C3VD-DEFCOL: A Deformable Colonoscopy Dataset with Time-Resolved 3D Ground Truth and Realistic Appearance
Pith reviewed 2026-06-27 21:50 UTC · model grok-4.3
The pith
C3VD-DEFCOL supplies 110 colonoscopy videos with realistic appearance and time-resolved 3D ground truth across controlled deformation levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
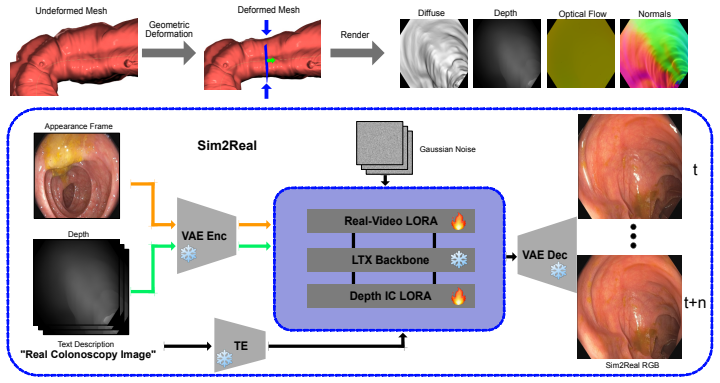
The paper presents C3VD-DEFCOL as a dataset of 110 videos from 11 unique colon mesh geometries that includes varying camera trajectories, appearances, and parameterized deformation regimes. It supplies per-frame depth, surface normals, optical flow, camera poses, and time-stamped 3D meshes generated through controlled surface and centerline deformations followed by translation to in vivo-like mucosal color, texture, vasculature, and specular highlights. The paired ground truth enables direct measurement of how pose estimation error increases with peristaltic severity, providing evaluation axes unavailable in existing in vivo data.
What carries the argument
Parameterized deformation of colon meshes combined with depth-conditioned translation to realistic RGB that preserves underlying scene structure for valid ground truth.
If this is right
- Pose estimation methods can be tested for robustness across three explicit levels of peristaltic deformation.
- The dataset supplies controlled axes for measuring how non-rigid motion affects accuracy of downstream tasks such as coverage estimation.
- Time-stamped meshes and optical flow allow direct quantitative comparison of reconstruction algorithms on identical deformation sequences.
- The generation pipeline supports creation of additional videos with new trajectories or appearance variations while retaining geometric labels.
- Researchers obtain a reproducible testbed that reduces reliance on real patient data for initial algorithm validation.
Where Pith is reading between the lines
- The controlled severity axis could reveal specific failure modes in current reconstruction pipelines that remain hidden when tested only on real data.
- The same deformation-plus-translation approach might extend to other soft-tissue endoscopic procedures to create comparable ground-truth resources.
- If geometric fidelity holds under the translation, the dataset could serve as training material for models that must handle both appearance variation and deformation.
- Future algorithms evaluated on this data may need explicit deformation modeling to avoid the observed error growth with severity.
Load-bearing premise
The translation step produces realistic video while keeping the rendered depth and meshes accurate enough to serve as valid 3D ground truth.
What would settle it
A measurement showing that 3D reconstructions computed from the generated RGB videos deviate substantially from the supplied ground-truth meshes and depth would indicate the translation altered the scene structure.
Figures

read the original abstract
3D reconstruction could improve colonoscopy by estimating mucosal coverage and alerting clinicians to missed regions during screening. However, algorithm development is limited as no current datasets provide both a realistic in vivo appearance and dense, time-resolved 3D ground truth, especially under non-rigid deformation. We present C3VD-DEFCOL, a framework and dataset for evaluating deformable colonoscopy reconstruction with paired geometry and realistic texture. Starting from C3VD/C3VDv2 colon meshes and camera trajectories, we generate controlled deformations of the colon surface, including peristaltic waves and centerline motion, and render per-frame depth, surface normals, optical flow, camera poses, and time-stamped 3D meshes. We then use the rendered geometry, primarily depth, to condition an LTX-2.3-based sim-to-real translation model that produces RGB clips with in vivo-like mucosal color, texture, vasculature, and specular appearance while preserving the underlying 3D scene structure. The resulting dataset contains 110 videos from 11 unique colon mesh geometries, with varying camera trajectories, appearances, and parameterized deformation regimes, including three peristaltic severity levels that serve as controlled evaluation axes. We evaluate the generated videos using appearance realism, geometric consistency, and temporal consistency metrics, and use the paired ground truth to benchmark the downstream task of pose estimation in deformable 3D reconstruction. Our experiments show how pose estimation error increases with increasing deformation severity, providing a controlled stress test that is not possible with existing in vivo datasets. Overall, C3VD-DEFCOL is designed as a reproducible, quantitative evaluation platform for testing deformable 3D reconstruction algorithms, with the goal of reducing the domain gap between synthetic datasets and in vivo colonoscopy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
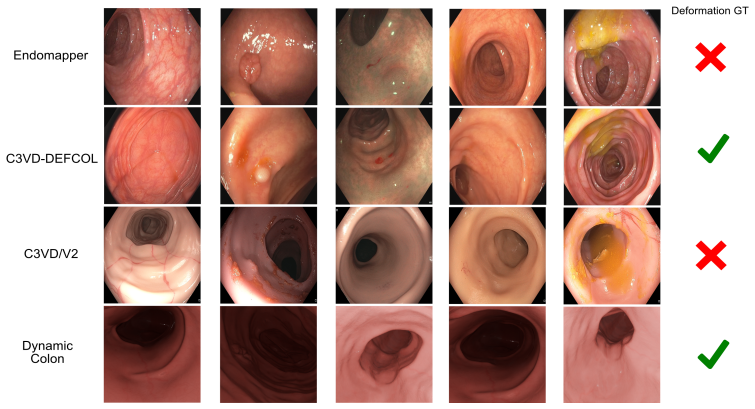
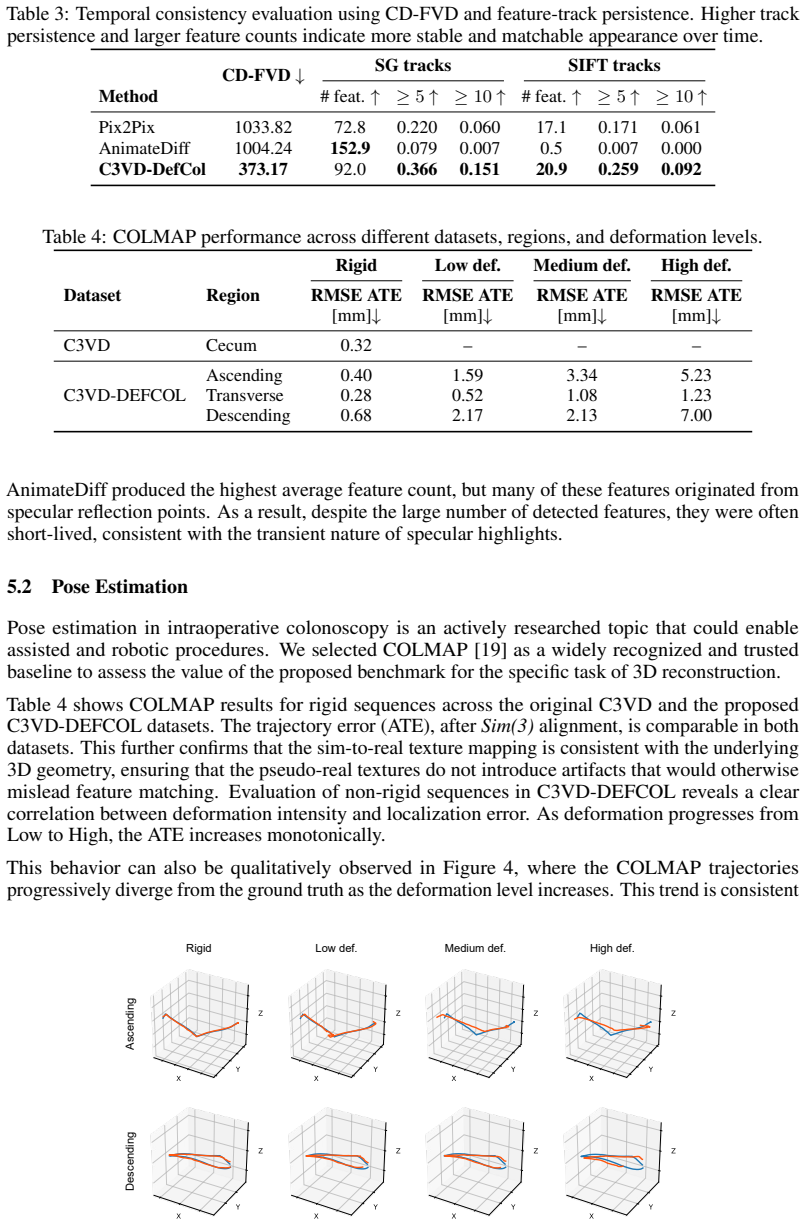
Summary. The paper presents C3VD-DEFCOL, a dataset and framework for evaluating deformable 3D colonoscopy reconstruction. Starting from C3VD/C3VDv2 colon meshes and trajectories, it generates controlled surface deformations (peristaltic waves at three severity levels plus centerline motion), renders per-frame depth, normals, optical flow, poses and time-stamped meshes, then applies a depth-conditioned LTX-2.3 sim-to-real model to produce 110 RGB videos with in-vivo-like appearance. The paired geometry is used to benchmark pose estimation, with the central experimental claim that error increases with deformation severity, supplying a controlled stress test unavailable in existing in-vivo datasets.
Significance. If the geometric-preservation claim holds, the work supplies a reproducible quantitative platform with time-resolved 3D ground truth under explicitly parameterized deformation regimes; the three peristaltic severity levels constitute a controlled evaluation axis that directly addresses the domain gap between synthetic and in-vivo colonoscopy data. The manuscript explicitly positions the release as a benchmark resource rather than a one-off collection.
major comments (1)
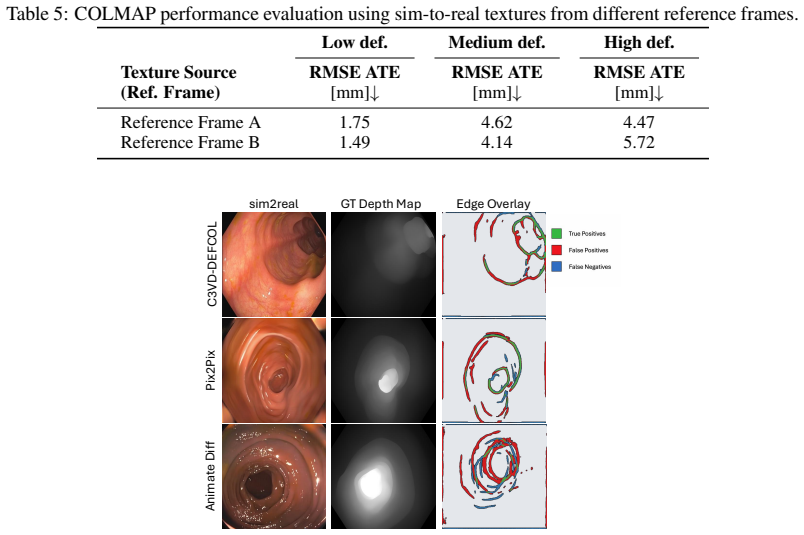
- [Abstract] Abstract: the claim that 'geometric consistency metrics' were computed to verify that the LTX-2.3 translation 'preserves the underlying 3D scene structure' is load-bearing for every downstream use of the rendered meshes and depth maps as ground truth. No metric definitions, quantitative thresholds, error bars, or ablation (e.g., depth re-estimation error from translated RGB) are supplied, leaving the central assumption that viewpoint-dependent appearance changes do not alter implied geometry untested.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'geometric consistency metrics' were computed to verify that the LTX-2.3 translation 'preserves the underlying 3D scene structure' is load-bearing for every downstream use of the rendered meshes and depth maps as ground truth. No metric definitions, quantitative thresholds, error bars, or ablation (e.g., depth re-estimation error from translated RGB) are supplied, leaving the central assumption that viewpoint-dependent appearance changes do not alter implied geometry untested.
Authors: We agree that the abstract's reference to geometric consistency metrics requires explicit support to substantiate the claim that the sim-to-real translation preserves 3D structure. The manuscript states that such metrics were computed as part of the evaluation, but we acknowledge that definitions, numerical results with error bars, thresholds, and an ablation (e.g., re-projecting depth from the translated RGB) are not detailed in the current version. In the revision we will add these elements, including precise metric definitions (depth L1 error and surface normal angular deviation between original rendered geometry and geometry recovered from translated RGB), reported values with standard deviations across the 110 sequences, and the requested ablation study. revision: yes
Circularity Check
No circularity; dataset generation with external components
full rationale
The work is a dataset construction pipeline starting from prior C3VD meshes, applying parameterized deformations, rendering geometry outputs, and conditioning an external LTX-2.3 translation model. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via citation appear in the provided text. Evaluations use separate realism/consistency metrics on outputs, but these do not reduce the core claims to the inputs by construction. This is the expected non-finding for a reproducible dataset paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- peristaltic severity levels
axioms (1)
- domain assumption The LTX-2.3-based sim-to-real translation preserves the underlying 3D geometry when generating realistic RGB appearance
Reference graph
Works this paper leans on
-
[1]
Cancer statistics, 2025.CA: A Cancer Journal for Clinicians, 75(1):10, 2025
Rebecca L Siegel, Tyler B Kratzer, Angela N Giaquinto, Hyuna Sung, and Ahmedin Jemal. Cancer statistics, 2025.CA: A Cancer Journal for Clinicians, 75(1):10, 2025
2025
-
[2]
Magnitude, risk factors, and factors associated with adenoma miss rate of tandem colonoscopy: a systematic review and meta-analysis.Gastroenterology, 156(6):1661–1674, 2019
Shengbing Zhao, Shuling Wang, Peng Pan, Tian Xia, Xin Chang, Xia Yang, Liliangzi Guo, Qianqian Meng, Fan Yang, Wei Qian, et al. Magnitude, risk factors, and factors associated with adenoma miss rate of tandem colonoscopy: a systematic review and meta-analysis.Gastroenterology, 156(6):1661–1674, 2019
2019
-
[3]
Artificial intelligence identifies and quantifies colonoscopy blind spots.Endoscopy, 53(12):1284–1286, 2021
Sarah K McGill, Julian Rosenman, Rui Wang, Ruibin Ma, Jan-Michael Frahm, and Stephen Pizer. Artificial intelligence identifies and quantifies colonoscopy blind spots.Endoscopy, 53(12):1284–1286, 2021
2021
-
[4]
RNNSLAM: Reconstructing the 3D colon to visualize missing regions during a colonoscopy
Ruibin Ma, Rui Wang, Yubo Zhang, Stephen Pizer, Sarah K McGill, Julian Rosenman, and Jan-Michael Frahm. RNNSLAM: Reconstructing the 3D colon to visualize missing regions during a colonoscopy. Medical image analysis, 72:102100, 2021
2021
-
[5]
Improving colonoscopy lesion classification using semi-supervised deep learning.IEEE Access, 9:631–640, 2020
Mayank Golhar, Taylor L Bobrow, Mirmilad Pourmousavi Khoshknab, Simran Jit, Saowanee Ngamru- engphong, and Nicholas J Durr. Improving colonoscopy lesion classification using semi-supervised deep learning.IEEE Access, 9:631–640, 2020
2020
-
[6]
Gan inversion for data augmentation to improve colonoscopy lesion classification.IEEE Journal of Biomedical and Health Informatics, 2024
Mayank V Golhar, Taylor L Bobrow, Saowanee Ngamruengphong, and Nicholas J Durr. Gan inversion for data augmentation to improve colonoscopy lesion classification.IEEE Journal of Biomedical and Health Informatics, 2024
2024
-
[7]
A robust method for blood vessel extraction in endoscopic images with svm-based scene classification
Mayank Golhar, Yuji Iwahori, Manas Kamal Bhuyan, Kenji Funahashi, and Kunio Kasugai. A robust method for blood vessel extraction in endoscopic images with svm-based scene classification. InICPRAM, pages 148–156, 2017
2017
-
[8]
Blood vessel delineation in endoscopic images with deep learning based scene classification
Mayank Golhar, Yuji Iwahori, Manas Kamal Bhuyan, Kenji Funahashi, and Kunio Kasugai. Blood vessel delineation in endoscopic images with deep learning based scene classification. InPattern Recognition Applications and Methods: 6th International Conference, ICPRAM 2017, Porto, Portugal, February 24–26, 2017, Revised Selected Papers 6, pages 147–168. Springer, 2018
2017
-
[9]
A deep learning framework for quality assessment and restoration in video endoscopy.Medical image analysis, 68:101900, 2021
Sharib Ali, Felix Zhou, Adam Bailey, Barbara Braden, James E East, Xin Lu, and Jens Rittscher. A deep learning framework for quality assessment and restoration in video endoscopy.Medical image analysis, 68:101900, 2021
2021
-
[10]
Endomapper dataset of complete calibrated endoscopy procedures.Scientific Data, 10(1):671, 2023
Pablo Azagra, Carlos Sostres, Ángel Ferrández, Luis Riazuelo, Clara Tomasini, O León Barbed, Javier Morlana, David Recasens, Víctor M Batlle, Juan J Gómez-Rodríguez, et al. Endomapper dataset of complete calibrated endoscopy procedures.Scientific Data, 10(1):671, 2023
2023
-
[11]
Simcol3d—3d reconstruction during colonoscopy challenge.Medical Image Analysis, 96:103195, 2024
Anita Rau, Sophia Bano, Yueming Jin, Pablo Azagra, Javier Morlana, Rawen Kader, Edward Sanderson, Bogdan J Matuszewski, Jae Young Lee, Dong-Jae Lee, et al. Simcol3d—3d reconstruction during colonoscopy challenge.Medical Image Analysis, 96:103195, 2024
2024
-
[12]
Simintestine: A synthetic dataset from virtual capsule endoscope.Medical Image Analysis, 105:103706, 2025
Sarita Singh, Basabi Bhaumik, and Shouri Chatterjee. Simintestine: A synthetic dataset from virtual capsule endoscope.Medical Image Analysis, 105:103706, 2025
2025
-
[13]
Weronika Smolak-Dy˙zewska, Joanna Kaleta, Diego Dall’Alba, and Przemysław Spurek. ColonSplat: Reconstruction of peristaltic motion in colonoscopy with dynamic gaussian splatting.arXiv preprint arXiv:2603.06860, 2026
-
[14]
Colonoscopy 3d video dataset with paired depth from 2d-3d registration.Medical image analysis, 90:102956, 2023
Taylor L Bobrow, Mayank Golhar, Rohan Vijayan, Venkata S Akshintala, Juan R Garcia, and Nicholas J Durr. Colonoscopy 3d video dataset with paired depth from 2d-3d registration.Medical image analysis, 90:102956, 2023. 10
2023
-
[15]
C3VDv2–colonoscopy 3D video dataset with enhanced realism.arXiv preprint arXiv:2506.24074, 2025
Mayank V Golhar, Lucas Sebastian Galeano Fretes, Loren Ayers, Venkata S Akshintala, Taylor L Bobrow, and Nicholas J Durr. C3VDv2–colonoscopy 3D video dataset with enhanced realism.arXiv preprint arXiv:2506.24074, 2025
-
[16]
NR-SLAM: Non-rigid monocular SLAM
Juan J Gomez Rodriguez, José MM Montiel, and Juan D Tardós. NR-SLAM: Non-rigid monocular SLAM. IEEE Transactions on Robotics, 40:4252–4264, 2024
2024
-
[17]
Bobrow, Gulfize Coskun, Kagan Incetan, Yasin Almalioglu, Faisal Mahmood, Eva Curto, Luis Perdigoto, Marina Oliveira, Hasan Sahin, Helder Araujo, Henrique Alexandrino, Nicholas J
Kutsev Bengisu Ozyoruk, Guliz Irem Gokceler, Taylor L. Bobrow, Gulfize Coskun, Kagan Incetan, Yasin Almalioglu, Faisal Mahmood, Eva Curto, Luis Perdigoto, Marina Oliveira, Hasan Sahin, Helder Araujo, Henrique Alexandrino, Nicholas J. Durr, Hunter B. Gilbert, and Mehmet Turan. EndoSLAM dataset and an unsupervised monocular visual odometry and depth estimat...
2021
-
[18]
Vr-caps: a virtual environment for capsule endoscopy.Medical image analysis, 70:101990, 2021
Ka˘gan ˙Incetan, Ibrahim Omer Celik, Abdulhamid Obeid, Guliz Irem Gokceler, Kutsev Bengisu Ozyoruk, Yasin Almalioglu, Richard J Chen, Faisal Mahmood, Hunter Gilbert, Nicholas J Durr, et al. Vr-caps: a virtual environment for capsule endoscopy.Medical image analysis, 70:101990, 2021
2021
-
[19]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[20]
SAGE: SLAM with appearance and geometry prior for endoscopy
Xingtong Liu, Zhaoshuo Li, Masaru Ishii, Gregory D Hager, Russell H Taylor, and Mathias Unberath. SAGE: SLAM with appearance and geometry prior for endoscopy. In2022 International conference on robotics and automation (ICRA), pages 5587–5593. IEEE, 2022
2022
-
[21]
The drunkard’s odometry: Estimating camera motion in deforming scenes.Advances in Neural Information Processing Systems, 36, 2024
David Recasens Lafuente, Martin R Oswald, Marc Pollefeys, and Javier Civera. The drunkard’s odometry: Estimating camera motion in deforming scenes.Advances in Neural Information Processing Systems, 36, 2024
2024
-
[22]
Gaussian pancakes: Geometrically-regularized 3D gaussian splatting for realistic endoscopic reconstruction
Sierra Bonilla, Shuai Zhang, Dimitrios Psychogyios, Danail Stoyanov, Francisco Vasconcelos, and Sophia Bano. Gaussian pancakes: Geometrically-regularized 3D gaussian splatting for realistic endoscopic reconstruction. InInt. Conf. on Medical Image Computing and Computer-Assisted Intervention (MICCAI), pages 274–283. Springer Nature, 2024
2024
-
[23]
EndoGSLAM: Real-time dense reconstruction and tracking in endoscopic surgeries using gaussian splatting
Kailing Wang, Chen Yang, Yuehao Wang, Sikuang Li, Yan Wang, Qi Dou, Xiaokang Yang, and Wei Shen. EndoGSLAM: Real-time dense reconstruction and tracking in endoscopic surgeries using gaussian splatting. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 219–229. Springer, 2024
2024
-
[24]
ENeRF-SLAM: A dense endoscopic SLAM with neural implicit representation.IEEE Transactions on Medical Robotics and Bionics, 6(3):1030–1041, 2024
Jiwei Shan, Yirui Li, Ting Xie, and Hesheng Wang. ENeRF-SLAM: A dense endoscopic SLAM with neural implicit representation.IEEE Transactions on Medical Robotics and Bionics, 6(3):1030–1041, 2024
2024
-
[25]
SD- DefSLAM: Semi-direct monocular slam for deformable and intracorporeal scenes
Juan J Gómez-Rodríguez, José Lamarca, Javier Morlana, Juan D Tardós, and José MM Montiel. SD- DefSLAM: Semi-direct monocular slam for deformable and intracorporeal scenes. In2021 IEEE interna- tional conference on robotics and automation (ICRA), pages 5170–5177. IEEE, 2021
2021
-
[26]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
In-context LoRA for diffusion transformers
Lianghua Huang, Wei Wang, Zhi-Fan Wu, Yupeng Shi, Huanzhang Dou, Chen Liang, Yutong Feng, Yu Liu, and Jingren Zhou. In-context lora for diffusion transformers.arXiv preprint arXiv:2410.23775, 2024
-
[29]
Coloncrafter: A depth estimation model for colonoscopy videos using diffusion priors
Romain Hardy, Tyler M Berzin, and Pranav Rajpurkar. Coloncrafter: A depth estimation model for colonoscopy videos using diffusion priors. InBiocomputing 2026: Proceedings of the Pacific Symposium, pages 27–41. World Scientific, 2025
2026
-
[30]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017
2017
-
[31]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
High-resolution image synthesis with latent diffusion models [internet].arXiv [cs
R Rombach. High-resolution image synthesis with latent diffusion models [internet].arXiv [cs. CV]., 2021
2021
-
[33]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[34]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[35]
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans. arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Soria, E
X. Soria, E. Riba, and A. Sappa. Dense extreme inception network: Towards a robust cnn model for edge detection. In2020 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1912–1921, Los Alamitos, CA, USA, mar 2020. IEEE Computer Society
1912
-
[38]
HalF-SAM: SAM-based haustral fold detection in colonoscopy with debris suppression and temporal consistency
Mayank Golhar, Luojie Huang, and Nicholas J Durr. HalF-SAM: SAM-based haustral fold detection in colonoscopy with debris suppression and temporal consistency. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 300–309. Springer, 2025
2025
-
[39]
On the content bias in fréchet video distance
Songwei Ge, Aniruddha Mahapatra, Gaurav Parmar, Jun-Yan Zhu, and Jia-Bin Huang. On the content bias in fréchet video distance. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7277–7288, 2024
2024
-
[40]
Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
David G Lowe. Distinctive image features from scale-invariant keypoints.International journal of computer vision, 60(2):91–110, 2004
2004
-
[41]
Superglue: Learning feature matching with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4938–4947, 2020. 12
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.