TVI-CoT: Text-Visual Interleaved Chain-of-Thought Reasoning for Multimodal Understanding
Pith reviewed 2026-06-27 18:52 UTC · model grok-4.3
The pith
Multimodal LLMs can interleave textual reasoning with on-demand visual lookups via three control tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
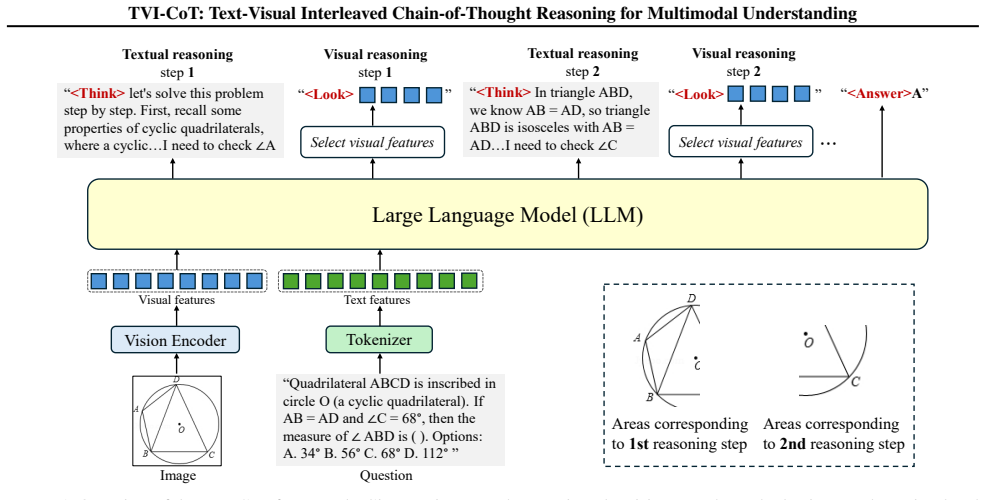
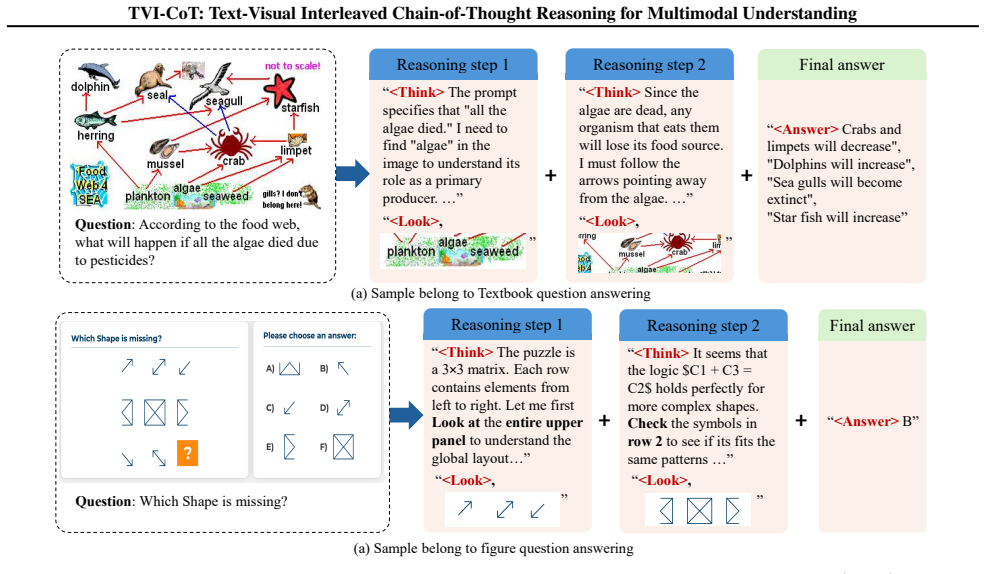
The central claim is that learnable control tokens enable explicit interleaving of textual reasoning and visual feature access, so the model attends to relevant image regions conditioned on the evolving reasoning state rather than relying on a single initial encoding.
What carries the argument
The three learnable control tokens <THINK>, <LOOK> and <ANSWER> that trigger textual reasoning steps, visual attention to image regions, and final answer generation respectively.
Load-bearing premise
Fine-tuning the base multimodal model on these tokens will produce stable switching behavior that actually improves visual grounding rather than adding noise.
What would settle it
A controlled test in which the model is required to use the tokens on a visual reasoning benchmark but shows no accuracy gain or a clear drop relative to the untuned baseline.
Figures
read the original abstract
Chain-of-thought (CoT) reasoning has proven effective for enhancing problem-solving in large language models. However, when applied to multimodal LLMs (MLLMs), existing CoT approaches suffer from a fundamental limitation: they perform reasoning entirely in text without accessing visual features during the reasoning process. After initial visual encoding, image information becomes inaccessible, forcing models to reason based solely on whatever was captured in the initial description, which forms a `vision-blind reasoning' paradigm that limits fine-grained visual extraction, error verification, and adaptive attention. We propose Text-Visual Interleaved Chain-of-Thought (TVI-CoT), a framework that enables explicit interleaving of textual reasoning and visual feature access through learnable control tokens <THINK>, <LOOK> and <ANSWER>. These tokens allow dynamic switching between reasoning and visual grounding, attending to relevant image regions conditioned on the evolving reasoning state. Experiments on eight benchmarks demonstrate state-of-the-art results among MLLM-based CoT methods and notable performance boost compared to the baseline: +6.1% on MMMU, +3.8% on MathVerse, +3.4% on MathVista, and +3.4% on ScienceQA. Code is available at https://github.com/hulianyuyy/TVI-CoT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TVI-CoT, a framework for multimodal LLMs that inserts three learnable control tokens (<THINK>, <LOOK>, <ANSWER>) to enable explicit interleaving of textual chain-of-thought reasoning with visual feature access. The tokens are intended to permit dynamic switching between reasoning and conditioned visual grounding, overcoming the 'vision-blind' limitation of prior MLLM CoT methods that encode images only once. Experiments on eight benchmarks are reported to yield state-of-the-art results among MLLM-based CoT approaches, with gains of +6.1% on MMMU, +3.8% on MathVerse, +3.4% on MathVista, and +3.4% on ScienceQA relative to baselines.
Significance. If the control tokens reliably produce reasoning-dependent <LOOK> emissions that trigger useful visual re-access, the method would address a genuine architectural limitation in current MLLMs and could improve performance on tasks requiring iterative visual verification. The concrete benchmark lifts suggest empirical promise, but only if the gains are shown to stem from the interleaving mechanism rather than ancillary effects of added tokens or training data.
major comments (2)
- [Abstract / Method] The central mechanism claim (abstract) that <LOOK> enables 'attending to relevant image regions conditioned on the evolving reasoning state' is load-bearing yet underspecified. Standard MLLM pipelines run the vision encoder once; the manuscript must detail (in the architecture or inference section) whether this requires persistent visual tokens, a re-encoding path, or another modification, and how ordinary fine-tuning on the three tokens induces stable, non-incidental switching behavior.
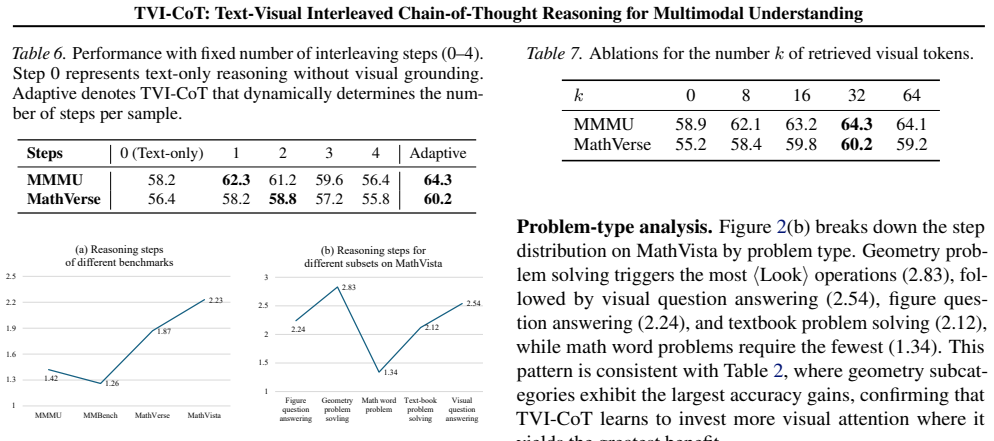
- [Experiments] The reported gains (+6.1% MMMU etc.) are presented without ablations that isolate the interleaving behavior, without analysis of actual <LOOK> token placement or attention maps conditioned on reasoning state, and without statistical tests or multiple-run variance. These omissions make it impossible to rule out that improvements arise from longer CoT traces or extra training data rather than the advertised dynamic visual access.
minor comments (1)
- The abstract states results on 'eight benchmarks' but provides quantitative gains for only four; the remaining four should be reported with the same level of detail for completeness.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each major comment in detail below and outline the revisions we plan to make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] The central mechanism claim (abstract) that <LOOK> enables 'attending to relevant image regions conditioned on the evolving reasoning state' is load-bearing yet underspecified. Standard MLLM pipelines run the vision encoder once; the manuscript must detail (in the architecture or inference section) whether this requires persistent visual tokens, a re-encoding path, or another modification, and how ordinary fine-tuning on the three tokens induces stable, non-incidental switching behavior.
Authors: We thank the referee for this observation. While the manuscript introduces the control tokens and their intended function, we agree that the implementation details of how <LOOK> triggers visual access and the training dynamics are underspecified. In the revised version, we will include a more detailed explanation in the Method section regarding the model architecture modifications (if any) for dynamic visual feature access and how the fine-tuning process leads to reliable interleaving behavior. We will also add pseudocode for the inference procedure. revision: yes
-
Referee: [Experiments] The reported gains (+6.1% MMMU etc.) are presented without ablations that isolate the interleaving behavior, without analysis of actual <LOOK> token placement or attention maps conditioned on reasoning state, and without statistical tests or multiple-run variance. These omissions make it impossible to rule out that improvements arise from longer CoT traces or extra training data rather than the advertised dynamic visual access.
Authors: We concur that these elements would strengthen the empirical validation. For the revision, we commit to adding: ablations that compare against a non-interleaved CoT baseline with matched sequence length to control for trace length; quantitative analysis and examples of <LOOK> token positions; attention map visualizations demonstrating reasoning-conditioned visual attention; and performance metrics with standard deviations across multiple random seeds. This will better isolate the contribution of the dynamic visual access. revision: yes
Circularity Check
Empirical training procedure with no derivations or self-referential reductions
full rationale
The paper proposes TVI-CoT as an empirical extension to MLLMs via insertion of three learnable control tokens followed by standard fine-tuning, with all performance claims resting on benchmark evaluations rather than any mathematical derivation, fitted parameter, or prediction step. No equations appear in the manuscript, no quantity is presented as a 'prediction' that reduces to a fit by construction, and no self-citation chain is invoked to justify a uniqueness theorem or ansatz. The central claim therefore remains an independent empirical assertion about the effect of the added tokens and training regime.
Axiom & Free-Parameter Ledger
free parameters (1)
- control token embeddings for <THINK>, <LOOK>, <ANSWER>
axioms (1)
- domain assumption Standard fine-tuning of the base MLLM with the added tokens is sufficient to induce useful switching and attention behavior.
invented entities (1)
-
control tokens <THINK>, <LOOK>, <ANSWER>
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
An, X., Xie, Y ., Yang, K., Zhang, W., Zhao, X., Cheng, Z., Wang, Y ., Xu, S., Chen, C., Zhu, D., et al. Llava- onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Bai, S., Cai, Y ., Chen, R., et al. Qwen3-vl: Advancing mul- timodal understanding with enhanced visual reasoning. arXiv preprint arXiv:2511.21631, 2025a. Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025b. Bai, S., Li, M., Liu, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chen, Z., Wang, W., Cao, Y ., Liu, Y ., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al. Expanding per- formance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024b. Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Z...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Skywork Open Reasoner 1 Technical Report
He, J., Liu, J., Liu, C. Y ., Yan, R., Wang, C., Cheng, P., Zhang, X., Zhang, F., Xu, J., Shen, W., et al. Sky- work open reasoner 1 technical report.arXiv preprint arXiv:2505.22312,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Lu, P., Bansal, H., Xia, T., Liu, J., Li, C., Hajishirzi, H., Cheng, H., Chang, K.-W., Galley, M., and Gao, J. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Lu, S., Li, Y ., Xia, Y ., Hu, Y ., Zhao, S., Ma, Y ., Wei, Z., Li, Y ., Duan, L., Zhao, J., et al. Ovis2.5 technical report. arXiv preprint arXiv:2508.11737,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Cand `es, E., and Hashimoto, T
Muennighoff, N., Yang, Z., Shi, W., Li, X. L., Fei-Fei, L., Hajishirzi, H., Zettlemoyer, L., Liang, P., Cand `es, E., and Hashimoto, T. B. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 20286– 20332,
2025
-
[9]
V- thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460,
Qiao, R., Tan, Q., Yang, M., Dong, G., Yang, P., Lang, S., Wan, E., Wang, X., Xu, Y ., Yang, L., et al. V- thinker: Interactive thinking with images.arXiv preprint arXiv:2511.04460,
-
[10]
Singh, A., Fry, A., Perelman, A., Tart, A., Ganesh, A., El-Kishky, A., McLaughlin, A., Low, A., Ostrow, A., Ananthram, A., et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
Su, Z., Li, L., Song, M., Hao, Y ., Yang, Z., Zhang, J., Chen, G., Gu, J., Li, J., Qu, X., et al. Openthinkimg: Learning to think with images via visual tool reinforcement learning. arXiv preprint arXiv:2505.08617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Team, K., Du, A., Yin, B., Xing, B., Qu, B., Wang, B., Chen, C., Zhang, C., Du, C., Wei, C., et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Tian, X., Zou, S., Yang, Z., He, M., Waschkowski, F., Wese- mann, L., Tu, P., and Zhang, J. More thought, less accu- racy? on the dual nature of reasoning in vision-language models.arXiv preprint arXiv:2509.25848,
-
[14]
Llava-cot: Let vision language models reason step- by-step
Xu, G., Jin, P., Wu, Z., Li, H., Song, Y ., Sun, L., and Yuan, L. Llava-cot: Let vision language models reason step- by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2087–2098,
2087
-
[15]
Yao, H., Huang, J., Wu, W., Zhang, J., Wang, Y ., Liu, S., Wang, Y ., Song, Y ., Feng, H., Shen, L., et al. Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search.arXiv preprint arXiv:2412.18319,
-
[16]
Ying, K., Meng, F., Wang, J., Li, Z., Lin, H., Yang, Y ., Zhang, H., Zhang, W., Lin, Y ., Liu, S., et al. Mmt- bench: A comprehensive multimodal benchmark for eval- uating large vision-language models towards multitask agi.arXiv preprint arXiv:2404.16006,
-
[17]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., and Smola, A. Multimodal chain-of-thought reasoning in lan- guage models.arXiv preprint arXiv:2302.00923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2411.14405 , year=
Zhao, Y ., Yin, H., Zeng, B., Wang, H., Shi, T., Lyu, C., Wang, L., Luo, W., and Zhang, K. Marco-o1: Towards open reasoning models for open-ended solutions.arXiv preprint arXiv:2411.14405,
-
[19]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.