GEAR-VLA: Learning Geometry-Aware Action Representations for Generalizable Robotic Manipulation
Pith reviewed 2026-06-27 18:27 UTC · model grok-4.3
The pith
GEAR-VLA learns unified geometry-aware action representations through coarse-to-fine learning, 3D alignment, and embodiment canonicalization to generalize across unseen objects and robot bodies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
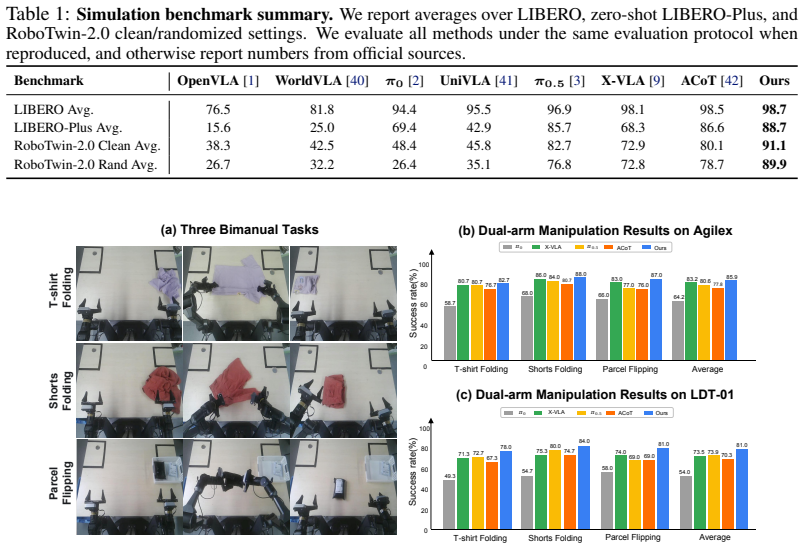
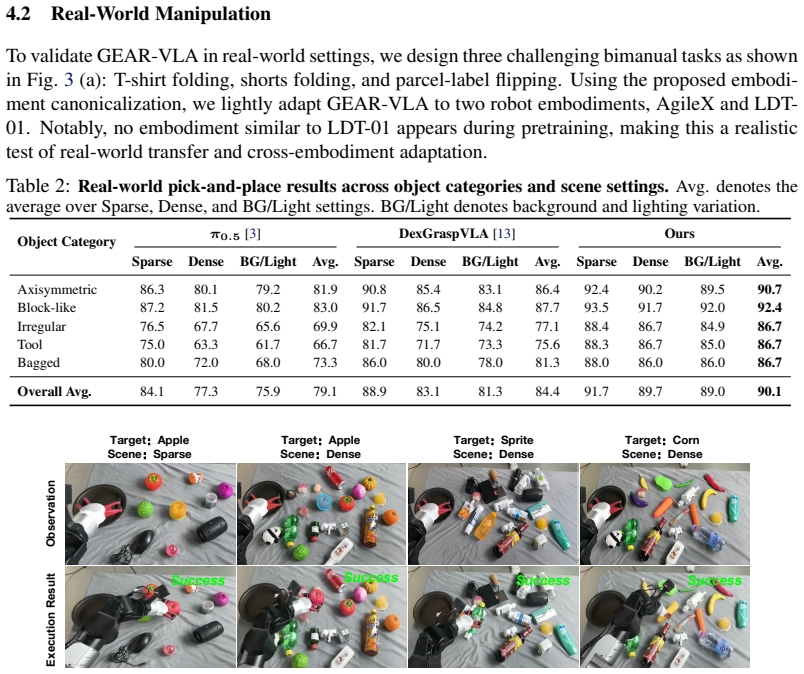
GEAR-VLA shows that a unified geometry-aware action representation arises when coarse-to-fine action learning equips the VLM with embodied reasoning before latent tokens link semantics to a gradient-decoupled DiT continuous expert, when semantic-aligned 3D integration trains a 3D backbone while freezing the original VLM visual pathway, and when embodiment canonicalization uses embodiment-aware states together with embodiment-invariant actions; these elements together produce representations that achieve state-of-the-art results on LIBERO, zero-shot LIBERO-Plus, and RoboTwin 2.0, plus 85.9 percent success on AgileX, 81.0 percent on the unseen LDT-01 embodiment, and 90.1 percent on a 6,360-tri
What carries the argument
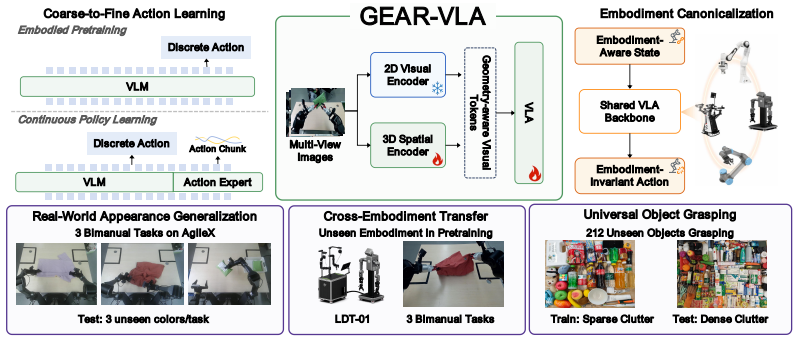
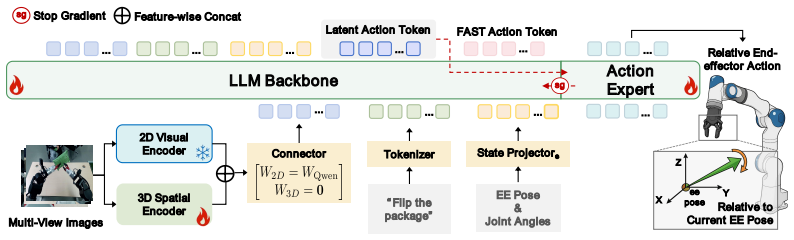
The GEAR-VLA framework, which combines coarse-to-fine action learning, semantic-aligned 3D integration, and embodiment canonicalization to produce unified geometry-aware action representations.
If this is right
- The same representation transfers to zero-shot evaluation on LIBERO-Plus without further training.
- Real-world success reaches 85.9 percent on AgileX and 81.0 percent on a previously unseen robot embodiment.
- A single model attains 90.1 percent success across 212 novel objects in a large-scale grasping test.
- Simulation benchmarks such as LIBERO and RoboTwin 2.0 reach state-of-the-art levels under the new representation.
Where Pith is reading between the lines
- The separation of invariant actions from embodiment-specific states may allow pooling of demonstration data across heterogeneous robot fleets more efficiently than current approaches.
- Freezing the original VLM visual pathway while training only the 3D backbone suggests a route to add spatial awareness to existing large models without full retraining.
- If the geometry-aware tokens remain effective, the same coarse-to-fine structure could extend to manipulation tasks that require contact-rich or deformable-object handling.
- The canonicalization step may reduce the need for embodiment-specific fine-tuning when deploying the model on new hardware.
- keywords:[
Load-bearing premise
The central performance gains come from the geometry-aware components rather than from pretraining data volume or base VLM choice.
What would settle it
An ablation that removes either the semantic-aligned 3D integration or the embodiment canonicalization and shows unchanged success rates on the 6,360-trial universal grasping benchmark with 212 unseen objects would falsify the claim.
Figures

read the original abstract
Vision-Language-Action (VLA) models achieve strong benchmark performance but still struggle in real-world deployment with unseen objects, background shifts, and different robot embodiments. We argue that this stems from the lack of a unified geometry-aware manipulation representation, leaving existing VLAs vulnerable to low-level trajectory supervision, misaligned 3D features, and embodiment differences. To address this, we propose GEAR-VLA, a VLA framework for learning unified geometry-aware action representations for generalizable robotic manipulation. GEAR-VLA adopts coarse-to-fine action learning, where multi-source embodied pretraining equips the VLM with embodied reasoning and discrete action understanding before latent action tokens connect action semantics to a gradient-decoupled DiT continuous action expert. It further performs semantic-aligned 3D integration by aligning a trainable 3D spatial backbone with the VLA representation while freezing the original VLM-aligned visual pathway. To share this representation across robots, GEAR-VLA uses embodiment canonicalization, where embodiment-aware states and embodiment-invariant actions confine robot differences to the low-level interface. Extensive simulation and real-world experiments demonstrate strong generalization: GEAR-VLA achieves state-of-the-art performance on LIBERO, zero-shot LIBERO-Plus, and RoboTwin 2.0, reaches 85.9% success on AgileX and 81.0% on the pretraining-unseen LDT-01 embodiment, and obtains 90.1% success on a 6,360-trial universal grasping benchmark with 212 unseen objects. Code and models will be released at https://github.com/babynabeauty/GEAR-VLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GEAR-VLA, a VLA framework that learns unified geometry-aware action representations via coarse-to-fine action learning (multi-source pretraining followed by latent tokens and gradient-decoupled DiT), semantic-aligned 3D integration (trainable 3D backbone aligned to frozen VLM visual pathway), and embodiment canonicalization (embodiment-aware states with invariant actions). It reports SOTA results on LIBERO, zero-shot LIBERO-Plus, RoboTwin 2.0, 85.9% success on AgileX, 81.0% on unseen LDT-01 embodiment, and 90.1% on a 6,360-trial grasping benchmark with 212 unseen objects, with code/models to be released.
Significance. If the performance gains are shown to stem specifically from the geometry-aware components rather than pretraining scale or base VLM choice, the work would offer a concrete path to improving VLA robustness to unseen objects, backgrounds, and embodiments. The multi-benchmark evaluation including real-robot and cross-embodiment tests, together with the planned code release, would strengthen the contribution by supporting reproducibility and further research.
major comments (1)
- [Abstract and Experiments] Abstract and Experiments section: The central claim attributes SOTA performance to the three geometry-aware components and states that lack of unified geometry-aware representation is the root cause of prior VLA failures. However, no controlled ablations are described that hold pretraining data volume, VLM backbone, and training recipe fixed while removing or varying each component (coarse-to-fine tokens+DiT, 3D alignment, canonicalization). Without these, the reported success rates on LIBERO, RoboTwin, AgileX, LDT-01, and the grasping benchmark cannot substantiate the causal attribution over alternative explanations such as multi-source pretraining scale.
minor comments (2)
- [Method] Notation for latent action tokens and the DiT expert could be introduced with explicit equations in the method section to improve clarity of the coarse-to-fine pipeline.
- [Experiments] Table captions for benchmark results should explicitly state the number of trials and whether statistical significance or variance across seeds is reported.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that isolating the contributions of the proposed geometry-aware components through controlled ablations is essential to substantiate the central claims, and we will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim attributes SOTA performance to the three geometry-aware components and states that lack of unified geometry-aware representation is the root cause of prior VLA failures. However, no controlled ablations are described that hold pretraining data volume, VLM backbone, and training recipe fixed while removing or varying each component (coarse-to-fine tokens+DiT, 3D alignment, canonicalization). Without these, the reported success rates on LIBERO, RoboTwin, AgileX, LDT-01, and the grasping benchmark cannot substantiate the causal attribution over alternative explanations such as multi-source pretraining scale.
Authors: We acknowledge the validity of this point. Our current experiments compare GEAR-VLA against prior VLAs and include some component evaluations, but they do not include fully controlled ablations that hold pretraining data volume, VLM backbone, and training recipe fixed while ablating each of the three components individually. In the revised manuscript, we will add these controlled ablations (e.g., variants with/without the gradient-decoupled DiT, 3D alignment, and canonicalization under matched conditions) to directly address potential alternative explanations such as pretraining scale and to strengthen the causal attribution to the geometry-aware design. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper is an empirical VLA framework proposal whose central claims rest on reported benchmark results (LIBERO, RoboTwin, real-robot trials) rather than any mathematical derivation chain. The abstract and provided text contain no equations, no fitted parameters renamed as predictions, no self-citations invoked as uniqueness theorems, and no ansatzes smuggled via prior work. The three proposed components are motivated by stated limitations of prior VLAs and evaluated via experiments; the performance attribution is therefore not forced by construction or self-reference but remains open to external verification through ablations and replication.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. OpenVLA: An open-source vision-language-action model. InProceedings of The 8th Conference on Robot Learning, volume 270 ofProceedings of Machine Learni...
2025
-
[2]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, L. Smith, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky. π0: A vision-language-action flow model for general robot control. InProceeding...
2025
-
[3]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Walke...
2025
-
[4]
Z. Liang, Y . Li, T. Yang, C. Wu, S. Mao, T. Nian, L. Pei, S. Zhou, X. Yang, J. Pang, Y . Mu, and P. Luo. Discrete diffusion VLA: Bringing discrete diffusion to action decoding in vision- language-action policies.arXiv preprint arXiv:2508.20072, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [5]
-
[6]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, and X. Li. SpatialVLA: Exploring spatial representations for visual-language-action model. In Proceedings of Robotics: Science and Systems, 2025
2025
-
[7]
Y . Yang, S. Zeng, T. Lin, X. Chang, D. Qi, J. Xiao, H. Liu, R. Chen, Y . Chen, D. Huo, F. Xiong, X. Wei, Z. Ma, and M. Xu. ABot-M0: VLA foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
H. Bi, L. Wu, T. Lin, H. Tan, Z. Su, H. Su, and J. Zhu. H-RDT: Human manipulation enhanced bimanual robotic manipulation.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22):18135–18143, 2026. doi:10.1609/aaai.v40i22.38875
-
[9]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, Y .-Q. Zhang, J. Pang, J. Liu, T. Wang, and X. Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[11]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H.-a. Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu. RoboTwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Y . Zhong, X. Huang, R. Li, C. Zhang, Z. Chen, T. Guan, F. Zeng, K. N. Lui, Y . Ye, Y . Liang, Y . Yang, and Y . Chen. DexGraspVLA: A vision-language-action framework towards general dexterous grasping.Proceedings of the AAAI Conference on Artificial Intelligence, 40(22): 18836–18844, 2026. doi:10.1609/aaai.v40i22.38953
-
[14]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017
2017
-
[15]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
2021
-
[16]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the International Conference on Machine Learning, 2021
2021
-
[17]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning. InAdvances in Neural Informa- tion Processing Systems, 2023
2023
-
[18]
Ichter, A
B. Ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Irpan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. To- shev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Lu...
2023
-
[19]
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InProceedings of the IEEE International Conference on Robotics and Automation, pages 9493–9500, 2023. doi:10.1109/ ICRA48891.2023.10160591
-
[20]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, B. Ichter, A. Irpan, D. Kalashnikov, S. Levine, I. Mordatch, C. Parada, M. Ryoo, P. Ser- manet, V . Vanhoucke, F. Xia, T. Xiao, T. Yu, and B. Zitkovich. RT-1: Robotics transformer for real-world control at scale. InProceedings of Robotics: Science and Systems, 2023
2023
-
[21]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, Q. Vuong, V . Vanhoucke, H. Tran, R. Soricut, A. Singh, J. Singh, P. Sermanet, P. R. San- keti, G. Salazar, M. S. Ryoo, K. Reymann, K. Rao, K. Pertsch, I. Mordatch, H. Michalewski, Y . Lu, S. Levine, L. Lee, T.-W. E. Lee, I. Leal, Y . Kuang, D. Kalashnikov, R. Jul...
2023
-
[22]
Driess, F
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, W. Huang, Y . Chebotar, P. Sermanet, D. Duckworth, S. Levine, V . Vanhoucke, K. Hausman, M. Toussaint, K. Greff, A. Zeng, I. Mordatch, and P. Florence. PaLM-E: An embodied multimodal language model. InProceedings of the International Conference o...
2023
-
[23]
Open X-Embodiment: Robotic learning datasets and RT-X models
Open X-Embodiment Collaboration et al. Open X-Embodiment: Robotic learning datasets and RT-X models. InProceedings of the IEEE International Conference on Robotics and Automation, 2024
2024
-
[24]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[25]
Y . Hong, H. Zhen, P. Chen, S. Zheng, Y . Du, Z. Chen, and C. Gan. 3D-LLM: Injecting the 3D world into large language models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[26]
J. L. Sch ¨onberger and J.-M. Frahm. Structure-from-motion revisited. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016
2016
-
[27]
J. L. Sch ¨onberger, E. Zheng, M. Pollefeys, and J.-M. Frahm. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision, 2016
2016
-
[28]
J. Wang, N. Karaev, C. Rupprecht, and D. Novotny. VGGSfM: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21686–21697, 2024
2024
-
[29]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[30]
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5261–5271, 2025
2025
-
[31]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. DUSt3R: Geometric 3D vision made easy. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697–20709, 2024
2024
-
[32]
Leroy, Y
V . Leroy, Y . Cabon, and J. Revaud. Grounding image matching in 3D with MASt3R. In European Conference on Computer Vision, 2024
2024
-
[33]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. VGGT: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5294–5306, 2025
2025
-
[34]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, L. Liden, K. Lee, J. Gao, L. Zettlemoyer, D. Fox, and M. Seo. Latent action pretraining from videos. InInternational Conference on Learning Representations, 2025
2025
-
[35]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. C. M. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InProceedings of Robotics: Science and Systems, 2023. 11
2023
-
[37]
Z. Ren, Y . Wei, X. Yu, G. Luo, Y . Zhao, B. Kang, J. Feng, and X. Jin. Videoworld 2: Learning transferable knowledge from real-world videos, 2026
2026
-
[38]
Y . Wang, H. Zhu, M. Liu, J. Yang, H.-S. Fang, and T. He. Vq-vla: Improving vision-language- action models via scaling vector-quantized action tokenizers. InICCV, 2025
2025
-
[39]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations, volume 2025, pages 28213–28239, 2025
2025
-
[40]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, D. Zhao, and H. Chen. WorldVLA: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
L. Zhong, Y . Liu, Y . Wei, Z. Xiong, S. Liu, and G. Ren. ACoT-VLA: Action chain-of-thought for vision-language-action models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8152–8162, 2026. 12 Appendix A Training Data and Implementation Details Training data.Tables 4 and 5 summarize the two data pools used in C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.