SD-GRPO: Verifiable Segment Decomposition for Long-Form Vision-Language Generation
Pith reviewed 2026-06-28 10:29 UTC · model grok-4.3
The pith
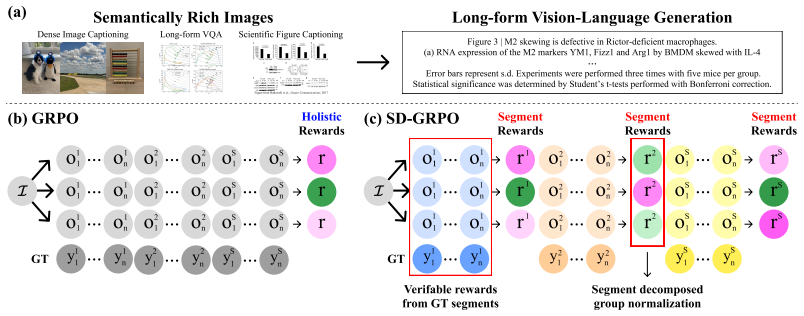
SD-GRPO replaces GRPO's single scalar advantage with a vector of per-segment advantages from z-normalized verifiable rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SD-GRPO z-normalizes verifiable per-segment rewards across the rollout group to yield a vector of per-segment advantages in place of a single scalar advantage, and this change consistently outperforms the GRPO baseline on long-form VL generation tasks, with blending of holistic and per-segment signals required when segments share context.
What carries the argument
The per-segment advantage vector obtained by z-normalizing verifiable rewards across the rollout group, which replaces the scalar advantage used in standard GRPO.
If this is right
- Gains from SD-GRPO increase with the number of segments on tasks where segments are semantically independent.
- Rollout-level rewards produce cross-segment credit misattribution that grows with output length.
- Blending holistic and per-segment rewards improves results when segments share context across the image.
- SD-GRPO can be added to any existing GRPO framework with only small code changes.
Where Pith is reading between the lines
- Automatic methods to discover segments could extend the approach to tasks that lack explicit divisions.
- The same per-segment normalization may reduce credit misattribution in other long-sequence reinforcement learning settings.
- Reward models for vision-language agents might benefit from explicit decomposition when outputs contain multiple verifiable parts.
Load-bearing premise
Long-form vision-language outputs possess a natural segmentation into parts for which independent verifiable rewards can be computed without substantial new labeling or modeling error.
What would settle it
An experiment on a long-form VL benchmark where per-segment rewards cannot be assigned independently would show no performance gain for SD-GRPO over GRPO if the central claim is false.
Figures
read the original abstract
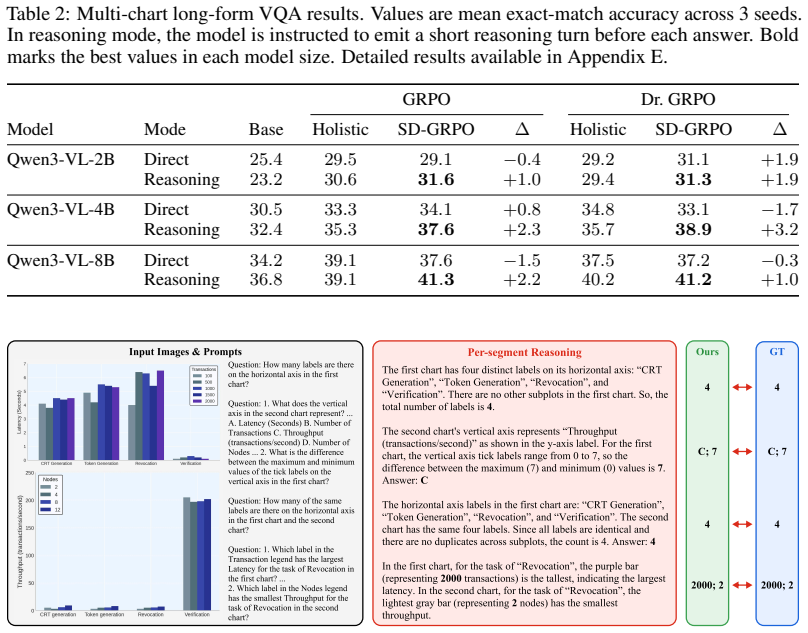
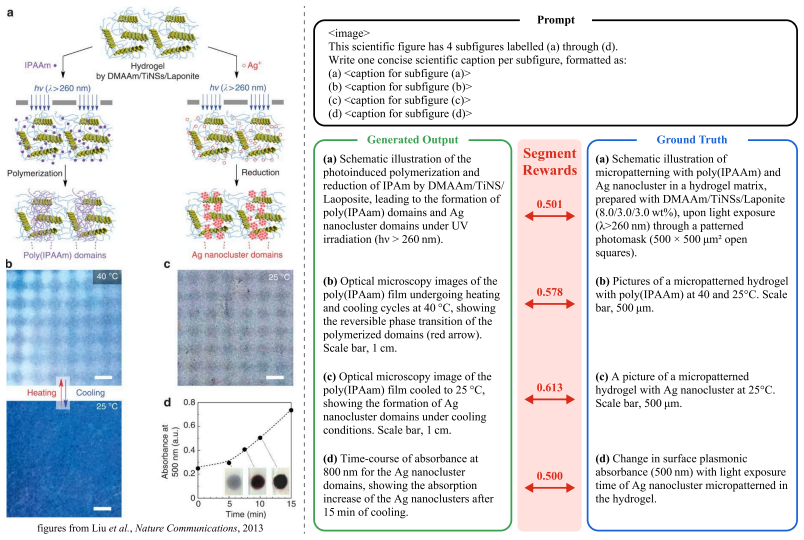
Group Relative Policy Optimization (GRPO) and its variants, originally developed for Large Language Models (LLMs), have recently been applied to Multimodal LLMs and produced strong results. However, their coarse-grained holistic credit assignment from a single scalar advantage underfits vision-language (VL) tasks, where outputs are often long-form responses grounded in semantically rich images. To address this limitation, we exploit a structured signal that single-scalar formulations discard: the natural segmentation of long-form VL outputs. Concretely, we propose Segment-Decomposed GRPO (SD-GRPO), which z-normalizes verifiable per-segment rewards across the rollout group, yielding a vector of per-segment advantages in place of a single scalar. We evaluate SD-GRPO across three settings spanning controlled and real-world long-form VL generation, organized by increasing semantic entanglement across segments. On a controlled multi-panel dense-captioning task constructed from DOCCI, where segments are semantically independent, SD-GRPO consistently outperforms the GRPO baseline, with larger gains at higher segment counts. Extending to a controlled multi-chart long-form VQA task constructed from MultiChartQA, we show both theoretically and empirically that rollout-level rewards suffer from cross-segment credit misattribution that scales with output length. On a real-world scientific figure captioning task on the MMSci dataset, where subfigure captions share context across the figure, blending holistic and per-segment rewards further improves on both, suggesting per-segment normalization alone is insufficient when segments are semantically entangled. Finally, by integrating SD-GRPO into Dr. GRPO, we confirm that it can be applied to any GRPO framework with minimal implementation overhead to enhance long-form VL generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Segment-Decomposed GRPO (SD-GRPO), which extends standard GRPO by z-normalizing verifiable per-segment rewards across a rollout group to produce a vector of per-segment advantages instead of a single scalar advantage. It evaluates the approach on three long-form VL tasks of increasing semantic entanglement: a controlled multi-panel captioning task from DOCCI (independent segments), a multi-chart VQA task from MultiChartQA (credit misattribution analyzed theoretically and empirically), and scientific figure captioning on MMSci (entangled subfigures requiring blending of holistic and per-segment rewards). The central claim is that SD-GRPO consistently outperforms GRPO baselines, with larger gains at higher segment counts on independent cases, and that the method integrates into existing GRPO frameworks such as Dr. GRPO with minimal overhead.
Significance. If the empirical gains and theoretical analysis of credit misattribution hold under scrutiny, the work offers a targeted improvement to credit assignment for long-form VL generation by exploiting natural output segmentation, a signal discarded by scalar-advantage methods. The low-overhead integration claim and the controlled-to-real-world progression of experiments are strengths that could make the technique broadly useful if the per-segment reward assumption generalizes.
major comments (2)
- [Abstract / MMSci evaluation] Abstract and MMSci evaluation: the statement that 'per-segment normalization alone is insufficient when segments are semantically entangled' and that blending with holistic rewards is required directly qualifies the central claim; if computing the per-segment rewards in such cases necessarily incorporates cross-segment context or additional modeling error, the resulting advantage vector no longer isolates the intended credit assignment, undermining consistent outperformance across the three settings of increasing entanglement.
- [MultiChartQA evaluation] MultiChartQA section: the theoretical claim that rollout-level rewards suffer from cross-segment credit misattribution that scales with output length is load-bearing for motivating the vector advantage; without the explicit derivation or equations showing how z-normalization removes this scaling (as opposed to merely reweighting it), the empirical outperformance cannot be attributed to the proposed mechanism rather than other implementation choices.
minor comments (2)
- [Abstract / Methods] The abstract refers to 'verifiable per-segment rewards' and 'semantically independent' segments without defining the reward functions or segmentation procedure; these should be specified with pseudocode or equations in the methods section to allow reproduction.
- [DOCCI evaluation] No mention of statistical significance, number of runs, or variance for the 'consistently outperforms' and 'larger gains at higher segment counts' claims on DOCCI; tables or figures reporting these quantities are needed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and note planned revisions.
read point-by-point responses
-
Referee: [Abstract / MMSci evaluation] Abstract and MMSci evaluation: the statement that 'per-segment normalization alone is insufficient when segments are semantically entangled' and that blending with holistic rewards is required directly qualifies the central claim; if computing the per-segment rewards in such cases necessarily incorporates cross-segment context or additional modeling error, the resulting advantage vector no longer isolates the intended credit assignment, undermining consistent outperformance across the three settings of increasing entanglement.
Authors: We disagree that the statement undermines the central claim. The manuscript structures its evaluation explicitly around increasing entanglement levels, showing SD-GRPO gains on independent segments and further gains from blending on entangled ones; this progression demonstrates the method's flexibility rather than a limitation. Per-segment rewards are derived from independent verifiable signals without cross-segment context in the reward computation, and blending is applied afterward as an optional adjustment. We will revise the abstract and MMSci discussion to explicitly state that the core per-segment advantage vector remains isolated even under blending. revision: partial
-
Referee: [MultiChartQA evaluation] MultiChartQA section: the theoretical claim that rollout-level rewards suffer from cross-segment credit misattribution that scales with output length is load-bearing for motivating the vector advantage; without the explicit derivation or equations showing how z-normalization removes this scaling (as opposed to merely reweighting it), the empirical outperformance cannot be attributed to the proposed mechanism rather than other implementation choices.
Authors: We agree that the theoretical section would benefit from greater explicitness. The current analysis derives the scaling of misattribution under scalar advantages and shows how per-segment z-normalization removes cross-segment terms, but we will expand the MultiChartQA section with the complete set of equations for the advantage computation and scaling behavior in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces SD-GRPO as an empirical algorithmic modification to GRPO: it defines per-segment advantages directly via z-normalization of verifiable rewards within rollout groups. No equations derive a result that reduces to the inputs by construction, no parameters are fitted on a subset and then renamed as predictions, and no self-citation chain or uniqueness theorem is invoked to force the method. Performance claims rest on direct comparisons against GRPO baselines across three external datasets (DOCCI, MultiChartQA, MMSci), with the segment-independence premise stated as an operating assumption rather than a derived necessity. The approach is therefore self-contained as a heuristic extension without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-form VL outputs admit segmentation into parts with independent verifiable rewards
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
METEOR: An automatic metric for MT evaluation with improved correlation with human judgments
Satanjeev Banerjee and Alon Lavie. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, 2005
2005
-
[3]
SciBERT: A pretrained language model for scientific text
Iz Beltagy, Kyle Lo, and Arman Cohan. SciBERT: A pretrained language model for scientific text. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3615–3620, 2019
2019
-
[4]
R1-v: Reinforcing super generalization ability in vision-language models with less than $3.https://github.com/Deep-Agent/R1-V, 2025
Liang Chen, Lei Li, Haozhe Zhao, Yifan Song, and Vinci. R1-v: Reinforcing super generalization ability in vision-language models with less than $3.https://github.com/Deep-Agent/R1-V, 2025
2025
-
[5]
Wu Fei, Hao Kong, Shuxian Liang, Yang Lin, Yibo Yang, Jing Tang, Lei Chen, and Xiansheng Hua. Self-guided process reward optimization with redefined step-wise advantage for process reinforcement learning.arXiv preprint arXiv:2507.01551, 2025
-
[6]
Group-in-group policy optimization for LLM agent training.Advances in Neural Information Processing Systems, 2025
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training.Advances in Neural Information Processing Systems, 2025
2025
-
[7]
Segmental advantage estimation: Enhancing ppo for long-context llm training
Xue Gong, Qi Yi, Ziyuan Nan, Guanhua Huang, Kejiao Li, Yuhao Jiang, Ruibin Xiong, Zenan Xu, Jiaming Guo, Shaohui Peng, et al. Segmental advantage estimation: Enhancing ppo for long-context llm training. arXiv preprint arXiv:2601.07320, 2026
-
[8]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Segment policy optimization: Effective segment- level credit assignment in RL for large language models.Advances in Neural Information Processing Systems, 2025
Yiran Guo, Lijie Xu, Jie Liu, Ye Dan, and Shuang Qiu. Segment policy optimization: Effective segment- level credit assignment in RL for large language models.Advances in Neural Information Processing Systems, 2025
2025
-
[10]
mTORC2 signalling regulates M2 macrophage differentiation in response to helminth infection and adaptive thermogenesis.Nature communications, 8(1):14208, 2017
RW Hallowell, SL Collins, JM Craig, Y Zhang, M Oh, PB Illei, Y Chan-Li, CL Vigeland, W Mitzner, AL Scott, et al. mTORC2 signalling regulates M2 macrophage differentiation in response to helminth infection and adaptive thermogenesis.Nature communications, 8(1):14208, 2017
2017
-
[11]
SciCap: Generating captions for scientific figures
Ting-Yao Hsu, C Lee Giles, and Ting-Hao Huang. SciCap: Generating captions for scientific figures. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 3258–3264, 2021
2021
-
[12]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaoshen Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.ArXiv, abs/2503.06749, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
2019
-
[15]
Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding.Advances in Neural Information Processing Systems, 37:3229– 3242, 2024
Xiang Li, Jian Ding, and Mohamed Elhoseiny. Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding.Advances in Neural Information Processing Systems, 37:3229– 3242, 2024
2024
-
[16]
Hybrid retrieval-generation reinforced agent for medical image report generation.Advances in neural information processing systems, 31, 2018
Yuan Li, Xiaodan Liang, Zhiting Hu, and Eric P Xing. Hybrid retrieval-generation reinforced agent for medical image report generation.Advances in neural information processing systems, 31, 2018
2018
-
[17]
Zekun Li, Xianjun Yang, Kyuri Choi, Wanrong Zhu, Ryan Hsieh, HyeonJung Kim, Jin Hyuk Lim, Sungyoung Ji, Byungju Lee, Xifeng Yan, et al. Mmsci: A dataset for graduate-level multi-discipline multimodal scientific understanding.arXiv preprint arXiv:2407.04903, 2024
-
[18]
Photolatently modulable hydrogels using unilamellar titania nanosheets as photocatalytic crosslinkers.Nature Communications, 4 (1):2029, 2013
Mingjie Liu, Yasuhiro Ishida, Yasuo Ebina, Takayoshi Sasaki, and Takuzo Aida. Photolatently modulable hydrogels using unilamellar titania nanosheets as photocatalytic crosslinkers.Nature Communications, 4 (1):2029, 2013. 10
2029
-
[19]
Improved image captioning via policy gradient optimization of spider
Siqi Liu, Zhenhai Zhu, Ning Ye, Sergio Guadarrama, and Kevin Murphy. Improved image captioning via policy gradient optimization of spider. InProceedings of the IEEE international conference on computer vision, pages 873–881, 2017
2017
-
[20]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
DOCCI: Descriptions of Connected and Contrasting Images
Yasumasa Onoe, Sunayana Rane, Zachary Berger, Yonatan Bitton, Jaemin Cho, Roopal Garg, Alexander Ku, Zarana Parekh, Jordi Pont-Tuset, Garrett Tanzer, et al. DOCCI: Descriptions of Connected and Contrasting Images. InEuropean Conference on Computer Vision, pages 291–309, 2024
2024
-
[23]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002
2002
-
[24]
Kirill Pavlenko, Alexander Golubev, Simon Karasik, and Boris Yangel. Blockwise advantage estimation for multi-objective rl with verifiable rewards.arXiv preprint arXiv:2602.10231, 2026
-
[25]
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Yi Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl.arXiv preprint arXiv:2503.07536, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Self-critical sequence training for image captioning
Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jerret Ross, and Vaibhava Goel. Self-critical sequence training for image captioning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7008–7024, 2017
2017
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
A picture is worth more than 77 text tokens: Evaluating clip-style models on dense captions
Jack Urbanek, Florian Bordes, Pietro Astolfi, Mary Williamson, Vasu Sharma, and Adriana Romero- Soriano. A picture is worth more than 77 text tokens: Evaluating clip-style models on dense captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26700– 26709, 2024
2024
-
[30]
Cider: Consensus-based image description evaluation
Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. Cider: Consensus-based image description evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4566–4575, 2015
2015
-
[31]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-Math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Bartscore: Evaluating generated text as text generation
Weizhe Yuan, Graham Neubig, and Pengfei Liu. Bartscore: Evaluating generated text as text generation. Advances in neural information processing systems, 34:27263–27277, 2021
2021
-
[33]
BERTScore: Evaluating Text Generation with BERT
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert.arXiv preprint arXiv:1904.09675, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[34]
Describe each panel
Zifeng Zhu, Mengzhao Jia, Zhihan Zhang, Lang Li, and Meng Jiang. MultiChartQA: Benchmarking vision-language models on multi-chart problems. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 11341–11359, 2025. 11 A Implemen...
2025
-
[35]
Accuracy – does each subfigure caption correctly describe what the reference describes (apparatus, conditions, observed effect, statistical claims)? Penalize hallucinated or contradicted claims
-
[36]
Completeness – does the candidate cover the salient information the reference covers for each subfigure?
-
[37]
accuracy
Fluency – is the candidate’s language scientific, concise, and 18 grammatical? Anchor points (use0.5steps between): -5.0near-publication-quality; matches the reference faithfully on this axis -4.0substantively correct, minor omissions or stylistic differences -3.0partially correct; salient details missing or slightly off -2.0multiple errors or substantial...
-
[38]
Accuracy – which candidate more correctly describes each subfigure as the reference does (apparatus, conditions, observed effect, statistical claims)? Penalize hallucinated or contradicted claims
-
[39]
Completeness – which candidate covers more of the salient information present in the reference for each subfigure?
-
[40]
Fluency – which candidate’s language is more scientific, concise, and grammatical? Also give an overall preference: which candidate, all axes considered, would you prefer as the published caption? Return ONLY a JSON object with these exact keys (each value one of "A", "B", "tie"): {"accuracy": "A|B|tie", "completeness": "A|B|tie", "fluency": "A|B|tie", "o...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.