Instrumented data for causal scientific machine learning
Pith reviewed 2026-06-27 22:22 UTC · model grok-4.3
The pith
Every training datum can embed its own mechanistic model, uncertainty estimate, and editable counterfactuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that instrumented data, in which every datum carries the mechanistic model that produced it, an explicit uncertainty over that model, and an executable family of counterfactuals, is now operationally feasible. Verification-and-validation instrumented image-to-simulation pipelines realize this by turning a sensor observation into a fully specified, solver-backed simulation with explicit, editable parameters and propagated aleatoric and epistemic uncertainty. The resulting data substrate is case-specific and mechanistically supervised, supports causal interventions through the do-operator, and enables near-term advances in validation, auditing, and surrogate training across co
What carries the argument
Instrumented data, the structure that attaches to each datum its generating mechanistic model, explicit uncertainty, and executable family of counterfactuals.
If this is right
- Training data becomes open to direct causal interventions via the do-operator.
- Validation and auditing gain mechanistic traceability in biology, climate, materials, fluids, and medical imaging.
- Surrogate models can be trained on case-specific, mechanistically supervised examples rather than generic templates.
- A longer-term path opens toward foundation models whose scientific reasoning can be falsified against embedded models.
Where Pith is reading between the lines
- Existing sensor streams could be retrofitted into instrumented form without requiring entirely new data collection.
- The approach may reduce the volume of data needed for reliable scientific models by increasing the information density per example.
- Uncertainty propagation through the pipeline creates a natural test bed for comparing epistemic and aleatoric contributions in downstream tasks.
- Adoption would require solver interfaces that expose parameters and uncertainties in standardized, machine-readable form.
Load-bearing premise
Verification-and-validation instrumented image-to-simulation pipelines are operationally feasible and can be realized at scale for case-specific mechanistic supervision.
What would settle it
A concrete demonstration that an image-to-simulation pipeline cannot propagate uncertainty or support editable parameters at usable scale for any domain such as medical imaging would falsify the operational-feasibility claim.
Figures
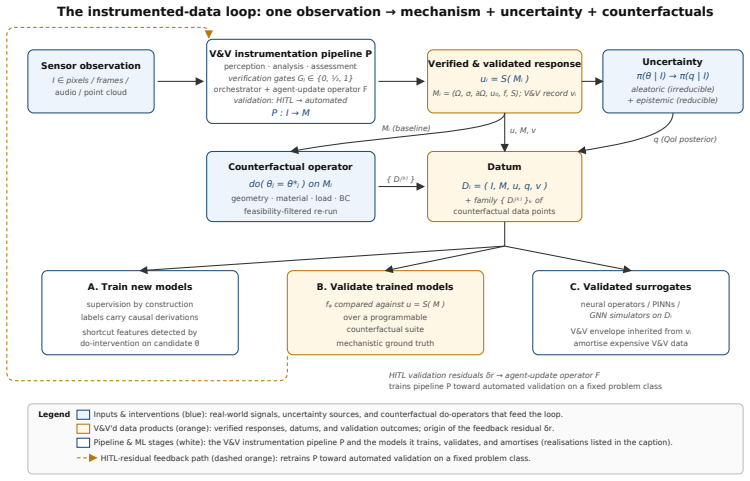
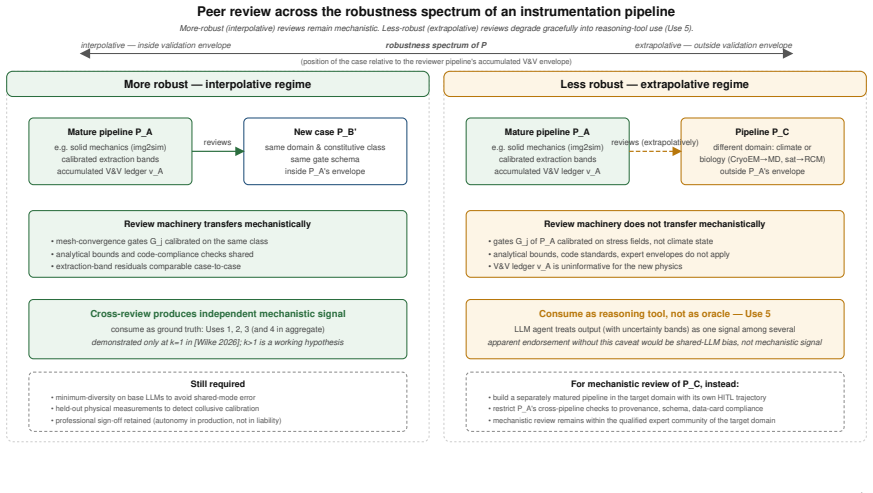
read the original abstract
Scientific machine learning is limited less by model size than by the data it is trained on. Observational data records what happened but not why; template synthetic data has a known generating process but only for the simulator's template, not the case a user faces. We argue a third option is now operationally feasible: instrumented data, in which every datum carries the mechanistic model that produced it, an explicit uncertainty over that model, and an executable family of counterfactuals. Verification-and-validation (V&V) instrumented image-to-simulation pipelines are one realisation: a sensor observation becomes a fully specified, solver-backed simulation with explicit, editable parameters and a propagated aleatoric/epistemic uncertainty. The substrate is case-specific, mechanistically supervised, and supports causal interventions through Pearl's do-operator. Near-term consequences for validation, auditing, and surrogate training span computational biology, climate, materials, fluid mechanics, and medical imaging; a longer-term, falsifiable implication concerns foundation models for scientific reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'instrumented data' as a third data paradigm for causal scientific machine learning, beyond observational data (which records outcomes without mechanisms) and template synthetic data (tied to a fixed simulator template). Each instrumented datum embeds the mechanistic model that produced it, explicit uncertainty over that model, and an executable family of counterfactuals. Verification-and-validation (V&V) instrumented image-to-simulation pipelines are presented as one realization that converts sensor observations into solver-backed simulations with editable parameters, propagated aleatoric/epistemic uncertainty, and support for Pearl's do-operator interventions. Near-term uses include validation, auditing, and surrogate training across computational biology, climate, materials, fluid mechanics, and medical imaging; a longer-term implication is foundation models for scientific reasoning.
Significance. If the feasibility claim holds, instrumented data could supply mechanistically supervised training signals that enable causal reasoning and case-specific validation at scale, addressing a core bottleneck in scientific ML. The vision of falsifiable implications for scientific foundation models is high-potential. The manuscript, however, is a position paper whose central assertion of operational feasibility rests on an unshown engineering substrate rather than any derivation, pipeline, or demonstration.
major comments (2)
- The abstract's claim that 'V&V instrumented image-to-simulation pipelines are one realisation' and are 'now operationally feasible' at scale is load-bearing for the entire argument yet supplies no workflow, solver integration example, uncertainty propagation derivation, runtime/memory scaling data, or domain-specific instance (e.g., biology or fluids).
- No concrete mechanism is given for how the 'executable family of counterfactuals' would be realized while preserving editability and propagating both aleatoric and epistemic uncertainty through the image-to-simulation step.
minor comments (1)
- The abstract would be strengthened by a brief comparison to related concepts such as digital twins or physics-informed surrogates to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the potential of instrumented data. The manuscript is a position paper whose goal is to articulate a new data paradigm rather than to deliver an engineering implementation or scaling study. We address the two major comments below and will revise the text to better distinguish conceptual claims from the supporting substrate drawn from existing V&V practice.
read point-by-point responses
-
Referee: The abstract's claim that 'V&V instrumented image-to-simulation pipelines are one realisation' and are 'now operationally feasible' at scale is load-bearing for the entire argument yet supplies no workflow, solver integration example, uncertainty propagation derivation, runtime/memory scaling data, or domain-specific instance (e.g., biology or fluids).
Authors: We agree that the manuscript supplies none of the requested technical artifacts. As a position paper the central claim is that the required substrate (case-specific V&V pipelines that already embed solvers, uncertainty quantification, and editable parameters) exists in multiple scientific domains and can be repurposed for causal training. We will revise the abstract and introduction to cite representative published pipelines in medical imaging, computational fluid dynamics, and materials science that already perform image-to-simulation with propagated uncertainty, thereby grounding the feasibility statement without adding new derivations or benchmarks. revision: yes
-
Referee: No concrete mechanism is given for how the 'executable family of counterfactuals' would be realized while preserving editability and propagating both aleatoric and epistemic uncertainty through the image-to-simulation step.
Authors: The manuscript does not supply a concrete mechanism or derivation. The intended realization is the standard practice, already routine in V&V, of exposing solver parameters as editable inputs and applying established uncertainty-quantification techniques (Monte-Carlo sampling for aleatoric, Bayesian or ensemble methods for epistemic) to the resulting simulation ensemble. We will add a short clarifying paragraph that points to this existing practice rather than claiming a novel algorithmic contribution. revision: yes
Circularity Check
No circularity: conceptual position paper with no derivations or fitted quantities
full rationale
The manuscript is a conceptual proposal advocating instrumented data and V&V pipelines. It contains no equations, no parameter fitting, no derivation chain, and no self-citations used to justify core claims. The feasibility assertion is stated as a premise rather than derived from any prior result by the same authors. All load-bearing steps are therefore external to any self-referential construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
instrumented data
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirnsberger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu, A. Merose, S. Hoyer, G. Holland, O. Vinyals, J. Stott, A. Pritzel, S. Mohamed, and P. Battaglia. Learning skillful medium-range global weather forecasting.Science, 382(6677):1416–1421, 2023. doi.org/10.1126/science.adi2336
-
[2]
K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian. Accurate medium-range global weather forecasting with 3D neural networks.Nature, 619(7970):533–538, 2023.doi.org/10.1038/s41586-023-06185-3
-
[3]
A. Merchant, S. Batzner, S.S. Schoenholz, M. Aykol, G. Cheon, and E.D. Cubuk. Scaling deep learning for materials discovery.Nature, 624:80–85, 2023.doi.org/10.1038/s41586-023-06735-9
-
[4]
Cheetham and R
A.K. Cheetham and R. Seshadri. Artificial intelligence driving materials discovery? Perspective on the article: scaling deep learning for materials discovery.Chemistry of Materials, 36(8):3490–3495, 2024.doi.org/10. 1021/acs.chemmater.4c00643
2024
-
[5]
Highly Accurate Protein Structure Prediction with
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenko, et al. Highly accurate protein structure prediction with AlphaFold.Nature, 596(7873):583–589, 2021.doi.org/10.1038/s41586-021-03819-2
-
[6]
T. Pfaff, M. Fortunato, A. Sanchez-Gonzalez, and P.W. Battaglia. Learning mesh-based simulation with graph networks (MeshGraphNets). InInternational Conference on Learning Representations (ICLR), 2021. doi.org/10.48550/arXiv.2010.03409
-
[7]
S.A. Niederer, J. Lumens, and N.A. Trayanova. Computational models in cardiology.Nature Reviews Cardiology, 16:100–111, 2019.doi.org/10.1038/s41569-018-0104-y
-
[8]
Geirhos, J.-H
R. Geirhos, J.-H. Jacobsen, C. Michaelis, R. Zemel, W. Brendel, M. Bethge, and F.A. Wichmann. Short- cut learning in deep neural networks.Nature Machine Intelligence, 2:665–673, 2020.doi.org/10.1038/ s42256-020-00257-z
2020
-
[9]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L.A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, J.W. Rae, O. Vinyals, and L. Sifre. Training compute-optimal large language models. In Advances in Neural Informati...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.15556 2022
-
[10]
Everyone wants to do the model work, not the data work
N. Sambasivan, S. Kapania, H. Highfill, D. Akrong, P. Paritosh, and L.M. Aroyo. “Everyone wants to do the model work, not the data work”: Data cascades in high-stakes AI. InProc. ACM CHI Conference on Human Factors in Computing Systems, article no. 39, p. 1–15, 2021.doi.org/10.1145/3411764.3445518. 9
-
[11]
S.Y. Gadre, G. Ilharco, A. Fang, J. Hayase, G. Smyrnis, T. Nguyen, R. Marten, M. Wortsman, D. Ghosh, J. Zhang, E. Orgad, R. Entezari, G. Daras, S. Pratt, V. Ramanujan, Y. Bitton, K. Marathe, S. Mussmann, R. Vencu, M. Cherti, R. Krishna, P.W. Koh, O. Saukh, A. Ratner, S. Song, H. Hajishirzi, A. Farhadi, R. Beaumont, S. Oh, A. Dimakis, J. Jitsev, Y. Carmon,...
-
[12]
B. Schölkopf, F. Locatello, S. Bauer, N.R. Ke, N. Kalchbrenner, A. Goyal, and Y. Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021. doi.org/10.1109/JPROC.2021. 3058954
-
[13]
W.L. Oberkampf and C.J. Roy.Verification and Validation in Scientific Computing. Cambridge University Press, Cambridge, 2010. ISBN 978-0-521-11360-1.doi.org/10.1017/CBO9780511760396
-
[14]
ASME, New York, 2020 (reaffirmed 2025)
American Society of Mechanical Engineers.ASME V&V 10-2019 (R2025): Guide for Verification and Validation in Computational Solid Mechanics. ASME, New York, 2020 (reaffirmed 2025). asme.org/ codes-standards/v-v-10
2019
-
[15]
D. Ha and J. Schmidhuber. World models. InAdvances in Neural Information Processing Systems (NeurIPS), 2018.doi.org/10.48550/arXiv.1803.10122
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1803.10122 2018
-
[16]
Y. LeCun. A path towards autonomous machine intelligence. Open Review preprint, version 0.9, 2022. openreview.net/forum?id=BZ5a1r-kVsf
2022
-
[17]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprintarXiv:2301.04104, 2023.doi.org/10.48550/arXiv.2301.04104
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2301.04104 2023
-
[18]
D.N. Wilke. From Perception to Autonomous Computational Modeling: A Multi-Agent Approach.arXiv preprintarXiv:2604.06788, 2026.arxiv.org/abs/2604.06788
Pith/arXiv arXiv 2026
-
[19]
Pearl.Causality: Models, Reasoning, and Inference
J. Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, Cambridge, 2nd edition,
-
[20]
ISBN 978-0-521-89560-6.doi.org/10.1017/CBO9780511803161
-
[21]
L.A. Zadeh. Fuzzy sets.Information and Control, 8(3):338–353, 1965.doi.org/10.1016/S0019-9958(65) 90241-X
-
[22]
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anandkumar. Fourier neural operator for parametric partial differential equations. InInternational Conference on Learning Representations (ICLR), 2021.doi.org/10.48550/arXiv.2010.08895
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.08895 2021
-
[23]
Kovachki, Z
N. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A.M. Stuart, and A. Anandkumar. Neural operator: Learning maps between function spaces with applications to PDEs.Journal of Machine Learning Research, 24(89):1–97, 2023.jmlr.org/papers/v24/21-1524.html
2023
-
[24]
M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational Physics, 378:686–707, 2019.doi.org/10.1016/j.jcp.2018.10.045
-
[25]
Sanchez-Gonzalez, J
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, and P.W. Battaglia. Learning to simulate complex physics with graph networks. InProceedings of the 37th International Conference on Machine Learning (ICML), volume 119 ofPMLR, pages 8459–8468, 2020.proceedings.mlr.press/v119/sanchez-gonzalez20a. html
2020
-
[26]
Z. Jin, Y. Chen, F. Leeb, L. Gresele, O. Kamal, Z. Lyu, K. Blin, F. Gonzalez Adauto, M. Kleiman-Weiner, M. Sachan, and B. Schölkopf. CLadder: Assessing causal reasoning in language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023.doi.org/10.48550/arXiv.2312.04350
-
[27]
D. Kaushik, E. Hovy, and Z.C. Lipton. Learning the difference that makes a difference with counterfactually- augmented data. InInternational Conference on Learning Representations (ICLR), 2020.doi.org/10.48550/ arXiv.1909.12434
arXiv 2020
-
[28]
V. Vovk, A. Gammerman, and G. Shafer.Algorithmic Learning in a Random World. Springer, New York,
-
[29]
ISBN 978-0-387-00152-4.doi.org/10.1007/b106715
-
[30]
A.N. Angelopoulos and S. Bates. Conformal prediction: A gentle introduction.Foundations and Trends in Machine Learning, 16(4):494–591, 2023.doi.org/10.1561/2200000101
-
[31]
T. Gebru, J. Morgenstern, B. Vecchione, J.W. Vaughan, H. Wallach, H. Daumé III, and K. Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021.doi.org/10.1145/3458723. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.