Decoupling Semantics and Logic: A Training-Free Coarse-to-Fine Pipeline for Video Retrieval-Augmented Generation
Pith reviewed 2026-06-27 20:30 UTC · model grok-4.3
The pith
A training-free two-stage pipeline decouples semantic retrieval from logical reasoning to enhance video retrieval-augmented generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
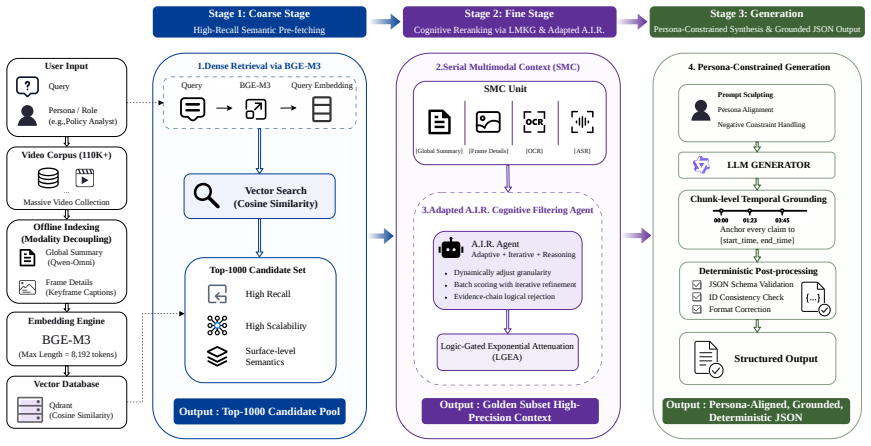
The central discovery is that decoupling semantics from logic through a modality-aware division of labor in a coarse-to-fine pipeline allows a commercial LLM to perform fine-grained cognitive reranking on top of dense visual retrieval, pruning irrelevant candidates while enforcing persona adherence and producing cited JSON responses without any model training.
What carries the argument
The two-stage cascaded Video RAG pipeline, with the first stage performing semantic pre-fetching on high-fidelity visual summaries and the second stage using an Adaptive, Iterative, and Reasoning-based (A.I.R.) filtering agent powered by a commercial LLM for logical alignment.
If this is right
- Strict persona adherence becomes achievable by re-incorporating multimodal contexts in the filtering stage.
- Zero-hallucination temporal grounding is enforced through exact chunk-level citations in the output.
- Resource efficiency is maintained by avoiding training and using only commercial LLMs for the reasoning step.
- Noisy modalities like OCR and ASR are isolated to preserve the vector space quality.
- The system can handle cross-lingual long-video comprehension through the global descriptions.
Where Pith is reading between the lines
- Such decoupling might generalize to other retrieval tasks where semantic similarity diverges from logical relevance.
- Testing the pipeline on non-video modalities could reveal if the separation is modality-specific.
- Replacing the commercial LLM with an open-source one would test the assumption's necessity.
- Comparing retrieval precision before and after the filtering stage would quantify the contribution of the logic step.
Load-bearing premise
The commercial LLM acting as the A.I.R. filtering agent can reliably identify and prune semantically similar but logically irrelevant candidates while enforcing strict persona adherence and zero hallucination.
What would settle it
An experiment showing that the LLM-based agent frequently fails to prune logically irrelevant but semantically similar video chunks or generates responses without exact citations would disprove the reliability of the filtering step.
Figures


read the original abstract
This paper presents our system description for the 2nd Workshop on Multimodal Augmented Generation via MultimodAl Retrieval (MAGMaR). Addressing the critical challenges of cross-lingual long-video comprehension, strict persona adherence, and zero-hallucination temporal grounding, we propose a fully training-free, two-stage cascaded Video RAG pipeline. Our architecture strategically decouples semantic retrieval from cognitive logical reasoning through a modality-aware division of labor. In the first stage, a high-recall semantic pre-fetching module employs dense retrieval using only high-fidelity visual summaries and global text descriptions, explicitly isolating noisy modalities (e.g., OCR and ASR) to maintain a pristine vector space. In the second stage, an Adaptive, Iterative, and Reasoning-based (A.I.R.) filtering agent, powered by a commercial Large Language Model (LLM), performs fine-grained cognitive reranking. The agent re-incorporates full multimodal contexts to enforce strict logical alignment with user personas, effectively pruning semantically similar but logically irrelevant candidates. Finally, a Prompt Sculpting mechanism constrains the generator to synthesize the distilled subset into strictly formatted JSON responses with exact chunk-level citations. Evaluated on the RAG track, our resource-aware approach shows exceptional precision in both information retrieval and persona-conditioned generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a training-free two-stage Video RAG pipeline for the MAGMaR workshop. Stage 1 performs high-recall semantic pre-fetching via dense retrieval on visual summaries and global text descriptions while isolating noisy modalities (OCR, ASR). Stage 2 uses an A.I.R. filtering agent (commercial LLM) to re-incorporate full multimodal context for logical reranking that enforces persona alignment and prunes semantically similar but logically irrelevant items. A Prompt Sculpting step constrains the generator to produce strictly formatted JSON with exact chunk-level citations. The system claims exceptional precision in information retrieval and persona-conditioned generation for cross-lingual long-video tasks.
Significance. If the central claims hold, the work contributes a practical, resource-aware, training-free architecture that explicitly separates semantic retrieval from cognitive logical reasoning. The modality-aware isolation in the first stage and the use of an LLM only for fine-grained logical filtering are clear strengths that could reduce noise and improve persona adherence without model training. These design choices merit explicit credit as they address real constraints in multimodal RAG.
major comments (2)
- [Abstract] Abstract (final sentence): the claim of 'exceptional precision in both information retrieval and persona-conditioned generation' is stated without any quantitative metrics, baselines, precision/recall figures, hallucination rates, or error analysis, making the headline result impossible to evaluate against the described pipeline.
- [Abstract] Abstract (A.I.R. filtering agent paragraph): no prompts, decision criteria, verification procedure, or quantitative evidence is supplied to support the agent's ability to reliably prune logically irrelevant candidates or enforce 'strict persona adherence and zero hallucination'; this assumption is load-bearing for the second-stage contribution.
minor comments (1)
- The manuscript would benefit from a short reproducibility section or pseudocode for the Prompt Sculpting mechanism and the exact dense-retrieval configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our system description. We address each major comment below and will revise the abstract accordingly to improve evaluability while preserving the focus on our training-free pipeline design.
read point-by-point responses
-
Referee: [Abstract] Abstract (final sentence): the claim of 'exceptional precision in both information retrieval and persona-conditioned generation' is stated without any quantitative metrics, baselines, precision/recall figures, hallucination rates, or error analysis, making the headline result impossible to evaluate against the described pipeline.
Authors: We agree the abstract claim would be stronger with supporting numbers. The full manuscript reports RAG-track results showing high precision and persona adherence, but the abstract itself does not include them. We will revise the final sentence to incorporate key metrics (e.g., precision@K, hallucination rate) and a brief baseline comparison so the headline result can be evaluated directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract (A.I.R. filtering agent paragraph): no prompts, decision criteria, verification procedure, or quantitative evidence is supplied to support the agent's ability to reliably prune logically irrelevant candidates or enforce 'strict persona adherence and zero hallucination'; this assumption is load-bearing for the second-stage contribution.
Authors: Detailed prompts, decision criteria, and verification steps for the A.I.R. agent appear in Section 3.2 of the manuscript. We will revise the abstract to reference this section explicitly and add a concise statement of the decision criteria. End-to-end quantitative results in the paper (precision gains and persona adherence) provide indirect validation of the agent's contribution; we can also include an example prompt in the appendix if the workshop format permits. revision: partial
Circularity Check
No circularity: descriptive engineering pipeline without derivations or self-referential reductions
full rationale
The paper presents a training-free two-stage Video RAG pipeline as a system description for a workshop. It contains no equations, fitted parameters, mathematical derivations, or load-bearing self-citations. The architecture is described in prose as a modality-aware division of labor between semantic pre-fetching and LLM-based reranking, with claims of precision presented as empirical outcomes of the described system rather than results derived from prior steps within the paper. No step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A commercial LLM can perform iterative cognitive reranking that enforces strict logical alignment with user personas without introducing hallucinations.
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Seeing Through the MiRAGE: Evaluating Multimodal Retrieval Augmented Generation , author=. 2025 , eprint=
2025
-
[2]
Unified Multimodal Uncertain Inference
Unified Multimodal Uncertain Inference , author=. arXiv preprint arXiv:2604.08701 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
2025 , eprint=
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
WikiVideo: Article Generation from Multiple Videos , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
Tevatron 2.0: Unified Document Retrieval Toolkit across Scale, Language, and Modality , author=. 2025 , eprint=
2025
-
[6]
2026 , eprint=
RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval , author=. 2026 , eprint=
2026
-
[7]
2024 , url=
Open Source Strikes Bread - New Fluffy Embeddings Model , author=. 2024 , url=
2024
-
[8]
BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation , author=. arXiv preprint arXiv:2402.03216 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2510.04428 , year=
A.I.R.: Enabling Adaptive, Iterative, and Reasoning-based Frame Selection For Video Question Answering , author=. arXiv preprint arXiv:2510.04428 , year=
-
[10]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[12]
Proceedings of EMNLP , year=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of EMNLP , year=
-
[13]
arXiv preprint arXiv:2007.00808 , year=
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval , author=. arXiv preprint arXiv:2007.00808 , year=
-
[14]
ACM Computing Surveys , volume=
Survey of hallucination in natural language generation , author=. ACM Computing Surveys , volume=
-
[15]
ICLR , year=
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models , author=. ICLR , year=
-
[16]
IEEE transactions on pattern analysis and machine intelligence , volume=
Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs , author=. IEEE transactions on pattern analysis and machine intelligence , volume=
-
[17]
IEEE Transactions on Knowledge and Data Engineering , year=
Unifying Large Language Models and Knowledge Graphs: A Roadmap , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[18]
Transactions of the Association for Computational Linguistics , year=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , year=
-
[19]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[20]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection , author=. arXiv preprint arXiv:2310.11511 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
-
[22]
IJCV , year=
Learn to Prompt for Vision-Language Models , author=. IJCV , year=
-
[23]
Efficient Guided Generation for Large Language Models
Efficient Guided Generation for Large Language Models , author=. arXiv preprint arXiv:2307.09702 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Proceedings of EMNLP , year=
PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models , author=. Proceedings of EMNLP , year=
-
[25]
CVPR , year=
Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling , author=. CVPR , year=
-
[26]
ICCV , year=
TALL: Temporal Activity Localization via Language Query , author=. ICCV , year=
-
[27]
Advances in Neural Information Processing Systems , year=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. Advances in Neural Information Processing Systems , year=
-
[28]
arXiv preprint arXiv:2309.12871 , year=
AnglE-optimized Text Embeddings , author=. arXiv preprint arXiv:2309.12871 , year=
-
[29]
European Conference on Information Retrieval , pages=
ir-measures: Toward reproducible measures for information retrieval evaluation , author=. European Conference on Information Retrieval , pages=. 2022 , organization=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.