Real-IKEA: Physical Fidelity is the Prerequisite for Robust Manipulation
Pith reviewed 2026-06-27 18:17 UTC · model grok-4.3
The pith
High-fidelity simulation of real IKEA handles lets reinforcement-learning policies discover robust mechanical-advantage strategies instead of fragile friction pulling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Real-IKEA demonstrates that physical fidelity in articulated assets is a prerequisite for robust manipulation policies: when damping, friction, and collision geometry are calibrated to real hardware, RL agents learn hooking and levering behaviors that exploit mechanical advantage rather than depending on fragile friction-based pulling.
What carries the argument
The Real-IKEA dataset of 1,079 articulated asset configurations produced from 83 real IKEA handles and knobs via a six-step physical workflow that includes bidirectional surface-deviation collision-mesh validation and resistance-calibrated damping and friction parameters.
If this is right
- High-fidelity assets shift learned policies from friction-dependent to leverage-dependent strategies.
- Low-fidelity assets produce policies that remain brittle under real contact resistance.
- Accurate collision-mesh deviation metrics and resistance calibration are necessary to expose these strategy differences.
- Articulated manipulation benchmarks must incorporate measured physical parameters to support transferable robustness claims.
Where Pith is reading between the lines
- Future sim-to-real pipelines may need to prioritize contact-parameter calibration over visual fidelity alone.
- The same fidelity requirement could apply to other contact-rich tasks such as door opening or drawer pulling beyond IKEA parts.
- Policy comparison studies that omit fidelity controls may systematically underestimate the value of mechanical-advantage behaviors.
Load-bearing premise
The simulation dynamics produced by the six-step workflow and calibrated resistance values are close enough to real articulated contact that the observed policy differences will appear on physical hardware.
What would settle it
Train the same RL policies on the high-fidelity and low-fidelity versions, deploy both on physical IKEA hardware, and check whether the high-fidelity policy consistently succeeds with hooking or levering while the low-fidelity policy fails or reverts to slipping friction pulls.
Figures





read the original abstract
Robotic manipulation robustness often founders on the physics gap between simplified simulations and the resistance-laden real world. In this work, we emphasize that physical realism in articulated interaction is an important ingredient for robust policy learning. We present Real-IKEA, a dataset and simulation framework designed with physical accuracy as a first-class goal. Real-IKEA provides 1,079 articulated asset configurations, derived from 83 authentic IKEA handles and knobs processed through a meticulous six-step physical workflow. For contact-geometry accuracy, we introduce a bidirectional surface-deviation metric to quantify collision meshes. For dynamics realism, we establish resistance-calibrated configurations that vary damping and friction. Crucially, we demonstrate through a Reinforcement Learning (RL) policy that high-fidelity assets enable the discovery of robust "hooking" and "levering" strategies that prioritize mechanical advantage over fragile friction-pulling. Together, these results position Real-IKEA as a critical benchmark for developing manipulation policies capable of human-level robustness in articulated object tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Real-IKEA, a dataset of 1,079 articulated asset configurations derived from 83 IKEA parts via a six-step physical workflow. It introduces a bidirectional surface-deviation metric for collision-mesh accuracy and resistance-calibrated damping/friction values for dynamics. The central claim is that RL policies trained on these high-fidelity assets discover robust 'hooking' and 'levering' strategies that exploit mechanical advantage, unlike fragile friction-pulling approaches, positioning the dataset as a benchmark for human-level robust manipulation.
Significance. If the simulation-to-reality gap is closed, the dataset and workflow would provide a useful benchmark for articulated-object manipulation, with the bidirectional metric and calibrated parameters offering concrete tools for improving contact and dynamics fidelity in simulation.
major comments (2)
- [Abstract] Abstract: The claim that high-fidelity assets enable discovery of robust hooking/levering strategies provides no quantitative metrics, baselines, error bars, success rates, or statistical comparisons between high- and low-fidelity conditions; the demonstration is described only qualitatively.
- [Abstract] Abstract and title: The assertion that physical fidelity is a prerequisite for robust manipulation (implying real-world applicability) is unsupported because no sim-to-real transfer experiments, real-robot deployments, or hardware torque/force validation of the calibrated parameters are reported; all results remain inside simulation.
minor comments (1)
- [Methods] The six-step workflow is outlined but lacks explicit numerical values or validation data for the resistance-calibrated damping and friction parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that high-fidelity assets enable discovery of robust hooking/levering strategies provides no quantitative metrics, baselines, error bars, success rates, or statistical comparisons between high- and low-fidelity conditions; the demonstration is described only qualitatively.
Authors: We agree that the abstract would be strengthened by quantitative support. The manuscript body contains RL experiments demonstrating the effect; we will revise the abstract to report key success rates, baselines, error bars, and statistical comparisons between high- and low-fidelity conditions. revision: yes
-
Referee: [Abstract] Abstract and title: The assertion that physical fidelity is a prerequisite for robust manipulation (implying real-world applicability) is unsupported because no sim-to-real transfer experiments, real-robot deployments, or hardware torque/force validation of the calibrated parameters are reported; all results remain inside simulation.
Authors: We acknowledge that all experiments are simulation-only and no sim-to-real transfer or hardware validation is provided. The work positions physical fidelity as a prerequisite for discovering robust strategies inside simulation. We will revise the abstract and title to explicitly limit the scope to simulation-based policy learning and to frame Real-IKEA as a benchmark for simulation fidelity rather than claiming direct real-world applicability. revision: yes
Circularity Check
No circularity; empirical dataset construction and simulation demonstration
full rationale
The paper presents a six-step workflow for creating 1,079 articulated assets from IKEA parts, a bidirectional surface-deviation metric, resistance-calibrated damping/friction, and RL policy experiments showing strategy differences in simulation. No load-bearing derivation, equation, or prediction is claimed that reduces to its own inputs by construction. No self-citations are invoked as uniqueness theorems or ansatzes. The work is self-contained as an empirical contribution within simulation; the central claim rests on observed policy outcomes rather than tautological fitting or renaming.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding,
K. Mo, S. Zhu, A. X. Chang, L. Yi, S. Tripathi, L. J. Guibas, and H. Su, “Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 909– 918
2019
-
[2]
Sapien: A simulated part-based interactive environment,
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang,et al., “Sapien: A simulated part-based interactive environment,” inProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, 2020, pp. 11 097–11 107
2020
-
[3]
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills,
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su, “ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[4]
Y . Li, X. Zhang, R. Wu, Z. Zhang, Y . Geng, H. Dong, and Z. He, “Unidoormanip: Learning universal door manipulation policy over large-scale and diverse door manipulation environments,”arXiv preprint arXiv:2403.02604, 2024
-
[5]
Articubot: Learning universal articulated object manipulation policy via large scale simulation
Y . Wang, Z. Wang, M. Nakura, P. Bhowal, C.-L. Kuo, Y .-T. Chen, Z. Erickson, and D. Held, “Articubot: Learning universal articulated object manipulation policy via large scale simulation,” 2025. [Online]. Available: https://arxiv.org/abs/2503.03045
-
[6]
Dex1b: Learning with 1b demonstrations for dexterous manipulation,
J. Ye, K. Wang, C. Yuan, R. Yang, Y . Li, J. Zhu, Y . Qin, X. Zou, and X. Wang, “Dex1b: Learning with 1b demonstrations for dexterous manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2506.17198
-
[7]
Learning to walk in minutes using massively parallel deep reinforcement learning,
N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” 2022. [Online]. Available: https://arxiv.org/abs/2109.11978
-
[8]
Humanoidbench: Simulated humanoid benchmark for whole- body locomotion and manipulation,
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel, “Humanoidbench: Simulated humanoid benchmark for whole- body locomotion and manipulation,” 2024. [Online]. Available: https://arxiv.org/abs/2403.10506
-
[9]
Sim-to-Real: Learning Agile Locomotion For Quadruped Robots
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke, “Sim-to-real: Learning agile locomotion for quadruped robots,” 2018. [Online]. Available: https://arxiv.org/abs/1804.10332
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Benchmarking the sim-to-real gap in cloth manipulation,
D. Blanco-Mulero, O. Barbany, G. Alcan, A. Colom ´e, C. Torras, and V . Kyrki, “Benchmarking the sim-to-real gap in cloth manipulation,”
-
[11]
Available: https://arxiv.org/abs/2310.09543
[Online]. Available: https://arxiv.org/abs/2310.09543
-
[12]
Sim2realviz: Visualizing the sim2real gap in robot ego-pose estimation,
T. Jaunet, G. Bono, R. Vuillemot, and C. Wolf, “Sim2realviz: Visualizing the sim2real gap in robot ego-pose estimation,” 2021. [Online]. Available: https://arxiv.org/abs/2109.11801
-
[13]
Bridging the sim2real gap: Vision encoder pre-training for visuomotor policy transfer,
Y . Yardi, S. Biruduganti, and L. Ankile, “Bridging the sim2real gap: Vision encoder pre-training for visuomotor policy transfer,” 2025. [Online]. Available: https://arxiv.org/abs/2501.16389
-
[14]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Aydin, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gweon, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
S. Srivastava, C. Li, M. Lingelbach, R. Mart ´ın-Mart´ın, F. Xia, K. Vainio, Z. Lian, C. Gokmen, S. Buch, C. K. Liu, S. Savarese, H. Gweon, J. Wu, and L. Fei-Fei, “Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments,” 2021. [Online]. Available: https://arxiv.org/abs/2108.03332
-
[16]
Adamanip: Adaptive articulated object manipulation environments and policy learning,
Y . Wang, X. Zhang, R. Wu, Y . Li, Y . Shen, M. Wu, Z. He, Y . Wang, and H. Dong, “Adamanip: Adaptive articulated object manipulation environments and policy learning,” 2025. [Online]. Available: https://arxiv.org/abs/2502.11124
-
[17]
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI,
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T.-K. Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N, Y . Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su, “ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI,” inRSS 2025, 2025
2025
-
[18]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 5026–5033
2012
-
[19]
Isaac gym: High performance gpu-based physics simulation for robot learning,
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Mack- lin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac gym: High performance gpu-based physics simulation for robot learning,” 2021
2021
-
[20]
Orbit: A unified simulation framework for interactive robot learning environments,
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, A. Mandlekar, B. Babich, G. State, M. Hutter, and A. Garg, “Orbit: A unified simulation framework for interactive robot learning environments,”IEEE Robotics and Automa- tion Letters, vol. 8, no. 6, pp. 3740–3747, 2023
2023
-
[21]
Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search,
X. Wei, M. Liu, Z. Ling, and H. Su, “Approximate convex decomposition for 3d meshes with collision-aware concavity and tree search,”ACM Transactions on Graphics, vol. 41, no. 4, p. 1–18, July
-
[22]
Available: http://dx.doi.org/10.1145/3528223.3530103
[Online]. Available: http://dx.doi.org/10.1145/3528223.3530103
-
[23]
Graspgen: A diffusion-based framework for 6-dof grasping with on- generator training,
A. Murali, B. Sundaralingam, Y .-W. Chao, J. Yamada, W. Yuan, M. Carlson, F. Ramos, S. Birchfield, D. Fox, and C. Eppner, “Graspgen: A diffusion-based framework for 6-dof grasping with on- generator training,”arXiv preprint arXiv:2507.13097, 2025. [Online]. Available: https://arxiv.org/abs/2507.13097
-
[24]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347 APPENDIX A. Real-IKEA Dataset Construction and Physical Modeling Details While the main text focuses on the emergence of robust manipulation policies, this appendix provides extended de- tai...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
The Four Characteristic Failure Modes in Manipu- lation:The primary motivation for developing Real-IKEA stems from observing how conventional, friction-dominated policies fail when deployed on real articulated objects. As illustrated in Figure 8, these failures typically manifest in four characteristic modes: i)Slip:When joint resistance exceeds the frict...
-
[26]
swelling
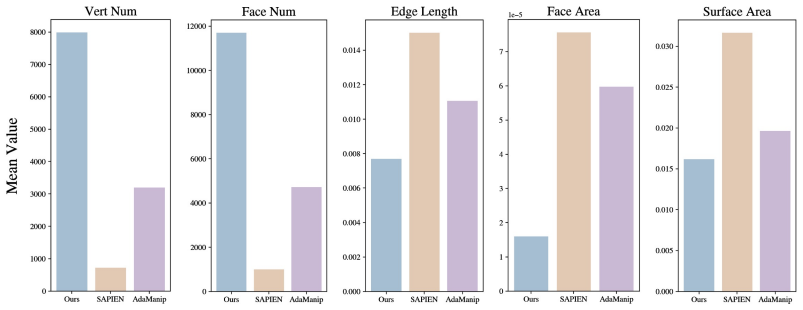
Dataset Construction Workflow:Unlike existing datasets that often rely on synthetically generated or sim- plified CAD models [2], all interactive assets in Real-IKEA are derived from authentic IKEA products. Constructing a single ready-to-use, high-fidelity articulated asset requires a meticuloussix-step processing workflow: i)Component Segmentation and F...
-
[27]
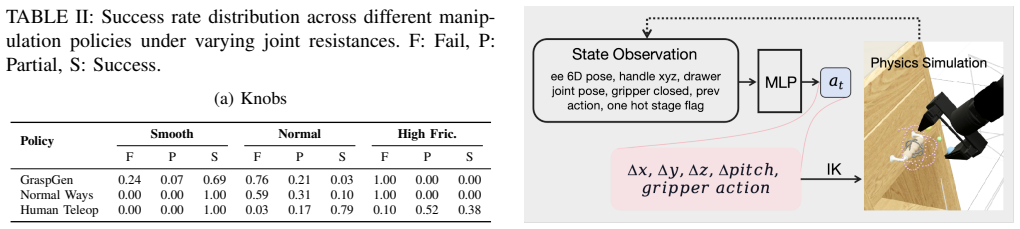
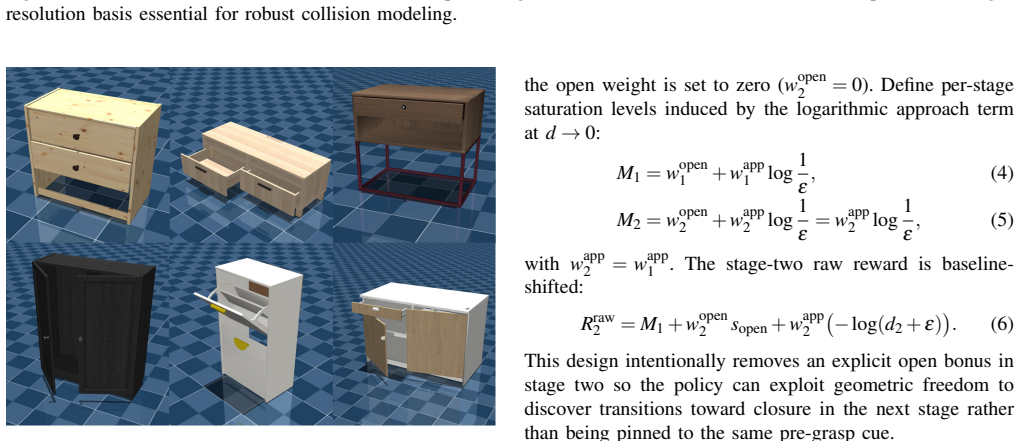
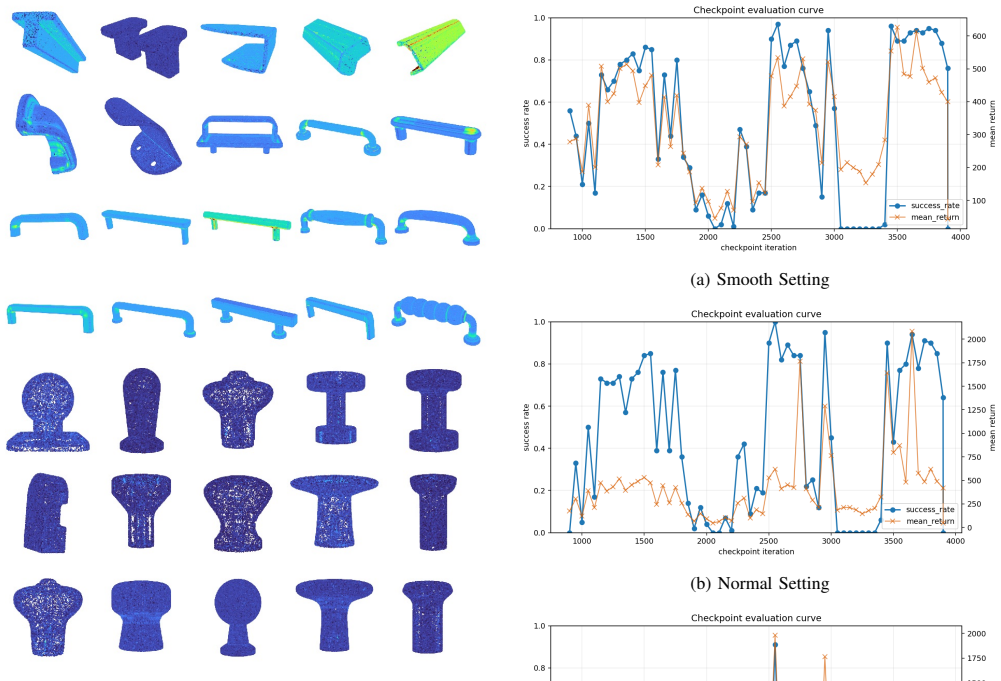
Interactive Component Diversity:Leveraging IKEA’s modular design philosophy, we combinatorially paired base cabinet units with a curated library of 83 authentic handles and knobs. As shown in Figure 7, we categorize these inter- active parts into three main types based on their geometric affordances: •Knobs:Require wrist rotation to wedge the gripper agai...
-
[28]
The metricH Q→P represents the outward deviation from the collision shell to the visual shell
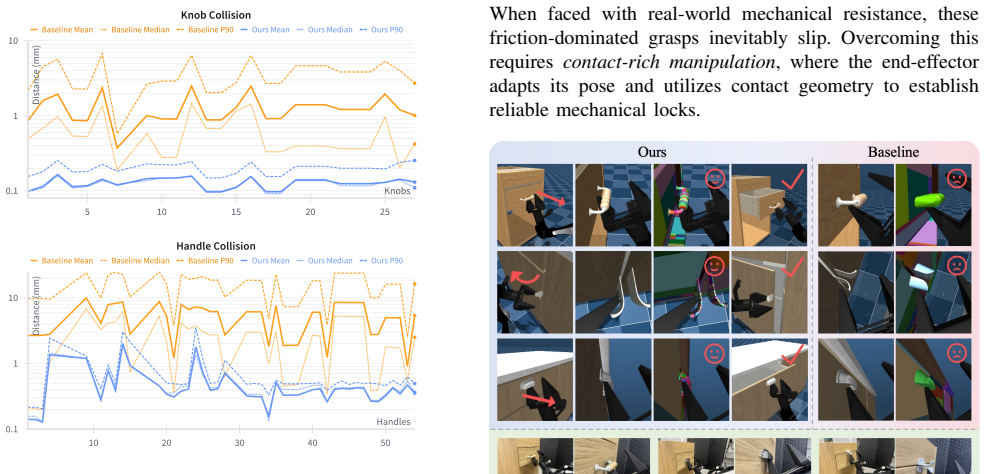
Extended Collision Accuracy Visualization:To visually confirm the quality of our COACD processing (Step 4 of our workflow), we provide a heatmap visualization in Figure 11. The metricH Q→P represents the outward deviation from the collision shell to the visual shell. The results show that the collision models for knobs are highly precise. For complex hand...
-
[29]
A control decimation ofN dec =50 yields a policy command interval ∆t=N dec ∆tsim =0.1s,(1) corresponding to a 10Hz low-level command rate
Simulation and Control Rate:The simulator integrates rigid-body dynamics with a fixed physics timestep∆t sim = 0.002s. A control decimation ofN dec =50 yields a policy command interval ∆t=N dec ∆tsim =0.1s,(1) corresponding to a 10Hz low-level command rate. Episode duration is bounded by a maximum horizon (fixed wall-clock length in simulation time), afte...
-
[30]
Privileged State:The Policy observes low-dimensional features sufficient to specify the manipulation geometry: an end-effector–centric pose summary, the handle position in world coordinates, the drawer joint displacement, a gripper aperture–based closure indicator, the previous action (for temporal context), and a four-dimensional stage indicator aligned ...
-
[31]
Four dimensions specify an incremental end-effector motion relative to the current configuration; one dimension commands the parallel gripper
Action Parameterization and Kinematics:The policy outputs a five-dimensional continuous action each control step, clipped to[−1,1]before execution. Four dimensions specify an incremental end-effector motion relative to the current configuration; one dimension commands the parallel gripper. Let(a 0,a 1,a 2,a 3)denote the clipped arm command. These are scal...
-
[32]
stay open
Staged Reward: Geometry, Gates, and Monotonic Baselines:Rewards are decomposed into four stages that encourage a coarse ordering: approach a pre-grasp region, refine approach to the handle neighborhood, adopt a grasp- ready closure, then open the drawer by increasing the slide displacement. Letcbe the midpoint between the fingertips andhthe handle positio...
-
[33]
Episodes may also terminate on timeout, prolonged kinematic infeasibility, or stagnation under commanded mo- tion (task-specific definitions)
Auxiliary Terms and Terminations:A small penalty discourages jerk; inverse-kinematics failures incur a per-step cost. Episodes may also terminate on timeout, prolonged kinematic infeasibility, or stagnation under commanded mo- tion (task-specific definitions). Fig. 11: Heatmap visualization of physical interaction fidelity (HQ→P) for Real-IKEA components....
-
[34]
First, the handle and robot base poses are fixed at reset to reduce variance while acquir- ing a feasible skill
Domain Randomization and Two-Phase Training: Training proceeds in two phases. First, the handle and robot base poses are fixed at reset to reduce variance while acquir- ing a feasible skill. Second, per-episode pose perturbations are applied to the handle and base within bounded ranges to improve robustness. Specifically, the switch to the second phase oc...
-
[35]
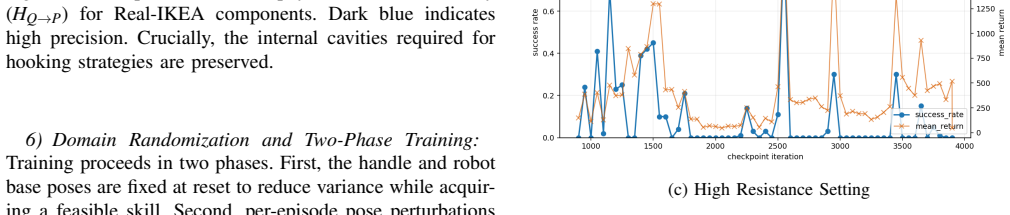
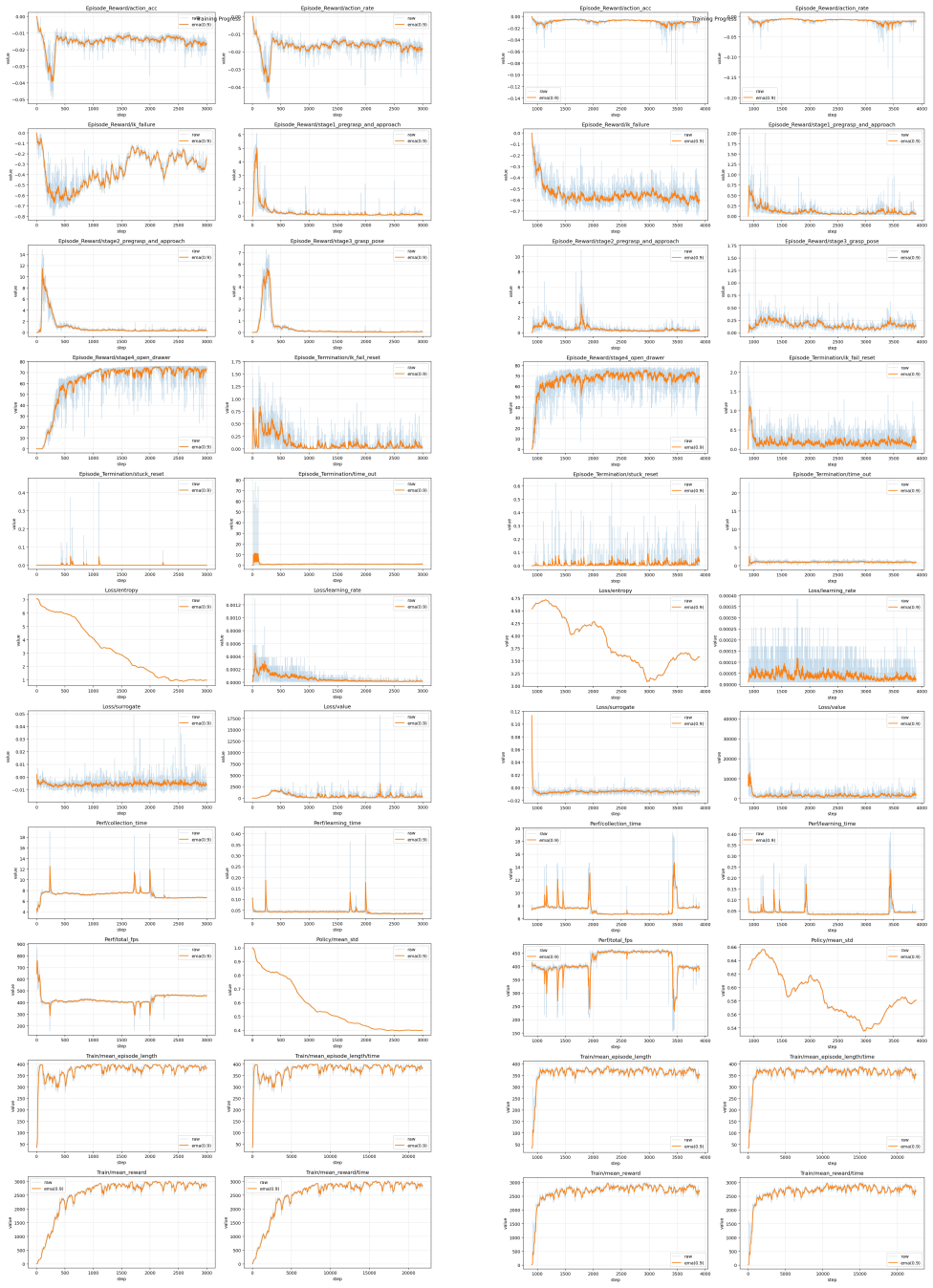
To select the most robust Policy for deployment and downstream distillation, we systematically evaluated intermediate checkpoints saved during the training process
Policy Selection and Robustness Evaluation:Due to the highly dynamic nature of reinforcement learning and the aggressive domain randomization applied during the second phase of training, the policy’s performance can fluctuate between iterations. To select the most robust Policy for deployment and downstream distillation, we systematically evaluated interm...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.