TEVI: Text-Conditioned Editing of Visual Representations via Sparse Autoencoders for Improved Vision-Language Alignment
Pith reviewed 2026-06-27 22:19 UTC · model grok-4.3
The pith
Text captions can selectively edit image embeddings to better align them with descriptions in CLIP models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
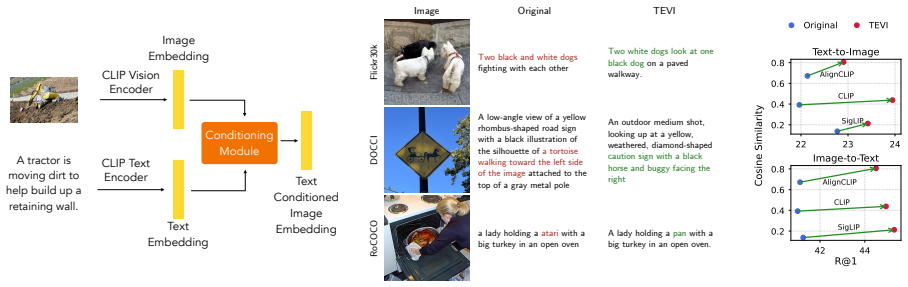
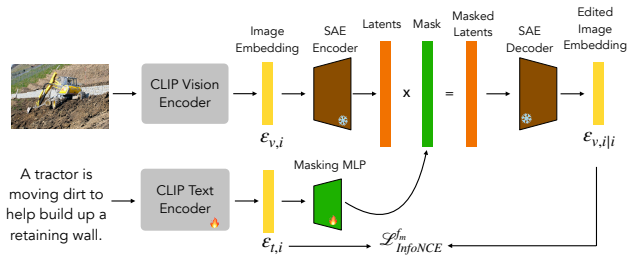
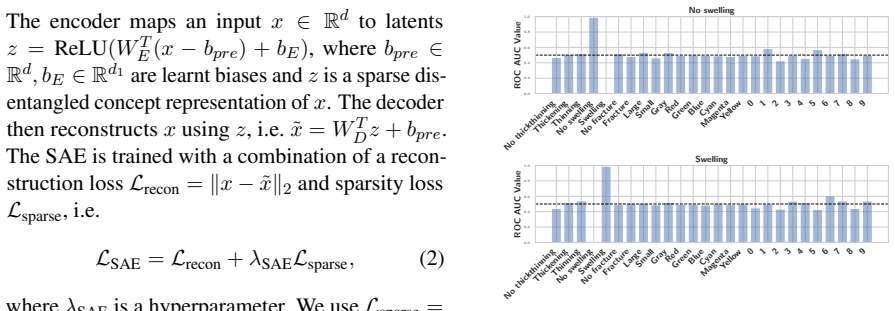
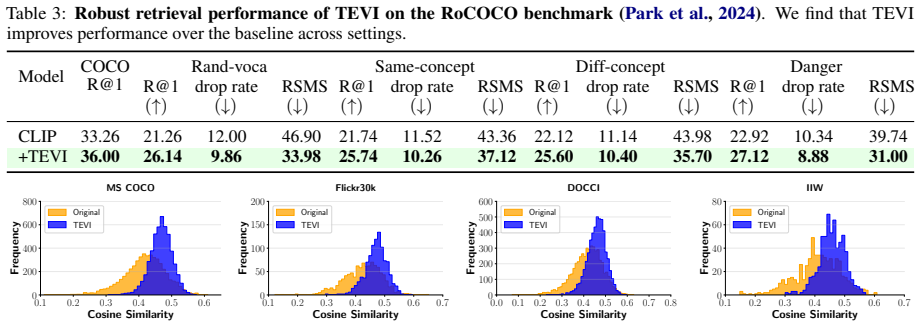
TEVI disentangles image embeddings via sparse autoencoders and trains a masking module that reconstructs the embedding while retaining only features described by a given caption; the resulting edited embeddings produce higher retrieval accuracy on MS COCO, Flickr, IIW, and DOCCI, with larger gains on longer captions, plus better robustness on RoCOCO.
What carries the argument
A caption-conditioned masking module applied to sparse-autoencoder-disentangled image embeddings that selectively reconstructs only text-relevant features.
If this is right
- Higher retrieval performance on coarse short-caption datasets such as MS COCO and Flickr.
- Even larger gains on fine-grained long-caption datasets such as IIW and DOCCI.
- Improved robustness measured on the RoCOCO benchmark.
- The editing step works without retraining the underlying CLIP weights.
Where Pith is reading between the lines
- The same masking logic could be tested on other vision-language embedding spaces besides CLIP.
- If the selector generalizes, it might allow targeted removal of unwanted attributes from embeddings for downstream tasks.
- The approach might reduce the need for paired data by letting text steer which visual information survives in the shared space.
Load-bearing premise
A masking module trained on synthetic captions will correctly identify and keep only the relevant features when applied to embeddings from real images and natural captions.
What would settle it
No gain or a drop in retrieval accuracy on the MS COCO, Flickr, IIW, DOCCI, and RoCOCO benchmarks after applying the TEVI masking step to a CLIP model would falsify the central claim.
Figures


read the original abstract
Vision-language models such as CLIP are highly useful for diverse tasks due to their shared image-text embedding space. Despite this, the image and text embeddings are often poorly aligned, affecting downstream performance. Recent work has shown that this can be attributed to an information imbalance: images contain more information than their captions describe. In this work, we propose TEVI, a framework that uses captions as a signal for what to retain from image embeddings. Specifically, we use sparse autoencoders to disentangle image embeddings and train a masking module to selectively reconstruct the embedding based on a given caption. In a controlled setup with synthetic captions, we show that TEVI is effective at preserving caption-described attributes while discarding others. By applying TEVI to CLIP models trained on natural images, we further achieve improved retrieval performance across coarse-grained short-caption (MS COCO, Flickr) and fine-grained long-caption (IIW, DOCCI) benchmarks, with stronger gains on richer captions, and improved robustness on the RoCOCO benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TEVI, which uses sparse autoencoders to disentangle image embeddings from vision-language models like CLIP and trains a masking module to selectively retain features based on a given caption. It validates the approach in a synthetic caption controlled setup for preserving described attributes and reports improved retrieval performance on benchmarks including MS COCO, Flickr for coarse-grained and IIW, DOCCI for fine-grained, plus better robustness on RoCOCO, with stronger gains on richer captions.
Significance. Should the generalization from synthetic to natural captions hold and the experimental results prove robust with proper controls, TEVI could offer an efficient post-training method to mitigate information imbalance in VLMs, leading to better alignment and performance on retrieval tasks, especially those involving detailed descriptions. The integration of SAEs for disentangling representations is a notable technical contribution if the features prove interpretable and the masking effective.
major comments (2)
- [Abstract] The abstract reports performance lifts but supplies no quantitative details on training, error bars, ablation controls, or how post-hoc choices affect the reported gains; the central claim therefore rests on unverified experimental execution.
- [Abstract] The masking module is trained exclusively on synthetic captions to learn which SAE features to retain, but the improved retrieval performance claims on natural image-caption benchmarks (MS COCO, Flickr, IIW, DOCCI, RoCOCO) rely on the assumption that this selector generalizes without introducing mismatches; no validation is provided that the selected features remain caption-relevant under shifts in caption style, length, and visual complexity.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the abstract and provide additional validation where needed.
read point-by-point responses
-
Referee: [Abstract] The abstract reports performance lifts but supplies no quantitative details on training, error bars, ablation controls, or how post-hoc choices affect the reported gains; the central claim therefore rests on unverified experimental execution.
Authors: We agree the abstract is currently high-level and would benefit from quantitative anchors. In revision we will add specific recall@K improvements on the reported benchmarks, note that all results include error bars from multiple random seeds, and explicitly reference the ablation studies and training controls already present in Sections 4 and 5. The full experimental protocol (including post-hoc hyper-parameter choices and their sensitivity) is documented in the main text and supplementary material; we will make this linkage clearer in the abstract. revision: yes
-
Referee: [Abstract] The masking module is trained exclusively on synthetic captions to learn which SAE features to retain, but the improved retrieval performance claims on natural image-caption benchmarks (MS COCO, Flickr, IIW, DOCCI, RoCOCO) rely on the assumption that this selector generalizes without introducing mismatches; no validation is provided that the selected features remain caption-relevant under shifts in caption style, length, and visual complexity.
Authors: The controlled synthetic-caption experiments in the paper directly validate that the masking module preserves caption-described attributes while discarding others. Application to the natural-caption benchmarks then yields consistent gains, with larger improvements on the richer, longer-caption sets (IIW, DOCCI) than on short-caption sets (COCO, Flickr). This pattern supplies indirect empirical support for generalization. We nevertheless acknowledge that an explicit side-by-side comparison of selected SAE features under synthetic versus natural caption distributions is not currently reported. We will add this analysis (or a targeted cross-style validation experiment) in the revised manuscript. revision: yes
Circularity Check
No circularity: gains measured on external benchmarks after separate synthetic training
full rationale
The paper trains the masking module exclusively on synthetic captions to learn feature selection via SAEs, then evaluates retrieval improvements on independent real-world benchmarks (MS COCO, Flickr, IIW, DOCCI, RoCOCO). No equations, fitted parameters, or self-citations are shown to reduce the reported gains to the training inputs by construction. The derivation chain remains self-contained against external evaluation data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mothilal Asokan, Kebin Wu, and Fatima Albreiki. 2025. FineLIP: Extending CLIP's Reach via Fine-Grained Alignment with Longer Text Inputs . In CVPR, pages 14495--14504
2025
-
[2]
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, Robert Lasenby, Yifan Wu, Shauna Kravec, Nicholas Schiefer, Tim Maxwell, Nicholas Joseph, Zac Hatfield-Dodds, Alex Tamkin, Karina Nguyen, and 6 others. 2023. Towards Monosemanticity: Decomposing Language Models With D...
2023
-
[3]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. 2025. Learning Multi-Level Features with Matryoshka Sparse Autoencoders . In ICML
2025
-
[4]
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. 2021. Conceptual 12M: Pushing Web-Scale Image-Text Pre-training to Recognize Long-Tail Visual Concepts . In CVPR, pages 3558--3568
2021
-
[5]
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2024. Sparse Autoencoders Find Highly Interpretable Features in Language Models . In ICLR
2024
-
[6]
Bartosz Cywi \'n ski and Kamil Deja. 2025. SAeUron: Interpretable Concept Unlearning in Diffusion Models with Sparse Autoencoders . In ICML
2025
-
[7]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale . In ICLR
2021
-
[8]
Sedigheh Eslami and Gerard de Melo. 2025. Mitigate the Gap: Investigating Approaches for Improving Cross-modal Alignment in CLIP . In ICLR
2025
-
[9]
Eoin Farrell, Yeu-Tong Lau, and Arthur Conmy. 2025. Applying Sparse Autoencoders to Unlearn Knowledge in Language Models . In ICLR
2025
-
[10]
Leo Gao, Tom Dupr \'e la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. 2025. Scaling and Evaluating Sparse Autoencoders . In ICLR
2025
-
[11]
Roopal Garg, Andrea Burns, Burcu Karagol-Ayan, Yonatan Bitton, Ceslee Montgomery, Yasumasa Onoe, Andrew Bunner, Ranjay Krishna, Jason Michael Baldridge, and Radu Soricut. 2024. ImageInWords: Unlocking Hyper-Detailed Image Descriptions . In EMNLP, pages 93--127
2024
-
[12]
Shashank Goel, Hritik Bansal, Sumit Bhatia, Ryan Rossi, Vishwa Vinay, and Aditya Grover. 2022. CyCLIP: Cyclic Contrastive Language-Image Pretraining . In NeurIPS, volume 35, pages 6704--6719
2022
-
[13]
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Lixuan Zhu, Samyak Parajuli, Mike Guo, and 1 others. 2021. The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization . In ICCV
2021
-
[14]
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Xiaodong Song. 2019. Natural Adversarial Examples . In CVPR, pages 15257--15266
2019
-
[16]
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. 2021. Scaling Up Visual and Vision-Language Representation Learning with Noisy Text Supervision . In ICML, pages 4904--4916
2021
-
[17]
Sonia Joseph, Praneet Suresh, Ethan Goldfarb, Lorenz Hufe, Yossi Gandelsman, Robert Graham, Danilo Bzdok, Wojciech Samek, and Blake Aaron Richards. 2025. Steering CLIP's Vision Transformer with Sparse Autoencoders . arXiv preprint arXiv:2504.08729
arXiv 2025
-
[18]
Alex Krizhevsky, Geoffrey Hinton, and 1 others. 2009. Learning Multiple Layers of Features from Tiny Images . Technical Report, Computer Science Department, University of Toronto
2009
-
[19]
Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. 2022. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm . In ICLR
2022
-
[20]
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. 2022. Mind the Gap: Understanding the Modality Gap in Multi-Modal Contrastive Representation Learning . In NeurIPS
2022
-
[21]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll \'a r, and C Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context . In ECCV, pages 740--755
2014
-
[22]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning . In NeurIPS
2023
-
[23]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization . In ICLR
2019
-
[24]
Marco Mistretta, Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Andrew D Bagdanov. 2025. Cross the Gap: Exposing the Intra-modal Misalignment in CLIP via Modality Inversion . In ICLR
2025
-
[25]
Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. 2022. SLIP: Self-supervision meets Language-Image pre-training . In ECCV, pages 529--544
2022
-
[26]
Yasumasa Onoe, Sunayana Rane, Zachary Berger, Yonatan Bitton, Jaemin Cho, Roopal Garg, Alexander Ku, Zarana Parekh, Jordi Pont-Tuset, Garrett Tanzer, and 1 others. 2024. DOCCI: Descriptions of Connected and Contrasting Images . In ECCV, pages 291--309
2024
-
[27]
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation Learning with Contrastive Predictive Coding . arXiv preprint arXiv:1807.03748
Pith/arXiv arXiv 2018
-
[28]
Mateusz Pach, Shyamgopal Karthik, Quentin Bouniot, Serge Belongie, and Zeynep Akata. 2025. Sparse Autoencoders Learn Monosemantic Features in Vision-language Models . In NeurIPS, volume 38, pages 95706--95742
2025
-
[29]
Seulki Park, Daeho Um, Hajung Yoon, Sanghyuk Chun, and Sangdoo Yun. 2024. RoCOCO: Robustness Benchmark of MS-COCO to Stress-Test Image-Text Matching Models . In ECCV, pages 71--91
2024
-
[30]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, and 1 others. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library . In NeurIPS
2019
-
[31]
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. 2015. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models . In ICCV, pages 2641--2649
2015
-
[32]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning Transferable Visual Models from Natural Language Supervision . In ICML, pages 8748--8763
2021
-
[33]
Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Tom Lieberum, Vikrant Varma, J \'a nos Kram \'a r, Rohin Shah, and Neel Nanda. 2024 a . Improving Dictionary Learning with Gated Sparse Autoencoders . In NeurIPS
2024
-
[35]
Sukrut Rao, Sweta Mahajan, Moritz Böhle, and Bernt Schiele. 2024. Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery . In ECCV
2024
-
[36]
Anton Razzhigaev, Arseniy Shakhmatov, Anastasia Maltseva, Vladimir Arkhipkin, Igor Pavlov, Ilya Ryabov, Angelina Kuts, Alexander Panchenko, Andrey Kuznetsov, and Denis Dimitrov. 2023. Kandinsky: An Improved Text-to-Image Synthesis with Image Prior and Latent Diffusion . In EMNLP (Demos)
2023
-
[37]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. 2019. Do ImageNet Classifiers Generalize to ImageNet? In ICML, pages 5389--5400. PMLR
2019
-
[38]
Simon Schrodi, David T Hoffmann, Max Argus, Volker Fischer, and Thomas Brox. 2025. Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Models . In ICLR
2025
-
[39]
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset for Automatic Image Captioning . In ACL , pages 2556--2565
2018
-
[40]
Peiyang Shi, Michael C Welle, M rten Bj \"o rkman, and Danica Kragic. 2023. Towards Understanding the Modality Gap in CLIP . In ICLR 2023 Workshop on Multimodal Representation Learning: Perks and Pitfalls
2023
-
[41]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, and 1 others. 2025. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features . arXiv preprint arXiv:2502.14786
Pith/arXiv arXiv 2025
-
[42]
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P Xing. 2019. Learning Robust Global Representations by Penalizing Local Predictive Power . In NeurIPS, volume 32
2019
-
[43]
Rui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, Zeynep Akata, and Stephan Alaniz. 2025. FLAIR: VLM with Fine-grained Language-informed Image Representations . In CVPR
2025
-
[44]
Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng, and Yuhui Yin. 2025 a . FG-CLIP: Fine-grained Visual and Textual Alignment . In ICML
2025
-
[45]
Shaoan Xie, Lingjing Lingjing, Yujia Zheng, Yu Yao, Zeyu Tang, Eric P Xing, Guangyi Chen, and Kun Zhang. 2025 b . SmartCLIP: Modular Vision-language Alignment with Identification Guarantees . In CVPR, pages 29780--29790
2025
-
[46]
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. 2022. FILIP: Fine-grained Interactive Language-image Pre-training . In ICLR
2022
-
[47]
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. 2022. CoCa: Contrastive Captioners are Image-Text Foundation Models . TMLR
2022
-
[48]
Vladimir Zaigrajew, Hubert Baniecki, and Przemyslaw Biecek. 2025. Interpreting CLIP with Hierarchical Sparse Autoencoders . In ICML
2025
-
[49]
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. 2023. Sigmoid Loss for Language Image Pre-Training . In ICCV, pages 11975--11986
2023
-
[50]
Goel, Shashank and Bansal, Hritik and Bhatia, Sumit and Rossi, Ryan and Vinay, Vishwa and Grover, Aditya , booktitle=NIPS, volume=
-
[51]
Mu, Norman and Kirillov, Alexander and Wagner, David and Xie, Saining , booktitle=ECCV, pages=
-
[52]
Li, Yangguang and Liang, Feng and Zhao, Lichen and Cui, Yufeng and Ouyang, Wanli and Shao, Jing and Yu, Fengwei and Yan, Junjie , booktitle=ICLR, year=
-
[53]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[54]
Moritz Böhle and Mario Fritz and Bernt Schiele , year=
-
[55]
Knowledge distillation: A good teacher is patient and consistent , author=
-
[56]
Distilling Large Vision-Language Model with Out-of-Distribution Generalizability , author=
-
[57]
DIME-FM: DIstilling Multimodal and Efficient Foundation Models , author=
-
[58]
Walid Bousselham and Felix Petersen and Vittorio Ferrari and Hilde Kuehne , year=
-
[59]
ImageBind: One Embedding Space To Bind Them All , author=
-
[60]
What does CLIP know about a red circle? Visual prompt engineering for VLMs , author=
-
[61]
Oikarinen, Tuomas and Das, Subhro and Nguyen, Lam M and Weng, Tsui-Wei , booktitle=ICLR, year=
-
[62]
Panousis, Konstantinos Panagiotis and Ienco, Dino and Marcos, Diego , booktitle=ICCVW, pages=
-
[63]
DISCOVER: Making Vision Networks Interpretable via Competition and Dissection , author=
-
[64]
arXiv preprint arXiv:2312.00110 , year=
CLIP-QDA: An Explainable Concept Bottleneck Model , author=. arXiv preprint arXiv:2312.00110 , year=
-
[65]
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification , author=
-
[66]
Xu, Xinyue and Qin, Yi and Mi, Lu and Wang, Hao and Li, Xiaomeng , booktitle=ICLR, year=
-
[67]
Visual classification via description from large language models , author=
-
[68]
2022 , url=
Natural Language Descriptions of Deep Features , author=. 2022 , url=
2022
-
[69]
Koh, Pang Wei and Nguyen, Thao and Tang, Yew Siang and Mussmann, Stephen and Pierson, Emma and Kim, Been and Liang, Percy , booktitle = ICML, pages =
-
[70]
2023 , booktitle =
Interactive Concept Bottleneck Models , author =. 2023 , booktitle =
2023
-
[71]
Probabilistic Concept Bottleneck Models , author=
-
[72]
Yuksekgonul, Mert and Wang, Maggie and Zou, James , booktitle=ICLR, year=
-
[73]
arXiv preprint arXiv:2310.02116 , year=
Hierarchical Concept Discovery Models: A Concept Pyramid Scheme , author=. arXiv preprint arXiv:2310.02116 , year=
-
[74]
Cross-Modal Conceptualization in Bottleneck Models , author=
-
[75]
Sophia and Vinyals, Oriol and Schmid, Cordelia and Akata, Zeynep , title =
Roth, Karsten and Kim, Jae Myung and Koepke, A. Sophia and Vinyals, Oriol and Schmid, Cordelia and Akata, Zeynep , title =. 2023 , pages =
2023
-
[76]
Meghal Dani and Isabel Rio
-
[77]
Fel, Thomas and Picard, Agustin and Bethune, Louis and Boissin, Thibaut and Vigouroux, David and Colin, Julien and Cad
-
[78]
A holistic approach to unifying automatic concept extraction and concept importance estimation , author=
-
[79]
Disentangling Neuron Representations with Concept Vectors , author=
-
[80]
Oikarinen, Tuomas and Weng, Tsui-Wei , booktitle=ICLR, year=
-
[81]
Moayeri, Mazda and Rezaei, Keivan and Sanjabi, Maziar and Feizi, Soheil , booktitle=ICML, pages=
-
[82]
Diagnosing and rectifying vision models using language , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.