Steer Where It Matters: Token-Level Visual-Sensitivity Steering for LVLMs Hallucination Mitigation
Pith reviewed 2026-06-28 10:20 UTC · model grok-4.3
The pith
Token-level visual-sensitivity steering mitigates hallucinations in large vision-language models by intervening only at critical decoding steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
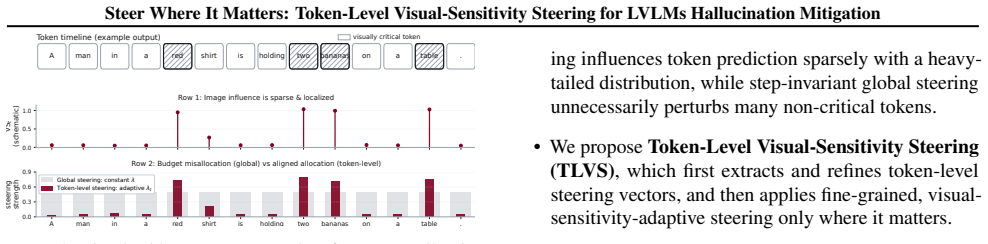
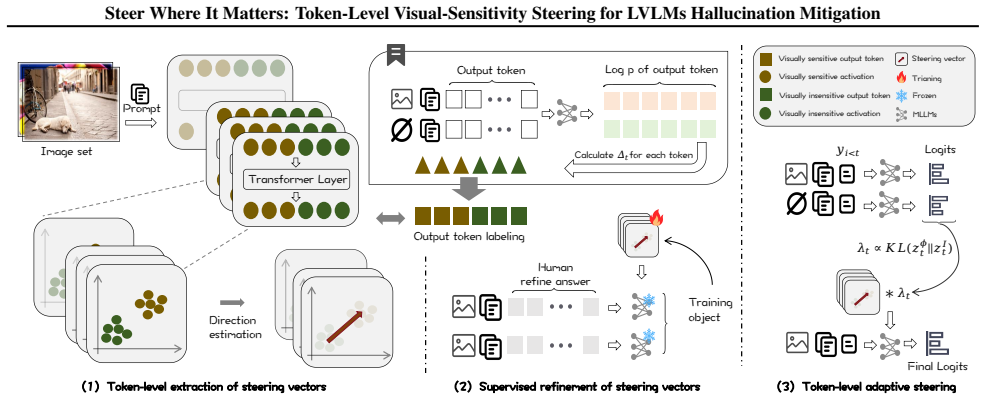
TLVS extracts token-level steering vectors from image-versus-no-image activation differences, refines them, and applies them with strength modulated by each token's measured visual sensitivity so that intervention occurs only on hallucination-prone positions.
What carries the argument
Token-level visual-sensitivity map that selects both the direction and the per-step magnitude of the steering vector during decoding.
Load-bearing premise
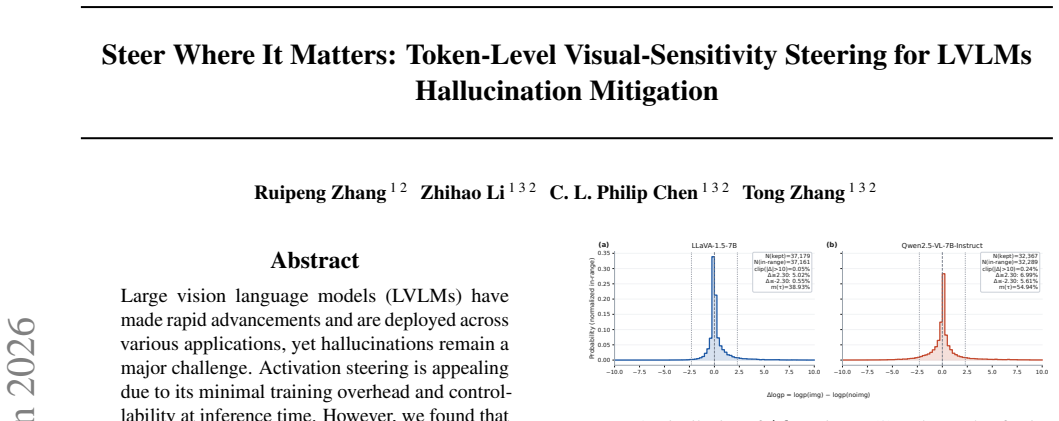
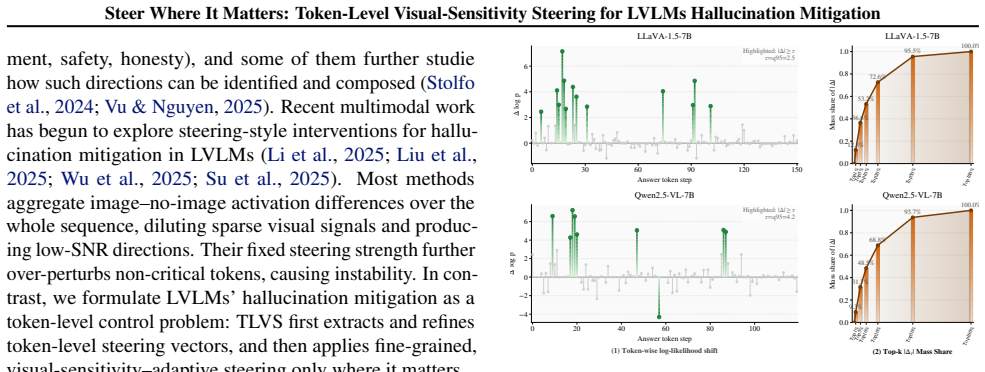
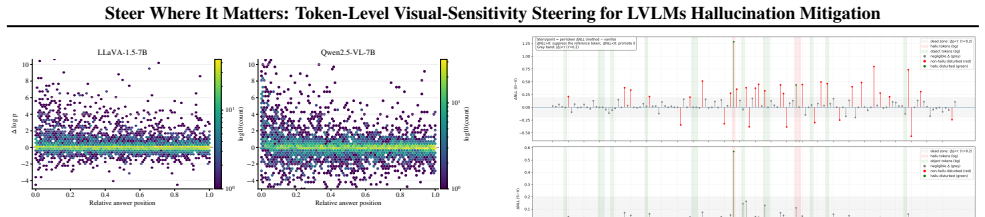
Visual conditioning affects token prediction sparsely and locally across decoding steps such that averaging over the full sequence necessarily dilutes the useful signal.
What would settle it
Run the same set of prompts through both a sequence-averaged steering vector and the token-level version; if hallucination rates remain statistically identical, the core premise does not hold.
Figures
read the original abstract
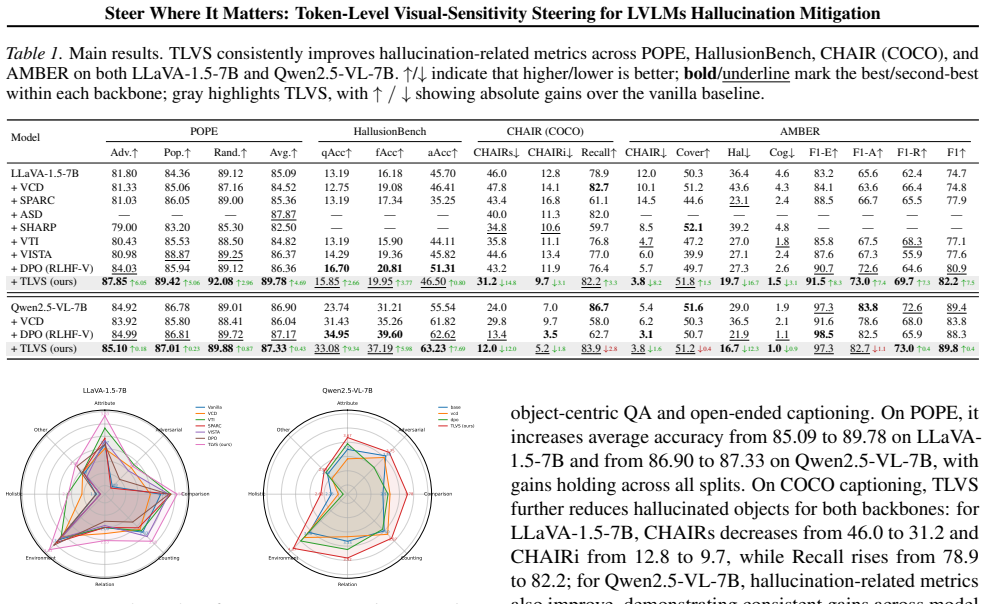
Large vision language models (LVLMs) have made rapid advancements and are deployed across various applications, yet hallucinations remain a major challenge. Activation steering is appealing due to its minimal training overhead and controllability at inference time. However, we found that during autoregressive decoding, visual conditioning affects token prediction sparsely and locally across decoding steps, and many existing methods that average image-versus-no-image differences over the entire sequence dilute these critical signals, yielding low signal-to-noise ratio steering directions. Additionally, many existing methods apply a fixed steering strength, which misallocates the intervention budget, over-perturbs non-critical tokens, and can cause instability. To address these limitations, we propose Token-Level Visual-Sensitivity Steering (TLVS) for hallucination mitigation. Our approach first extracts token-level steering vectors and refines them, and then applies fine-grained, visual-sensitivity-adaptive steering only where it matters. This lightweight, plug-and-play mechanism requires only minimal training for calibration and can be applied across diverse vision-language models. It modulates the steering strength at each decoding step, selectively suppressing hallucination-prone spans while preserving evidence-grounded content. We evaluate TLVS on several benchmarks, including POPE, AMBER, CHAIR (COCO), MMHal, and HallusionBench, demonstrating consistent improvements over previous steering methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that visual conditioning in LVLMs affects token prediction sparsely and locally during autoregressive decoding, so that sequence-level averaging of image-versus-no-image activation differences produces low-SNR steering vectors. It proposes Token-Level Visual-Sensitivity Steering (TLVS), which extracts per-token steering vectors, refines them, and applies visual-sensitivity-adaptive steering strength only at hallucination-prone steps. The method is presented as lightweight and plug-and-play, requiring only minimal calibration, and is reported to yield consistent gains over prior steering baselines on POPE, AMBER, CHAIR (COCO), MMHal, and HallusionBench.
Significance. If the token-level extraction and adaptive application are shown to be robust, the approach would supply a practical, low-overhead inference-time intervention for LVLM hallucination that avoids the dilution problem of global averaging and the instability of fixed-strength steering. The emphasis on sparse, position-specific visual effects aligns with known properties of autoregressive generation and could generalize across model families.
major comments (2)
- [Method (token-level steering vector extraction)] The central extraction procedure (described in the method) computes token-level steering vectors as the difference between hidden states (or logits) in an image-conditioned forward pass and a no-image pass at each decoding step. No mention is made of teacher-forcing, position remapping, or any alignment mechanism to ensure that the k-th token in the two trajectories occupies an equivalent semantic context. In autoregressive decoding the first differing token causes all subsequent positions to diverge, so the reported per-token differences necessarily compare activations from mismatched output distributions. This directly undermines the claim that token-level extraction yields higher-SNR directions than sequence averaging.
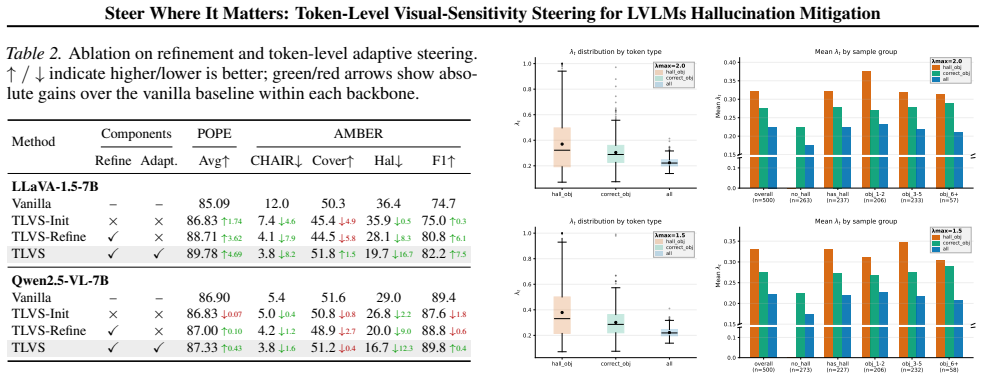
- [Experiments / Ablations] The paper asserts that the proposed adaptive steering “selectively suppresses hallucination-prone spans while preserving evidence-grounded content,” yet no ablation isolates the contribution of the visual-sensitivity weighting from the simple act of applying any per-token modulation. Without such a control, it is unclear whether the reported benchmark gains are attributable to the claimed sparsity insight or to the general benefit of non-uniform intervention strength.
minor comments (2)
- [Method] Notation for the steering vector (e.g., whether it is defined on hidden states, attention outputs, or logits) should be stated explicitly with an equation in the method section.
- [Method] The calibration procedure for the visual-sensitivity threshold is described only at a high level; a precise algorithmic statement or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which help clarify key aspects of our method and evaluation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Method (token-level steering vector extraction)] The central extraction procedure (described in the method) computes token-level steering vectors as the difference between hidden states (or logits) in an image-conditioned forward pass and a no-image pass at each decoding step. No mention is made of teacher-forcing, position remapping, or any alignment mechanism to ensure that the k-th token in the two trajectories occupies an equivalent semantic context. In autoregressive decoding the first differing token causes all subsequent positions to diverge, so the reported per-token differences necessarily compare activations from mismatched output distributions. This directly undermines the claim that token-level extraction yields higher-SNR directions than sequence averaging.
Authors: The referee correctly notes that the manuscript does not describe any alignment mechanism for the token-level extraction. This is a valid point regarding the current presentation. We will revise the method section to explicitly specify the extraction procedure, including the use of teacher-forcing on matched token sequences (derived from the image-conditioned trajectory) for both passes to ensure positional and contextual alignment at each step. This clarification will directly support the higher-SNR claim by addressing the potential for mismatched distributions. revision: yes
-
Referee: [Experiments / Ablations] The paper asserts that the proposed adaptive steering “selectively suppresses hallucination-prone spans while preserving evidence-grounded content,” yet no ablation isolates the contribution of the visual-sensitivity weighting from the simple act of applying any per-token modulation. Without such a control, it is unclear whether the reported benchmark gains are attributable to the claimed sparsity insight or to the general benefit of non-uniform intervention strength.
Authors: We agree that the current experiments do not include an ablation that isolates the visual-sensitivity-adaptive weighting from the general effect of any non-uniform per-token modulation. This is a fair observation that would strengthen the attribution to our sparsity insight. We will add a targeted ablation in the revised version, comparing TLVS against a control that applies per-token modulation with fixed or randomly varying strengths, to demonstrate the specific contribution of the sensitivity-based adaptation. revision: yes
Circularity Check
No circularity: empirical method with external benchmarks
full rationale
The paper describes an empirical activation-steering procedure (token-level image/no-image differences, refinement, and per-token adaptive scaling) whose claimed gains are measured on independent benchmarks (POPE, AMBER, CHAIR, MMHal, HallusionBench). No equation or step reduces a claimed result to a fitted parameter or self-citation by construction; the central premise is an observed empirical pattern rather than a definitional identity. The derivation chain therefore remains self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, W., Yan, X., Wen, B., Yang, F., Gao, T., Zhang, D., and Chen, L. Decoupling contrastive decoding: Robust hallucination mitigation in multimodal large language models.arXiv preprint arXiv:2504.08809,
-
[3]
Fang, H., Zhou, C., Kong, J., Gao, K., Chen, B., Liang, T., Ma, G., and Xia, S.-T. Grounding language with vision: A conditional mutual information calibrated decoding strat- egy for reducing hallucinations in lvlms.arXiv preprint arXiv:2505.19678,
-
[4]
M., and Soricut, R
Garg, R., Burns, A., Karagol-Ayan, B., Bitton, Y ., Mont- gomery, C., Onoe, Y ., Bunner, A., Krishna, R., Baldridge, J. M., and Soricut, R. Imageinwords: Unlocking hyper- detailed image descriptions. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp. 93–127,
2024
-
[5]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Huang, W., Wang, C., Zhang, R., Li, Y ., Wu, J., and Fei-Fei, L. V oxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Huo, F., Xu, W., Zhang, Z., Wang, H., Chen, Z., and Zhao, P. Self-introspective decoding: Alleviating hallucina- tions for large vision-language models.arXiv preprint arXiv:2408.02032,
-
[7]
Jung, M., Lee, S., Kim, E., and Yoon, S. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large lan- guage models.arXiv preprint arXiv:2502.01419,
-
[8]
Lee, S., Park, S. H., Jo, Y ., and Seo, M. V olcano: mitigating multimodal hallucination through self-feedback guided revision. InProceedings of the 2024 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 391–404, 2024a. Lee, S., Yoon, S., Bui, T., Shi, J., ...
-
[9]
Evaluating Object Hallucination in Large Vision-Language Models
9 Steer Where It Matters: Token-Level Visual-Sensitivity Steering for LVLMs Hallucination Mitigation Li, Y ., Du, Y ., Zhou, K., Wang, J., Zhao, W. X., and Wen, J.-R. Evaluating object hallucination in large vision- language models.arXiv preprint arXiv:2305.10355,
work page internal anchor Pith review Pith/arXiv arXiv
- [10]
-
[11]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, H., Liu, W., Zhang, B., Wang, B., Dong, K., Liu, B., Sun, J., Ren, T., Li, Z., Yang, H., et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qian, J., Shen, Y ., Chen, Z., Zhou, J., and Wang, P. Cotbox-ttt: Grounding medical vqa with visual chain- of-thought boxes during test-time training.arXiv preprint arXiv:2511.12446,
-
[13]
Object Hallucination in Image Captioning
Rohrbach, A., Hendricks, L. A., Burns, K., Darrell, T., and Saenko, K. Object hallucination in image captioning. arXiv preprint arXiv:1809.02156,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Stolfo, A., Balachandran, V ., Yousefi, S., Horvitz, E., and Nushi, B. Improving instruction-following in lan- guage models through activation steering.arXiv preprint arXiv:2410.12877,
-
[15]
Aligning large multi- modal models with factually augmented rlhf
Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y ., Gan, C., Gui, L., Wang, Y .-X., Yang, Y ., et al. Aligning large multi- modal models with factually augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 13088–13110,
2024
- [16]
-
[17]
Y ., Xu, N., Zhang, S., Poon, H., and Chen, M
Wang, F., Zhou, W., Huang, J. Y ., Xu, N., Zhang, S., Poon, H., and Chen, M. mdpo: Conditional preference opti- mization for multimodal large language models.arXiv preprint arXiv:2406.11839,
-
[18]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Wang, J., Wang, Y ., Xu, G., Zhang, J., Gu, Y ., Jia, H., Wang, J., Xu, H., Yan, M., Zhang, J., et al. Amber: An llm-free multi-dimensional benchmark for mllms hallucination evaluation.arXiv preprint arXiv:2311.07397,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Sharp: Steering hal- lucination in lvlms via representation engineering
Wu, J., Ding, Y ., Liu, G., Xia, T., Huang, Z., Sui, D., Liu, Q., Wu, S., Wang, L., and Tan, T. Sharp: Steering hal- lucination in lvlms via representation engineering. In Proceedings of the 2025 Conference on Empirical Meth- ods in Natural Language Processing, pp. 14357–14372,
2025
-
[20]
10 Steer Where It Matters: Token-Level Visual-Sensitivity Steering for LVLMs Hallucination Mitigation Xie, Y ., Li, G., Xu, X., and Kan, M.-Y . V-dpo: Mitigating hallucination in large vision language models via vision- guided direct preference optimization.arXiv preprint arXiv:2411.02712,
-
[21]
Re-align: Align- ing vision language models via retrieval-augmented direct preference optimization
Xing, S., Li, P., Wang, Y ., Bai, R., Wang, Y ., Hu, C.- W., Qian, C., Yao, H., and Tu, Z. Re-align: Align- ing vision language models via retrieval-augmented direct preference optimization. In Christodoulopou- los, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Conference on Em- pirical Methods in Natural Language Processing,...
2025
-
[22]
Asso- ciation for Computational Linguistics. ISBN 979- 8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[23]
emnlp-main.121/
URL https://aclanthology.org/2025. emnlp-main.121/. Yang, T., Li, Z., Cao, J., and Xu, C. Understanding and mitigating hallucination in large vision-language models via modular attribution and intervention. In Yue, Y ., Garg, A., Peng, N., Sha, F., and Yu, R. (eds.),International Con- ference on Learning Representations, volume 2025, pp. 51546–51568,
2025
-
[24]
iclr.cc/paper_files/paper/2025/file/ 8001c3568152d134d821cd46d4d84768-Paper-Conference
URL https://proceedings. iclr.cc/paper_files/paper/2025/file/ 8001c3568152d134d821cd46d4d84768-Paper-Conference. pdf. Yin, S., Fu, C., Zhao, S., Xu, T., Wang, H., Sui, D., Shen, Y ., Li, K., Sun, X., and Chen, E. Woodpecker: Hallucination correction for multimodal large language models.Science China Information Sciences, 67(12):220105,
2025
-
[25]
Ferret: Refer and Ground Anything Anywhere at Any Granularity
You, H., Zhang, H., Gan, Z., Du, X., Zhang, B., Wang, Z., Cao, L., Chang, S.-F., and Yang, Y . Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Active layer-contrastive decoding reduces hallucination in large language model generation
Zhang, H., Chen, H., Chen, M., and Zhang, T. Active layer-contrastive decoding reduces hallucination in large language model generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 3028–3046, 2025a. Zhang, J., Khayatkhoei, M., Chhikara, P., and Ilievski, F. Mllms know where to look: Training-free perceptio...
-
[27]
Unless otherwise specified, we run this analysis on the AMBER benchmark (Wang et al., 2023). AMBER protocol and annotations.AMBER provides images with structured annotations and an LLM-free evaluation protocol covering existence, attribute, and relation hallucinations (Wang et al., 2023). Following AMBER’s generative setting, we obtain the reference respo...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.