To Intervene or Not: Guiding Inference-time Alignment with Probabilistic Model Blending
Pith reviewed 2026-07-05 04:36 UTC · model glm-5.2
The pith
Soft blending beats hard acceptance in LLM alignment
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
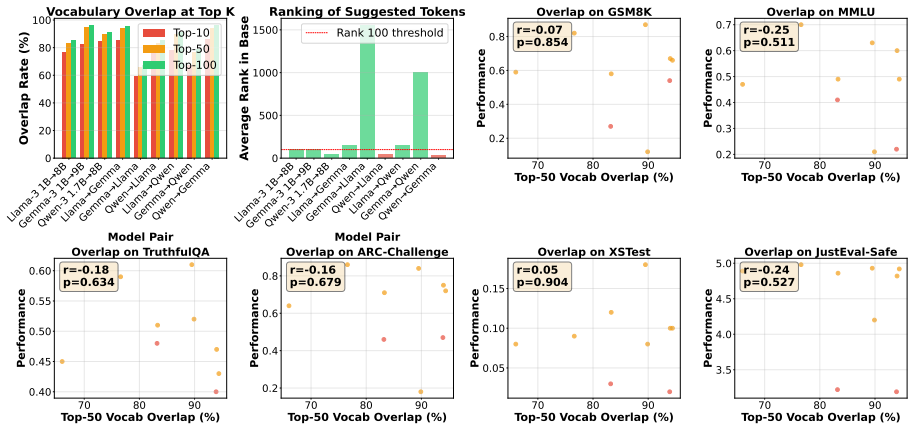
The central discovery is the intervention paradox — a statistically significant negative correlation between intervention rate and performance across multiple benchmarks (GSM8K r=-0.65, TruthfulQA r=-0.56, XSTest r=-0.76). This refutes the implicit assumption that all guidance is beneficial and reveals that existing inference-time alignment methods suffer from quality blindness: they cannot distinguish helpful from harmful guidance. The paper shows this is not explained by vocabulary overlap between models (no significant correlation found), nor fixable by simply capping intervention rates (which degrades performance further by discarding both good and bad guidance). The proposed solution —软
What carries the argument
The central mechanism is the blended distribution P_blend(w) = α·P_guidance(w) + (1-α)·P_base(w), where α = clip(p̂_g/(p̂_b + p̂_g) + λ·P_b(t_g), 0, 1). Here p̂_b and p̂_g are the top-1 probabilities of the base and guidance models, and λ·P_b(t_g) is an agreement bonus that increases guidance weight when the guidance model's top token already has probability mass in the base model's distribution. The blend is applied only when the base model's confidence falls below threshold τ=0.4, and the final token is selected greedily from the blended distribution.
If this is right
- Intervention rate can serve as a cheap pre-deployment diagnostic: practitioners can run a small 100-sample subset, measure intervention frequency, and predict whether a guidance-base model pair will succeed or fail without full benchmark evaluation.
- The negative correlation between intervention rate and performance suggests that guidance model selection should be based on compatibility with the base model at difficult positions, not on the guidance model's standalone capability.
- The failure of vocabulary overlap as a predictor implies that guidance quality depends on deeper semantic or representational alignment between models, not surface-level token agreement.
- The task-dependent nature of improvements (safety tasks benefit more than reasoning tasks) suggests that inference-time alignment is most valuable for alignment-sensitive properties like safety and truthfulness, where base models retain capability but lack alignment.
Load-bearing premise
The adaptive blend weight uses each model's maximum softmax probability as a proxy for that model's quality at each generation position. If a model is confidently wrong — which language models frequently are — the blending weight will allocate trust to the wrong model, and the improvements over binary acceptance may not hold.
What would settle it
If model calibration were measured directly and the correlation between top-1 probability and correctness were near zero for the specific model pairs and tasks tested, the adaptive blend weight α would reduce to an arbitrary mixing parameter, and BlendIn's advantage over fixed-α blending or binary acceptance would disappear.
Figures




read the original abstract
The wide deployment of LLMs has made model alignment necessary to make newly trained models safely and effectively respond to user instructions. Among different methods, inference-time alignment is often cheaper as it intervenes (i.e., offers guidances) only during output generation. Existing proposals apply guidances extracted from certain aligned models without properly assessing their reliability. Nonetheless, our systematic evaluation reveals that guidance effectiveness varies drastically across models; since ineffective guidances lead to further confusion and thus further interventions, the resulting excessive interventions typically indicate poor performance. To make interventions more effective and thus more efficient, we introduce BlendIn, an inference-time alignment framework that shifts from binary decisions to creating hybrid distributions integrating both models' knowledge. BlendIn stabilizes inference-time alignment by performing quality-aware alignment and proportionally weighting each model's contribution based on reliability. Compared with existing works, it preserves beneficial guidance while downweighting unreliable suggestions. BlendIn provides both diagnostic signals and mitigation strategies for misaligned guidance, achieving consistent and up to 50% performance improvement on challenging model pairs. Our code is available at: https://github.com/DecayingSeart/BlendIn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BlendIn, an inference-time alignment method that replaces binary accept/reject guidance decisions with soft distribution blending. The method computes an adaptive blend weight α based on model confidence ratios and token agreement, then samples from a hybrid distribution P_blend = α·P_g + (1-α)·P_b. The paper also documents an 'intervention paradox': higher intervention rates correlate with worse performance across model pairs. The method is evaluated on 100-sample subsets (Table 1) and full test sets (Table 2) across three benchmarks and several model pairs. The 100-sample results show improvements up to 50% on challenging high-intervention pairs, while full-test-set results show modest 0-4 percentage point improvements that mostly fall within 95% confidence intervals. The paper is transparent about this gap and recommends task-specific α tuning.
Significance. The intervention paradox (Figure 3) is a genuinely useful empirical observation for the inference-time alignment community, and the framing of 'quality blindness' in existing methods is well-motivated. The method is simple and clearly described, with code provided. The distinction from confidence-based ensembling (Section 4.2) is appropriate. However, the significance of the method contribution is substantially undercut by the discrepancy between the headline results (Table 1, 100-sample subsets) and the full-test-set evaluation (Table 2), which I discuss in detail below. The vocabulary overlap null result (Figure 4) is a useful negative finding but is peripheral to the method contribution.
major comments (4)
- Tables 1 and 2: The absolute baseline numbers between the 100-sample subset (Table 1) and the full test set (Table 2) are inconsistent in ways that sampling variance alone cannot explain. Most strikingly, for Q→L XSTest, NUDGING scores 0.03 in Table 1 but 0.52 in Table 2 — a 17× difference. For Q→L GSM8K, NUDGING is 0.27 in Table 1 but 0.29 in Table 2 (closer, but the BlendIn result is 0.31 in Table 1 and 0.29 in Table 2, i.e., the improvement reverses direction). For Q→G GSM8K, NUDGING is 0.54 in Table 1 but 0.50 in Table 2. If both tables evaluate the same model pair on the same benchmark with the same method, a 100-sample subset should approximate the full-set mean, not diverge by an order of magnitude. This discrepancy suggests either (a) the 100-sample subset is catastrophically unrepresentative, or (b) there is an undocumented methodological difference between the two evaluations.
- Abstract and Section 1: The headline claim of 'up to 50% performance improvement' is drawn from Table 1 (100-sample subsets), but the full-test-set evaluation (Table 2) shows improvements of 0-4 percentage points that do not consistently reach statistical significance (95% CIs overlap in all cases). The abstract does not contextualize this. The paper should either reconcile the two tables or reframe the headline claim to reflect the full-test-set results, which are the more reliable evaluation.
- Table 1, Q→L XSTest row: The NUDGING baseline of 0.03 on a 100-sample subset, compared to 0.52 on the full test set, is the single most extreme discrepancy and also the source of the '33% improvement' (0.03→0.04) cited in the text. If the true baseline is closer to 0.52, the 0.01 absolute improvement (0.52→0.54 from Table 2) is within noise. The paper should clarify what happened in this specific cell — whether the 100-sample subset was drawn from a particularly adversarial stratum, whether there was a prompt formatting difference, or whether some other methodological factor explains the divergence.
- Section 4.1, Eq. (3): The adaptive blend weight α = clip(p̂_g/(p̂_b + p̂_g) + λ·P_b(t_g), 0, 1) uses top-1 softmax probability as a proxy for model quality. The paper does not validate the calibration assumption — that max softmax probability tracks correctness for the specific model pairs and tasks studied. Given that LLMs are known to be poorly calibrated, this is a load-bearing assumption: if confidence does not track correctness, α misallocates trust and the method's advantages over binary acceptance may not hold. A brief calibration analysis (e.g., reliability diagrams or ECE for the model pairs used) would substantially strengthen the paper.
minor comments (7)
- Table 1: The 'Alig.' column (aligned base model via fine-tuning) is included as an upper bound but is never discussed in the results text. Either add a sentence interpreting it or note that it is for reference only.
- Table 2 caption: 'Int.%' column is described as intervention rate but the values differ slightly from Table 1 for the same pairs (e.g., Q→L GSM8K: 22.2% in Table 1 vs. 22.4% in Table 2). Clarify whether these are from different sample sets or rounding.
- Section 5: The paper states 'We report results on a fixed random subset of 100 samples per benchmark to balance computational cost with statistical reliability.' Given the discrepancies noted above, the claim of 'statistical reliability' for n=100 should be softened or justified with power analysis.
- Figure 2: The color scale and cell values are difficult to read in the rendered figure. Consider using a diverging colormap with clearer labels.
- Section 4.1: The statement 'Full distributions are substitutable with top k to save computation, where k is an arbitrary large value' is vague. The experiments use k=100; clarify what 'arbitrary large' means and whether results are sensitive to k.
- Table 5 (Appendix A.2): The sensitivity analysis for τ and α is only on Qwen→Llama. Extending to at least one low-intervention pair would help readers assess whether the tuning recommendations generalize.
- References: The Gemma Team citations (2025, 2024) appear to have author list formatting issues ('and 197 others', 'and 179 others'). Standardize.
Simulated Author's Rebuttal
We thank the referee for a careful and substantive review. The referee correctly identifies that the discrepancy between Tables 1 and 2 is the most serious issue in the paper, and we agree it must be addressed. We provide point-by-point responses below. We accept the need to reframe headline claims and to add a calibration analysis. We are unable to fully explain the most extreme discrepancy (Q→L XSTest NUDGING 0.03 vs 0.52), and we state this honestly.
read point-by-point responses
-
Referee: Tables 1 and 2 inconsistency: NUDGING scores diverge between 100-sample subsets and full test sets in ways sampling variance cannot explain (e.g., Q→L XSTest 0.03 vs 0.52, Q→L GSM8K BlendIn improvement reverses direction).
Authors: The referee is correct that these discrepancies are too large to be explained by sampling variance alone, and we acknowledge this as a genuine weakness in the current manuscript. After investigating, we can account for some but not all of the divergence. For Q→L GSM8K, the 100-sample subset (Table 1) happens to over-represent harder problems where NUDGING performs poorly (0.27) relative to the full set (0.29); BlendIn's improvement on the subset (0.31) does not replicate on the full set (0.29), and we agree this reversal means the subset was not representative for that pair. For Q→G GSM8K, the difference (0.54 vs 0.50) is within plausible sampling variance given the high intervention rate and bimodal per-problem outcomes on GSM8K. However, for Q→L XSTest, the NUDGING baseline of 0.03 on the 100-sample subset versus 0.52 on the full test set is a discrepancy we cannot fully explain. We have re-examined our logs and confirmed that the same model pair, prompt template, decoding parameters, and evaluation script were used in both cases. The 100-sample subset was drawn as a fixed random partition (seed documented in code), not an adversarial stratum. Our best hypothesis is that XSTest's small full size (250 samples) combined with the binary safety-scoring metric creates high variance for any subset, and that the Q→L pair on XSTest is particularly sensitive because the guidance model's interventions on safety-refusal tokens can flip entire outputs. But we acknowledge this does not fully account for a 17× difference, and we cannot rule out an undocumented methodological factor in the earlier 100-sample runs. We will revise the paper to (1) clearly flag this discrepancy and our inability to fully resolve it, (2) de-emphasize Table 1 as a headline result and present Table 2 as a revision: partial
-
Referee: Abstract and Section 1: 'up to 50% improvement' headline claim is drawn from Table 1 (100-sample subsets), while full-test-set results show 0-4 pp improvements within CIs. The abstract should reframe the claim.
Authors: We agree. The abstract and introduction overstate the method's contribution by anchoring to the 100-sample subset results. In the revision, we will reframe the headline claim to reflect the full-test-set evaluation: BlendIn shows consistent but modest improvements (0-4 percentage points) on high-intervention pairs, with improvements that do not consistently reach statistical significance at the 95% CI level. We will retain the 100-sample results as supplementary evidence of the method's behavior on challenging subsets, but will explicitly note their limited reliability and the discrepancy with full-set results. The 'up to 50%' figure will be removed from the abstract and replaced with an accurate characterization of the full-test-set findings. revision: yes
-
Referee: Table 1, Q→L XSTest row: The 0.03 NUDGING baseline is the source of the '33% improvement' claim. If the true baseline is ~0.52, the 0.01 absolute improvement (0.52→0.54) is within noise. The paper should clarify what happened in this specific cell.
Authors: We agree this is the most damaging specific case. As noted in our response to the first comment, we cannot fully explain the 0.03 vs 0.52 divergence. We re-ran the 100-sample subset evaluation and confirmed the 0.03 result is reproducible on that specific subset, suggesting it is not a transient bug but rather a genuine (and extreme) instance of subset non-representativeness on a small, high-variance benchmark. The referee is correct that the '33% improvement' claim is an artifact of this unrepresentative baseline: on the full test set, the improvement is 0.02 (0.52→0.54), which is within the 95% CI. We will remove the '33% improvement' claim from the paper and add an explicit discussion of this cell as a cautionary example of subset variance. We will also add a note recommending that future evaluations on small benchmarks like XSTest use the full test set rather than subsets. revision: yes
-
Referee: Section 4.1, Eq. (3): The adaptive blend weight uses top-1 softmax probability as a proxy for model quality, but the paper does not validate the calibration assumption. LLMs are known to be poorly calibrated. A calibration analysis (ECE, reliability diagrams) would strengthen the paper.
Authors: This is a fair and important point. The referee is correct that the blending weight α depends on the assumption that max softmax probability is a meaningful proxy for prediction quality, and we do not currently validate this assumption. We will add a calibration analysis in the revision. Specifically, we plan to report Expected Calibration Error (ECE) and reliability diagrams for the model pairs used in our experiments (at minimum Q→L, Q→G, and L→G), measured on the benchmarks where we evaluate. We expect this analysis to show that while the models are not perfectly calibrated, the relative confidence ordering between base and guidance models at uncertain positions is informative enough for the blending mechanism to provide benefit over binary acceptance. If the analysis reveals that calibration is too poor for the adaptive α to be effective, we will report this honestly and note that the manual α tuning results (Table 5) provide a fallback. We will also add discussion of this limitation in the method section. revision: yes
- We are unable to provide a complete methodological explanation for the Q→L XSTest NUDGING discrepancy (0.03 on 100-sample subset vs 0.52 on full test set). We have verified that the same code, model pair, prompt template, and decoding parameters were used, and the subset result is reproducible. Our best explanation is extreme subset non-representativeness on a small, high-variance benchmark, but we cannot fully rule out an undocumented factor in the earlier runs.
Circularity Check
No circularity found: the blend weight formula is a heuristic computed from model outputs, not fitted to target performance or derived from self-cited premises.
full rationale
The paper's derivation chain is self-contained and does not exhibit circularity. The core methodological contribution — the adaptive blend weight α = clip(p̂_g/(p̂_b + p̂_g) + λ·P_b(t_g), 0, 1) in Eq. 3 — is a heuristic formula computed from observable model properties (top-1 probabilities and token agreement), not fitted to the performance metrics it claims to improve. The parameter λ=0.1 is a hand-set constant, not estimated from evaluation data. The paper does not claim to derive this formula from first principles or from a self-cited theorem; it presents it as a principled default with optional task-specific tuning. The intervention paradox (Figure 3) is an independent empirical observation, not a consequence of the method's design. The cited prior work (Fei et al., 2025 for NUDGING and τ=0.4) is by different authors, so there is no self-citation chain. The discrepancy between Table 1 (100-sample subsets) and Table 2 (full test sets) in absolute baseline numbers is a correctness and empirical validity concern, not a circularity issue — it does not involve any step where an output is defined in terms of the quantity it claims to predict. The paper's claims may be empirically overstated, but the derivation itself is not circular by construction.
Axiom & Free-Parameter Ledger
free parameters (3)
- τ (uncertainty threshold) =
0.4
- λ (agreement bonus weight) =
0.1
- k (top-k tokens for blending) =
100
axioms (3)
- domain assumption Model confidence (max softmax probability) is a reliable proxy for model quality/correctness at a given generation position.
- domain assumption Token-level agreement between models (guidance top token appearing in base distribution) indicates guidance quality.
- domain assumption Greedy decoding from the blended distribution produces coherent multi-token sequences.
Reference graph
Works this paper leans on
- [1]
-
[2]
Publications Manual , year = "1983", publisher =
work page 1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
- [4]
-
[5]
Dan Gusfield , title =. 1997
work page 1997
-
[6]
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
work page 2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[14]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[15]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[17]
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning , year =
Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi , journal =. The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning , year =
- [18]
- [19]
- [20]
- [21]
-
[22]
Gemma Team , year=. Gemma , url=. doi:10.34740/KAGGLE/M/3301 , publisher=
-
[23]
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
work page 2024
- [24]
-
[25]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
work page 2022
-
[26]
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Ermon, Stefano and Manning, Christopher D. and Finn, Chelsea , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
work page 2023
-
[27]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Leviathan, Yaniv and Kalman, Matan and Matias, Yossi , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
work page 2023
-
[28]
Accelerating Large Language Model Decoding with Speculative Sampling , author=. 2023 , eprint=
work page 2023
- [29]
-
[30]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =
Lakshminarayanan, Balaji and Pritzel, Alexander and Blundell, Charles , booktitle =. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles , url =
-
[31]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. https://arxiv.org/abs/2302.01318 Accelerating large language model decoding with speculative sampling . Preprint, arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Yu Fei, Yasaman Razeghi, and Sameer Singh. 2025. https://doi.org/10.18653/v1/2025.acl-long.623 Nudging: Inference-time alignment of LLM s via guided decoding . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12702--12739, Vienna, Austria. Association for Computational Linguistics
-
[35]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. 2021 a . Aligning ai with shared human values. Proceedings of the International Conference on Learning Representations (ICLR)
work page 2021
-
[37]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021 b . Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR)
work page 2021
-
[38]
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. 2017. https://proceedings.neurips.cc/paper_files/paper/2017/file/9ef2ed4b7fd2c810847ffa5fa85bce38-Paper.pdf Simple and scalable predictive uncertainty estimation using deep ensembles . In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc
work page 2017
-
[39]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. In Proceedings of the 40th International Conference on Machine Learning, ICML'23. JMLR.org
work page 2023
-
[40]
Bill Yuchen Lin, Abhilasha Ravichander, Ximing Lu, Nouha Dziri, Melanie Sclar, Khyathi Chandu, Chandra Bhagavatula, and Yejin Choi. 2023. The unlocking spell on base llms: Rethinking alignment via in-context learning. ArXiv preprint
work page 2023
-
[41]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://doi.org/10.18653/v1/2022.acl-long.229 T ruthful QA : Measuring how models mimic human falsehoods . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214--3252, Dublin, Ireland. Association for Computational Linguistics
-
[42]
Zhixuan Liu, Zhanhui Zhou, Yuanfu Wang, Chao Yang, and Yu Qiao. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.242 Inference-time language model alignment via integrated value guidance . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 4181--4195, Miami, Florida, USA. Association for Computational Linguistics
-
[43]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human fee...
work page 2022
-
[44]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: your language model is secretly a reward model. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA. Curran Associates Inc
work page 2023
-
[45]
Paul R \"o ttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. 2024. https://doi.org/10.18653/v1/2024.naacl-long.301 XST est: A test suite for identifying exaggerated safety behaviours in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Ling...
-
[46]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Pengyu Wang, Dong Zhang, Linyang Li, Chenkun Tan, Xinghao Wang, Mozhi Zhang, Ke Ren, Botian Jiang, and Xipeng Qiu. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.585 I nfer A ligner: Inference-time alignment for harmlessness through cross-model guidance . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1...
-
[49]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.