EgoAERO: Learning Dexterous Manipulation from a Single Egocentric Video without Object Assets
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Dexterous manipulation can be learned from a single egocentric RGB-D video without object assets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
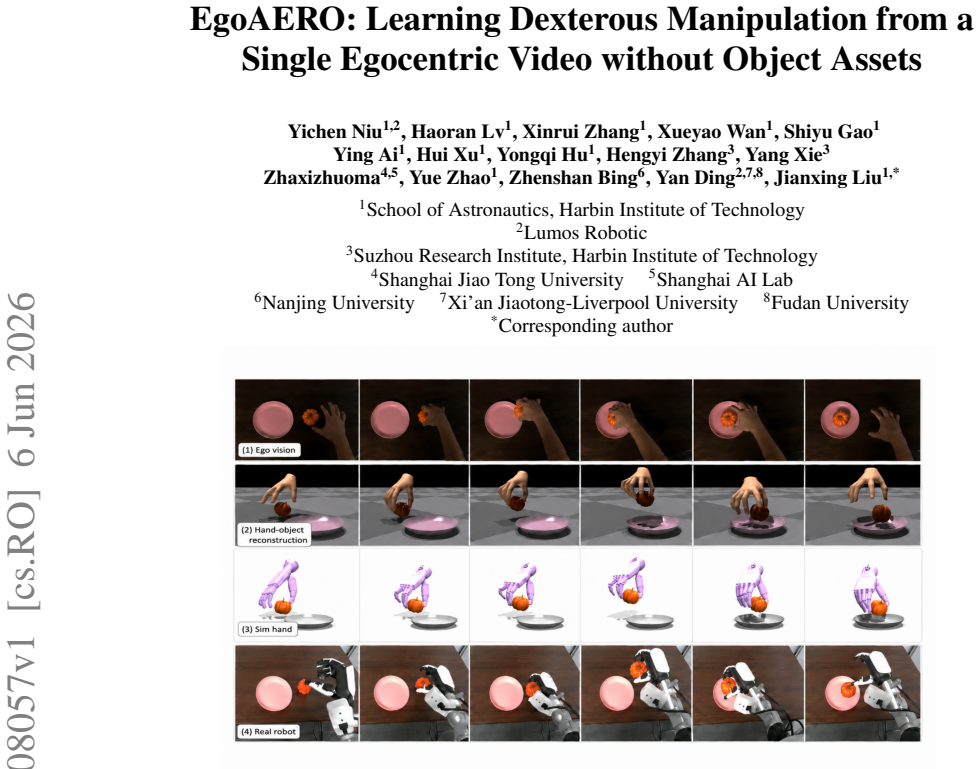
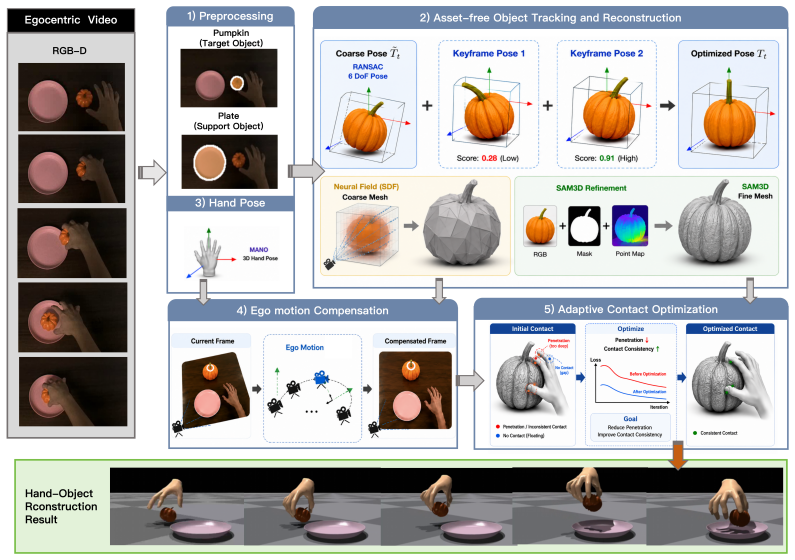
EgoAERO is the first framework that learns dexterous manipulation from a single egocentric RGB-D human demonstration without object assets. It reconstructs contact-consistent hand-object trajectories through asset-free object tracking and reconstruction, ego motion compensation, and adaptive contact optimization, then converts them into robot policies using two-stage residual learning. An online quality assessment mechanism is introduced, and the EgoDex-R dataset of 4.3 million RGB-D frames is constructed to support this form of policy learning. Simulation and real-world tests show that the resulting policies enable single-demonstration dexterous manipulation and reach performance close to t
What carries the argument
Asset-free object tracking and reconstruction together with ego motion compensation and adaptive contact optimization, which together turn a raw egocentric RGB-D video into contact-consistent hand-object trajectories suitable for policy training.
If this is right
- Single-demonstration dexterous manipulation becomes feasible without any object assets.
- Downstream performance on HOI4D tasks reaches levels comparable to CAD-based reconstruction methods.
- The online quality assessment mechanism filters usable trajectories from raw video.
- The EgoDex-R dataset supplies 4.3 million frames as a resource for further policy learning.
Where Pith is reading between the lines
- Large existing collections of egocentric human videos could be repurposed as direct training sources for robot skills.
- The reconstruction pipeline might be tested on tasks with previously unseen object shapes to measure how far asset-free recovery generalizes.
- Real-time versions of the same tracking steps could allow a robot to refine its policy while watching a human perform the task.
Load-bearing premise
The asset-free tracking, reconstruction, compensation, and contact optimization steps produce trajectories accurate enough for the two-stage residual learner to transfer successfully to a robot.
What would settle it
Policies trained on EgoAERO trajectories achieve substantially lower success rates than policies trained on the same tasks using CAD-based object models, when evaluated on identical simulation and real-robot test suites.
Figures


read the original abstract
Egocentric RGB-D videos offer a natural source of human dexterous manipulation demonstrations, but existing data is difficult to use for robot learning because object pose, geometry, and contact information are often missing or require pre-scanned object assets. We present EgoAERO, the first framework that learns dexterous manipulation from a single egocentric RGB-D human demonstration without object assets. EgoAERO reconstructs contact-consistent hand-object trajectories through asset-free object tracking and reconstruction, ego motion compensation, and adaptive contact optimization, then converts them into robot policies using two-stage residual learning. We further introduce an online quality assessment mechanism and construct EgoDex-R, a large-scale egocentric dataset with 4.3M RGB-D frames for dexterous policy learning. Simulation and real-world experiments show that EgoAERO enables single-demonstration dexterous manipulation and achieves downstream performance close to CAD-based reconstructions on HOI4D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoAERO, the first framework to learn dexterous robot manipulation policies from a single egocentric RGB-D human demonstration without any object CAD assets or pre-scanned models. The method reconstructs contact-consistent hand-object trajectories via asset-free object tracking and reconstruction, ego-motion compensation, and adaptive contact optimization; these trajectories are then used to train policies through two-stage residual learning. The authors also release the EgoDex-R dataset (4.3M RGB-D frames) and report simulation and real-world results on HOI4D showing single-demonstration success with performance close to CAD-based baselines.
Significance. If the central claims hold, the work would represent a meaningful advance by removing the object-asset requirement that currently limits scaling of dexterous manipulation learning from human video. The combination of asset-free reconstruction with residual policy learning and the release of EgoDex-R could enable broader use of egocentric data; the two-stage residual approach and online quality assessment are concrete technical contributions worth evaluating.
major comments (2)
- [Abstract] Abstract: the claim that EgoAERO 'achieves downstream performance close to CAD-based reconstructions on HOI4D' is load-bearing for the single-demonstration asset-free claim, yet the manuscript provides no quantitative reconstruction metrics (pose ADD, contact F1, trajectory drift, or reconstruction error) comparing the asset-free pipeline against CAD ground truth on the same sequences. Without these numbers, policy success cannot be attributed to the proposed tracking/reconstruction modules rather than the residual learner or simulator details.
- [Method (asset-free tracking and reconstruction)] The asset-free object tracking + reconstruction + adaptive contact optimization pipeline is the critical conversion step from raw RGB-D to usable training data; the absence of any reported error analysis or ablation on contact consistency or pose accuracy for this pipeline (as opposed to end-to-end policy success) leaves the weakest assumption unverified.
minor comments (2)
- [Method] Clarify the exact definition and implementation of 'adaptive contact optimization' and how it differs from standard contact modeling in prior HOI work.
- [Dataset] The EgoDex-R dataset construction and online quality assessment mechanism are mentioned but lack details on filtering criteria or failure modes; adding these would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive feedback. We address the major comments point-by-point below and will incorporate revisions to strengthen the evaluation of the reconstruction pipeline.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that EgoAERO 'achieves downstream performance close to CAD-based reconstructions on HOI4D' is load-bearing for the single-demonstration asset-free claim, yet the manuscript provides no quantitative reconstruction metrics (pose ADD, contact F1, trajectory drift, or reconstruction error) comparing the asset-free pipeline against CAD ground truth on the same sequences. Without these numbers, policy success cannot be attributed to the proposed tracking/reconstruction modules rather than the residual learner or simulator details.
Authors: We agree that providing quantitative reconstruction metrics would better support the claim and allow clearer attribution of performance gains. In the revised version, we will add a dedicated evaluation section comparing our asset-free reconstruction against CAD-based ground truth on HOI4D sequences, reporting metrics such as pose ADD, contact F1, and trajectory drift. This will help verify the quality of the contact-consistent trajectories generated by the pipeline. revision: yes
-
Referee: [Method (asset-free tracking and reconstruction)] The asset-free object tracking + reconstruction + adaptive contact optimization pipeline is the critical conversion step from raw RGB-D to usable training data; the absence of any reported error analysis or ablation on contact consistency or pose accuracy for this pipeline (as opposed to end-to-end policy success) leaves the weakest assumption unverified.
Authors: We acknowledge the importance of direct error analysis for the reconstruction pipeline. We will include additional ablations and quantitative error analysis on pose accuracy and contact consistency in the method section of the revised manuscript. These will be based on available ground truth where possible in the dataset. revision: yes
Circularity Check
No circularity: derivation relies on independent new modules and external benchmarks
full rationale
The paper's central pipeline (asset-free tracking + reconstruction + ego-motion compensation + adaptive contact optimization + two-stage residual learning) is presented as a sequence of novel algorithmic steps that convert raw RGB-D input into training data and policies; none of the provided text shows any quantity defined in terms of the final performance metric, any fitted parameter renamed as a prediction, or a load-bearing claim justified solely by self-citation. The claim of performance "close to CAD-based reconstructions on HOI4D" is framed as an empirical comparison against an external baseline rather than a self-referential identity. No equations or uniqueness theorems are quoted that collapse the result to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[2]
Zhaxizhuoma, K
Z. Zhaxizhuoma, K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, H. Song, D. Qu, D. Wang, Z. Wang, N. Cao, Y . Ding, B. Zhao, and X. Li. Fastumi: A scalable and hardware-independent universal manipulation interface with dataset. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning...
2025
-
[3]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Scaling egocentric vision: The epic-kitchens dataset. InProceedings of the European Conference on Computer Vision (ECCV), pages 720– 736, 2018
2018
-
[4]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, V . Cartillier, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu, A. Gebreselas...
2022
-
[5]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025. URL https://arxiv.org/abs/2505.11709
Pith/arXiv arXiv 2025
-
[6]
T. Kwon, B. Tekin, J. St ¨uhmer, F. Bogo, and M. Pollefeys. H2o: Two hands manipulating objects for first person interaction recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10138–10148, 2021
2021
-
[7]
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21013–21022, 2022
2022
-
[9]
URLhttps://arxiv.org/abs/2411.19167
-
[10]
Hampali, M
S. Hampali, M. Rad, M. Oberweger, and V . Lepetit. Honnotate: A method for 3d annotation of hand and object poses. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3196–3206, 2020
2020
-
[11]
Y .-W. Chao, W. Yang, Y . Xiang, P. Molchanov, A. Handa, J. Tremblay, Y . S. Narang, K. Van Wyk, U. Iqbal, S. Birchfield, J. Kautz, and D. Fox. Dexycb: A benchmark for cap- turing hand grasping of objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9044–9053, 2021. 9
2021
-
[12]
L. Yang, K. Li, X. Zhan, J. Lv, W. Xu, J. Li, and C. Lu. Oakink: A large-scale knowledge repository for understanding hand-object interaction. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 20953–20962, 2022
2022
-
[13]
Z. Fan, O. Taheri, D. Tzionas, M. Kocabas, M. Kaufmann, M. J. Black, and O. Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12943–12954, 2023
2023
-
[14]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick. Segment anything. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4015–4026, 2023
2023
-
[16]
URLhttps://arxiv.org/abs/2511.16719
-
[17]
B. Wen, C. Mitash, B. Ren, and K. E. Bekris. Bundletrack: 6d pose tracking for novel objects without instance or category-level 3d models. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 8067–8074, 2021
2021
-
[18]
B. Wen, J. Tremblay, V . Blukis, S. Tyree, T. M¨uller, A. Evans, D. Fox, J. Kautz, and S. Birch- field. Bundlesdf: Neural 6-dof tracking and 3d reconstruction of unknown objects. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 606–617, 2023
2023
-
[19]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17868–17879, 2024
2024
-
[20]
M. A. Fischler and R. C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, 1981. doi:10.1145/358669.358692
-
[21]
SAM 3D Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, A. Lin, J. Liu, Z. Ma, A. Sagar, B. Song, X. Wang, J. Yang, B. Zhang, P. Doll´ar, G. Gkioxari, M. Feiszli, and J. Malik. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025. URLhttps://arxiv.org/abs/2511.16624
Pith/arXiv arXiv 2025
- [22]
-
[23]
Zhang, J
J. Zhang, J. Deng, C. Ma, and R. A. Potamias. Hawor: World-space hand motion reconstruction from egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1805–1815, 2025
2025
-
[24]
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. M. Montiel, and J. D. Tard´os. Orb-slam3: An accurate open-source library for visual, visual-inertial, and multimap slam.IEEE Transactions on Robotics, 37(6):1874–1890, 2021. doi:10.1109/TRO.2021.3075644
-
[25]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InProceedings of the European Conference on Computer Vision (ECCV), pages 570–587, 2022
2022
-
[26]
K. Li, P. Li, T. Liu, Y . Li, and S. Huang. Maniptrans: Efficient dexterous bimanual manipula- tion transfer via residual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6991–7003, 2025
2025
-
[27]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021. URLhttps: //arxiv.org/abs/2108.10470. 10 A Details of Keyframe Memory-pool Pose Optimization Memory-frame repres...
Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.