TileFuse: A Fused Mixed-Precision Kernel Library for Efficient Quantized LLM Inference on AMD NPUs
Pith reviewed 2026-06-27 11:25 UTC · model grok-4.3
The pith
TileFuse runs AWQ on AMD NPUs cutting LLM prefilling latency by 2x
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
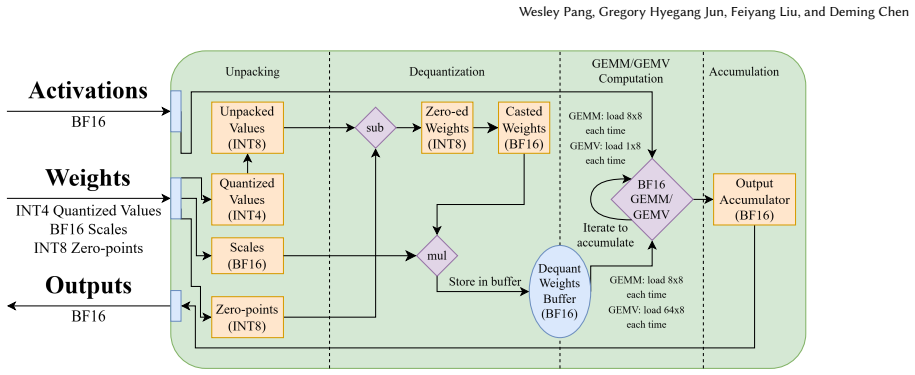
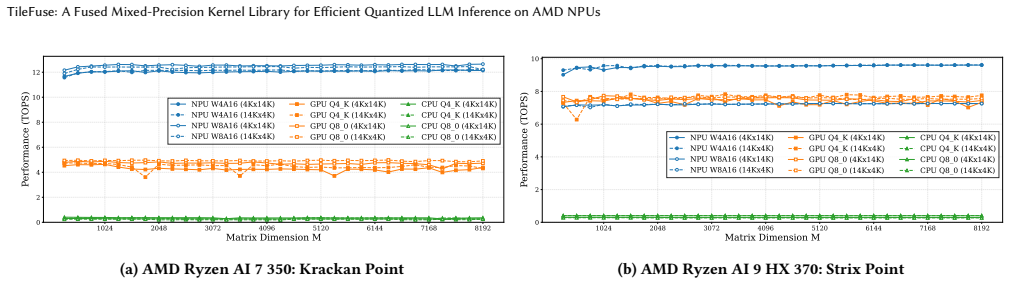
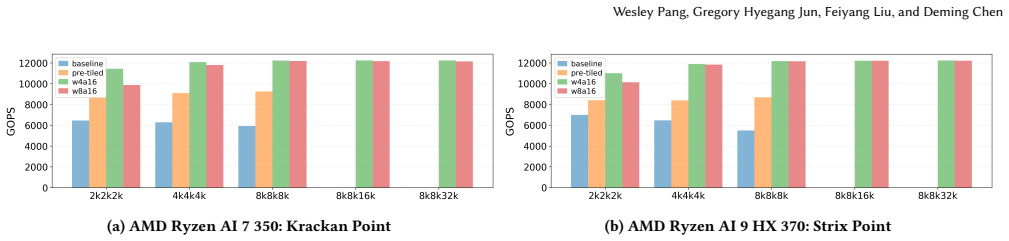
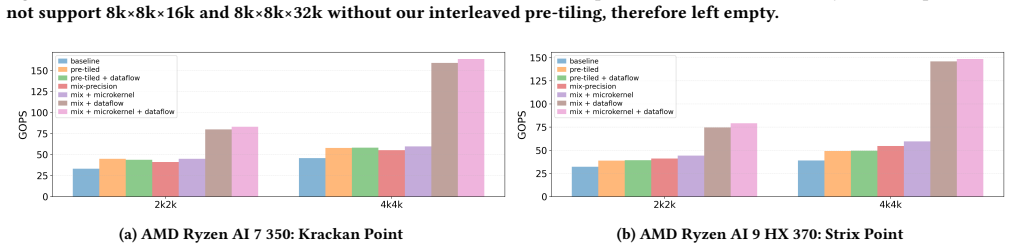
TileFuse brings practical low-bit formats such as AWQ-style W4A16 and W8A16 directly onto XDNA2 rather than forcing the model to be reshaped around an NPU-specific quantization scheme. It co-designs weight layout, metadata placement, mixed-precision microkernels, and array-level dataflow. It fuses unpacking, dequantization, and GEMM/GEMV execution into a single kernel flow, introduces an interleaved pre-tiling layout that supports GEMM dimensions up to 32K, and redesigns GEMV dataflow to utilize the full 4x8 AIE array. This results in up to 121.6% performance improvement for GEMM and 281% for GEMV over full-precision baselines, more than 2x gains over iGPU baselines, and in end-to-end LLM ex
What carries the argument
The fused mixed-precision kernel library that integrates weight layout, metadata placement, microkernels, and array-level dataflow to enable direct AWQ-style inference on XDNA2 NPUs.
Load-bearing premise
The interleaved pre-tiling layout and redesigned GEMV dataflow can fully utilize the 4x8 AIE array while fusing unpacking, dequantization, and GEMM without overheads that negate the gains, even with the proprietary NPU software stack.
What would settle it
Benchmark results where the AIE array utilization is significantly below capacity or where the fused kernel's overhead exceeds the reported performance improvements when executing AWQ-quantized models.
Figures

read the original abstract
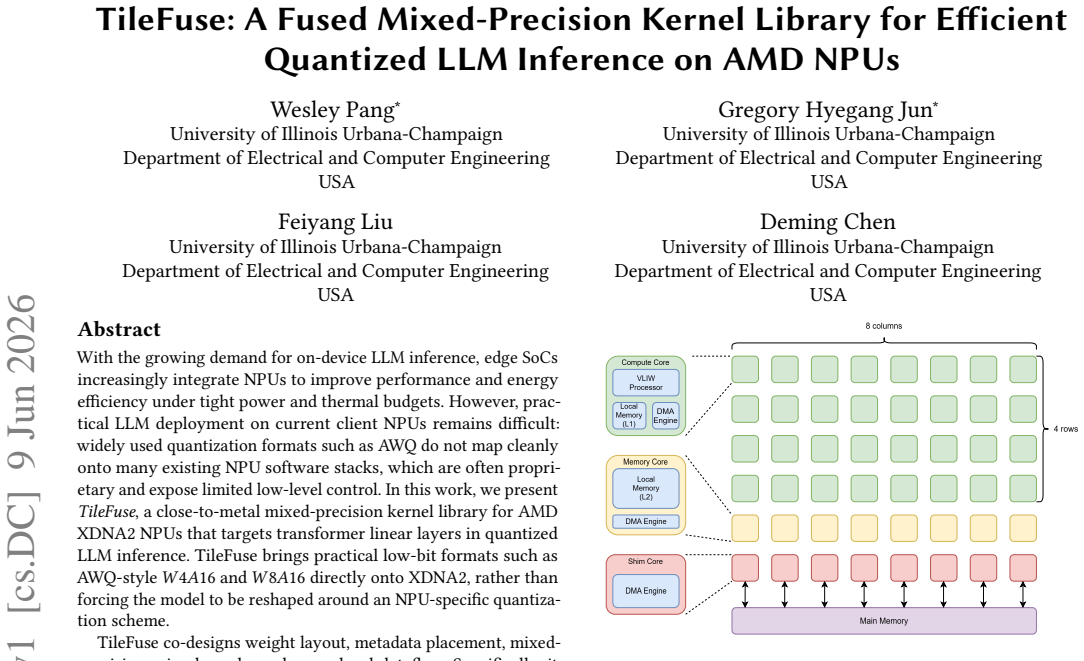
With the growing demand for on-device LLM inference, edge SoCs increasingly integrate NPUs to improve performance and energy efficiency under tight power and thermal budgets. However, practical LLM deployment on current client NPUs remains difficult: widely used quantization formats such as AWQ do not map cleanly onto many existing NPU software stacks, which are often proprietary and expose limited low-level control. In this work, we present \textit{TileFuse}, a close-to-metal mixed-precision kernel library for AMD XDNA2 NPUs that targets transformer linear layers in quantized LLM inference. TileFuse brings practical low-bit formats such as AWQ-style W4A16 and W8A16 directly onto XDNA2, rather than forcing the model to be reshaped around an NPU-specific quantization scheme. TileFuse co-designs weight layout, metadata placement, mixed-precision microkernels, and array-level dataflow. Specifically, it fuses unpacking, dequantization, and GEMM/GEMV execution into a single kernel flow, introduces an interleaved pre-tiling layout that supports GEMM dimensions up to 32K, and redesigns GEMV dataflow to utilize the full 4x8 AIE array. Across kernel-level evaluations, TileFuse improves performance by up to 121.6% for GEMM and 281% for GEMV over full-precision baselines, while delivering more than 2x performance and energy-efficiency gains over strong iGPU baselines on GEMM. In end-to-end LLM experiments on Ryzen AI laptops, TileFuse achieves up to 2.0x lower prefilling latency with more than 64.6% lower energy consumption. Together, these results show that XDNA2 is a practical target for AWQ-style edge LLM inference and that native NPU support for off-the-shelf quantization can make NPUs substantially more usable in real client deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TileFuse, a close-to-metal mixed-precision kernel library for AMD XDNA2 NPUs that enables AWQ-style W4A16 and W8A16 quantized LLM inference. It co-designs weight layout, metadata placement, microkernels, and array-level dataflow to fuse unpacking/dequantization with GEMM/GEMV, using an interleaved pre-tiling layout supporting up to 32K dimensions and a redesigned GEMV dataflow for full 4x8 AIE utilization. Kernel results show up to 121.6% GEMM and 281% GEMV improvement over full-precision baselines plus >2x gains over iGPU baselines; end-to-end experiments on Ryzen AI laptops report up to 2.0x lower prefilling latency and >64.6% lower energy.
Significance. If the measurements hold, the work demonstrates that off-the-shelf quantization formats can be supported efficiently on client NPUs without model reshaping, addressing a practical barrier to NPU usability for on-device LLMs. The co-design of layout, metadata, and dataflow for a proprietary stack provides a concrete template for similar hardware targets.
major comments (1)
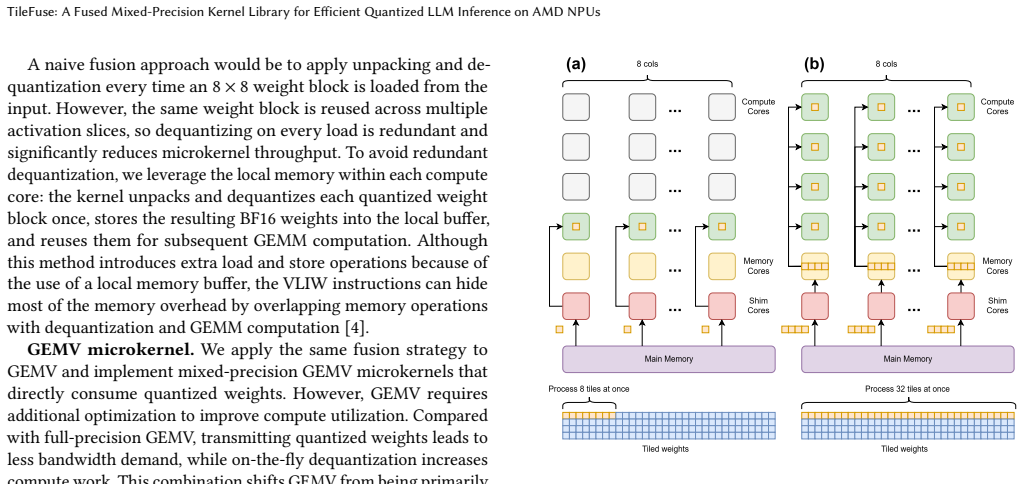
- [Experimental sections (kernel and end-to-end evaluations)] The central performance claims (kernel speedups of 121.6% GEMM / 281% GEMV and end-to-end 2.0x latency / 64.6% energy) rest on the assumption that the interleaved pre-tiling layout and redesigned GEMV dataflow achieve full 4x8 AIE utilization while fusing unpacking/dequantization/GEMM without net overhead from the proprietary XDNA2 stack. The manuscript provides no direct evidence (e.g., array utilization counters, memory-bandwidth breakdowns, or overhead isolation experiments) to rule out hidden costs in layout conversion or synchronization; without such data the headline numbers cannot be confirmed as net gains.
minor comments (2)
- [Abstract and §1] The abstract and introduction refer to 'strong iGPU baselines' without naming the specific device, driver version, or optimization level used for comparison.
- [Evaluation sections] No error bars, number of runs, or statistical methodology is mentioned for the reported latency and energy figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern regarding direct evidence for hardware utilization and net overheads in the fused kernels is valid and highlights an area where the experimental presentation can be strengthened. We address this point below and outline targeted revisions.
read point-by-point responses
-
Referee: [Experimental sections (kernel and end-to-end evaluations)] The central performance claims (kernel speedups of 121.6% GEMM / 281% GEMV and end-to-end 2.0x latency / 64.6% energy) rest on the assumption that the interleaved pre-tiling layout and redesigned GEMV dataflow achieve full 4x8 AIE utilization while fusing unpacking/dequantization/GEMM without net overhead from the proprietary XDNA2 stack. The manuscript provides no direct evidence (e.g., array utilization counters, memory-bandwidth breakdowns, or overhead isolation experiments) to rule out hidden costs in layout conversion or synchronization; without such data the headline numbers cannot be confirmed as net gains.
Authors: We agree that additional instrumentation would strengthen confidence in the net gains. Our reported numbers are wall-clock kernel execution times measured directly on Ryzen AI hardware under identical conditions for TileFuse and all baselines; any layout conversion, synchronization, or dequantization costs are therefore already embedded in the deltas. The interleaved pre-tiling layout is performed once offline and the GEMV dataflow redesign targets full 4x8 AIE occupancy by construction. Nevertheless, we will revise the experimental sections to add (1) memory-bandwidth utilization estimates derived from the available XDNA2 profiling interface and (2) an overhead-isolation micro-benchmark that measures the fused kernel against an equivalent non-fused sequence on the same hardware. We note that fine-grained per-AIE utilization counters are not exposed by the proprietary stack, limiting the granularity we can provide. revision: partial
- Direct per-AIE array utilization counters on the proprietary XDNA2 stack, which are not exposed by AMD's current tooling.
Circularity Check
No circularity: empirical kernel measurements with no derivations
full rationale
The paper is a systems/engineering contribution focused on co-designing layouts, metadata, microkernels, and dataflow for quantized GEMM/GEMV on proprietary AMD XDNA2 NPUs, with all claims supported by direct empirical measurements of latency, throughput, and energy on real hardware. No equations, mathematical derivations, parameter fitting, or predictions appear in the provided text or abstract. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatzes or renamings of known results are presented as novel derivations. The work is self-contained against external benchmarks via reported kernel and end-to-end timings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advanced Micro Devices, Inc. 2024. AMD XDNA Driver and Runtime Stack. https://github.com/amd/xdna-driver GitHub repository. Accessed: 2026-01-16
2024
-
[2]
2024.RDNA3.5 Instruction Set Architecture: Ref- erence Guide
Advanced Micro Devices, Inc. 2024.RDNA3.5 Instruction Set Architecture: Ref- erence Guide. Advanced Micro Devices, Inc. https://docs.amd.com/api/khub/ Wesley Pang, Gregory Hyegang Jun, Feiyang Liu, and Deming Chen documents/UVVZM22UN7tMUeiW_4ShTQ/content Document ID: 70649. Re- lease date: 2024-07-23. Accessed: 2026-01-16
2024
-
[3]
2025.AI Engine API User Guide (AIE-API) 2025.2 (UG1529)
Advanced Micro Devices, Inc. 2025.AI Engine API User Guide (AIE-API) 2025.2 (UG1529). Advanced Micro Devices, Inc. https://download.amd.com/docnav/ aiengine/xilinx2025_2/aiengine_api/aie_api/doc/index.html Accessed: 2026-01- 18
2025
-
[4]
Advanced Micro Devices, Inc. 2025. AI Engine Architecture Overview. InAI Engine Kernel and Graph Programming Guide. Number UG1079. https://docs.amd.com/r/en-US/ug1079-ai-engine-kernel-coding/AI-Engine- Architecture-Overview Version 2025.2 English. Release date: 2025-11-26. Accessed: 2026-01-18
2025
-
[5]
Advanced Micro Devices, Inc. 2025. Interface Considerations. InAI Engine Kernel and Graph Programming Guide. Number UG1079. https://docs.amd.com/r/en- US/ug1079-ai-engine-kernel-coding/Interface-Considerations Version 2025.2 English. Release date: 2025-11-26. Accessed: 2026-01-18
2025
-
[6]
AMD. [n. d.]. AMD XDNA Architecture. https://www.amd.com/en/technologies/ xdna.html
-
[7]
AMD. 2025. AMD Ryzen AI 7 350 Processor. https://www.amd.com/en/products/ processors/laptop/ryzen/ai-300-series/amd-ryzen-ai-7-350.html Accessed: 2026- 01-17
2025
-
[8]
AMD. 2025. AMD Ryzen AI 9 HX 370 Processor. https://www.amd.com/en/ products/processors/laptop/ryzen/ai-300-series/amd-ryzen-ai-9-hx-370.html Accessed: 2026-01-17
2025
-
[9]
AMD. 2026. OnnxRuntime GenAI (OGA) Flow — Ryzen AI Software. https: //ryzenai.docs.amd.com/en/latest/hybrid_oga.html. Accessed: 2026-03-23
2026
-
[10]
Anthropic. 2025. Claude Code. https://www.anthropic.com. AI coding assistant built on Claude; accessed 31 Jul 2025
2025
-
[11]
Apple. [n. d.]. The Most Powerful Neural Engine Ever. https://www.apple.com/ newsroom/2024/05/apple-introduces-m4-chip
2024
-
[12]
Apple. 2026. Core ML | Apple Developer Documentation. https://developer.apple. com/documentation/coreml. Accessed: 2026-03-23
2026
-
[13]
Le Chen, Dahu Feng, Erhu Feng, Yingrui Wang, Rong Zhao, Yubin Xia, Pinjie Xu, and Haibo Chen. 2025. Characterizing Mobile SoC for Accelerating Het- erogeneous LLM Inference. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles(Lotte Hotel World, Seoul, Republic of Korea) (SOSP ’25). Association for Computing Machinery, New York, ...
-
[14]
Dimitrios Danopoulos, Enrico Lupi, Chang Sun, Sebastian Dittmeier, Michael Kagan, Vladimir Loncar, and Maurizio Pierini. 2025. AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines.arXiv preprint arXiv:2512.15946(2025). https://arxiv.org/abs/2512.15946
arXiv 2025
-
[15]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.arXiv preprint arXiv:2307.08691(2023)
Pith/arXiv arXiv 2023
-
[16]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.arXiv preprint arXiv:2208.07339(2022)
Pith/arXiv arXiv 2022
-
[17]
Shouyu Du, Miaoxiang Yu, Zhenyu Xu, Zhiheng Ni, Jillian Cai, Qing Yang, and Tao Wei. 2026. Mapping Gemma3 onto an Edge Dataflow Architecture.arXiv preprint arXiv:2602.06063(2026). https://arxiv.org/abs/2602.06063
arXiv 2026
-
[18]
FastFlowLM. 2026. FastFlowLM. https://github.com/FastFlowLM/FastFlowLM. GitHub repository, accessed 2026-04-04
2026
-
[19]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. InThe International Conference on Learning Representations (ICLR). https://arxiv. org/abs/2210.17323
Pith/arXiv arXiv 2023
-
[20]
Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh
Elias Frantar, Roberto L. Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh
-
[21]
https://arxiv.org/abs/ 2408.11743
MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models.arXiv preprint arXiv:2408.11743(2024). https://arxiv.org/abs/ 2408.11743
arXiv 2024
-
[22]
2023.llama.cpp: Port of Facebook’s LLaMA Model in C/C++
Georgi Gerganov and contributors. 2023.llama.cpp: Port of Facebook’s LLaMA Model in C/C++. https://github.com/ggml-org/llama.cpp Software repository
2023
-
[23]
Google. [n. d.]. Gemma. https://deepmind.google/models/gemma
-
[24]
Google DeepMind. 2026. Gemma 4 Model Card. https://ai.google.dev/gemma/ docs/core/model_card_4. Google AI for Developers, accessed 2026-04-13
2026
-
[25]
Jyothi Hariharan, Rahul Rama Varior, and Sunil Karunakaran. 2023. Real-time Driver Monitoring Systems on Edge AI Device.arXiv preprint arXiv:2304.01555 (2023). doi:10.48550/arXiv.2304.01555
-
[26]
Erika Hunhoff, Joseph Melber, Kristof Denolf, Andra Bisca, Samuel Bayliss, Stephen Neuendorffer, Jeff Fifield, Jack Lo, Pranathi Vasireddy, Phil James-Roxby, and Eric Keller. 2025. Efficiency, Expressivity, and Extensibility in a Close-to- Metal NPU Programming Interface. arXiv:2504.18430 [cs.SE] https://arxiv.org/ abs/2504.18430
arXiv 2025
-
[27]
Intel. [n. d.]. Quick overview of Intel’s Neural Processing Unit (NPU). https: //intel.github.io/intel-npu-acceleration-library/npu.html
-
[28]
2025.OpenVINO GenAI on NPU: Inference and Weight Com- pression Guide
Intel Corporation. 2025.OpenVINO GenAI on NPU: Inference and Weight Com- pression Guide. https://docs.openvino.ai/2025/openvino-workflow-generative/ inference-with-genai/inference-with-genai-on-npu.html Accessed: 2026-01-16
2025
-
[29]
Iwan Kawrakow. 2023. K-Quants: Hierarchical 4-bit Quantization for llama.cpp. https://github.com/ggerganov/llama.cpp/pull/1684. Accessed: 2026-01-16
2023
-
[30]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. OpenVLA: An Open-Source Vision- Language-Action Model.arXiv preprint arXiv:2406.0...
Pith/arXiv arXiv 2024
-
[31]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Chen Wang, Wei-Ming Chen, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2023. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. arXiv preprint arXiv:2306.00978(2023)
Pith/arXiv arXiv 2023
-
[32]
Yujun Lin, Haotian Tang, Shang Yang, Zhekai Zhang, Guangxuan Xiao, Chuang Gan, and Song Han. 2024. QServe: W4A8KV4 Quantization and System Co- design for Efficient LLM Serving.arXiv preprint arXiv:2405.04532(2024). https: //arxiv.org/abs/2405.04532
arXiv 2024
-
[33]
Liu et al
J. Liu et al. 2025. Fast On-device LLM Inference with NPUs. InProceedings of ASPLOS
2025
-
[34]
OpenAI. 2023. ChatGPT. https://openai.com/chatgpt. Large-language-model conversational agent; accessed 31 Jul 2025
2023
-
[35]
OpenAI. 2023. GPT-4 Technical Report. (2023). arXiv:2303.08774 [cs.CL] https: //arxiv.org/abs/2303.08774
Pith/arXiv arXiv 2023
-
[36]
2023.Khan Academy
OpenAI. 2023.Khan Academy. https://openai.com/index/khan-academy/ An- nounces GPT-4 powering Khanmigo as a tutor and classroom assistant
2023
-
[37]
OpenVINO Documentation. 2025. NPU Device. https://docs.openvino.ai/2025/ openvino-workflow/running-inference/inference-devices-and-modes/npu- device.html Accessed: 2026-01-18
2025
-
[38]
OWON Technology. 2026. OWON SPE Series 1 CH 100W–300W DC Power Supply. https://www.owon.com.hk/products_owon_spe_series_1_ch_100w- 300w_dc_power_supply. Product page, accessed 2026-04-03
2026
-
[39]
Physical Intelligence, Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ur...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164 2024
-
[40]
Qualcomm. [n. d.]. A new era of possibility with on-device AI. https://www. qualcomm.com/products/technology/artificial-intelligence
-
[41]
2025.Qualcomm AI Engine Direct SDK
Qualcomm Technologies, Inc. 2025.Qualcomm AI Engine Direct SDK. Qualcomm Technologies, Inc. https://developer.qualcomm.com Accessed: 2025-05-16
2025
-
[42]
Qualcomm Technologies, Inc. 2026. Qualcomm AI Engine Direct SDK Documen- tation. https://docs.qualcomm.com/nav/home/QNN_general_overview.html? product=1601111740009302. Accessed: 2026-03-23
2026
-
[43]
Alejandro Rico, Satyaprakash Pareek, Javier Cabezas, David Clarke, Baris Özgül, Francisco Barat, Yao Fu, Stephan Münz, Dylan Stuart, Patrick Schlangen, Pedro Duarte, Sneha Date, Indrani Paul, Jian Weng, Sonal Santan, Vinod Kathail, Ashish Sirasao, and Juanjo Noguera. 2024. AMD XDNA NPU in Ryzen AI Processors. IEEE Micro44, 6 (2024), 73–82. doi:10.1109/MM....
-
[44]
Yushan Siriwardhana, Pawani Porambage, Madhusanka Liyanage, and Mika Ylianttila. 2021. A Survey on Mobile Augmented Reality With 5G Mobile Edge Computing: Architectures, Applications, and Technical Aspects.IEEE Commu- nications Surveys & Tutorials23, 2 (2021), 1160–1192. doi:10.1109/COMST.2021. 3061981
-
[45]
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. 2024. PowerInfer: Fast Large Language Model Serving with a Consumer-grade GPU. InProceedings of the 30th ACM Symposium on Operating Systems Principles. 590–606. doi:10.1145/ 3694715.3695964
arXiv 2024
-
[46]
Zhiyi Song et al . 2018. Computation Error Analysis of Block Floating Point Arithmetic Oriented Convolution Neural Network Accelerator Design. InAAAI Conference on Artificial Intelligence
2018
-
[47]
Nazish Tahir and Ramviyas Parasuraman. 2025. Edge Computing and its Application in Robotics: A Survey.arXiv preprint arXiv:2507.00523(2025). doi:10.48550/arXiv.2507.00523
-
[48]
Endri Taka, Aman Arora, Kai-Chiang Wu, and Diana Marculescu. 2023. MaxEVA: Maximizing the Efficiency of Matrix Multiplication on Versal AI Engine.arXiv preprint arXiv:2311.04980(2023). https://arxiv.org/abs/2311.04980
arXiv 2023
-
[49]
Endri Taka, Andre Roesti, Joseph Melber, Pranathi Vasireddy, Kristof Denolf, and Diana Marculescu. 2025. Striking the Balance: GEMM Performance Optimization Across Generations of Ryzen AI NPUs.arXiv preprint arXiv:2512.13282(2025). https://arxiv.org/abs/2512.13282
arXiv 2025
-
[50]
Chengyue Wang, Wesley Pang, Xinrui Wu, Gregory Jun, Luis Romero, Endri Taka, Diana Marculescu, Tony Nowatzki, Pranathi Vasireddy, Joseph Melber, Deming Chen, and Jason Cong. 2025. Can Asymmetric Tile Buffering Be Beneficial? arXiv:2511.16041 [cs.DC] https://arxiv.org/abs/2511.16041
arXiv 2025
-
[51]
Erwei Wang, Samuel Bayliss, Andra Bisca, Zachary Blair, Sangeeta Chowdhary, Kristof Denolf, Jeff Fifield, Brandon Freiberger, Erika Hunhoff, Phil James-Roxby, Jack Lo, Joseph Melber, Stephen Neuendorffer, Eddie Richter, Andre Rosti, Javier TileFuse: A Fused Mixed-Precision Kernel Library for Efficient Quantized LLM Inference on AMD NPUs Setoain, Gagandeep...
arXiv 2025
-
[52]
Xubin Wang, Zhiqing Tang, Jianxiong Guo, Tianhui Meng, Chenhao Wang, Tian Wang, and Weijia Jia. 2025. Empowering Edge Intelligence: A Comprehensive Survey on On-Device AI Models.Comput. Surveys57, 9 (2025), 1–39. doi:10. 1145/3724420
2025
-
[53]
Leann: A low-storage vector index.arXiv preprint arXiv:2506.08276, 2025
Yichuan Wang, Zhifei Li, Shu Liu, Yongji Wu, Ziming Mao, Yilong Zhao, Xiao Yan, Zhiying Xu, Yang Zhou, Ion Stoica, Sewon Min, Matei Zaharia, and Joseph E. Gon- zalez. 2025. LEANN: A Low-Storage Vector Index.arXiv preprint arXiv:2506.08276 (2025). doi:10.48550/arXiv.2506.08276
-
[54]
Zijie J. Wang and Duen Horng Chau. 2024. MeMemo: On-device Retrieval Augmentation for Private and Personalized Text Generation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. doi:10.1145/3626772.3657662
-
[55]
Zhenliang Xue, Yixin Song, Zeyu Mi, Xinrui Zheng, Yubin Xia, and Haibo Chen
-
[56]
arXiv preprint arXiv:2406.06282(2024)
PowerInfer-2: Fast Large Language Model Inference on a Smartphone. arXiv preprint arXiv:2406.06282(2024). https://arxiv.org/abs/2406.06282
arXiv 2024
-
[57]
Li Yang, Wei Zhang, and Xinyu Chen. 2025. Scaling LLM Test-Time Compute with Mobile NPU on Smartphones.arXiv preprint arXiv:2509.23324(2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.