MotionEnhancer: Leveraging Video Diffusion for Motion-Enhanced Vision-Language Models
Pith reviewed 2026-06-27 22:47 UTC · model grok-4.3
The pith
Motion priors from video diffusion models can be extracted via two parameter-free modules to improve VLMs on fine-grained motion understanding in videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
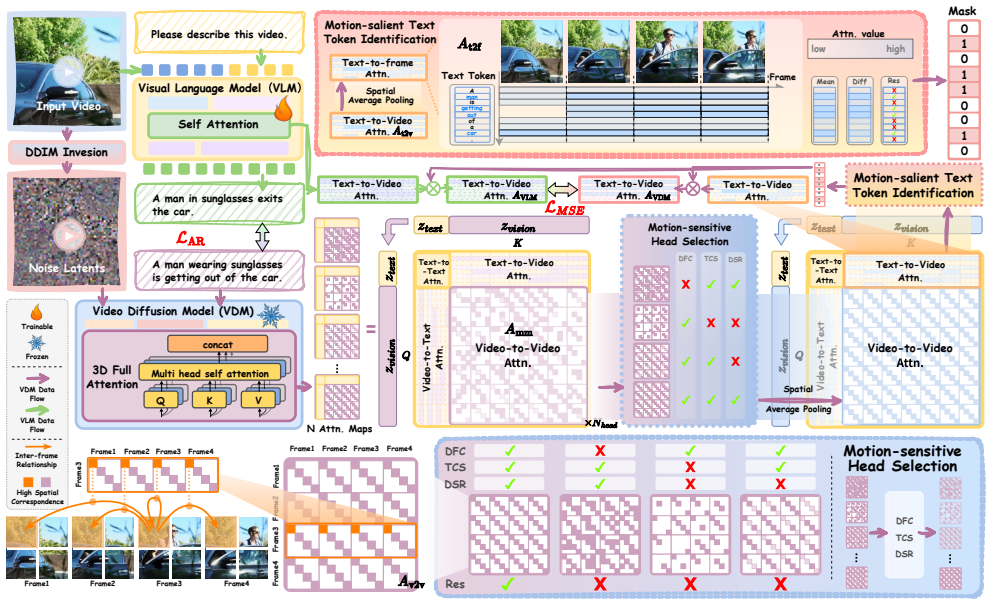
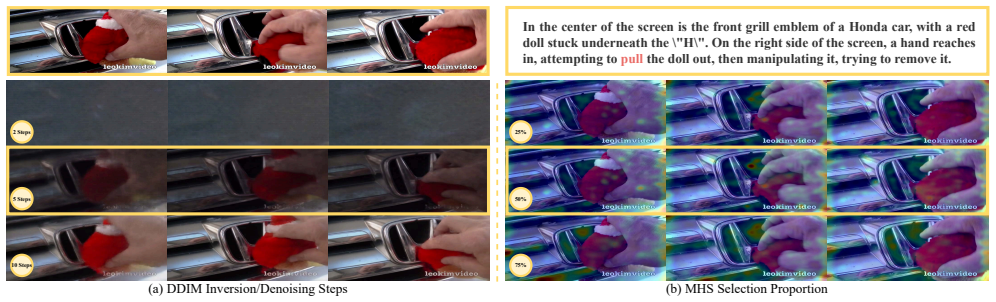
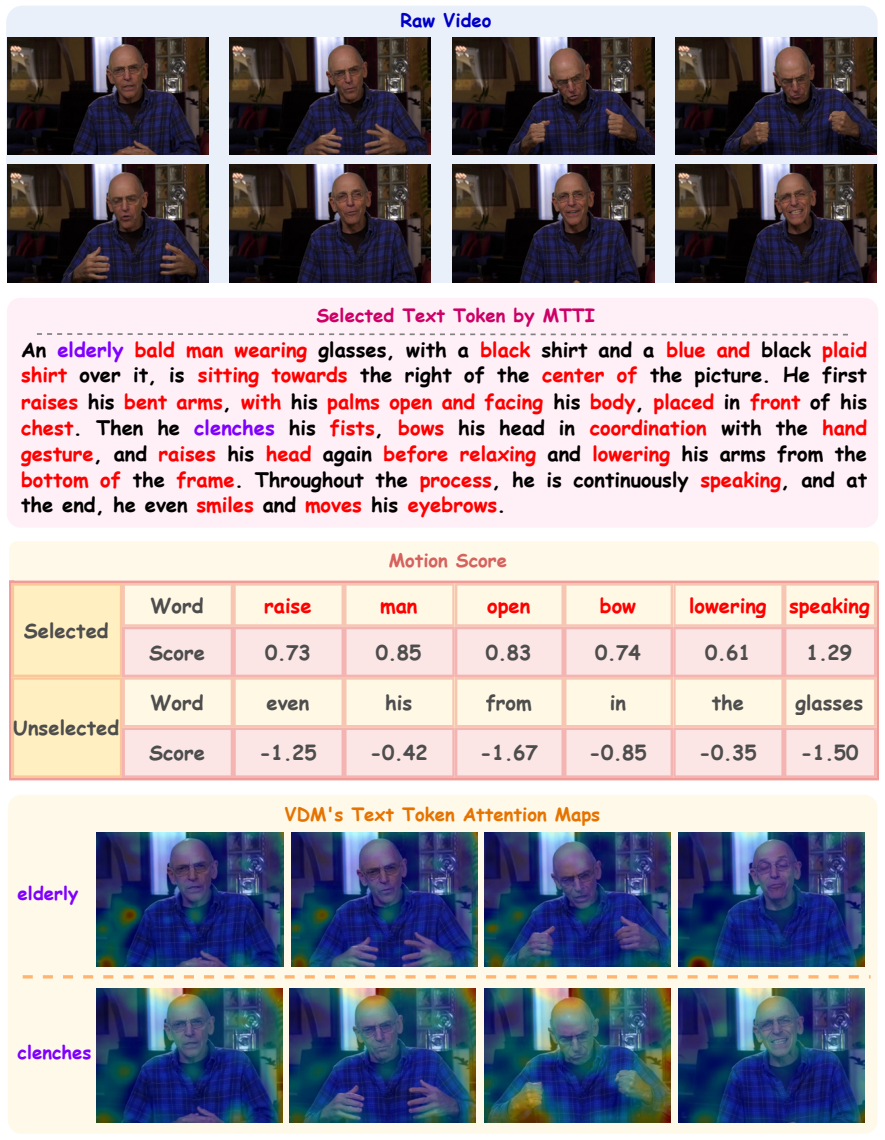
MotionEnhancer introduces two parameter-free modules, Motion-sensitive Head Selection and Motion-salient Text Token Identification, that directly extract motion-related attentions from a video diffusion model and align them to a vision-language model, providing motion priors as auxiliary supervision that improve motion understanding on video benchmarks without training or architectural modifications.
What carries the argument
Motion-sensitive Head Selection (MHS) and Motion-salient Text Token Identification (MTTI), two parameter-free modules that identify and align motion-related attentions from the video diffusion model to the VLM.
If this is right
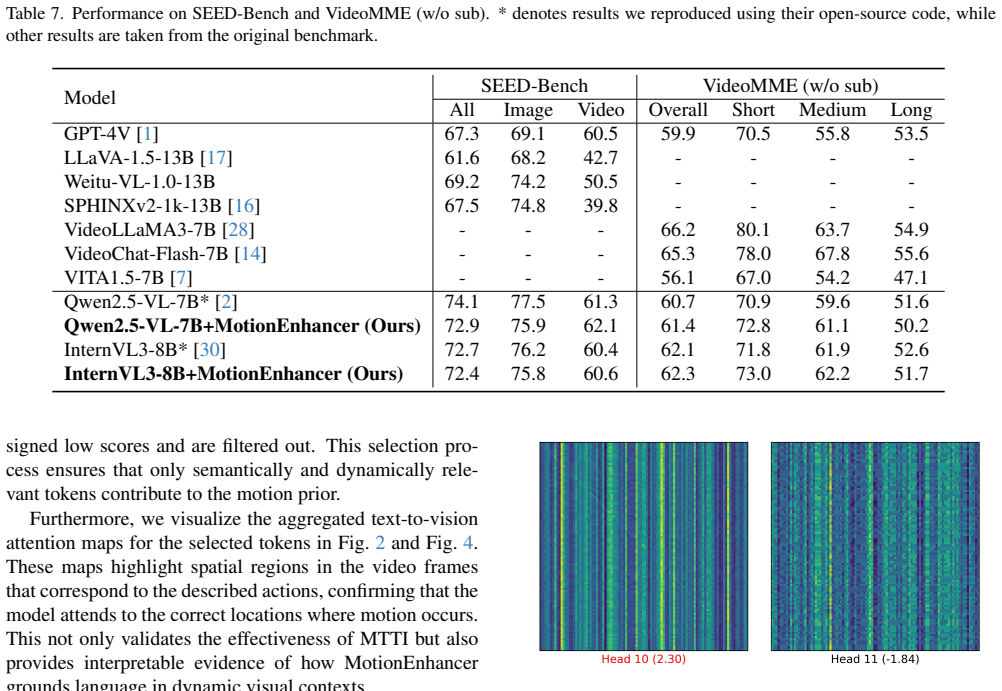
- The approach yields consistent gains over state-of-the-art VLMs on two motion-level video understanding benchmarks.
- Improvements appear especially on motion-related evaluation metrics.
- The method requires no additional training parameters or changes to existing VLM architectures.
- It operates in a computation-only manner using existing models.
- It supplies a scalable route to stronger motion understanding in video tasks.
Where Pith is reading between the lines
- The same attention-extraction idea might transfer to other generative priors for enhancing different VLM capabilities.
- If the modules prove robust across diffusion model families, practitioners could swap in newer video generators without retraining the VLM.
- The parameter-free nature suggests the technique could be stacked with other lightweight adapters for multi-aspect video understanding.
- Success here raises the question of whether similar distillation can address other VLM weaknesses, such as temporal ordering or physics reasoning.
Load-bearing premise
Motion priors from a video diffusion model can be effectively extracted and aligned via the proposed parameter-free modules to enhance VLM motion understanding without any training or architectural changes.
What would settle it
Running the two modules on a standard VLM and observing no gain or a drop in motion-related metrics on the two motion-level video understanding benchmarks would falsify the central claim.
Figures






read the original abstract
The new era has witnessed a remarkable capability to extend Vision-Language Models (VLMs) for tackling tasks of video understanding. While current VLMs excel at event- or story-level understanding, their ability to capture fine-grained motion details remains limited, primarily due to their focus on high-level static semantic structures and macro-event logic. In contrast, Video Diffusion Models (VDMs) are adept at modeling dynamic motion patterns, benefiting from large-scale video data and the intrinsic requirement of temporal generation. In this paper, we introduce MotionEnhancer, a novel approach that leverages motion priors distilled from a powerful video diffusion model as auxiliary supervision to enhance the motion understanding capability of a VLM via attention alignment. MotionEnhancer comprises two simple parameter-free modules, Motion-sensitive Head Selection (MHS) and Motion-salient Text Token Identification (MTTI), to directly extract and optimize motion-related attentions from the VDM in a computation-only manner. MotionEnhancer provides a scalable solution for motion understanding without additional training parameters, modifications to existing architectures, or tool calling. Extensive experiments demonstrate that MotionEnhancer can achieve consistent improvements over state-of-the-art VLMs on two motion-level video understanding benchmarks, especially on motion-related metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MotionEnhancer, a training-free method that distills motion priors from a Video Diffusion Model (VDM) into a Vision-Language Model (VLM) using two parameter-free modules: Motion-sensitive Head Selection (MHS) and Motion-salient Text Token Identification (MTTI). These modules extract motion-related attentions from the VDM and align them to the VLM via attention mechanisms. The central claim is that this yields consistent improvements over state-of-the-art VLMs on two motion-level video understanding benchmarks, with particular gains on motion-related metrics, without any architectural changes, additional parameters, or tool calling.
Significance. If the benchmark gains are reproducible and robust, the work offers a scalable, zero-cost way to inject motion modeling capabilities from large-scale VDMs into existing VLMs. This could be valuable for video tasks requiring fine-grained temporal understanding, as it avoids retraining or data collection while leveraging the generative priors already present in diffusion models.
major comments (2)
- Abstract: The abstract asserts 'consistent improvements' and 'especially on motion-related metrics' but supplies no information on the two benchmarks, the specific VLMs tested, baselines, evaluation metrics, number of runs, or statistical significance. Without these details the central empirical claim cannot be assessed for soundness or reproducibility.
- Abstract (and implied method description): The claim that MHS and MTTI are strictly 'parameter-free' and operate in a 'computation-only manner' is presented without any derivation, pseudocode, or complexity analysis showing how motion heads/tokens are selected and aligned; this makes it impossible to verify whether the alignment is truly free of implicit hyperparameters or data-dependent choices.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below with references to the full manuscript.
read point-by-point responses
-
Referee: [—] Abstract: The abstract asserts 'consistent improvements' and 'especially on motion-related metrics' but supplies no information on the two benchmarks, the specific VLMs tested, baselines, evaluation metrics, number of runs, or statistical significance. Without these details the central empirical claim cannot be assessed for soundness or reproducibility.
Authors: The abstract is intentionally concise to summarize the core contribution. All requested details are provided in the full manuscript: Section 4 specifies the two motion-level benchmarks, the VLMs evaluated (including baselines), the evaluation metrics (with emphasis on motion-related ones), the number of runs, and statistical analysis. These sections allow full assessment of reproducibility and soundness. We can revise the abstract to name the benchmarks and primary VLMs if the editor prefers a more informative summary. revision: partial
-
Referee: [—] Abstract (and implied method description): The claim that MHS and MTTI are strictly 'parameter-free' and operate in a 'computation-only manner' is presented without any derivation, pseudocode, or complexity analysis showing how motion heads/tokens are selected and aligned; this makes it impossible to verify whether the alignment is truly free of implicit hyperparameters or data-dependent choices.
Authors: Section 3 of the manuscript derives MHS and MTTI in full, including the attention-based selection criteria, the alignment procedure, pseudocode (Algorithm 1), and complexity analysis (Section 3.4). Both modules use only existing attention maps with fixed, non-learnable selection rules and introduce no trainable parameters or external data. No implicit hyperparameters are involved beyond standard attention operations. The 'computation-only' phrasing refers to the absence of training or tool use. revision: no
Circularity Check
No significant circularity
full rationale
The paper introduces MotionEnhancer as a parameter-free method using MHS and MTTI modules to align motion priors from a VDM to a VLM via attention, with claims resting on empirical benchmark gains rather than any derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing premises. No self-definitional steps, uniqueness theorems, or ansatzes are invoked; the approach is described as computation-only without training, making the central claim externally falsifiable via the reported experiments on motion-level benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, An elderly bald man wearing glasses, with a black shirt and a blue and black plaid shirt over it, is sitting towards the right of the center of the picture. He first raises his bent arms, with his palms open and facing his body, placed in front of his chest. Then he clenches his fists, bows his head i...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Yipeng Du, Tiehan Fan, Kepan Nan, Rui Xie, Penghao Zhou, Xiang Li, Jian Yang, Zhenheng Yang, and Ying Tai. Motion- sight: Boosting fine-grained motion understanding in multi- modal llms.arXiv preprint arXiv:2506.01674, 2025
-
[6]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108– 24118, 2025
2025
-
[7]
VITA-1.5: Towards GPT-4o Level Real-Time Vision and Speech Interaction
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yun- hang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Het- ing Gao, Ke Li, et al. Vita-1.5: Towards gpt-4o level real-time vision and speech interaction.arXiv preprint arXiv:2501.01957, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
V2pe: Improving multi- modal long-context capability of vision-language models with variable visual position encoding
Junqi Ge, Ziyi Chen, Jintao Lin, Jinguo Zhu, Xihui Liu, Jifeng Dai, and Xizhou Zhu. V2pe: Improving multi- modal long-context capability of vision-language models with variable visual position encoding. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 21070–21084, 2025
2025
-
[9]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[10]
CogVLM2: Visual Language Models for Image and Video Understanding
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qingsong Lv, Yan Wang, Yean Cheng, Shiyu Huang, Jun- hui Ji, Zhao Xue, et al. Cogvlm2: Visual language mod- els for image and video understanding.arXiv preprint arXiv:2408.16500, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8450–8460, 2025
2025
-
[12]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yix- iao Ge, and Ying Shan. Seed-bench: Benchmarking mul- timodal llms with generative comprehension.arXiv preprint arXiv:2307.16125, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models.arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, et al. Videochat-flash: Hierarchical com- pression for long-context video modeling.arXiv preprint arXiv:2501.00574, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Video-LLaVA: Learning United Visual Representation by Alignment Before Projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual rep- resentation by alignment before projection.arXiv preprint arXiv:2311.10122, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models.arXiv preprint arXiv:2311.07575, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023
2023
-
[18]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
2023
-
[19]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205, 2023
2023
-
[20]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
2020
-
[21]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
Chongjun Tu, Lin Zhang, Pengtao Chen, Peng Ye, Xianfang Zeng, Wei Cheng, Gang Yu, and Tao Chen. Favor-bench: A comprehensive benchmark for fine-grained video motion understanding.arXiv preprint arXiv:2503.14935, 2025
-
[23]
Tarsier: Recipes for training and evaluating large video description models,
Jiawei Wang, Liping Yuan, Yuchen Zhang, and Haomiao Sun. Tarsier: Recipes for training and evaluating large video description models.arXiv preprint arXiv:2407.00634, 2024
-
[24]
Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, et al. Enhancing the reasoning ability of multimodal large language models via mixed preference optimization.arXiv preprint arXiv:2411.10442, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understand- ing.arXiv preprint arXiv:2501.13106, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Zi- wei Liu, and Chunyuan Li. Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.