Contrast encodes inductive bias: separating slow noise from dynamics in predictive representation learning
Pith reviewed 2026-06-27 22:35 UTC · model grok-4.3
The pith
Contrastive predictive objectives encode slow noise instead of dynamics when negatives are sampled across trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
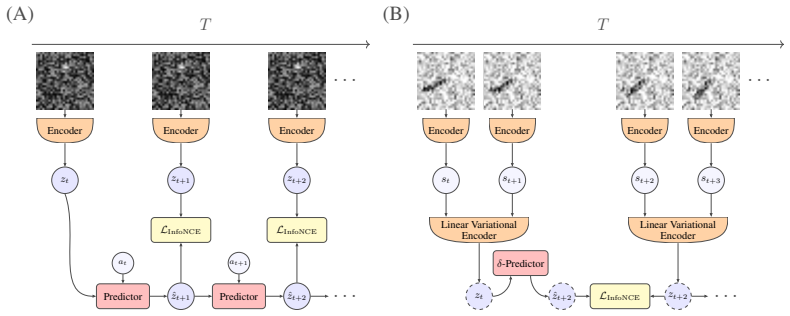
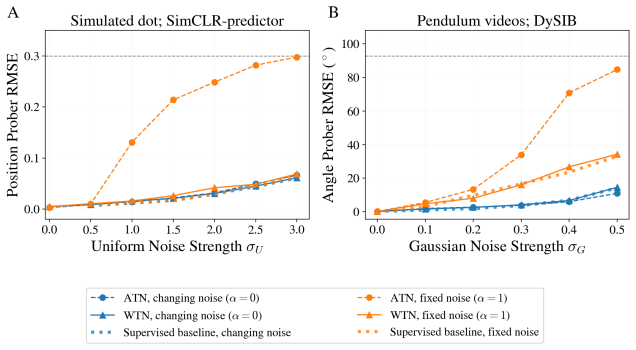
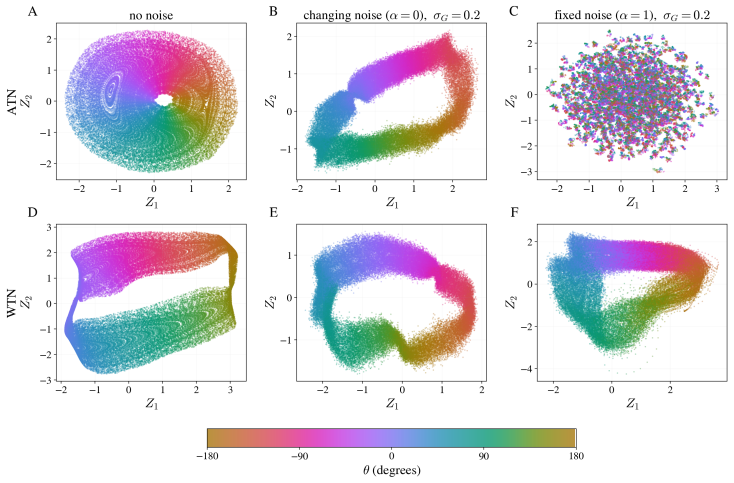
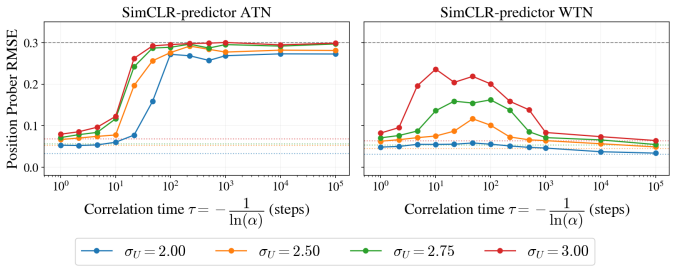
When negatives are sampled across trajectories, contrastive predictive objectives encode trajectory-specific slow noise rather than the latent variables that govern the observed dynamics; sampling negatives within a single trajectory removes this shortcut and forces the encoder to capture the dynamics.
What carries the argument
Negative sampling strategy in contrastive predictive objectives: drawing negatives from other trajectories lets constant-within-trajectory noise serve as a distinguishing cue, while within-trajectory sampling removes that cue.
If this is right
- Representations learned with across-trajectory negatives will be dominated by trajectory identity rather than state variables, so downstream task performance will degrade as noise amplitude increases.
- Representations learned with within-trajectory negatives will improve as the number and duration of trajectories grow, even when slow noise is strong.
- The same failure mode appears in any contrastive predictive objective that draws negatives across trajectories, including SimCLR-style JEPA variants and DySIB.
- Physical systems observed with slowly drifting experimental noise require within-trajectory negative sampling to extract interpretable dynamical representations.
Where Pith is reading between the lines
- The same sampling principle may apply to other self-supervised objectives that rely on temporal or trajectory-level negatives, such as masked prediction or reconstruction losses in latent space.
- For real-world robotics or neuroscience data, experimenters could record long continuous trajectories and deliberately reuse frames from the same recording as negatives during training.
- The result suggests a general design rule: any contrastive objective whose negatives can be distinguished by a static cue will learn that cue instead of the intended signal.
Load-bearing premise
Noise features remain approximately constant within each trajectory so they can distinguish frames across different trajectories.
What would settle it
Train the same encoder on the pendulum movies with strong slow noise; measure whether within-trajectory negative sampling yields representations whose downstream prediction error decreases with trajectory length while across-trajectory sampling does not.
Figures
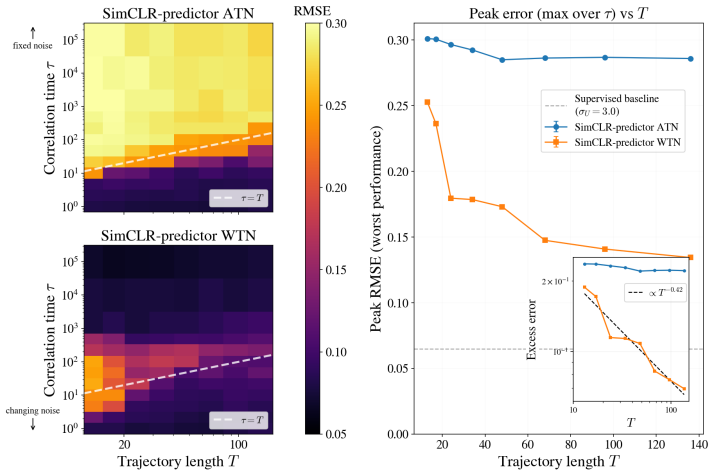
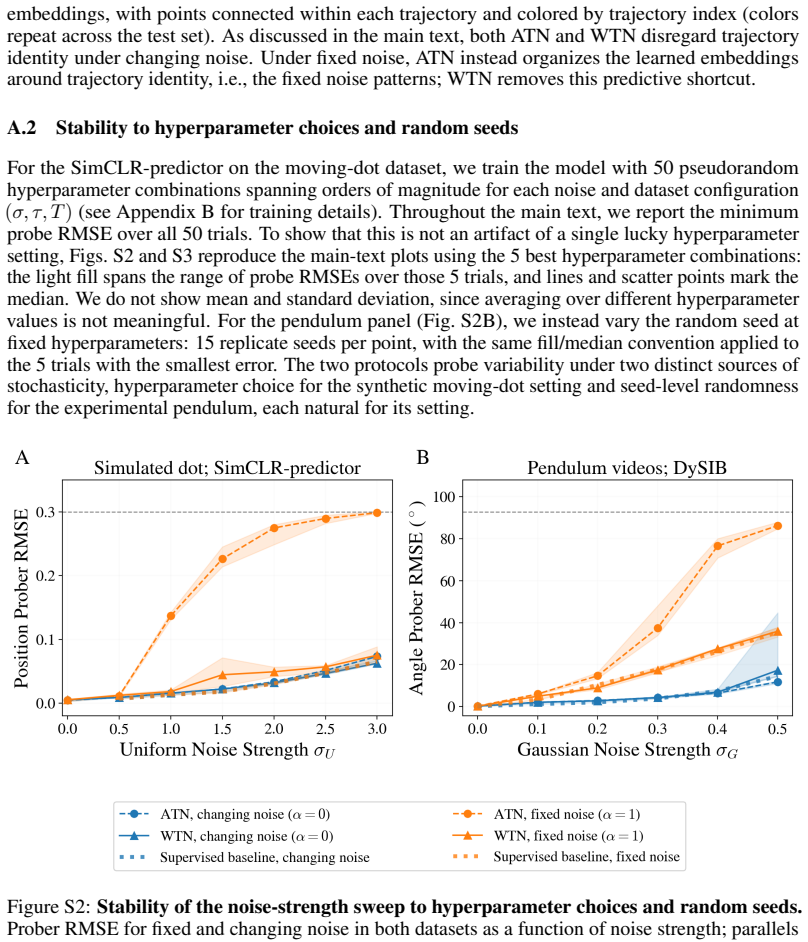
read the original abstract
Self-supervised methods that learn representations and predict dynamics fully in the latent space, such as JEPA, have been shown to confuse slowly varying noise with the dynamical signals they aim to capture. Specifically, when noise features remain approximately constant within each trajectory, contrastive predictive objectives preferentially encode these features instead of the true latent variables governing the system. The learned representation then becomes dominated by trajectory-specific noise, so downstream performance degrades with noise strength and does not improve even as the number and duration of training trajectories increase. We argue that this failure is a property of the objective itself, shared by a long line of contrastive predictive objectives that sample negatives across trajectories. To illustrate this generality, we study the failure mode and its remedy in two settings: a standard SimCLR-style JEPA on a synthetic moving-dot dataset, and DySIB, a recently introduced method designed for extracting physically interpretable representations of dynamics, on movies of a rigid-body pendulum. When negatives are instead sampled within a single trajectory, the slow noise can no longer distinguish frames within that trajectory, removing the predictive shortcut. Training one encoder simultaneously on many such trajectories then forces it to encode the variables relevant for the dynamics, with longer trajectories yielding better representations even for strong slow noise. Our results point toward principles for designing contrastive predictive objectives in dynamical representation learning, especially for physical systems with noisy experimental observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that contrastive predictive objectives (e.g., JEPA-style and DySIB) that draw negatives across trajectories encode slowly varying, trajectory-constant noise features rather than true dynamical variables; this is shown to degrade downstream performance in a manner independent of data volume. The failure is illustrated via controlled synthetic experiments on moving-dot trajectories (SimCLR-style JEPA) and pendulum movies (DySIB). Switching to within-trajectory negative sampling removes the shortcut, yielding representations that improve with trajectory length even under strong noise. The authors argue the issue is intrinsic to the objective class.
Significance. If the central mechanism holds, the work identifies a load-bearing inductive bias in a family of contrastive predictive losses used for dynamical representation learning, with direct implications for method design on noisy physical data. The controlled synthetic experiments directly illustrate both the failure mode and its removal, providing clear, falsifiable support for the proposed noise-encoding shortcut without reliance on fitted parameters or self-referential definitions.
major comments (1)
- [Abstract] Abstract and introduction: the assertion that the failure 'is a property of the objective itself, shared by a long line of contrastive predictive objectives that sample negatives across trajectories' rests on demonstrations in two specific architectures/datasets; without a general loss analysis, reduction to other objectives (e.g., CPC or InfoNCE variants), or proof that the minimizer must prefer constant-per-trajectory noise features under the stated noise model, the generality claim is not yet load-bearing.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the clear identification of where our generality claim requires additional support. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and introduction: the assertion that the failure 'is a property of the objective itself, shared by a long line of contrastive predictive objectives that sample negatives across trajectories' rests on demonstrations in two specific architectures/datasets; without a general loss analysis, reduction to other objectives (e.g., CPC or InfoNCE variants), or proof that the minimizer must prefer constant-per-trajectory noise features under the stated noise model, the generality claim is not yet load-bearing.
Authors: We agree that the current evidence consists of controlled demonstrations in two representative settings rather than a formal reduction or proof, and that this limits the strength of the generality assertion. The mechanism we identify is tied to the shared structure of cross-trajectory negative sampling, which permits any approximately constant-per-trajectory feature to act as a loss-minimizing shortcut. We will revise the abstract and introduction to qualify the claim as applying to the class of contrastive predictive objectives that employ cross-trajectory negatives, and we will add a short subsection providing a qualitative analysis of the InfoNCE-style loss under the slow-noise model. This analysis will show why the minimizer favors trajectory-constant features and will briefly indicate how the same logic extends to CPC and standard InfoNCE variants. These changes will be marked as partial because a complete mathematical proof for every possible variant is beyond the scope of the revision. revision: partial
Circularity Check
No circularity: empirical illustrations on synthetic data do not reduce to fitted inputs or self-definitions
full rationale
The manuscript's central argument—that the observed failure mode is an inherent property of contrastive predictive objectives sampling negatives across trajectories—is advanced via controlled experiments on two synthetic datasets (moving dots with SimCLR-style JEPA; pendulum movies with DySIB). No equations, loss derivations, or uniqueness theorems are supplied that would allow a prediction or result to be rewritten as an input by construction. The text contains no self-citation chains invoked as load-bearing mathematical facts, no fitted parameters renamed as predictions, and no ansatzes smuggled via prior work. The demonstration is therefore self-contained against external benchmarks (the two data generators) and does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Noise features remain approximately constant within each trajectory
Reference graph
Works this paper leans on
-
[1]
Joint embedding predictive architectures focus on slow features , author=. 2022 , howpublished=. 2211.10831 , archiveprefix=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Removing the background by adding the background: Towards background robust self-supervised video representation learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised video representation learning by context and motion decoupling , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Motion-aware contrastive video representation learning via foreground-background merging , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Tubelet-contrastive self-supervision for video-efficient generalization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[6]
dynamic information , author=
A deeper dive into what deep spatiotemporal networks encode: Quantifying static vs. dynamic information , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[7]
Denoised MDPs: Learning world models better than the world itself , author=. 2022 , howpublished=. 2206.15477 , archiveprefix=
-
[8]
Revisiting Feature Prediction for Learning Visual Representations from Video
Revisiting feature prediction for learning visual representations from video , author=. 2024 , howpublished=. 2404.08471 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M. and Bardes, A. and Fan, D. and Garrido, Q. and Howes, R. and Komeili, M. and Muckley, M. and Rizvi, A. and Roberts, C. and Sinha, K. and Zholus, A. and Arnaud, S. and Gejji, A. and Martin, A. and Hogan, F. R. and Dugas, D. and Bojanowski, P. and Khalidov, V. and Labatut, P. and Massa, F. and Szafraniec, M. and Krishnakumar, K. and Li, Y. and Ma...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[11]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. 2018 , howpublished=. 1807.03748 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Advances in Neural Information Processing Systems , volume=
What makes for good views for contrastive learning? , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Conditional contrastive learning for improving fairness in self-supervised learning , author=. 2021 , howpublished=. 2106.02866 , archiveprefix=
-
[14]
Journal of Machine Learning Research , volume=
Emergence of invariance and disentanglement in deep representations , author=. Journal of Machine Learning Research , volume=
-
[15]
OpenReview , volume=
A path towards autonomous machine intelligence version 0.9.2, 2022-06-27 , author=. OpenReview , volume=
2022
-
[16]
Martini, K. M. and Abdelaleem, E. and Gulati, P. and Nemenman, I. , title =. 2026 , howpublished =. 2604.24662 , archiveprefix =
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
LeJEPA: Provable and scalable self-supervised learning without the heuristics , author=. 2025 , howpublished=. 2511.08544 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
LeWorldModel: Stable end-to-end joint-embedding predictive architecture from pixels , author=. 2026 , howpublished=. 2603.19312 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Neural Computation , volume=
Data efficiency, dimensionality reduction, and the generalized symmetric information bottleneck , author=. Neural Computation , volume=
-
[20]
Joint embedding vs reconstruction: Provable benefits of latent space prediction for self-supervised learning , author=. 2025 , howpublished=. 2505.12477 , archiveprefix=
-
[21]
Nature Computational Science , volume=
Automated discovery of fundamental variables hidden in experimental data , author=. Nature Computational Science , volume=
-
[22]
Cell , volume=
Machine learning interpretable models of cell mechanics from protein images , author=. Cell , volume=
-
[23]
Gurevich, D. R. and Golden, M. R. and Reinbold, P. A. K. and Grigoriev, R. O. , journal=. Learning fluid physics from highly turbulent data using sparse physics-informed discovery of empirical relations (
-
[24]
Cell Reports Methods , volume=
Inferring single-cell transcriptomic dynamics with structured latent gene expression dynamics , author=. Cell Reports Methods , volume=
-
[25]
2025 , howpublished=
Interpretable gene network inference with nonlinear causality , author=. 2025 , howpublished=
2025
-
[26]
Daniels, B. C. and Ryu, W. S. and Nemenman, I. , journal=. Automated, predictive, and interpretable inference of
-
[27]
Proceedings of the National Academy of Sciences , volume=
Physics-tailored machine learning reveals unexpected physics in dusty plasmas , author=. Proceedings of the National Academy of Sciences , volume=
-
[28]
International Conference on Learning Representations , year=
Towards principled representation learning from videos for reinforcement learning , author=. International Conference on Learning Representations , year=
-
[29]
and Misra, D
Efroni, Y. and Misra, D. and Krishnamurthy, A. and Agarwal, A. and Langford, J. , booktitle=. Provable
-
[30]
Yu, J. and Chen, S. and Liu, M. and Horiuchi, N. and Braverman, V. and Xu, Z. and Haramati, D. and Balestriero, R. , year=. Why and how auxiliary tasks improve. 2509.12249 , archiveprefix=
-
[31]
Causal-JEPA: Learning World Models through Object-Level Latent Masking
Nam, J. and Le Lidec, Q. and Maes, L. and LeCun, Y. and Balestriero, R. , year=. Causal-. 2602.11389 , archiveprefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Learning invariant visual representations for planning with joint-embedding predictive world models , author=. 2026 , howpublished=. 2602.18639 , archiveprefix=
-
[33]
Neural Computation , volume=
Slow feature analysis: Unsupervised learning of invariances , author=. Neural Computation , volume=
-
[34]
International Conference on Machine Learning , pages=
Understanding contrastive learning requires incorporating inductive biases , author=. International Conference on Machine Learning , pages=
-
[35]
Advances in Neural Information Processing Systems , volume=
Self-supervised learning with data augmentations provably isolates content from style , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
International Conference on Machine Learning , pages=
Understanding contrastive representation learning through alignment and uniformity on the hypersphere , author=. International Conference on Machine Learning , pages=
-
[37]
International Conference on Learning Representations , year=
What should not be contrastive in contrastive learning , author=. International Conference on Learning Representations , year=
-
[38]
Koopman invariants as drivers of emergent time-series clustering in joint-embedding predictive architectures , author=. 2025 , howpublished=. 2511.09783 , archiveprefix=
-
[39]
and Pereira, F
Tishby, N. and Pereira, F. C. and Bialek, W. , title =. 37th Annual Allerton Conference on Communication, Control, and Computing , pages =
-
[40]
and Mosenzon, O
Friedman, N. and Mosenzon, O. and Slonim, N. and Tishby, N. , title =. Proceedings of the 17th Conference on Uncertainty in Artificial Intelligence (UAI) , pages =
-
[41]
and Fischer, I
Alemi, A. and Fischer, I. and Dillon, J. and Murphy, K. , title =. International Conference on Learning Representations , year =
-
[42]
and Nemenman, I
Abdelaleem, E. and Nemenman, I. and Martini, K. M. , title =. Journal of Machine Learning Research , volume =
-
[43]
and Nemenman, I
Bialek, W. and Nemenman, I. and Tishby, N. , title =. Neural Computation , volume =
-
[44]
, title =
Wiener, N. , title =
-
[45]
Advances in neural information processing systems , volume=
Random features for large-scale kernel machines , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.