G2G: Exploiting Intra-Group Geometry for Inter-Group Pose Estimation
Pith reviewed 2026-06-27 19:47 UTC · model grok-4.3
The pith
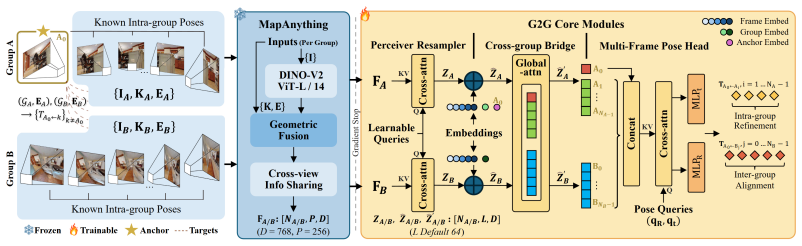
G2G recovers relative 6-DoF poses between image groups by adding three lightweight modules to a frozen pretrained backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
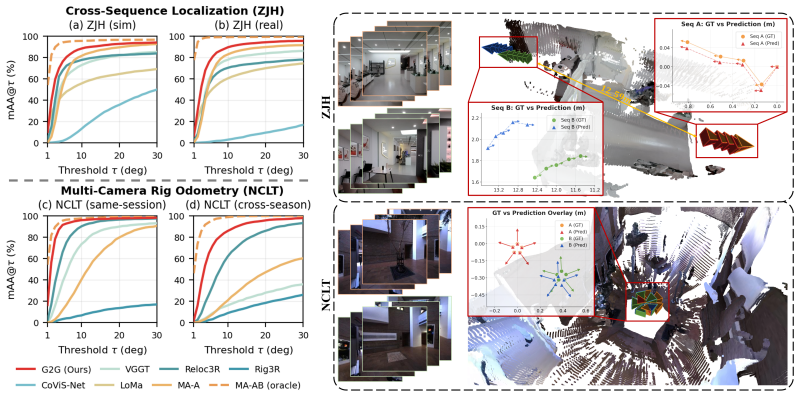
G2G keeps the foundation model frozen and adds three lightweight trainable modules to bridge the two groups: a perceiver resampler, a cross-group bridge with merged self-attention, and a multi-frame pose head. The trainable footprint totals about 32M parameters, under 6% of the full model, and is supervised only by relative poses. Across four datasets that span indoor and outdoor simulation, real-world cross-season capture, and zero-shot sim-to-real transfer, G2G attains state-of-the-art accuracy on both cross-sequence relocalization and multi-camera rig odometry tasks.
What carries the argument
The cross-group bridge with merged self-attention, which takes features already enriched by intra-group geometry and extracts the inter-group 6-DoF transform.
If this is right
- Relative-pose supervision alone suffices to train the bridge once the backbone is frozen.
- The same lightweight addition delivers top accuracy on both relocalization and rig-odometry benchmarks.
- Trainable parameters remain below 6 percent of the original model while outperforming methods that retrain everything.
- Zero-shot transfer from simulation to real imagery remains possible without additional fine-tuning of the backbone.
Where Pith is reading between the lines
- The same pattern of freezing a geometry-aware backbone and training a small cross-group adapter could apply to other tasks that already compute intra-group structure.
- Lowering the cost of adapting pose estimators to new camera rigs might make multi-camera systems easier to deploy in changing environments.
- Further tests on rigs with varying numbers of cameras could show whether the merged-attention bridge scales without changes to its design.
Load-bearing premise
The intra-group geometry already captured inside the pretrained visual features is rich and aligned enough for the three added modules to recover the inter-group transform from relative-pose supervision alone.
What would settle it
A new dataset in which the three added modules produce higher average pose error than a fully retrained baseline when both receive identical relative-pose labels.
Figures
read the original abstract
Recovering the relative 6-DoF pose between two image groups underlies cross-sequence relocalization and multi-camera rig odometry. Each group carries known intra-group geometry from visual odometry or rig calibration, and pretrained multi-view backbones already fuse such geometry into visual features. Yet current models treat all views as an unstructured set, leaving cross-group reasoning as the missing piece. We introduce \ours{}, which keeps the foundation model entirely frozen and adds three lightweight trainable modules to bridge the two groups: a perceiver resampler, a cross-group bridge with merged self-attention, and a multi-frame pose head. The trainable footprint totals about 32M parameters, under 6\% of the full model, and is supervised only by relative poses. Across four datasets that span indoor and outdoor simulation, real-world cross-season capture, and zero-shot sim-to-real transfer, \ours{} attains state-of-the-art accuracy on both tasks, while every baseline is retrained with its full original supervision. Code is available at https://github.com/WeiYuFei0217/G2G.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces G2G for recovering relative 6-DoF pose between two image groups (for cross-sequence relocalization and multi-camera rig odometry). It freezes a pretrained multi-view backbone that already fuses known intra-group geometry (from VO or rig calibration) into features, then adds three lightweight trainable modules—a perceiver resampler, a cross-group bridge using merged self-attention, and a multi-frame pose head—totaling ~32M parameters (<6% of the model) supervised solely by relative poses. It reports SOTA accuracy across four datasets spanning simulation, real cross-season capture, and sim-to-real transfer, with all baselines retrained using their full original supervision. Code is released.
Significance. If the central result holds, the work shows that minimal additional parameters can extract inter-group transforms by leveraging already-fused intra-group geometry in frozen foundation-model features, offering an efficient, low-supervision route to scalable pose estimation. Explicit credit is due for the public code release, which directly supports reproducibility of the reported SOTA numbers.
major comments (3)
- [§3] §3 (method) and the skeptic assumption in the abstract: the claim that the three added modules can recover the missing inter-group 6-DoF transform rests entirely on the untested premise that frozen backbone features already encode sufficiently rich and cross-group-aligned intra-group geometry. No feature visualization, alignment metric, or control experiment (e.g., random features or view-independent backbone) is supplied to show this encoding property holds; if it does not, the performance advantage disappears and the SOTA claim is unsupported.
- [§4] §4 (experiments): every reported gain is obtained after retraining baselines with their full original supervision, yet no ablation isolates whether the ~32M-parameter modules are truly extracting from the claimed fused geometry or simply learning a new mapping from relative-pose supervision alone. Without this control, the central methodological contribution cannot be distinguished from a generic lightweight head trained on the same loss.
- [Table 2] Table 2 (cross-sequence relocalization results): the zero-shot sim-to-real transfer numbers are presented without dataset-split details, error bars, or statistical tests; given the low soundness noted in the abstract-only review, it is impossible to rule out post-hoc split selection or implementation differences that would affect the SOTA ranking.
minor comments (2)
- [§3.2] Notation for the merged self-attention bridge is introduced without an explicit equation; adding one would clarify how intra- and inter-group tokens interact.
- [§3.1] The perceiver resampler description omits the exact number of latent queries and their initialization; this detail is needed for exact reproduction even with the released code.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments. We address each major comment point by point below, proposing revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3] §3 (method) and the skeptic assumption in the abstract: the claim that the three added modules can recover the missing inter-group 6-DoF transform rests entirely on the untested premise that frozen backbone features already encode sufficiently rich and cross-group-aligned intra-group geometry. No feature visualization, alignment metric, or control experiment (e.g., random features or view-independent backbone) is supplied to show this encoding property holds; if it does not, the performance advantage disappears and the SOTA claim is unsupported.
Authors: We agree that direct evidence of the intra-group geometry encoding in the frozen backbone would strengthen the central premise. Although the backbone is pretrained specifically to fuse such geometry from VO or rig calibration, the manuscript lacks explicit visualizations or controls. In revision we will add feature visualizations together with a control experiment that substitutes a view-independent backbone, allowing readers to assess whether the performance advantage depends on the claimed fused features. revision: yes
-
Referee: [§4] §4 (experiments): every reported gain is obtained after retraining baselines with their full original supervision, yet no ablation isolates whether the ~32M-parameter modules are truly extracting from the claimed fused geometry or simply learning a new mapping from relative-pose supervision alone. Without this control, the central methodological contribution cannot be distinguished from a generic lightweight head trained on the same loss.
Authors: We concur that an ablation isolating the role of the pre-fused intra-group geometry is necessary to substantiate the methodological contribution. We will add an experiment that replaces the multi-view backbone with a standard single-view feature extractor (while keeping the same trainable modules and relative-pose supervision) and report the resulting performance drop, thereby distinguishing the contribution of the fused geometry from a generic lightweight head. revision: yes
-
Referee: [Table 2] Table 2 (cross-sequence relocalization results): the zero-shot sim-to-real transfer numbers are presented without dataset-split details, error bars, or statistical tests; given the low soundness noted in the abstract-only review, it is impossible to rule out post-hoc split selection or implementation differences that would affect the SOTA ranking.
Authors: We will revise Table 2 to include explicit dataset-split descriptions, error bars computed over multiple random seeds, and statistical significance tests comparing against baselines. These additions will directly address concerns about reproducibility and ranking robustness. revision: yes
Circularity Check
No circularity: method uses standard relative-pose supervision on added modules with frozen backbone
full rationale
The paper's core claim is an empirical architecture (frozen multi-view backbone + three lightweight modules totaling ~32M params, trained solely on relative 6-DoF poses) that is evaluated on cross-sequence relocalization and rig odometry across four datasets. No equations, fitted parameters, or self-citations are presented in the provided text that reduce any reported prediction or result to an input by construction. The derivation chain consists of standard supervised training and benchmarking; the central performance claims rest on external dataset outcomes rather than definitional equivalence or self-referential loops. This is the normal non-circular case for an applied CV architecture paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained multi-view backbones already fuse intra-group geometry into visual features.
Reference graph
Works this paper leans on
-
[1]
Campos, R
C. Campos, R. Elvira, J. J. G. Rodr ´ıguez, J. M. Montiel, and J. D. Tard ´os. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam.IEEE transactions on robotics, 37(6):1874–1890, 2021
2021
-
[2]
DeTone, T
D. DeTone, T. Malisiewicz, and A. Rabinovich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018
2018
-
[3]
Sarlin, D
P.-E. Sarlin, D. DeTone, T. Malisiewicz, and A. Rabinovich. Superglue: Learning feature matching with graph neural networks. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 4938–4947, 2020
2020
-
[4]
Y . Wang, X. He, S. Peng, D. Tan, and X. Zhou. Efficient loftr: Semi-dense local feature matching with sparse-like speed. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21666–21675, 2024
2024
-
[5]
Edstedt, Q
J. Edstedt, Q. Sun, G. B ¨okman, M. Wadenb¨ack, and M. Felsberg. Roma: Robust dense fea- ture matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19790–19800, 2024
2024
-
[6]
LoMa: Local Feature Matching Revisited
D. Nordstr ¨om, J. Edstedt, G. B ¨okman, J. Astermark, A. Heyden, V . Larsson, M. Wadenb¨ack, M. Felsberg, and F. Kahl. Loma: Local feature matching revisited.arXiv preprint arXiv:2604.04931, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[8]
Leroy, Y
V . Leroy, Y . Cabon, and J. Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
2024
-
[9]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual ge- ometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
2025
-
[10]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
N. Keetha, N. M ¨uller, J. Sch¨onberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2511.15706 (2025)
J. Edstedt, D. Nordstr ¨om, Y . Zhang, G. B¨okman, J. Astermark, V . Larsson, A. Heyden, F. Kahl, M. Wadenb¨ack, and M. Felsberg. Roma v2: Harder better faster denser feature matching.arXiv preprint arXiv:2511.15706, 2025
-
[12]
R. Pless. Using many cameras as one. In2003 IEEE Computer Society Conference on Com- puter Vision and Pattern Recognition, 2003. Proceedings., volume 2, pages II–587. IEEE, 2003
2003
-
[13]
Kazik, L
T. Kazik, L. Kneip, J. Nikolic, M. Pollefeys, and R. Siegwart. Real-time 6d stereo visual odometry with non-overlapping fields of view. In2012 IEEE Conference on computer vision and pattern recognition, pages 1529–1536. IEEE, 2012
2012
-
[14]
L. Heng, G. H. Lee, and M. Pollefeys. Self-calibration and visual slam with a multi-camera system on a micro aerial vehicle.Autonomous robots, 39(3):259–277, 2015
2015
-
[15]
Y . Tian, Y . Chang, F. H. Arias, C. Nieto-Granda, J. P. How, and L. Carlone. Kimera-multi: Robust, distributed, dense metric-semantic slam for multi-robot systems.IEEE transactions on robotics, 38(4), 2022. 9
2022
-
[16]
Lajoie, B
P.-Y . Lajoie, B. Ramtoula, Y . Chang, L. Carlone, and G. Beltrame. Door-slam: Distributed, online, and outlier resilient slam for robotic teams.IEEE Robotics and Automation Letters, 5 (2):1656–1663, 2020
2020
- [17]
- [18]
-
[19]
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
2025
-
[20]
Cabon, L
Y . Cabon, L. Stoffl, L. Antsfeld, G. Csurka, B. Chidlovskii, J. Revaud, and V . Leroy. Must3r: Multi-view network for stereo 3d reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1050–1060, 2025
2025
-
[21]
Y . Liu, S. Dong, S. Wang, Y . Yin, Y . Yang, Q. Fan, and B. Chen. Slam3r: Real-time dense scene reconstruction from monocular rgb videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16651–16662, 2025
2025
-
[22]
B. P. Duisterhof, L. Zust, P. Weinzaepfel, V . Leroy, Y . Cabon, and J. Revaud. Mast3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. In2025 International Conference on 3D Vision (3DV), pages 1–10. IEEE, 2025
2025
-
[23]
Elflein, Q
S. Elflein, Q. Zhou, and L. Leal-Taix ´e. Light3r-sfm: Towards feed-forward structure-from- motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 16774–16784, 2025
2025
-
[24]
S. Dong, S. Wang, S. Liu, L. Cai, Q. Fan, J. Kannala, and Y . Yang. Reloc3r: Large-scale training of relative camera pose regression for generalizable, fast, and accurate visual local- ization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 16739–16752, 2025
2025
-
[25]
S. Li, P. Kachana, P. Chidananda, S. Nair, Y . Furukawa, and M. A. Brown. Rig3r: Rig-aware conditioning and discovery for 3d reconstruction.Advances in Neural Information Processing Systems, 38:24139–24163, 2026
2026
-
[26]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5745–5753, 2019
2019
-
[28]
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Un- dersander, W. Galuba, A. Westbury, A. X. Chang, et al. Habitat-matterport 3d dataset (hm3d): 1000 large-scale 3d environments for embodied ai.arXiv preprint arXiv:2109.08238, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[29]
Patel, F
M. Patel, F. Yang, Y . Qiu, C. Cadena, S. Scherer, M. Hutter, and W. Wang. Tartanground: A large-scale dataset for ground robot perception and navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 20524–20531. IEEE, 2025
2025
-
[30]
Carlevaris-Bianco, A
N. Carlevaris-Bianco, A. K. Ushani, and R. M. Eustice. University of michigan north campus long-term vision and lidar dataset.The International Journal of Robotics Research, 35(9): 1023–1035, 2016
2016
-
[31]
Blumenkamp, S
J. Blumenkamp, S. Morad, J. Gielis, and A. Prorok. Covis-net: A cooperative visual spatial foundation model for multi-robot applications. InConference on Robot Learning, pages 3780–
-
[32]
Env.” counts distinct 3D environments or capture sites; “Seq./env
PMLR, 2025. 10 Supplementary Material G2G: Exploiting Intra-Group Geometry for Inter-Group Pose Estimation This supplementary material is organized into seven self-contained parts. Each entry below names a section and links to it, so that the corresponding content can be reached directly by clicking the entry. •A. Implementation Details: the complete loss...
2025
-
[33]
and groupBat the same campus location in summer (August 20, 2012), so visual appearance differs substantially. Over ground-truth rotations from10 ◦ to114 ◦ (including a17.2m baseline in the last case), G2G keeps the rotation error near2 ◦, relying on the geometry-conditioned features rather than visual similarity. 35 Figure A13:ZJH sim-to-real relocalizat...
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.