed in the text. revision: yes
Circularity Check
No circularity: empirical reporting on external benchmark without self-referential reduction
full rationale
The paper constructs an evidence graph and five consistency measures from an external RAGTruth dataset and reports observed empirical patterns across model families. No equations, parameters, or claims are defined in terms of the target result (model-family reversal), nor are any 'predictions' fitted to subsets and then re-reported as outputs. No self-citations or uniqueness theorems are invoked. The analysis is self-contained against the benchmark and does not reduce by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal,et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” in Advances in Neural Information Processing Systems, 2020, pp. 9459– 9474
2020
-
[2]
RAGTruth: A hallucination corpus for developing trustworthy retrieval-augmented language models,
C. Niu, Y . Wu, J. Zhu, S. Xu, K. Shum, R. Zhong, J. Song, and T. Zhang, “RAGTruth: A hallucination corpus for developing trustworthy retrieval-augmented language models,” inProc. 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 2024, pp. 10862–10878
2024
-
[3]
RAGAs: Automated evaluation of retrieval augmented generation,
S. Es, J. James, L. Espinosa Anke, and S. Schockaert, “RAGAs: Automated evaluation of retrieval augmented generation,” inProc. 18th Conference of the European Chapter of the Association for Computa- tional Linguistics, 2024, pp. 150–158
2024
-
[4]
FActScore: Fine-grained atomic evaluation of factual precision in long form text generation,
S. Min, K. Krishna, X. Lyu, M. Lewis, W. Tau Yih, P. Koh, M. Iyyer, L. Zettlemoyer, and H. Hajishirzi, “FActScore: Fine-grained atomic evaluation of factual precision in long form text generation,” inProc. 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 2023, pp. 12076–12100
2023
-
[5]
SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models,
P. Manakul, A. Liusie, and M. Gales, “SelfCheckGPT: Zero-resource black-box hallucination detection for generative large language models,” inProc. 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 2023, pp. 9004–9017
2023
-
[6]
HotpotQA: A dataset for diverse, explainable multi-hop question answering,
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “HotpotQA: A dataset for diverse, explainable multi-hop question answering,” inProc. 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018, pp. 2369–2380
2018
-
[7]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProc. 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 2019, pp. 3982–3992
2019
-
[8]
spaCy: Industrial-strength natural language processing in Python,
M. Honnibal, I. Montani, S. Van Landeghem, and A. Boyd, “spaCy: Industrial-strength natural language processing in Python,” Explosion AI, Tech. Rep., 2020
2020
-
[9]
Exploring network structure, dynamics, and function using NetworkX,
A. A. Hagberg, D. A. Schult, and P. J. Swart, “Exploring network structure, dynamics, and function using NetworkX,” inProc. 7th Python in Science Conference, 2008
2008
-
[10]
MS MARCO: A human generated machine reading comprehension dataset,
T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, and L. Deng, “MS MARCO: A human generated machine reading comprehension dataset,” inProc. Workshop on Cognitive Computation: Integrating Neural and Symbolic Approaches, vol. 1773, 2016
2016
-
[11]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[12]
Wizard of Wikipedia: Knowledge-powered conversational agents,
E. Dinan, S. Roller, K. Shuster, A. Fan, M. Auli, and J. Weston, “Wizard of Wikipedia: Knowledge-powered conversational agents,” in Proc. International Conference on Learning Representations, 2019
2019
-
[13]
On faithfulness and factuality in abstractive summarisation,
J. Maynez, S. Narayan, B. Bohnet, and R. McDonald, “On faithfulness and factuality in abstractive summarisation,” inProc. 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 1906–1919
2020
-
[14]
Scikit-learn: Machine learning in Python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,”Journal of Machine Learn- ing Research, vol. 12, 2011
2011
-
[15]
A large annotated corpus for learning natural language inference,
S. R. Bowman, G. Angeli, C. Potts, and C. D. Manning, “A large annotated corpus for learning natural language inference,” inProc. 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 2015, pp. 632–642
2015
-
[16]
Retrieval augmentation reduces hallucination in conversation,
K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston, “Retrieval augmentation reduces hallucination in conversation,” inFindings of the Association for Computational Linguistics: EMNLP 2021, 2021, pp. 3784–3803
2021
-
[17]
C. J. Van Rijsbergen,Information Retrieval, 2nd ed. Butterworth- Heinemann, 1979
1979
-
[18]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inProc. 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, 2019, pp. 4171–4186
2019
-
[20]
QA- GNN: Reasoning with language models and knowledge graphs for question answering,
M. Yasunaga, H. Ren, A. Bosselut, P. Liang, and J. Leskovec, “QA- GNN: Reasoning with language models and knowledge graphs for question answering,” inProc. 2021 Conference of the North American Chapter of the Association for Computational Linguistics, 2021, pp. 535–546
2021
-
[21]
H. Hu, C. He, X. Xie, and Q. Zhang, “LRP4RAG: Detecting hal- lucinations in retrieval-augmented generation via layer-wise relevance propagation,” unpublished, arXiv:2408.15533, 2024
-
[22]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin, and T. Liu, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
D. W. Hosmer, S. Lemeshow, and R. X. Sturdivant,Applied Logistic Regression, 3rd ed. Wiley, 2013
2013
-
[24]
Distributed representations of words and phrases and their compositionality,
T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in Neural Information Processing Systems, vol. 2, 2013, pp. 3111–3119
2013
-
[25]
ARES: An automated evaluation framework for retrieval-augmented generation systems,
J. Saad-Falcon, O. Khattab, C. Potts, and M. Zaharia, “ARES: An automated evaluation framework for retrieval-augmented generation systems,”arXiv preprint arXiv:2311.09476, 2023
-
[26]
Ranking generated summaries by correctness: An interesting but chal- lenging application for natural language inference,
T. Falke, L. F. R. Ribeiro, P. A. Utama, I. Dagan, and I. Gurevych, “Ranking generated summaries by correctness: An interesting but chal- lenging application for natural language inference,” inProc. 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 2019, pp. 2214–2220
2019
-
[27]
RAG-HAT: A hallucination-aware tuning pipeline for LLM in retrieval- augmented generation,
J. Song, X. Wang, J. Zhu, Y . Wu, X. Cheng, R. Zhong, and C. Niu, “RAG-HAT: A hallucination-aware tuning pipeline for LLM in retrieval- augmented generation,” inProc. 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, Miami, FL, 2024, pp. 1548–1558
2024
-
[28]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, et al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprintarXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier,et al., “Mistral 7B,”arXiv preprintarXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
OpenAI, “GPT-4 technical report,”arXiv preprintarXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
A survey on RAG meeting LLMs: Towards retrieval-augmented large language models,
W. Fan, Y . Ding, L. Ning, S. Wang, H. Li, D. Yin, T.-S. Chua, and Q. Li, “A survey on RAG meeting LLMs: Towards retrieval-augmented large language models,” inProc. 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 6491–6501
2024
-
[32]
FactGraph: Evaluating factuality in summarization with semantic graph representations,
L. F. R. Ribeiro, M. Liu, I. Gurevych, M. Dreyer, and M. Bansal, “FactGraph: Evaluating factuality in summarization with semantic graph representations,” inProc. 2022 Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technolo- gies, Seattle, W A, USA, 2022, pp. 3238–3253
2022
-
[33]
GraphEval: A knowledge-graph based LLM hallucination evaluation framework,
H. Sansford, N. Richardson, H. Petric Maretic, and J. Nait Saada, “GraphEval: A knowledge-graph based LLM hallucination evaluation framework,” inProc. KiL’24: Workshop on Knowledge-infused Learn- ing, co-located with the 30th ACM SIGKDD Conf., Barcelona, Spain, 2024
2024
-
[34]
SummaC: Re-visiting NLI-based models for inconsistency detection in summa- rization,
P. Laban, T. Schnabel, P. N. Bennett, and M. A. Hearst, “SummaC: Re-visiting NLI-based models for inconsistency detection in summa- rization,”Transactions of the Association for Computational Linguistics, vol. 10, pp. 163–177, 2022
2022
-
[35]
Knowledge-centric hallucination detection,
X. Hu, D. Ru, L. Qiu, Q. Guo, T. Zhang, Y . Xu, Y . Luo, P. Liu, Y . Zhang, and Z. Zhang, “Knowledge-centric hallucination detection,” in Proc. 2024 Conf. Empirical Methods in Natural Language Processing (EMNLP), Miami, FL, USA, 2024, pp. 6953–6975
2024
-
[36]
BERTScore: Evaluating text generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinberger, and Y . Artzi, “BERTScore: Evaluating text generation with BERT,” inProc. Inter- national Conference on Learning Representations (ICLR), 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.