RTL-BenchLS: A Large-Scale Benchmark for RTL Reasoning and Generation with Large Language Models
Pith reviewed 2026-06-27 16:59 UTC · model grok-4.3
The pith
RTL-BenchLS supplies over 10,000 verified Verilog designs plus three self-supervised tasks that cap even the strongest LLMs at 28 percent accuracy on RTL reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
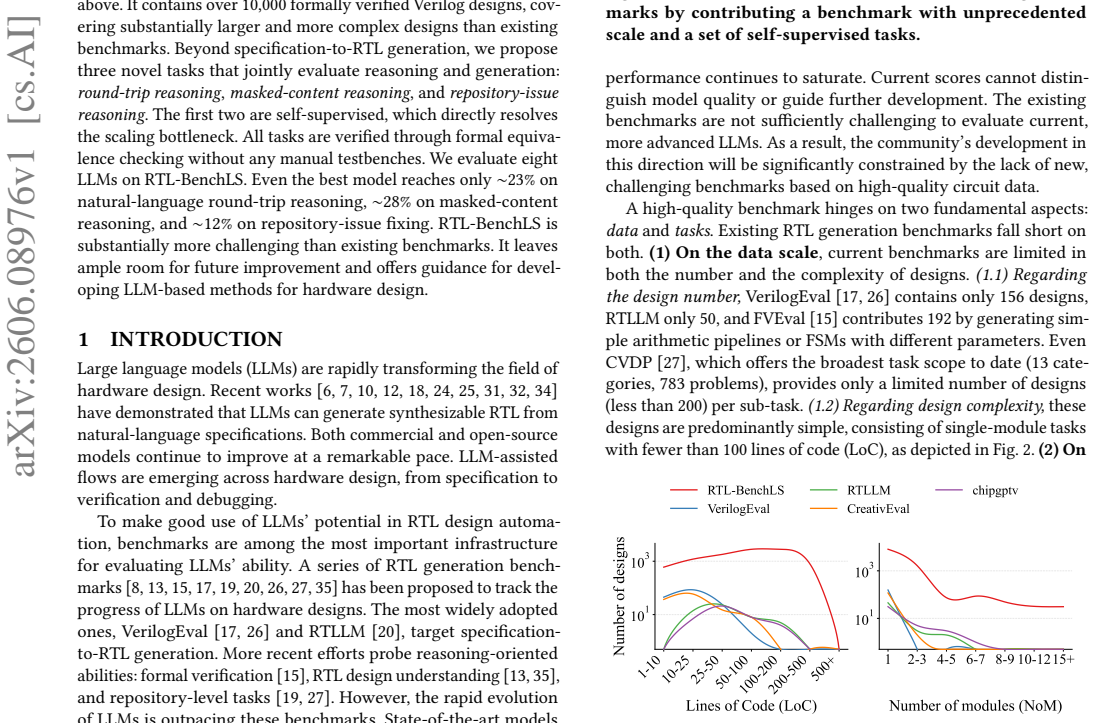
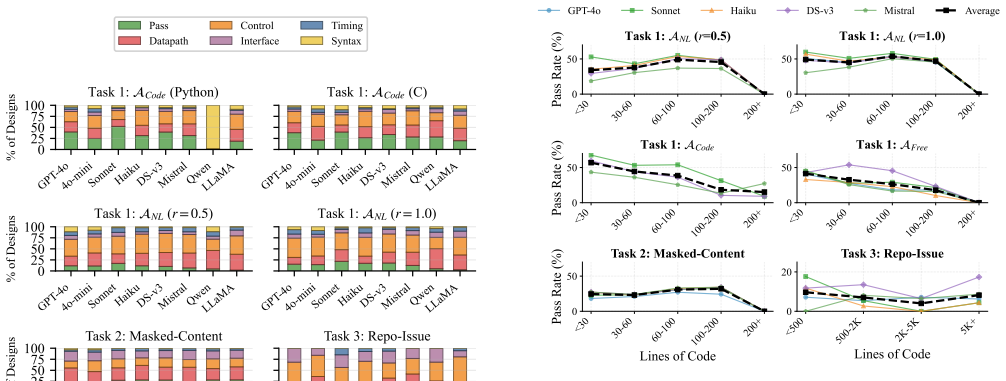
RTL-BenchLS contains more than 10,000 formally verified Verilog designs that are substantially larger and more complex than those in prior benchmarks. The three tasks—round-trip reasoning from natural language, masked-content reasoning, and repository-issue fixing—jointly measure reasoning and generation, are self-supervised for the first two tasks, and are verified by formal equivalence checking rather than manual testbenches. On this benchmark the best evaluated model scores 23 percent on natural-language round-trip reasoning, 28 percent on masked-content reasoning, and 12 percent on repository-issue fixing.
What carries the argument
RTL-BenchLS benchmark whose three tasks rely on formal equivalence checking to supply automatic labels for round-trip, masked-content, and repository-issue reasoning over large verified Verilog designs.
If this is right
- Self-supervised tasks remove the need for aligned specifications and testbenches, allowing benchmarks to grow with the size of open RTL repositories.
- Formal equivalence checking provides label-free verification that can be applied to any design for which an equivalence checker exists.
- Repository-issue fixing directly measures an LLM’s ability to repair real bugs described in issue text, a practical workflow step.
- Low ceiling scores indicate that current models still lack reliable grasp of hardware semantics at the scale of realistic modules.
Where Pith is reading between the lines
- The same self-supervised construction could be reused to create comparable benchmarks in other formally verifiable domains such as software or protocol implementations.
- Persistent low performance on round-trip tasks suggests that LLMs may be learning surface patterns rather than maintaining consistent internal models of circuit behavior.
- If future models close the gap, the benchmark supplies a ready-made training signal through its masked and round-trip formulations.
Load-bearing premise
The three tasks serve as faithful stand-ins for the reasoning and generation demands that arise in actual hardware design work.
What would settle it
A single model that exceeds 70 percent accuracy on all three tasks when evaluated on the same RTL-BenchLS suite would falsify the claim that the benchmark is substantially harder than existing ones.
Figures









read the original abstract
LLM-based RTL generation and reasoning is a promising direction for hardware design automation. High-quality benchmarks are critical infrastructure for tracking progress in this direction. However, existing RTL benchmarks face inherent limitations in both scale and task scope. The designs they cover are typically small and simple, and the tasks focus almost entirely on specification-to-RTL generation. Frontier models' performance already saturates on the existing benchmarks. Scaling these benchmarks up is fundamentally difficult because aligned labels are required for benchmarking, such as specifications and testbenches. Such aligned high-quality data are rarely available for real-world designs. We introduce RTL-BenchLS, a large-scale benchmark addressing both limitations above. It contains over 10,000 formally verified Verilog designs, covering substantially larger and more complex designs than existing benchmarks. Beyond specification-to-RTL generation, we propose three novel tasks that jointly evaluate reasoning and generation: round-trip reasoning, masked-content reasoning, and repository-issue reasoning. The first two are self-supervised, which directly resolves the scaling bottleneck. All tasks are verified through formal equivalence checking without any manual testbenches. We evaluate eight LLMs on RTL-BenchLS. Even the best model reaches only 23% on natural-language round-trip reasoning, 28% on masked-content reasoning, and 12% on repository-issue fixing. RTL-BenchLS is substantially more challenging than existing benchmarks. It leaves ample room for future improvement and offers guidance for developing LLM-based methods for hardware design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RTL-BenchLS, a benchmark with over 10,000 formally verified Verilog designs for LLM-based RTL reasoning and generation. It proposes three self-supervised tasks—round-trip reasoning, masked-content reasoning, and repository-issue reasoning—verified via formal equivalence checking without manual testbenches. Evaluation on eight LLMs shows low performance (23% on natural-language round-trip, 28% on masked-content, 12% on repository-issue), claiming the benchmark is substantially more challenging than existing ones.
Significance. If the tasks require the intended semantic reasoning, RTL-BenchLS offers a scalable, verifiable benchmark for tracking progress in hardware design automation with LLMs, overcoming scale and scope limitations of prior benchmarks. The formal verification approach and self-supervised construction are strengths that enable large-scale evaluation.
major comments (2)
- [Abstract] Abstract: The claim that the three tasks 'jointly evaluate reasoning and generation' is load-bearing for the headline result that the benchmark is substantially more challenging; however, round-trip and masked-content tasks could potentially be solved via surface syntactic mappings rather than multi-step semantic reasoning, and formal equivalence checking does not rule out such shortcuts.
- [Abstract] Abstract: No details are provided on how the 10,000 designs were collected or filtered, which is load-bearing for the claim of covering 'substantially larger and more complex designs' without selection effects that could inflate the apparent difficulty.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each point below and will revise the manuscript to improve clarity and address potential concerns about task design and data provenance.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the three tasks 'jointly evaluate reasoning and generation' is load-bearing for the headline result that the benchmark is substantially more challenging; however, round-trip and masked-content tasks could potentially be solved via surface syntactic mappings rather than multi-step semantic reasoning, and formal equivalence checking does not rule out such shortcuts.
Authors: We agree that formal equivalence checking alone does not rule out the theoretical possibility of syntactic shortcuts. The round-trip task requires producing a natural-language specification from RTL that is sufficiently complete and accurate to allow regeneration of equivalent RTL, while masked-content requires inferring omitted logic from surrounding context. However, to directly address the concern, the revised manuscript will include new experiments comparing LLM performance against simple syntactic baselines (e.g., template matching and regex-based rewriting), which achieve near-zero success rates on these tasks. This evidence will be added to Section 4 and referenced in the abstract to support that the tasks require semantic reasoning beyond surface patterns. revision: yes
-
Referee: [Abstract] Abstract: No details are provided on how the 10,000 designs were collected or filtered, which is load-bearing for the claim of covering 'substantially larger and more complex designs' without selection effects that could inflate the apparent difficulty.
Authors: The full manuscript (Section 3.1) details the collection from public open-source Verilog repositories followed by a formal verification pipeline and filters based on module size, hierarchy depth, and successful equivalence checks. We acknowledge that the abstract omits this summary, which is important for evaluating selection effects. We will revise the abstract to concisely describe the sources and filtering process, ensuring the claim of scale and complexity is properly contextualized. revision: yes
Circularity Check
No significant circularity; benchmark construction with direct empirical measurements.
full rationale
This is a benchmark paper that defines three tasks (round-trip reasoning, masked-content reasoning, repository-issue fixing), constructs a dataset of >10k formally verified Verilog designs, and reports direct model performance numbers (e.g., best model at 23%/28%/12%). No derivations, fitted parameters, or self-referential predictions exist. Performance figures are measurements on the released tasks, not outputs that reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central premise that the tasks jointly evaluate reasoning/generation is an assumption about task validity, not a circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Formal equivalence checking is a reliable and complete method for verifying RTL correctness without manual testbenches.
Reference graph
Works this paper leans on
-
[1]
Ahmed Allam et al . 2024. RTL-Repo: A Benchmark for Evaluating LLMs on Large-Scale RTL Design Projects. InWorkshop on LLM-Aided Design (LAD)
2024
-
[2]
Ahmed Allam et al. 2025. RTLPP: A Parallel Processing RTL Code Generation Framework Using LLMs. InWorkshop on LLM-Aided Design (LAD)
2025
-
[3]
Analog Devices. 2024. HDL Reference Designs. https://github.com/ analogdevicesinc/hdl
2024
- [4]
-
[5]
Kaiyan Chang, Zhirong Chen, Yunhao Zhou, Wenlong Zhu, Kun Wang, Haobo Xu, Cangyuan Li, Mengdi Wang, Shengwen Liang, Huawei Li, et al. 2024. Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation. InProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design. 1–9
2024
- [6]
- [7]
-
[8]
Matthew DeLorenzo, Vasudev Gohil, and Jeyavijayan Rajendran. 2024. Creative- val: Evaluating creativity of llm-based hardware code generation. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 1–5
2024
-
[9]
Alex Forencich. 2024. Verilog Ethernet Components. https://github.com/ alexforencich/verilog-ethernet
2024
-
[10]
Mingzhe Gao, Jieru Zhao, Zhe Lin, Wenchao Ding, Xiaofeng Hou, Yu Feng, Chao Li, and Minyi Guo. 2024. AutoVCoder: A Systematic Framework for Automated Verilog Code Generation using LLMs. InInternational Conference on Computer Design (ICCD)
2024
-
[11]
Mingzhe Gao, Jieru Zhao, Zhe Lin, Wenchao Ding, Xiaofeng Hou, Yu Feng, Chao Li, and Minyi Guo. 2024. Autovcoder: A systematic framework for automated verilog code generation using llms. In2024 IEEE 42nd International Conference on Computer Design (ICCD). IEEE, 162–169
2024
- [12]
- [13]
-
[14]
Konstantin Jejemont. 2023. basic_verilog: A General Verilog Library. https: //github.com/pConst/basic_verilog
2023
-
[15]
Minwoo Kang, Mingjie Liu, Ghaith Bany Hamad, Syed Suhaib, and Haoxing Ren
- [16]
-
[17]
Zeju Li, Changran Xu, Zhengyuan Shi, Zedong Peng, Yi Liu, Yunhao Zhou, Lingfeng Zhou, Chengyu Ma, Jianyuan Zhong, Xi Wang, et al. 2025. Deepcircuitx: A comprehensive repository-level dataset for rtl code understanding, generation, and ppa analysis.arXiv preprint arXiv:2502.18297(2025)
-
[18]
Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. 2023. Ver- ilogeval: Evaluating large language models for verilog code generation. In2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD). IEEE, 1–8
2023
-
[19]
Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Xie
-
[20]
In2024 IEEE LLM Aided Design Workshop (LAD)
Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open- source dataset and lightweight solution. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 1–5
- [21]
-
[22]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. 2024. Rtllm: An open-source benchmark for design rtl generation with large language model. In2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 722–727
2024
-
[23]
Zeus Marmolejo. 2014. Zet: Open-Source x86 Processor. https://github.com/ marmolejo/zet
2014
-
[24]
NVIDIA. 2018. NVDLA Hardware. https://github.com/nvdla/hw
2018
-
[25]
Andreas Olofsson. 2019. OH: Open Hardware Library. https://github.com/ aolofsson/oh
2019
-
[26]
Hammond Pearce, Benjamin Tan, and Ramesh Karri. 2020. Dave: Deriving automatically verilog from english. InWorkshop on Machine Learning for CAD (MLCAD)
2020
- [27]
- [28]
-
[29]
Nathaniel Pinckney, Christopher Deng, Chia-Tung Ho, Yi-Dian Tsai, Mingjie Liu, Wenfei·Zhou, Brucek Khailany, and Haoxing Ren. 2025. Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Evaluating Large Language Models and Agents on RTL Design and Verification.arXiv preprint arXiv:2506.14074(2025)
- [30]
-
[31]
SI-RISCV. 2020. HummingBird E200 Open-Source RISC-V Core. https://github. com/SI-RISCV/e200_opensource
2020
-
[32]
T-Head Semiconductor. 2021. OpenC910: XuanTie C910 RISC-V Processor. https: //github.com/XUANTIE-RV/openc910
2021
-
[33]
Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan- Gavitt, Ramesh Karri, and Siddharth Garg. 2024. Verigen: A large language model for verilog code generation.ACM Transactions on Design Automation of Electronic Systems29, 3 (2024), 1–31
2024
- [34]
-
[35]
Yongan Zhang, Zhongzhi Yu, Yonggan Fu, Cheng Wan, and Yingyan Celine Lin
-
[36]
In2024 IEEE LLM Aided Design Workshop (LAD)
Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation. In2024 IEEE LLM Aided Design Workshop (LAD). IEEE, 1–5
-
[37]
Yujie Zhao, Hejia Zhang, Hanxian Huang, Zhongming Yu, and Jishen Zhao
- [38]
- [39]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.