PRISM: PRior-guided Imagination Sampling in world Models
Pith reviewed 2026-06-27 19:57 UTC · model grok-4.3
The pith
A lightweight MLP on a frozen world-model encoder produces a state-conditioned Gaussian action prior that fuses into planning via Product-of-Gaussians and raises success rates by over 30 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
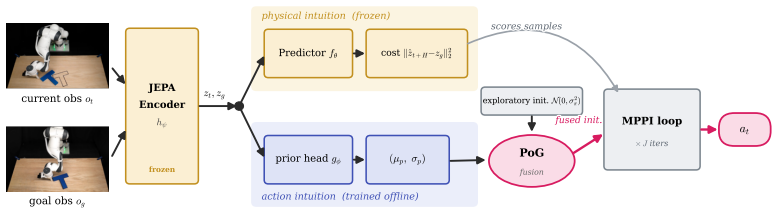
PRISM attaches a lightweight MLP directly to the frozen encoder of a JEPA-style latent world model to predict a state-conditioned Gaussian prior; this prior is then fused into the planner's sampling distribution via a parameter-free precision-weighted Product-of-Gaussians update, producing substantially higher success rates on Cube and PushT tasks without added overhead.
What carries the argument
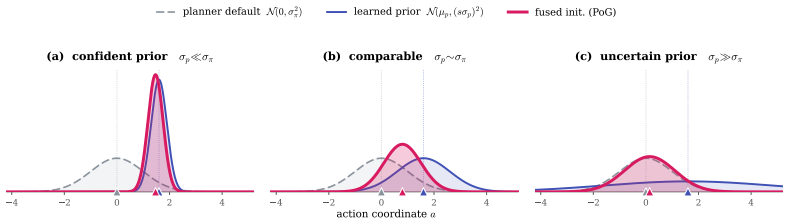
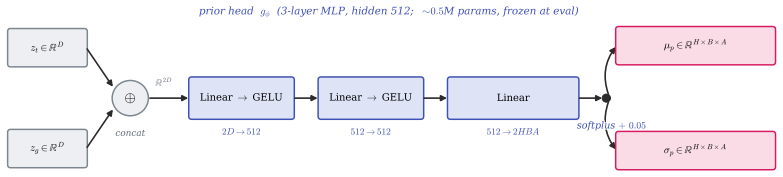
Precision-weighted Product-of-Gaussians fusion of a state-conditioned Gaussian prior extracted by a lightweight MLP from the world model's frozen encoder.
If this is right
- Success rates rise by 35 points on Cube and 32 points on PushT relative to vanilla world-model MPC.
- Inference time remains essentially unchanged because the prior is a single forward pass of a small MLP.
- The method stays task-agnostic and requires no expert demonstrations beyond the data already used to train the world model.
- No separate visual encoders or large-scale VLMs are needed to obtain the action prior.
Where Pith is reading between the lines
- The same prior-extraction idea could be tested on other latent dynamics models that do not use a JEPA objective.
- If the prior is already implicit in the encoder, future work might explore whether even lighter extraction methods, such as linear probes, suffice.
- The Product-of-Gaussians fusion rule might generalize to other sampling-based planners outside model-predictive control.
Load-bearing premise
That the representations already learned inside the world model encode the agent's action intuition in a form that a lightweight MLP can reliably extract as a useful state-conditioned Gaussian prior.
What would settle it
Running the same planner with and without the PRISM prior on a new task where the world model was trained only on random or low-quality action data and finding no gain or a performance drop.
Figures
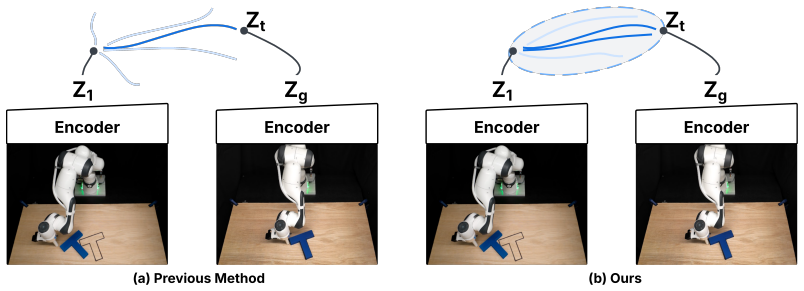

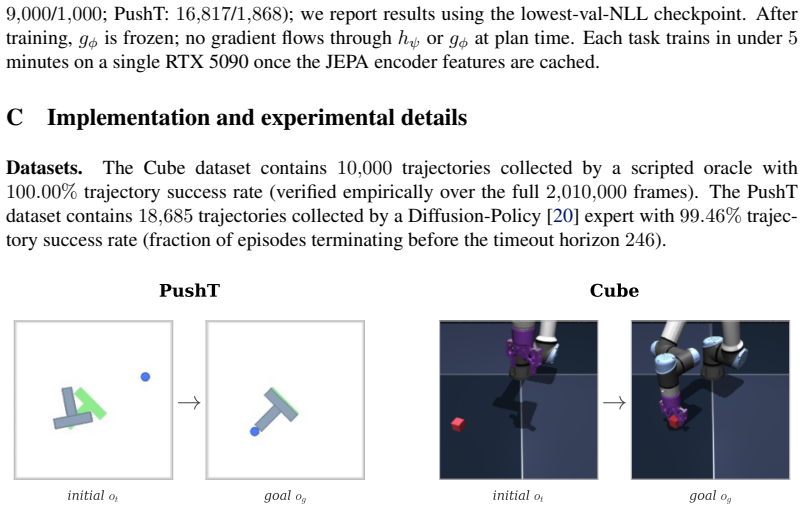
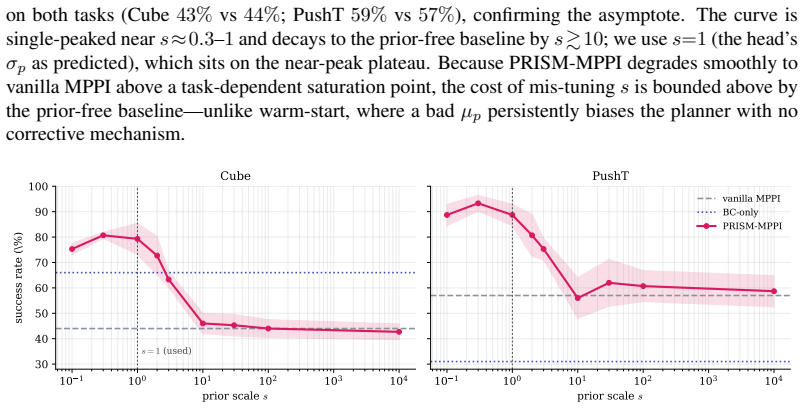

read the original abstract
A learned world model provides a powerful physical intuition for evaluating future states. But its effectiveness in continuous control also depends critically on how candidate actions are generated for model-based planning. Rather than solely asking how accurately a model can simulate the future, we ask: which candidate actions are worth evaluating in the first place? Existing planners typically search arbitrarily or use expert demonstrations only to initialize a sampling mean, discarding the expert's state-conditioned confidence. Properly guiding this search requires a robust action prior, yet current approaches often rely on independent visual encoders or large-scale VLMs to obtain one. We argue that this architectural bloat is unnecessary: the exact same data - and the learned representations of the world model itself - inherently encode the agent's action intuition. We introduce PRISM, a task-agnostic framework that extracts both from a single dataset while maintaining strict architectural simplicity. Building on a standard JEPA-style latent world model, PRISM attaches a lightweight MLP directly to its frozen encoder to predict a state-conditioned Gaussian prior. At plan time, PRISM fuses this prior into the planner's sampling distribution via a precision-weighted Product-of-Gaussians update. This parameter-free, closed-form integration steers the sampling process, making the prior confident where it is and ceding control where it is not. PRISM improves success rates by 35 percentage points over vanilla world-model-based MPC on Cube and 32 percentage points on PushT, without introducing significant inference overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a task-agnostic method that attaches a lightweight MLP to the frozen encoder of a JEPA-style latent world model to predict a state-conditioned Gaussian action prior; this prior is fused at planning time into the MPC sampling distribution via a closed-form, precision-weighted Product-of-Gaussians update. The central empirical claim is that PRISM raises success rates by 35 percentage points over vanilla world-model MPC on the Cube task and 32 points on PushT, with negligible added inference cost.
Significance. If the reported gains are reproducible and the prior demonstrably extracts control-relevant information from the JEPA latents rather than merely reparameterizing the data mean, the work would offer a lightweight way to inject demonstration-derived action intuition into model-based planners without separate visual encoders or large VLMs. This could reduce architectural complexity in continuous-control settings that already train world models.
major comments (3)
- [Abstract / §4] Abstract and §4 (results): the headline claims of +35 pp (Cube) and +32 pp (PushT) are presented without any description of the experimental protocol, number of random seeds, statistical tests, or definition of the 'vanilla world-model-based MPC' baseline; this absence prevents verification that the data support the central performance claim.
- [§3.2] §3.2 (prior extraction): the load-bearing assumption that frozen JEPA encoder representations linearly or MLP-separably encode state-to-action mappings sufficient for a useful Gaussian prior is not accompanied by any diagnostic (e.g., correlation of predicted mean/precision with task success, or comparison against a prior trained on random latents); without such evidence the Product-of-Gaussians fusion may reduce to standard sampling.
- [§4] §4 (ablations): no ablation isolates the contribution of the precision-weighted fusion versus simply initializing the sampler with the MLP mean; if the precision term adds little, the claimed advantage of the closed-form integration is not established.
minor comments (2)
- [§3.3] Notation for the Product-of-Gaussians update (Eq. 7?) should explicitly state how the fused covariance is computed when the prior precision is near zero, to avoid division-by-near-zero issues in implementation.
- [Figure 2] Figure 2 caption should clarify whether the visualized trajectories use the same random seed across methods or are cherry-picked.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where additional detail and evidence are needed to support the central claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (results): the headline claims of +35 pp (Cube) and +32 pp (PushT) are presented without any description of the experimental protocol, number of random seeds, statistical tests, or definition of the 'vanilla world-model-based MPC' baseline; this absence prevents verification that the data support the central performance claim.
Authors: We agree that the experimental details were insufficiently specified. The revised manuscript will expand §4 with a complete description of the experimental protocol, the number of random seeds, statistical tests performed, and an explicit definition of the vanilla world-model-based MPC baseline. revision: yes
-
Referee: [§3.2] §3.2 (prior extraction): the load-bearing assumption that frozen JEPA encoder representations linearly or MLP-separably encode state-to-action mappings sufficient for a useful Gaussian prior is not accompanied by any diagnostic (e.g., correlation of predicted mean/precision with task success, or comparison against a prior trained on random latents); without such evidence the Product-of-Gaussians fusion may reduce to standard sampling.
Authors: This is a valid observation. The revised version will incorporate the suggested diagnostics, including correlation analysis between predicted precision and task success as well as a comparison against a prior trained on random latents. revision: yes
-
Referee: [§4] §4 (ablations): no ablation isolates the contribution of the precision-weighted fusion versus simply initializing the sampler with the MLP mean; if the precision term adds little, the claimed advantage of the closed-form integration is not established.
Authors: We agree that this ablation is required to establish the value of the precision-weighted fusion. The revised manuscript will add an ablation in §4 comparing full PRISM against a variant that uses only the MLP mean for sampler initialization. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper trains a JEPA-style world model on a dataset, then fits a separate lightweight MLP on its frozen encoder outputs to produce a state-conditioned action prior, and applies a closed-form Product-of-Gaussians fusion at planning time. The reported gains (35 pp on Cube, 32 pp on PushT) are measured as empirical task success rates against vanilla MPC baselines. No equation or derivation step equates the final performance metric to a fitted quantity by construction, nor does any load-bearing premise reduce to a self-citation chain; the MLP training and fusion rule are standard supervised and parameter-free operations whose utility is externally validated on held-out task rollouts rather than internally tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Hansen, H
N. Hansen, H. Su, and X. Wang. TD-MPC2: Scalable, robust world models for continuous control. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[7]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
L. Maes, Q. Le Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Williams, N
G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou. Information theoretic MPC for model-based reinforcement learning. InIEEE International Conference on Robotics and Automation (ICRA), 2017
2017
-
[10]
De Boer, D
P.-T. De Boer, D. P. Kroese, S. Mannor, and R. Y . Rubinstein. A tutorial on the cross-entropy method.Annals of Operations Research, 134(1):19–67, 2005
2005
-
[11]
W. Zhao, J. Chen, Z. Meng, D. Mao, R. Song, and W. Zhang. VLMPC: Vision-language model predictive control for robotic manipulation. InRobotics: Science and Systems (RSS), 2024
2024
-
[12]
G. E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Computation, 14(8):1771–1800, 2002
2002
-
[13]
Trevisan and J
E. Trevisan and J. Alonso-Mora. Biased-MPPI: Informing sampling-based model predictive control by fusing ancillary controllers.IEEE Robotics and Automation Letters, 9(6):5871– 5878, 2024
2024
-
[14]
Pertsch, Y
K. Pertsch, Y . Lee, and J. J. Lim. Accelerating reinforcement learning with learned skill priors. InConference on Robot Learning (CoRL), 2020
2020
-
[15]
Paraschos, C
A. Paraschos, C. Daniel, J. Peters, and G. Neumann. Using probabilistic movement primitives in robotics.Autonomous Robots, 42(3):529–551, 2018
2018
- [16]
-
[17]
A. Chahe and L. Zhou. Policy-guided world model planning for language-conditioned visual navigation.arXiv preprint arXiv:2603.25981, 2026
-
[18]
Janner, J
M. Janner, J. Fu, M. Zhang, and S. Levine. When to trust your model: Model-based policy optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[19]
T. Yu, G. Thomas, L. Yu, S. Ermon, J. Zou, S. Levine, C. Finn, and T. Ma. MOPO: Model- based offline policy optimization. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[20]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[21]
Seitzer, A
M. Seitzer, A. Tavakoli, D. Antic, and G. Martius. On the pitfalls of heteroscedastic uncer- tainty estimation with probabilistic neural networks. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[22]
S. Park, K. Frans, B. Eysenbach, and S. Levine. OGBench: Benchmarking offline goal- conditioned reinforcement learning. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[23]
Andrychowicz, F
M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. To- bin, O. Pieter Abbeel, and W. Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017. 11 A Planning algorithm Algorithm 1 gives one PRISM-MPPI planning step, following the data flow of Fig. 2. PRISM adds oneg ϕ forward pass a...
2017
-
[24]
Cru- cially, these are usedonlyto initialize the MPPI sampling distribution via a Product-of-Gaussians (PoG) fusion with the planner’s defaultN(0, σ 2 π)
Prior Initialization:The prior is queried withz deploy g to generate the parameters(µ p, σp). Cru- cially, these are usedonlyto initialize the MPPI sampling distribution via a Product-of-Gaussians (PoG) fusion with the planner’s defaultN(0, σ 2 π)
-
[25]
For each sampled action candidate acand, the planner: • Rolls the action forward through the world model from the current statez t
MPPI Optimization:Throughout the iterations, the sampling standard deviationσremains frozen at this PoG-fused value (the signature of PRISM-MPPI). For each sampled action candidate acand, the planner: • Rolls the action forward through the world model from the current statez t. • Computes the cost as the squared distance between the predicted final-step e...
-
[26]
The final deployed action is entirely determined by MPPI re-weighting
Robustness Guarantee:Because candidate costs are evaluated against the actual deployment goalz deploy g , the prior’s training distribution only biases theinitialsampling. The final deployed action is entirely determined by MPPI re-weighting. This decoupling makes PRISM-MPPI highly robust to thez train g →z deploy g distribution shift. In contrast, direct...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.