Bypassing Copyright Protection in Diffusion-based Customization via Two-Stage Latent Feature Optimization
Pith reviewed 2026-06-27 19:38 UTC · model grok-4.3
The pith
Two-stage latent feature optimization restores disrupted mappings to bypass copyright defenses in diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Existing defenses primarily disrupt the mapping between input images and their latent representations in latent diffusion models. TS-LFO restores this mapping through a two-stage optimization: the Latent Denoising Stage enhances semantic consistency by minimizing the Latent-Image Alignment Loss and Latent Diffusion Loss with timestep-dependent weights to suppress high-frequency noise from defenses, while the Latent Reconstruction Stage recovers low-frequency semantic information using pixel-level constraints to refine the latent features, enabling the production of personalized outputs despite the protections.
What carries the argument
Two-Stage Latent Feature Optimization (TS-LFO), which performs a Latent Denoising Stage followed by a Latent Reconstruction Stage to restore the input-to-latent mapping broken by defense perturbations.
If this is right
- TS-LFO consistently bypasses state-of-the-art copyright defenses.
- TS-LFO outperforms prior attacks such as DiffPure, GrIDPure, and IMPRESS across diverse settings.
- The two-stage process enables effective copyright-stealing attacks on protected diffusion-based customization.
Where Pith is reading between the lines
- If defenses stay fixed, comparable optimization techniques could potentially transfer to other latent generative models.
- Defense designers may need to make perturbations responsive to multi-stage restoration attempts to stay ahead.
- Evaluating the method on additional diffusion architectures would test how broadly the mapping-restoration approach applies.
Load-bearing premise
Existing defenses primarily disrupt the mapping between input images and their latent representations in a manner that can be systematically restored by minimizing the described Latent-Image Alignment Loss and Latent Diffusion Loss without the defenses adapting to the attack.
What would settle it
A defense that is updated to detect and block the specific two-stage optimization process, after which TS-LFO no longer succeeds in restoring usable latent codes for personalized generation.
Figures



read the original abstract
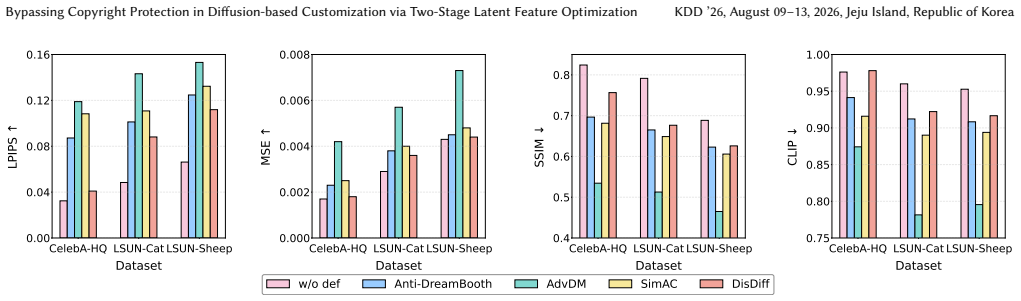
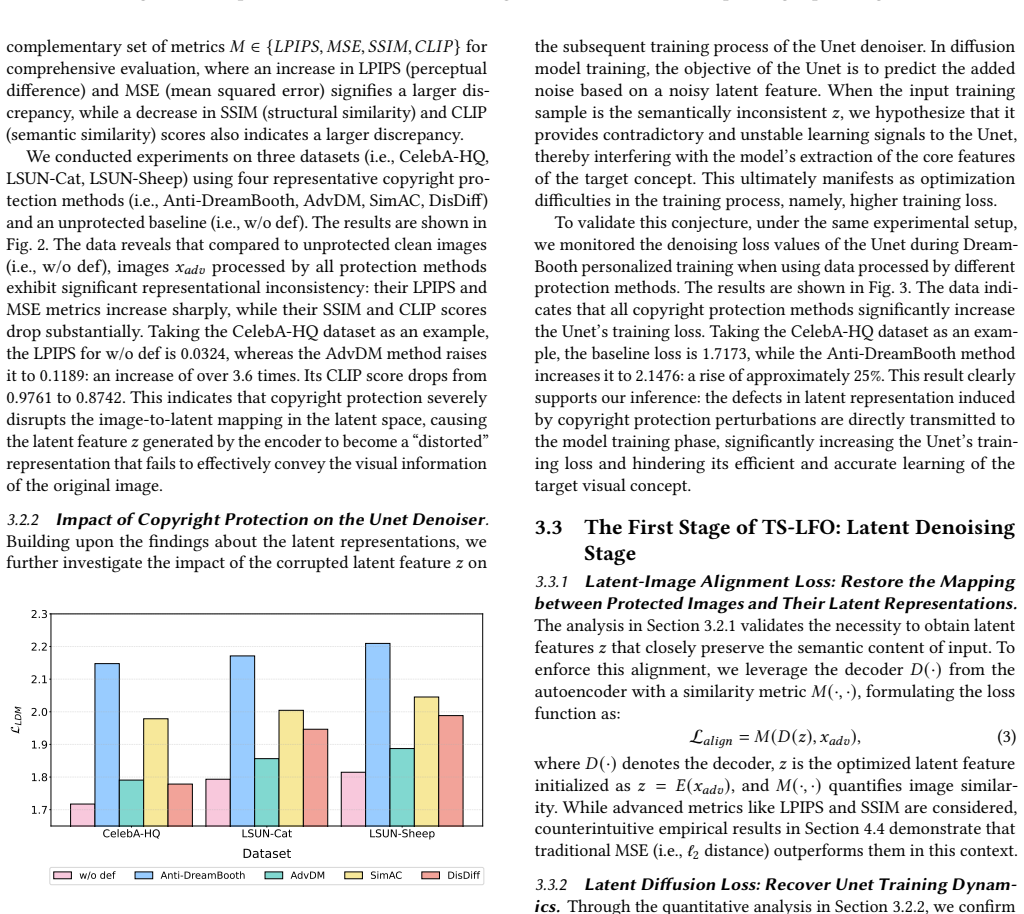
With the growing concerns over copyright infringement in diffusion-based customization, adversarial attacks have emerged as a prominent defense strategy to prevent malicious content forgery in personalized image generation. However, current defenses typically introduce persistent perturbations in the latent space of Latent Diffusion Models (LDMs), which remain susceptible to adaptive bypasses by adversaries. In this paper, we introduce Two-Stage Latent Feature Optimization (TS-LFO), an efficient and effective copyright-stealing attack against protected diffusion-based customization. We begin by observing that existing defenses primarily disrupt the mapping between input images and their latent representations, thereby degrading the model's ability to produce personalized outputs. To counteract this, TS-LFO restores the broken mapping through a two-stage optimization process. In the Latent Denoising Stage, we enhance semantic consistency between latent codes and input images by jointly minimizing a Latent-Image Alignment Loss and a Latent Diffusion Loss with timestep-dependent weights, effectively suppressing the high-frequency noise introduced by defenses. In the Latent Reconstruction Stage, we recover low-frequency semantic information using pixel-level constraints to refine the latent features. Extensive experiments show that TS-LFO consistently bypasses state-of-the-art (SOTA) copyright defenses and outperforms SOTA copyright attacks such as DiffPure, GrIDPure and IMPRESS across diverse settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Two-Stage Latent Feature Optimization (TS-LFO) to bypass copyright defenses in latent diffusion models for personalized image generation. It observes that defenses disrupt input-to-latent mappings and counters this via a Latent Denoising Stage (jointly minimizing Latent-Image Alignment Loss and timestep-weighted Latent Diffusion Loss to suppress high-frequency noise) followed by a Latent Reconstruction Stage (pixel-level constraints to recover low-frequency semantics). The abstract asserts that extensive experiments demonstrate consistent bypass of SOTA defenses and outperformance over DiffPure, GrIDPure, and IMPRESS across settings.
Significance. If the empirical results hold under the stated conditions, the work provides concrete evidence that existing adversarial perturbations in LDM latent spaces are invertible via the described two-stage losses, underscoring the need for adaptive or loss-aware defenses in copyright protection for diffusion customization. The explicit construction of the losses and the two-stage schedule constitute a clear, testable attack strategy.
major comments (2)
- [Abstract] Abstract and §3 (method description): the bypass claim is load-bearing on the assumption that defenses (DiffPure, GrIDPure, IMPRESS) remain fixed and do not incorporate knowledge of the Latent-Image Alignment Loss or the two-stage schedule; no experiments are described that test against defenses adapted to penalize these exact terms or alter the noise schedule accordingly.
- [Abstract] The manuscript provides no quantitative tables or figures in the supplied abstract, and the central outperformance claim cannot be evaluated without the reported metrics, datasets, and defense configurations; this prevents assessment of whether the two-stage optimization actually restores the mapping more reliably than baselines.
minor comments (1)
- Notation for the timestep-dependent weights and loss coefficients should be defined explicitly with their functional forms rather than left as free parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and §3 (method description): the bypass claim is load-bearing on the assumption that defenses (DiffPure, GrIDPure, IMPRESS) remain fixed and do not incorporate knowledge of the Latent-Image Alignment Loss or the two-stage schedule; no experiments are described that test against defenses adapted to penalize these exact terms or alter the noise schedule accordingly.
Authors: Our evaluation targets the published, fixed implementations of the cited SOTA defenses. The results establish that these existing protections are invertible under the proposed two-stage losses. Adaptive defenses that explicitly penalize the Latent-Image Alignment Loss or modify the noise schedule are not present in the current literature; constructing and evaluating such defenses constitutes a separate research direction. We will add a brief limitations paragraph acknowledging this scope in the revision. revision: partial
-
Referee: [Abstract] The manuscript provides no quantitative tables or figures in the supplied abstract, and the central outperformance claim cannot be evaluated without the reported metrics, datasets, and defense configurations; this prevents assessment of whether the two-stage optimization actually restores the mapping more reliably than baselines.
Authors: Abstracts are length-constrained and conventionally omit tables and figures. The full manuscript supplies the requested details in Section 4 (Tables 1–3 and Figures 3–6), reporting bypass rates, FID, LPIPS, and CLIP scores on CelebA-HQ and FFHQ under the exact defense configurations. We will revise the abstract to include two or three key numerical results (e.g., average bypass success rate and margin over baselines) to improve immediate evaluability. revision: yes
Circularity Check
No circularity; empirical attack method with independent experimental validation
full rationale
The paper describes an empirical two-stage optimization attack (TS-LFO) using Latent-Image Alignment Loss and timestep-weighted Latent Diffusion Loss, evaluated experimentally against external defenses (DiffPure, GrIDPure, IMPRESS). No equations, parameters, or claims reduce by construction to fitted inputs or self-citations. The central bypass result is supported by reported experiments rather than any self-referential derivation. This is a standard non-circular empirical security paper.
Axiom & Free-Parameter Ledger
free parameters (2)
- timestep-dependent weights
- loss coefficients for pixel-level constraints
axioms (1)
- domain assumption Existing defenses primarily disrupt the mapping between input images and their latent representations
Reference graph
Works this paper leans on
-
[1]
Blattmann, R
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis,Align your latents: High-resolution video synthesis with latent diffusion models, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22563–22575
2023
-
[2]
B. Cao, C. Li, T. W ang, J. Jia, B. Li, and J. Chen,Impress: Evaluating the resilience of imperceptible perturbations against unauthorized data usage in diffusion-based generative ai, Advances in Neural Information Processing Systems, 36 (2023), pp. 10657–10677
2023
-
[3]
H. Cao, C. Tan, Z. Gao, Y. Xu, G. Chen, P.-A. Heng, and S. Z. Li,A survey on gen- erative diffusion models, IEEE Transactions on Knowledge and Data Engineering, (2024)
2024
- [4]
-
[5]
Croitoru, V
F.-A. Croitoru, V. Hondru, R. T. Ionescu, and M. Shah,Diffusion models in vision: A survey, IEEE Transactions on Pattern Analysis and Machine Intelligence, 45 (2023), pp. 10850–10869
2023
-
[6]
J. Deng, J. Guo, E. Ververas, I. Kotsia, and S. Zafeiriou,Retinaface: Single-shot multi-level face localisation in the wild, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5203–5212
2020
-
[7]
J. Deng, J. Guo, N. Xue, and S. Zafeiriou,Arcface: Additive angular margin loss for deep face recognition, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4690–4699
2019
-
[8]
Esser, J
P. Esser, J. Chiu, P. Atighehchian, J. Granskog, and A. Germanidis,Structure and content-guided video synthesis with diffusion models, in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 7346–7356
2023
-
[9]
H. Fang, B. Chen, X. W ang, Z. W ang, and S.-T. Xia,Gifd: A generative gra- dient inversion method with feature domain optimization, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 4967–4976
2023
-
[10]
H. Fang, J. Kong, B. Chen, T. Dai, H. Wu, and S.-T. Xia,Clip-guided generative networks for transferable targeted adversarial attacks, in European Conference on Computer Vision, Springer, 2024, pp. 1–19
2024
-
[11]
H. Fang, J. Kong, W. Yu, B. Chen, J. Li, H. Wu, S.-T. Xia, and K. Xu,One perturbation is enough: On generating universal adversarial perturbations against vision-language pre-training models, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 4090–4100
2025
- [12]
- [13]
-
[14]
R. Gal, Y. Alaluf, Y. Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-or,An image is worth one word: Personalizing text-to-image generation using textual inversion, in The Eleventh International Conference on Learning Representations
-
[15]
R. Gal, Y. Alaluf, Y. Atzmon, O. Patashnik, A. H. Bermano, G. Chechik, and D. Cohen-Or,An image is worth one word: Personalizing text-to-image generation using textual inversion, arXiv preprint arXiv:2208.01618, (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, Gans trained by a two time-scale update rule converge to a local nash equilibrium, Advances in neural information processing systems, 30 (2017)
2017
-
[17]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
T. Karras, T. Aila, S. Laine, and J. Lehtinen,Progressive growing of gans for improved quality, stability, and variation, arXiv preprint arXiv:1710.10196, (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Kawar, S
B. Kawar, S. Zada, O. Lang, O. Tov, H. Chang, T. Dekel, I. Mosseri, and M. Irani,Imagic: Text-based real image editing with diffusion models, in Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6007–6017
2023
-
[19]
C. Liang, X. Wu, Y. Hua, J. Zhang, Y. Xue, T. Song, Z. Xue, R. Ma, and H. Guan, Adversarial example does good: Preventing painting imitation from diffusion models via adversarial examples, arXiv preprint arXiv:2302.04578, (2023)
-
[20]
X. Liu, D. H. Park, S. Azadi, G. Zhang, A. Chopikyan, Y. Hu, H. Shi, A. Rohrbach, and T. Darrell,More control for free! image synthesis with se- mantic diffusion guidance, in Proceedings of the IEEE/CVF winter conference on KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Ziang Xu et al. applications of computer vision, 2023, pp. 289–299
2026
-
[21]
Y. Liu, J. An, W. Zhang, D. Wu, J. Gu, Z. Lin, and W. W ang,Disrupting diffu- sion: Token-level attention erasure attack against diffusion-based customization, in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 3587–3596
2024
-
[22]
W. Nie, B. Guo, Y. Huang, C. Xiao, A. V ahdat, and A. Anandkumar,Diffu- sion models for adversarial purification, in International Conference on Machine Learning, PMLR, 2022, pp. 16805–16827
2022
-
[23]
DreamFusion: Text-to-3D using 2D Diffusion
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall,Dreamfusion: Text-to-3d using 2d diffusion, arXiv preprint arXiv:2209.14988, (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
R. Qiao, Q. Tan, P. Y ang, Y. W ang, X. W ang, E. W an, G. Dong, S. Lang, S. Zhou, Y. Xu, Y. Zeng, J. W ang, C. Sun, C. Li, and H. Zhang,We-math 2.0: A ver- satile mathbook system for incentivizing visual mathematical reasoning, in The Fourteenth International Conference on Learning Representations, 2026
2026
-
[25]
Y. Qiu, H. Fang, H. Yu, B. Chen, M. Qiu, and S.-T. Xia,A closer look at gan priors: Exploiting intermediate features for enhanced model inversion attacks, in European Conference on Computer Vision, Springer, 2024, pp. 109–126
2024
-
[26]
Y. Qiu, H. Yu, H. Fang, W. Yu, B. Chen, X. W ang, S.-T. Xia, and K. Xu,Mibench: A comprehensive benchmark for model inversion attack and defense, (2024)
2024
-
[27]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al.,Learning transferable visual models from natural language supervision, in International conference on machine learning, PmLR, 2021, pp. 8748–8763
2021
-
[28]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer,High-resolution image synthesis with latent diffusion models, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10684–10695
2022
-
[29]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox,U-net: Convolutional networks for biomedical image segmentation, in Medical image computing and computer- assisted intervention–MICCAI 2015: 18th international conference, Munich, Ger- many, October 5-9, 2015, proceedings, part III 18, Springer, 2015, pp. 234–241
2015
-
[30]
N. Ruiz, Y. Li, V. Jampani, Y. Pritch, M. Rubinstein, and K. Aberman,Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22500–22510
2023
-
[31]
Raising the cost of malicious ai-powered image editing.arXiv preprint arXiv:2302.06588, 2023
H. Salman, A. Khaddaj, G. Leclerc, A. Ilyas, and A. Madry,Raising the cost of malicious ai-powered image editing, arXiv preprint arXiv:2302.06588, (2023)
-
[32]
Takagi and S
Y. Takagi and S. Nishimoto,High-resolution image reconstruction with latent diffusion models from human brain activity, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 14453–14463
2023
-
[33]
Y. Tan, Y. Peng, H. Fang, B. Chen, and S.-T. Xia,Waterdiff: Perceptual image wa- termarks via diffusion model, in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2024, pp. 3250–3254
2024
-
[34]
V an Le, H
T. V an Le, H. Phung, T. H. Nguyen, Q. Dao, N. N. Tran, and A. Tran,Anti- dreambooth: Protecting users from personalized text-to-image synthesis, in Pro- ceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 2116–2127
2023
-
[35]
W ang, Z
F. W ang, Z. Tan, T. Wei, Y. Wu, and Q. Huang,Simac: A simple anti-customization method for protecting face privacy against text-to-image synthesis of diffusion models, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12047–12056
2024
-
[36]
W ang, C
Z. W ang, C. Chen, L. Lyu, D. N. Metaxas, and S. Ma,Diagnosis: Detecting unau- thorized data usages in text-to-image diffusion models, in The Twelfth International Conference on Learning Representations
-
[37]
H. Xiao, W. Yu, H. Fang, S. Sun, B. Chen, X. W ang, and S.-T. Xia,Diffusion-based natural adversarial perturbations towards segment anything model, in ICASSP 2026- 2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2026, pp. 13637–13641
2026
-
[38]
Y ang, Z
L. Y ang, Z. Zhang, Y. Song, S. Hong, R. Xu, Y. Zhao, W. Zhang, B. Cui, and M.-H. Y ang,Diffusion models: A comprehensive survey of methods and applications, ACM Computing Surveys, 56 (2023), pp. 1–39
2023
-
[39]
F. Yu, A. Seff, Y. Zhang, S. Song, T. Funkhouser, and J. Xiao,Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop, arXiv preprint arXiv:1506.03365, (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[40]
W. Yu, B. Chen, Q. Zhang, and S.-T. Xia,Editable-deepsc: cross-modal editable semantic communication systems, in 2024 IEEE 99th Vehicular Technology Con- ference (VTC2024-Spring), IEEE, 2024, pp. 1–5
2024
-
[41]
W. Yu, H. Fang, B. Chen, X. Sui, C. Chen, H. Wu, S.-T. Xia, and K. Xu,Gi-nas: Boosting gradient inversion attacks through adaptive neural architecture search, IEEE Transactions on Information Forensics and Security, (2025)
2025
-
[42]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. W ang,The unreasonable effectiveness of deep features as a perceptual metric, in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[43]
Zhang,A better autoencoder for image: Convolutional autoencoder, in ICONIP17-DCEC
Y. Zhang,A better autoencoder for image: Convolutional autoencoder, in ICONIP17-DCEC. Available online: http://users. cecs. anu. edu. au/Tom. Gedeon/conf/ABCs2018/paper/ABCs2018_paper_58. pdf (accessed on 23 March 2017), 2018
2017
-
[44]
Zhang, Y
Y. Zhang, Y. Huang, Y. Sun, C. Liu, Z. Zhao, Z. Fang, Y. W ang, H. Chen, X. Y ang, X. Wei, et al.,Multitrust: A comprehensive benchmark towards trustworthy multi- modal large language models, Advances in Neural Information Processing Systems, 37 (2024), pp. 49279–49383
2024
-
[45]
Which images are of the best quality and most similar to the reference (clean) image? Please select 2 to 4 images
Z. Zhao, J. Duan, K. Xu, C. W ang, R. Zhang, Z. Du, Q. Guo, and X. Hu,Can protective perturbation safeguard personal data from being exploited by stable diffusion?, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 24398–24407. A Algorithm of our method Our TS-LFO framework is outlined in Fig. 4. While the mai...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.