Ultra Flash: Scaling Real-Time Streaming Video Generation to High Resolutions
Pith reviewed 2026-06-27 17:06 UTC · model grok-4.3
The pith
Ultra Flash scales low-resolution streaming video models to real-time 1K and 2K output on a single GPU via a cascaded super-resolution framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
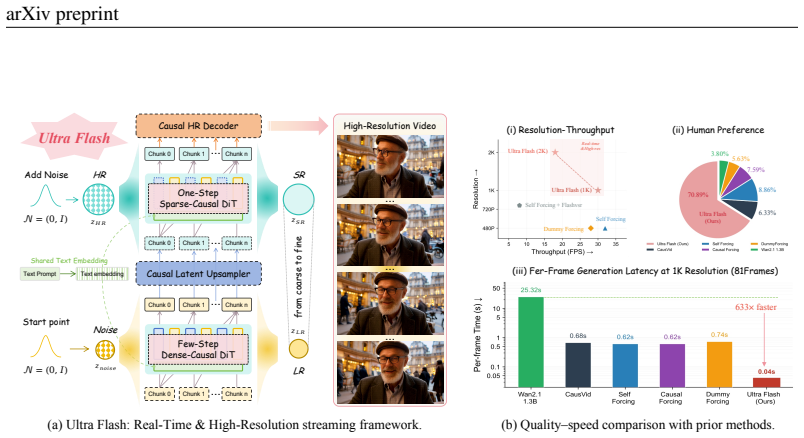
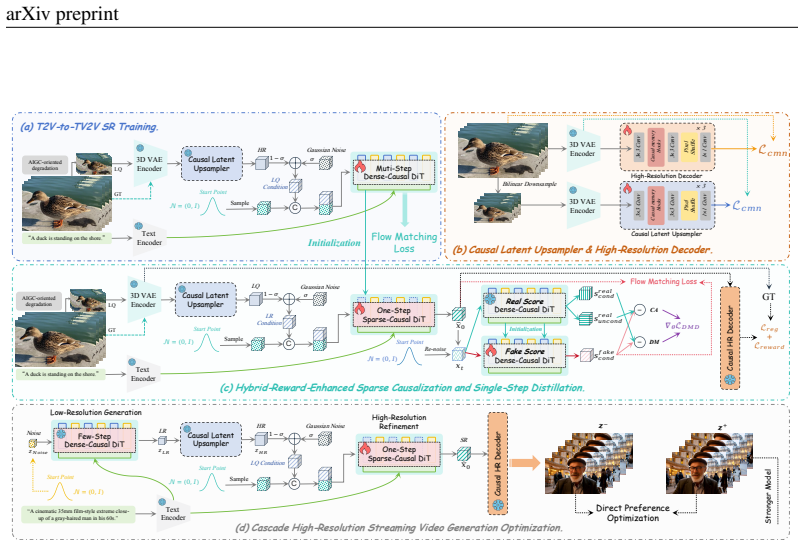
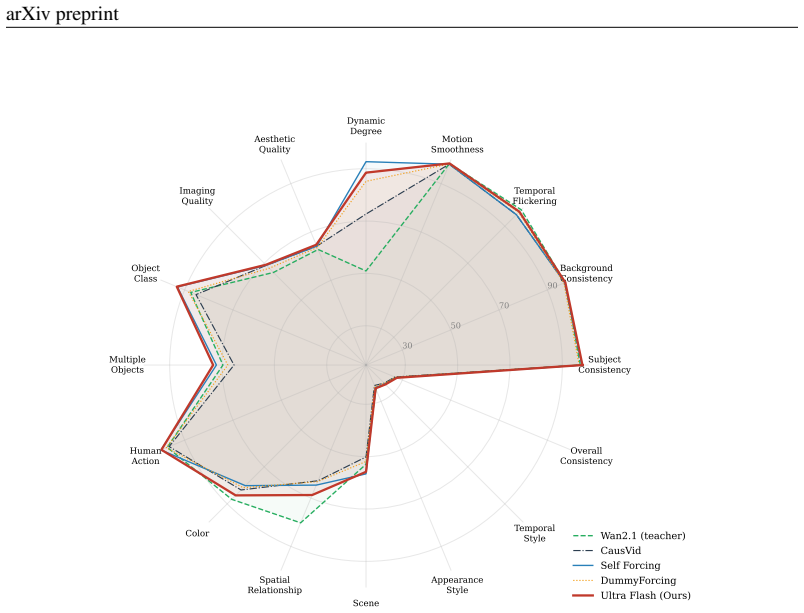
Ultra Flash is a cascaded streaming framework for real-time high-resolution video generation. It achieves approximately 30 FPS at 1K resolution and 18 FPS at 2K resolution on a single GPU by training a super-resolution model in an architecture-preserving T2V-to-TV2V manner with an AIGC-oriented data degradation pipeline, pairing it with a causal streaming latent upsampler and high-resolution decoder, and applying a cascade optimization scheme of hybrid-reward sparse causalization, single-step distillation, and cascaded streaming self-forcing preference optimization with dynamic cache management, while maintaining state-of-the-art visual quality.
What carries the argument
The cascaded streaming framework that combines an architecture-preserving T2V-to-TV2V super-resolution training paradigm, a causal streaming latent upsampler with high-resolution decoder, and a cascade optimization scheme using sparse causalization, distillation, and self-forcing preference optimization.
If this is right
- Existing low-resolution generative models can be extended to high-resolution real-time streaming output without retraining the base model from scratch.
- Spatiotemporal coherence improves through the causal latent upsampler with only negligible added computation.
- The optimization scheme jointly raises coherence and quality while supporting real-time performance via dynamic cache management.
- The full pipeline produces ultra-high-resolution streaming video at the reported frame rates on one GPU.
- The approach enables efficient latent spatial scaling followed by precise high-resolution decoding.
Where Pith is reading between the lines
- The same training and cascade structure could be tested on non-video generative tasks such as image or audio synthesis to check transferability.
- Real-time applications like live content creation or interactive simulation might adopt the method once base models are widely available.
- Adding further cascade stages could be examined to reach 4K resolutions while monitoring speed and quality trade-offs.
- The preservation of base-model capabilities can be directly measured by comparing prompt fidelity before and after the super-resolution stage on identical inputs.
Load-bearing premise
The architecture-preserving T2V-to-TV2V super-resolution training paradigm together with the AIGC-oriented data degradation pipeline will preserve the generative capability of the base low-resolution model while still enabling enhanced high-resolution detail when cascaded.
What would settle it
Integrate the trained super-resolution stage after a standard low-resolution streaming video model and check whether the high-resolution outputs retain the base model's text prompt adherence and motion coherence or instead introduce visible artifacts and quality degradation.
Figures







read the original abstract
While recent autoregressive video diffusion models achieve remarkable streaming quality, they remain confined to low resolutions (e.g., 480P), leaving efficient, scalable, real-time high-resolution video generation a fundamental open challenge. To bridge this gap, we present Ultra Flash, a cascaded streaming framework capable of real-time high-resolution video generation. Ultra Flash achieves ~30 FPS at 1K resolution and ~18 FPS at 2K resolution on a single GPU through three key contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm coupled with an AIGC-oriented data degradation pipeline that effectively preserves the generative capability of the base model, enabling enhanced high-resolution detail when cascaded after mainstream low-resolution generative models; (2) a causal streaming latent upsampler paired with a high-resolution decoder, which enhances spatiotemporal coherence while enabling efficient latent spatial scaling and precise high-resolution decoding with negligible computational overhead; and (3) a cascade high-resolution streaming video generation optimization scheme that first performs hybrid-reward-enhanced sparse causalization and single-step distillation of the super-resolution model, then introduces cascaded streaming self-forcing preference optimization with dynamic cache management, jointly enhancing overall coherence, improving quality, and enabling real-time high-resolution streaming video generation. Extensive experiments demonstrate that Ultra Flash reliably produces ultra-high-resolution streaming video while maintaining state-of-the-art visual quality and superior efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Ultra Flash, a cascaded streaming framework for real-time high-resolution video generation from low-resolution T2V models. It claims ~30 FPS at 1K and ~18 FPS at 2K resolution on a single GPU with SOTA visual quality via three contributions: (1) an architecture-preserving T2V-to-TV2V super-resolution training paradigm with AIGC-oriented data degradation to preserve base model generative capability; (2) a causal streaming latent upsampler and high-resolution decoder for spatiotemporal coherence and efficient scaling; and (3) a cascade optimization scheme using hybrid-reward sparse causalization, single-step distillation, and cascaded streaming self-forcing preference optimization with dynamic cache management. Extensive experiments are said to support the efficiency and quality claims.
Significance. If the empirical results hold, this would be a meaningful advance in scaling autoregressive video diffusion models beyond low resolutions (e.g., 480P) to real-time high-res streaming, addressing a practical bottleneck. The architecture-preserving transfer and optimization techniques could be reusable in other cascaded systems. The reported single-GPU FPS figures, if substantiated with baselines and ablations, would represent a notable efficiency improvement. However, significance depends on verification of the key preservation assumption and quantitative support for the performance claims.
major comments (2)
- [Abstract / Contribution (1)] Abstract / Contribution (1): The claim that the T2V-to-TV2V paradigm 'effectively preserves the generative capability of the base model' is load-bearing for the cascaded real-time claim and the assertion of maintained SOTA quality. No side-by-side quantitative metrics (FVD, CLIP similarity, or streaming coherence scores) are supplied comparing the unmodified base low-resolution model to the cascaded Ultra Flash system on identical prompts. This omission leaves open whether the super-resolution stage maintains the original distribution or introduces degradation that later stages cannot fully offset.
- [Abstract / Contribution (3)] Abstract / Contribution (3): The optimization scheme relies on free parameters including hybrid-reward weights and distillation step count. The abstract reports no ablation studies, sensitivity analysis, or details on how these parameters were selected to achieve the stated ~30 FPS at 1K / ~18 FPS at 2K while preserving quality. This information is necessary to evaluate reproducibility and whether the performance numbers are robust.
minor comments (1)
- [Abstract] The abstract states performance claims and 'extensive experiments' but supplies no dataset details, baseline comparisons, error bars, or model size/hardware specifications beyond 'single GPU'. Adding these would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the preservation of generative capability and the optimization details. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / Contribution (1)] Abstract / Contribution (1): The claim that the T2V-to-TV2V paradigm 'effectively preserves the generative capability of the base model' is load-bearing for the cascaded real-time claim and the assertion of maintained SOTA quality. No side-by-side quantitative metrics (FVD, CLIP similarity, or streaming coherence scores) are supplied comparing the unmodified base low-resolution model to the cascaded Ultra Flash system on identical prompts. This omission leaves open whether the super-resolution stage maintains the original distribution or introduces degradation that later stages cannot fully offset.
Authors: We agree that explicit side-by-side quantitative comparisons would strengthen the preservation claim. The architecture-preserving training and AIGC-oriented degradation are designed to maintain the base distribution, as supported by the overall SOTA results in our experiments. In the revision we will add a dedicated comparison table reporting FVD and CLIP similarity on identical prompts for the unmodified base model versus the cascaded system. revision: yes
-
Referee: [Abstract / Contribution (3)] Abstract / Contribution (3): The optimization scheme relies on free parameters including hybrid-reward weights and distillation step count. The abstract reports no ablation studies, sensitivity analysis, or details on how these parameters were selected to achieve the stated ~30 FPS at 1K / ~18 FPS at 2K while preserving quality. This information is necessary to evaluate reproducibility and whether the performance numbers are robust.
Authors: The abstract is space-constrained and summarizes contributions at a high level. Full ablation studies on hybrid-reward weights, distillation step count, and sensitivity analysis appear in Section 4.3 and the supplementary material, where we also describe the selection process that yields the reported FPS while preserving quality. We will revise the abstract to include a one-sentence reference to these ablations for improved reproducibility. revision: partial
Circularity Check
No circularity; empirical architecture and optimization claims are self-contained
full rationale
The paper advances three engineering contributions—an architecture-preserving T2V-to-TV2V training paradigm with AIGC degradation, a causal latent upsampler, and a cascade optimization scheme—validated solely through experimental results on FPS, visual quality, and coherence. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs; the central claim that the paradigm preserves base-model generative capability is an empirical assertion, not a definitional or self-citation tautology. The manuscript contains no derivation chain, uniqueness theorems, or ansatzes smuggled via prior self-work that would trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- hybrid-reward weights
- distillation step count
axioms (1)
- domain assumption The base low-resolution T2V model already produces coherent streaming output that can be upscaled without retraining the entire generator.
Reference graph
Works this paper leans on
-
[1]
Wang, Xintao and Xie, Liangbin and Dong, Chao and Shan, Ying , booktitle=. Real-
-
[2]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
OmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
OmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation , author=. arXiv preprint arXiv:2605.12480 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer , author=. arXiv preprint arXiv:2408.06072 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
HunyuanVideo: A Systematic Framework For Large Video Generative Models , author=. arXiv preprint arXiv:2412.03603 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Movie Gen: A Cast of Media Foundation Models
Movie Gen: A Cast of Media Foundation Models , author=. arXiv preprint arXiv:2410.13720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2024 , note=
Video Generation Models as World Simulators , author=. 2024 , note=
2024
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
From Slow Bidirectional to Fast Autoregressive Video Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[9]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion , author=. arXiv preprint arXiv:2506.08009 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Causal Forcing: Autoregressive Diffusion Distillation Done Right for High-Quality Real-Time Interactive Video Generation , author=. arXiv preprint arXiv:2602.02214 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2601.20499 , year=
Efficient Autoregressive Video Diffusion with Dummy Head , author=. arXiv preprint arXiv:2601.20499 , year=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
One-step Diffusion with Distribution Matching Distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[13]
arXiv preprint arXiv:2405.14867 , year=
Improved Distribution Matching Distillation for Fast Image Synthesis , author=. arXiv preprint arXiv:2405.14867 , year=
-
[14]
arXiv preprint arXiv:2511.22677 , year=
Decoupled DMD: CFG Augmentation as the Spear, Distribution Matching as the Shield , author=. arXiv preprint arXiv:2511.22677 , year=
-
[15]
International Conference on Machine Learning (ICML) , year=
Consistency Models , author=. International Conference on Machine Learning (ICML) , year=
-
[16]
International Conference on Learning Representations (ICLR) , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. International Conference on Learning Representations (ICLR) , year=
-
[17]
FlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution , author=. arXiv preprint arXiv:2510.12747 , year=
-
[18]
Stream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion
Stream-DiffVSR: Low-Latency Streamable Video Super-Resolution via Auto-Regressive Diffusion , author=. arXiv preprint arXiv:2512.23709 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
VEnhancer: Generative Space-Time Enhancement for Video Generation , author=. arXiv preprint arXiv:2407.07667 , year=
-
[20]
Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[21]
Generating Long Sequences with Sparse Transformers
Generating Long Sequences with Sparse Transformers , author=. arXiv preprint arXiv:1904.10509 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
International Conference on Learning Representations (ICLR) , year=
Reformer: The Efficient Transformer , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
arXiv preprint arXiv:2502.18137 , year=
SpargeAttention: Accurate and Training-free Sparse Attention Accelerating Any Model Inference , author=. arXiv preprint arXiv:2502.18137 , year=
-
[24]
Block-Sparse Attention , author=
-
[25]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[26]
Advances in Neural Information Processing Systems (NeurIPS) , year=
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
VBench: Comprehensive Benchmark Suite for Video Generative Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Scalable Diffusion Models with Transformers , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
High-Resolution Image Synthesis with Latent Diffusion Models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[30]
Tiny Autoencoder for High-Resolution Video (
Ollin Boer Bohan , howpublished=. Tiny Autoencoder for High-Resolution Video (
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Video Diffusion Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[32]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning , author=. arXiv preprint arXiv:2307.04725 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets , author=. arXiv preprint arXiv:2311.15127 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir , journal=
-
[35]
Diffusion Models Are Real-Time Game Engines
Diffusion Models Are Real-Time Game Engines , author=. arXiv preprint arXiv:2408.14837 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Pyramidal Flow Matching for Efficient Video Generative Modeling , author=. arXiv preprint arXiv:2410.05954 , year=
-
[37]
arXiv preprint arXiv:2402.09470 , year=
Rolling Diffusion Models , author=. arXiv preprint arXiv:2402.09470 , year=
-
[38]
Kim, Jihwan and Kang, Junoh and Choi, Jinyoung and Han, Bohyung , journal=
-
[39]
arXiv preprint arXiv:2310.07702 , year=
ScaleCrafter: Tuning-free Higher-Resolution Visual Generation with Diffusion Models , author=. arXiv preprint arXiv:2310.07702 , year=
-
[40]
arXiv preprint arXiv:2311.16973 , year=
DemoFusion: Democratising High-Resolution Image Generation With No \ \ \ , author=. arXiv preprint arXiv:2311.16973 , year=
-
[41]
arXiv preprint arXiv:2403.02084 , year=
ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models , author=. arXiv preprint arXiv:2403.02084 , year=
-
[42]
arXiv preprint arXiv:2407.02158 , year=
UltraPixel: Advancing Ultra-High-Resolution Image Synthesis to New Peaks , author=. arXiv preprint arXiv:2407.02158 , year=
-
[43]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Seedance 1.0: Exploring the Boundaries of Video Generation Models , author=. arXiv preprint arXiv:2506.09113 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[45]
Reward Forcing: Efficient Streaming Video Generation with Rewarded Distribution Matching Distillation , author=. arXiv preprint arXiv:2512.04678 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation , author=. arXiv preprint arXiv:2510.02283 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
arXiv preprint arXiv:2502.05179 , year=
FlashVideo: Flowing Fidelity to Detail for Efficient High-Resolution Video Generation , author=. arXiv preprint arXiv:2502.05179 , year=
-
[48]
HunyuanVideo 1.5 Technical Report
HunyuanVideo 1.5: A Systematic Framework For Large Video Generative Models , author=. arXiv preprint arXiv:2511.18870 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
FSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space , author=. arXiv preprint arXiv:2602.02092 , year=
-
[50]
Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
LongCat-Video Technical Report , author=. arXiv preprint arXiv:2510.22200 , year=
-
[51]
arXiv preprint arXiv:2506.13691 , year=
UltraVideo: High-Quality UHD Video Dataset with Comprehensive Captions , author=. arXiv preprint arXiv:2506.13691 , year=
-
[52]
HaCohen, Yoav and Brazowski, Benny and Chiprut, Nisan and Bitterman, Yaki and Kvochko, Andrew and Berkowitz, Avishai and Shalem, Daniel and Lifschitz, Daphna and Moshe, Dudu and Porat, Eitan and Richardson, Eitan and Shiran, Guy and Chachy, Itay and Chetboun, Jonathan and Finkelson, Michael and Kupchick, Michael and Zabari, Nir and Guetta, Nitzan and Kotl...
-
[53]
Waver: Wave your way to lifelike video generation.arXiv preprint arXiv:2508.15761, 2025
Waver: Wave Your Way to Lifelike Video Generation , author=. arXiv preprint arXiv:2508.15761 , year=
-
[54]
arXiv preprint arXiv:2603.21986 , year=
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model , author=. arXiv preprint arXiv:2603.21986 , year=
-
[55]
Ke, Junjie and Wang, Qifei and Wang, Yilin and Milanfar, Peyman and Yang, Feng , booktitle=
-
[56]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[57]
and Loy, Chen Change , booktitle=
Wang, Jianyi and Chan, Kelvin C.K. and Loy, Chen Change , booktitle=. Exploring
-
[58]
2022 , eprint=
LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models , author=. 2022 , eprint=
2022
-
[59]
Scaling Laws of
Liu, Xiaoran and Yan, Hang and Zhang, Shuo and An, Chenxin and Qiu, Xipeng and Lin, Dahua , journal=. Scaling Laws of
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[61]
Towards Accurate Generative Models of Video: A New Metric & Challenges
FVD: A New Metric for Video Generation , author=. arXiv preprint arXiv:1812.01717 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.