ChronoPhyBench: Do MLLMs Truly Understand the World or Merely Exploit Language Priors?
Pith reviewed 2026-06-27 20:21 UTC · model grok-4.3
The pith
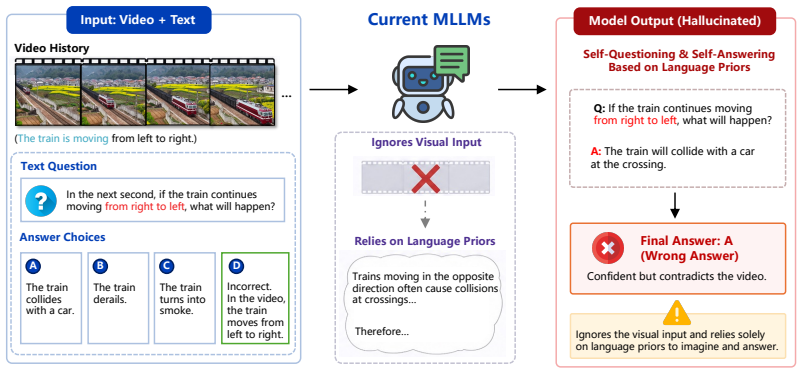
Open-source multimodal models cannot deduce physical states from video and text, relying on language patterns instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
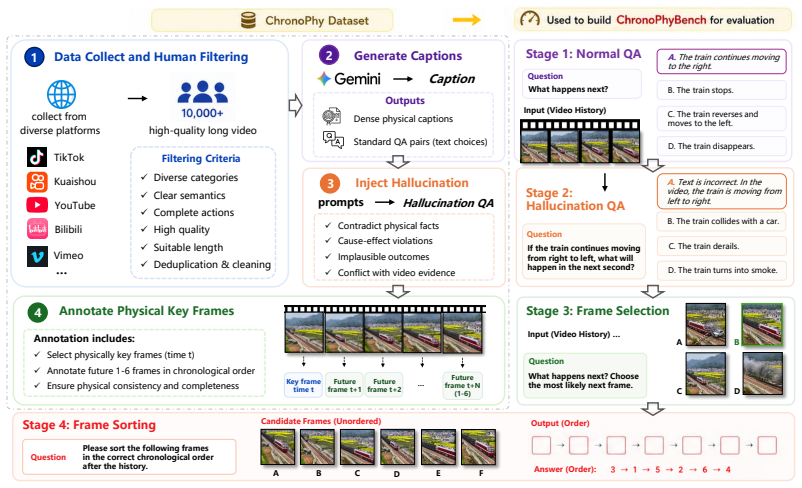
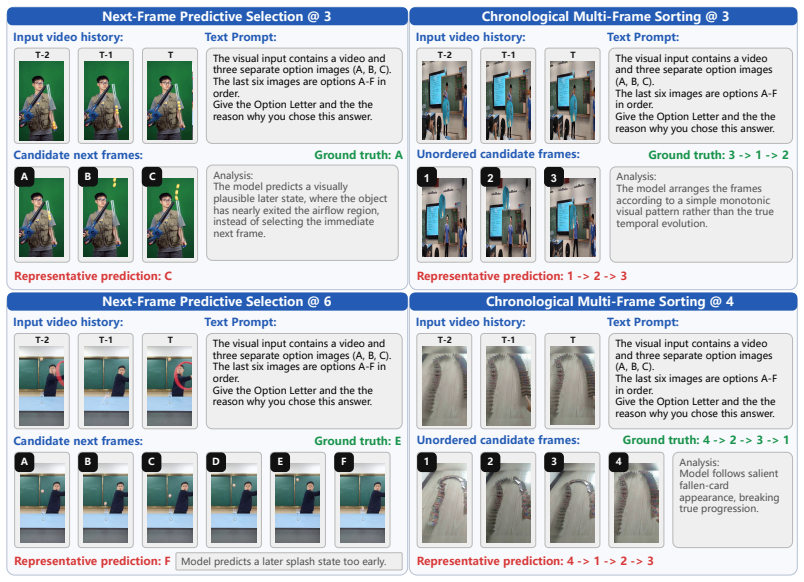
By creating tasks that require deducing subsequent physical states from historical video context and textual captions through single image selection and multiple frame chronological sorting, the benchmark reveals that the capacity of current open-source models to perform physically grounded multimodal reasoning remains in its infancy.
What carries the argument
ChronoPhyBench, which unifies next state prediction with VQA paradigms conditioned on historical video and captions to enforce physical state deduction.
Load-bearing premise
The benchmark tasks prevent solutions based solely on language priors and require actual physical state deduction from the multimodal input.
What would settle it
A model achieving high accuracy on the chronological sorting task after removal of all visual information would indicate that language priors alone suffice, undermining the benchmark's enforcement of physical reasoning.
Figures
read the original abstract
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable proficiency in open-world reasoning and understanding. However, a critical ambiguity persists: it remains unclear whether these models genuinely synthesize cross-modal information to construct physically grounded reasoning chains, or if they merely exploit strong language priors to mask single-modality reliance, thereby hallucinating advanced multimodal capabilities. Motivated by this, and to rigorously mitigate language modality bias and shortcuts, we propose a novel multimodal Chrono}logical Physical Dynamics Reasoning Benchmark ChronoPhyBench, which unifies next state prediction with Visual Question Answering (VQA) paradigms by conditioning on historical video context and textual captions to enforce models to deduce subsequent physical states through both single image selection and the inherently more complex task of multiple frame chronological sorting. Concurrently, we construct a large-scale multimodal reasoning dataset curated using the ChronoPhyBench criteria, comprising over 10,000 long-form videos paired with meticulously annotated captions, totaling 5M tokens. Our experimental evaluations reveal a stark contrast to conclusions drawn by previous benchmarks. The capacity of current open-source models to perform physically grounded multimodal reasoning remains in its infancy. Ultimately, this work seeks to systematically stress-test the reasoning capabilities of multimodal models, quantify hallucination rates, and advance the development of Physical AI, thereby providing the community with a robust and transparent evaluation framework toward Artificial General Intelligence (AGI).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ChronoPhyBench, a benchmark unifying next-state prediction with VQA paradigms. It conditions models on historical video context plus textual captions for two tasks (single-image selection and multi-frame chronological sorting) to test whether MLLMs perform physically grounded multimodal reasoning or merely exploit language priors. The authors also release a 10k-video dataset with meticulously annotated captions (5M tokens total) and conclude from their evaluations that the capacity of current open-source MLLMs for physically grounded multimodal reasoning remains in its infancy.
Significance. A benchmark that demonstrably isolates physical-state deduction from language-prior shortcuts would be a useful addition to the MLLM evaluation toolkit and could help steer development of models that integrate visual dynamics rather than textual patterns.
major comments (2)
- Abstract: the headline claim that open-source MLLMs remain 'in its infancy' for physically grounded multimodal reasoning is presented without any quantitative performance numbers, error bars, per-task breakdowns, or comparison tables, leaving the central empirical conclusion unsupported by visible evidence.
- Abstract: no ablation (caption-only models, visual-input removal, or language-predictability controls) is described to verify that the chosen physical scenarios have low language predictability and that performance gaps cannot be explained by textual shortcuts alone; this is load-bearing for the claim that the benchmark 'rigorously mitigate[s] language modality bias'.
minor comments (1)
- Abstract: the string 'Chrono}logical' contains an obvious LaTeX artifact and should be corrected to 'Chronological'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below.
read point-by-point responses
-
Referee: Abstract: the headline claim that open-source MLLMs remain 'in its infancy' for physically grounded multimodal reasoning is presented without any quantitative performance numbers, error bars, per-task breakdowns, or comparison tables, leaving the central empirical conclusion unsupported by visible evidence.
Authors: The abstract is intended as a concise summary of the paper's conclusions. The full manuscript contains the requested quantitative details, including performance numbers, error bars, per-task breakdowns, and comparison tables, in the Experiments section. We agree that incorporating a small number of key quantitative highlights into the abstract would strengthen the presentation of the central claim and will revise the abstract accordingly. revision: yes
-
Referee: Abstract: no ablation (caption-only models, visual-input removal, or language-predictability controls) is described to verify that the chosen physical scenarios have low language predictability and that performance gaps cannot be explained by textual shortcuts alone; this is load-bearing for the claim that the benchmark 'rigorously mitigate[s] language modality bias'.
Authors: The abstract states the design goal of mitigating language bias through the benchmark structure. The manuscript provides the supporting ablations (caption-only baselines, visual-input removal, and language-predictability controls) in the methodology and experimental sections. We agree that a brief reference to these controls in the abstract would make the claim more self-contained and will revise the abstract to include it. revision: yes
Circularity Check
No significant circularity; benchmark proposal is self-contained
full rationale
The paper proposes ChronoPhyBench as an empirical evaluation framework without any mathematical derivations, equations, fitted parameters, or self-citations that reduce claims to inputs by construction. The central assertion that open-source MLLMs lack physically grounded reasoning rests on reported model performance on the introduced tasks and dataset, not on any self-definitional loop or renamed prior result. Design choices such as video+caption conditioning are presented as methodological decisions rather than derived outputs that presuppose the target conclusion.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The chronological sorting and next-state selection tasks require genuine cross-modal physical reasoning and cannot be solved primarily through language priors.
Reference graph
Works this paper leans on
-
[1]
pi_0.5: a vision-language-action model with open-world generalization
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al. pi_0.5: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025. 1
2025
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026. 1
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Re-align: Aligning vision language models via retrieval-augmented direct preference optimization
Shuo Xing, Peiran Li, Yuping Wang, Ruizheng Bai, Yueqi Wang, Chan-Wei Hu, Chengxuan Qian, Huaxiu Yao, and Zhengzhong Tu. Re-align: Aligning vision language models via retrieval-augmented direct preference optimization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2379–2397, 2025. 1
2025
-
[5]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. In International Conference on Learning Representations, 2025. 1
2025
-
[7]
Weakly-supervised 3d spatial reasoning for text-based visual question answering.IEEE Transactions on Image Processing, 32:3367–3382, 2023
Hao Li, Jinfa Huang, Peng Jin, Guoli Song, Qi Wu, and Jie Chen. Weakly-supervised 3d spatial reasoning for text-based visual question answering.IEEE Transactions on Image Processing, 32:3367–3382, 2023. 2
2023
-
[8]
V-fat: Benchmarking visual fidelity against text-bias, 2026
Ziteng Wang, Yujie He, Guanliang Li, Siqi Yang, Jiaqi Xiong, and Songxiang Liu. V-fat: Benchmarking visual fidelity against text-bias, 2026. 2
2026
-
[9]
Mitigating hallucination in visual-language models via re-balancing contrastive decoding
Xiaoyu Liang, Jiayuan Yu, Lianrui Mu, Jiedong Zhuang, Jiaqi Hu, Yuchen Yang, Jiangnan Ye, Lu Lu, Jian Chen, and Haoji Hu. Mitigating hallucination in visual-language models via re-balancing contrastive decoding. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 482–496. Springer, 2024. 2
2024
-
[10]
DecAlign: Hierarchical Cross-Modal Alignment for Decoupled Multimodal Representation Learning
Chengxuan Qian, Shuo Xing, Shawn Li, Yue Zhao, and Zhengzhong Tu. Decalign: Hierarchical cross-modal alignment for decoupled multimodal representation learning.arXiv preprint arXiv:2503.11892,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Robust multimodal large language models against modality conflict
Zongmeng Zhang, Wengang Zhou, Jie Zhao, and Houqiang Li. Robust multimodal large language models against modality conflict. InForty-second International Conference on Machine Learning, 2025. 2
2025
-
[12]
Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality
Guanyu Zhou, Yibo Yan, Xin Zou, Kun Wang, Aiwei Liu, and Xuming Hu. Mitigating modality prior-induced hallucinations in multimodal large language models via deciphering attention causality. InThe Thirteenth International Conference on Learning Representations, 2025. 2
2025
-
[13]
Quantum physics intelligent question answering (q&a) system based on retrieval-augmented generation.Concurrency and Computation: Practice and Experience, 38(1):e70379, 2026
Wenchen Li, Su Lu, Hongqi Zhu, Peijun Wu, and Wuhe Zou. Quantum physics intelligent question answering (q&a) system based on retrieval-augmented generation.Concurrency and Computation: Practice and Experience, 38(1):e70379, 2026. 2
2026
-
[14]
arXiv preprint arXiv:2410.03659 , year =
Tinghui Zhu, Qin Liu, Fei Wang, Zhengzhong Tu, and Muhao Chen. Unraveling cross-modality knowledge conflicts in large vision-language models.arXiv preprint arXiv:2410.03659, 2024. 2
-
[15]
Dong Shu, Haiyan Zhao, Jingyu Hu, Weiru Liu, Ali Payani, Lu Cheng, and Mengnan Du. Large vision-language model alignment and misalignment: A survey through the lens of explainability.arXiv preprint arXiv:2501.01346, 2025. 2
-
[16]
Meng-Hao Guo, Jiajun Xu, Yi Zhang, Jiaxi Song, Haoyang Peng, Yi-Xuan Deng, Xinzhi Dong, Kiyohiro Nakayama, Zhengyang Geng, Chen Wang, et al. R-bench: Graduate-level multi-disciplinary benchmarks for llm & mllm complex reasoning evaluation.arXiv preprint arXiv:2505.02018, 2025. 2
-
[17]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, et al. Mme: A comprehensive evaluation benchmark for multimodal large language models.arXiv preprint arXiv:2306.13394, 2023. 3 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Mm-vet: Evaluating large multimodal models for integrated capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. InInternational conference on machine learning. PMLR, 2024. 3
2024
-
[19]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024. 3
2024
-
[20]
Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision, pages 216–233. Springer, 2024. 3
2024
-
[21]
Mmbench-video: A long-form multi-shot benchmark for holistic video understanding.Advances in Neural Information Processing Systems, 37:89098–89124, 2024
Xinyu Fang, Kangrui Mao, Haodong Duan, Xiangyu Zhao, Yining Li, Dahua Lin, and Kai Chen. Mmbench-video: A long-form multi-shot benchmark for holistic video understanding.Advances in Neural Information Processing Systems, 37:89098–89124, 2024. 3
2024
-
[22]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024. 3
2024
-
[23]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958–22967, 2025. 3
2025
-
[24]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024. 3
2024
-
[25]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 3, 4
2025
-
[26]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 13691–13701, 2025. 3
2025
-
[27]
Behavior in habitat 2.0: Simulator-independent logical task description for benchmarking embodied ai agents, 2022
Ziang Liu, Roberto Martín-Martín, Fei Xia, Jiajun Wu, and Li Fei-Fei. Behavior in habitat 2.0: Simulator-independent logical task description for benchmarking embodied ai agents, 2022. 3
2022
-
[28]
ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[29]
Affordance benchmark for mllms.arXiv preprint arXiv:2506.00893, 2025
Junying Wang, Wenzhe Li, Yalun Wu, Yingji Liang, Yijin Guo, Chunyi Li, Haodong Duan, Zicheng Zhang, and Guangtao Zhai. Affordance benchmark for mllms.arXiv preprint arXiv:2506.00893, 2025. 3
-
[30]
Zixin Zhang, Kanghao Chen, Xingwang Lin, Lutao Jiang, Xu Zheng, Yuanhuiyi Lyu, Litao Guo, Yinchuan Li, and Ying-Cong Chen. Phystoolbench: Benchmarking physical tool understanding for mllms.arXiv preprint arXiv:2510.09507, 2025. 3
-
[31]
Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, and Lei Bai. Robofactory: Exploring embodied agent collaboration with compositional constraints.arXiv preprint arXiv:2503.16408, 2025. 3
-
[32]
Li Puyin, Tiange Xiang, Ella Mao, Shirley Wei, Xinye Chen, Adnan Masood, Li Fei-Fei, and Ehsan Adeli. Quantiphy: A quantitative benchmark evaluating physical reasoning abilities of vision-language models. arXiv preprint arXiv:2512.19526, 2025. 3
-
[33]
Do generative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026. 3
2026
-
[34]
Rui Yang, Hanyang Chen, Junyu Zhang, Mark Zhao, Cheng Qian, Kangrui Wang, Qineng Wang, Teja Venkat Koripella, Marziyeh Movahedi, Manling Li, et al. Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents.arXiv preprint arXiv:2502.09560, 2025. 3 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Intphys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5016–5025, 2021
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys 2019: A benchmark for visual intuitive physics understanding.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(9):5016–5025, 2021. 3
2019
-
[36]
CLEVRER: CoLlision Events for Video REpresentation and Reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[37]
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines.arXiv preprint arXiv:2106.08261, 2021. 3, 4
-
[38]
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Judith Fan, and Kevin Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties.Advances in Neural Information Processing Systems, 36:67048–67068, 2023. 3
2023
-
[39]
Zhenfang Chen, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B Tenenbaum, and Chuang Gan. Comphy: Compositional physical reasoning of objects and events from videos.arXiv preprint arXiv:2205.01089, 2022. 3
-
[40]
Zhicheng Zheng, Xin Yan, Zhenfang Chen, Jingzhou Wang, Qin Zhi Eddie Lim, Joshua B Tenenbaum, and Chuang Gan. Contphy: Continuum physical concept learning and reasoning from videos.arXiv preprint arXiv:2402.06119, 2024. 3
-
[41]
Xin Xu, Qiyun Xu, Tong Xiao, Tianhao Chen, Yuchen Yan, Jiaxin Zhang, Shizhe Diao, Can Yang, and Yang Wang. Ugphysics: A comprehensive benchmark for undergraduate physics reasoning with large language models.arXiv preprint arXiv:2502.00334, 2025. 4
-
[42]
Phybench: Holistic evaluation of physical perception and reasoning in large language models, 2025
Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, et al. Phybench: Holistic evaluation of physical perception and reasoning in large language models.arXiv preprint arXiv:2504.16074, 2025. 4
-
[43]
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding.arXiv preprint arXiv:2501.16411,
-
[44]
Rohit Girdhar and Deva Ramanan. Cater: A diagnostic dataset for compositional actions and temporal reasoning.arXiv preprint arXiv:1910.04744, 2019. 4
-
[45]
Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environments, 2025
Florian Bordes, Quentin Garrido, Justine T Kao, Adina Williams, Michael Rabbat, and Emmanuel Dupoux. Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environments, 2025. 4
2025
-
[46]
Compositional physical reasoning of objects and events from videos
Zhenfang Chen, Shilong Dong, Kexin Yi, Yunzhu Li, Mingyu Ding, Antonio Torralba, Joshua B Tenenbaum, and Chuang Gan. Compositional physical reasoning of objects and events from videos. IEEE transactions on pattern analysis and machine intelligence, 2025. 4
2025
-
[47]
Craft: A benchmark for causal reasoning about forces and interactions
Tayfun Ates, M Ate¸ so˘glu, Ça ˘gatay Yi˘git, Ilker Kesen, Mert Kobas, Erkut Erdem, Aykut Erdem, Tilbe Goksun, and Deniz Yuret. Craft: A benchmark for causal reasoning about forces and interactions. In Findings of the Association for Computational Linguistics: ACL 2022, pages 2602–2627, 2022. 4
2022
-
[48]
Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023. 4
2023
-
[49]
Star: A benchmark for situated reasoning in real-world videos.arXiv preprint arXiv:2405.09711, 2024
Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. Star: A benchmark for situated reasoning in real-world videos.arXiv preprint arXiv:2405.09711, 2024. 4
-
[50]
Perception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023
Viorica Patraucean, Lucas Smaira, Ankush Gupta, Adria Recasens, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Mateusz Malinowski, Yi Yang, Carl Doersch, et al. Perception test: A diagnostic benchmark for multimodal video models.Advances in Neural Information Processing Systems, 36:42748–42761, 2023. 4
2023
-
[51]
Seeing sound, hearing sight: Uncovering modality bias and conflict of ai models in sound localization
Yanhao Jia, Ji Xie, S Jivaganesh, Hao Li, Xu Wu, and Mengmi Zhang. Seeing sound, hearing sight: Uncovering modality bias and conflict of ai models in sound localization. InAdvances in neural information processing systems, 2025. 5 13
2025
-
[52]
Vmbench: A benchmark for perception-aligned video motion generation
Xinran Ling, Chen Zhu, Meiqi Wu, Hangyu Li, Xiaokun Feng, Cundian Yang, Aiming Hao, Jiashu Zhu, Jiahong Wu, and Xiangxiang Chu. Vmbench: A benchmark for perception-aligned video motion generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13087–13098, 2025. 5
2025
-
[53]
Pai-bench: A comprehensive benchmark for physical ai.arXiv preprint arXiv:2512.01989, 2025
Fengzhe Zhou, Jiannan Huang, Jialuo Li, Deva Ramanan, and Humphrey Shi. Pai-bench: A comprehensive benchmark for physical ai.arXiv preprint arXiv:2512.01989, 2025. 5
-
[54]
Lintao Wang, Encheng Su, Jiaqi Liu, Pengze Li, Peng Xia, Jiabei Xiao, Wenlong Zhang, Xinnan Dai, Xi Chen, Yuan Meng, et al. Physunibench: an undergraduate-level physics reasoning benchmark for multimodal models.arXiv preprint arXiv:2506.17667, 2025. 5
-
[55]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 6 14 A Experiment Settings The experimental settings of this study are as follows: all test videos are sev...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.