AVIS: Adaptive Test-Time Scaling for Vision-Language Models
Pith reviewed 2026-06-27 10:45 UTC · model grok-4.3
The pith
AVIS jointly adapts visual context and reasoning scaling per query to improve accuracy-compute trade-off in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
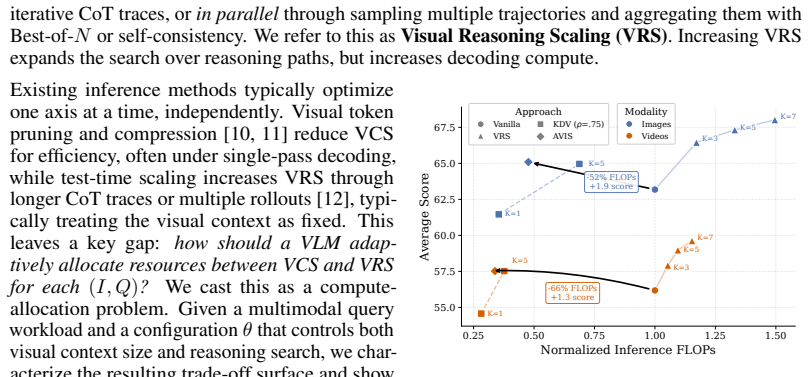
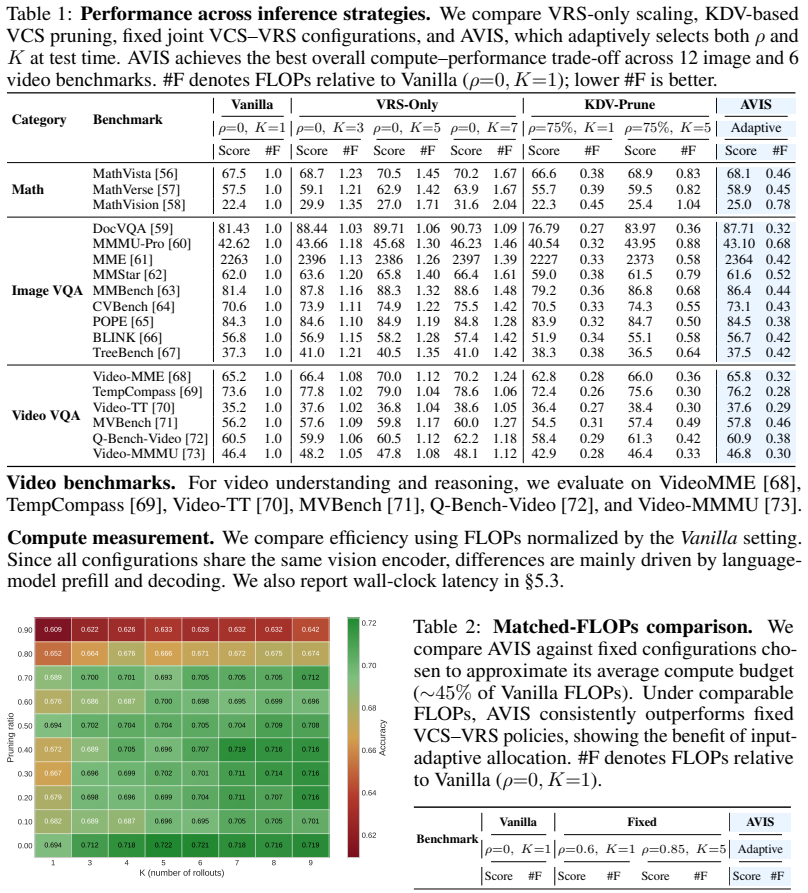
AVIS realizes Visual Context Scaling through Key Diversity Visual pruning, an O(N) rule that removes redundant visual tokens before the language model sees them, and realizes Visual Reasoning Scaling through adaptive self-consistency driven by a learned difficulty predictor that selects the number of rollouts. The design keeps all rollouts on a shared KV cache. Across image and video reasoning benchmarks this joint adaptation produces a better accuracy-compute curve than either VCS-only or VRS-only baselines and continues to help on RL post-trained VLMs.
What carries the argument
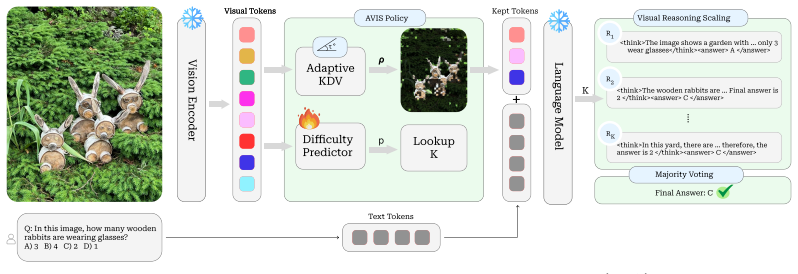
Adaptive Visual Inference Scaling (AVIS) policy that couples Key Diversity Visual (KDV) pruning for Visual Context Scaling with a learned difficulty predictor for Visual Reasoning Scaling.
If this is right
- AVIS yields higher accuracy at the same compute budget than methods that scale only visual context or only reasoning steps.
- The gains hold on top of models that have already received reinforcement-learning post-training.
- Shared-prefill compatibility keeps added latency and memory low because every rollout reuses one KV cache.
- KDV pruning is training-free and linear in the number of visual tokens, so it adds negligible cost.
Where Pith is reading between the lines
- Similar predictor-plus-pruning logic could be tested on long-context language models where context length and search depth are the two main cost drivers.
- The difficulty signal might be reused to gate other test-time techniques such as tool use or external retrieval.
- If the predictor is small enough, it could be distilled into the base VLM to remove the separate forward pass entirely.
Load-bearing premise
The learned difficulty predictor chooses rollout counts that match query needs without adding large overhead or wasting compute on a noticeable fraction of inputs.
What would settle it
If, on a held-out set of image and video reasoning tasks, AVIS reaches the same accuracy levels only by spending more total tokens or latency than a well-tuned fixed VCS or VRS baseline, the claimed improvement in the accuracy-compute trade-off would be refuted.
Figures

read the original abstract
Modern Vision-Language Models (VLMs) benefit from chain-of-thought prompting and test-time scaling, but these gains often come with prohibitive inference cost due to large visual contexts and long decoding chains. We view this cost through two coupled axes: Visual Context Scaling (VCS), which controls how much visual evidence is passed to the language model, and Visual Reasoning Scaling (VRS), which controls how much inference-time reasoning search is performed. Existing methods typically optimize one axis at a time, leaving the joint allocation of compute across these axes underexplored. We introduce Adaptive Visual Inference Scaling (AVIS), a lightweight policy that adapts both VCS and VRS per query. AVIS realizes VCS through Key Diversity Visual (KDV) pruning, a training-free $O(N)$ key-based rule for removing redundant visual tokens before prefilling, and realizes VRS through adaptive self-consistency, using a learned difficulty predictor to select the number of reasoning rollouts. AVIS is deployment-friendly and compatible with shared-prefill inference, where all rollouts reuse a single prefilling pass and KV cache. Across diverse image and video reasoning benchmarks, AVIS improves the accuracy--compute trade-off relative to VCS-only and VRS-only baselines, and remains effective on top of RL post-trained VLMs while keeping compute and latency low.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AVIS for adaptive test-time scaling in Vision-Language Models. It decomposes inference cost into Visual Context Scaling (VCS) via training-free Key Diversity Visual (KDV) token pruning and Visual Reasoning Scaling (VRS) via a learned difficulty predictor that selects the number of self-consistency rollouts per query. The central claim is that this joint adaptive policy improves the accuracy-compute frontier over VCS-only and VRS-only baselines across image and video reasoning benchmarks, remains effective on RL post-trained VLMs, and is compatible with shared-prefill inference.
Significance. If the empirical claims hold with proper validation, the work would be significant for practical VLM deployment by showing how to jointly allocate compute across visual evidence and reasoning search without prohibitive overhead. The training-free KDV pruning and shared-prefill design are practical strengths that could generalize beyond the reported setting.
major comments (2)
- [Abstract] Abstract: The abstract states performance gains but supplies no quantitative results, error bars, dataset details, or validation of the difficulty predictor; the central claim cannot be assessed from the provided text.
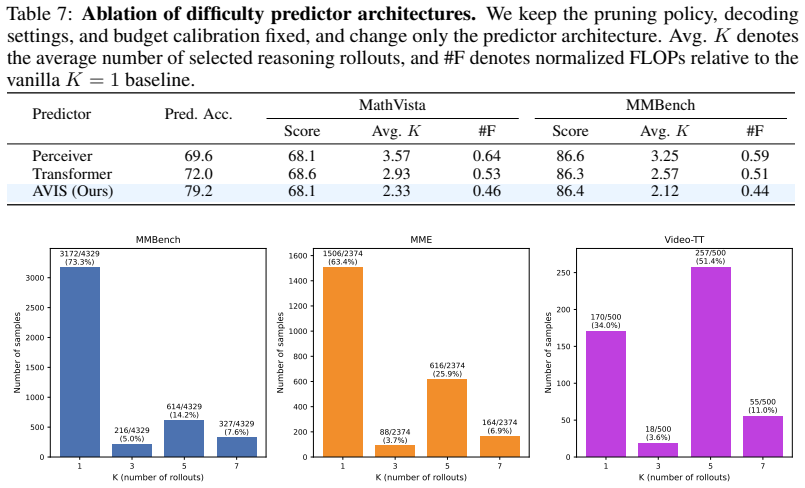
- [Method (difficulty predictor)] Method section on the difficulty predictor: The learned predictor is load-bearing for the adaptive VRS benefit, yet no details are supplied on its training data, loss, architecture, inference overhead, or cross-benchmark hold-out accuracy; without these, it is impossible to verify that the predictor avoids systematic misallocation or adds negligible cost on a non-trivial fraction of inputs.
minor comments (1)
- [Abstract] Abstract: Consider naming the specific image and video benchmarks and reporting at least one headline accuracy-compute number to allow readers to gauge the magnitude of the claimed improvement.
Simulated Author's Rebuttal
We appreciate the referee's comments highlighting areas where the manuscript can be improved for clarity and completeness. We address each point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states performance gains but supplies no quantitative results, error bars, dataset details, or validation of the difficulty predictor; the central claim cannot be assessed from the provided text.
Authors: We agree that the abstract would be strengthened by including quantitative results. In the revised version, we will add specific performance metrics, dataset details, and references to the validation of the difficulty predictor to make the central claim more assessable from the abstract. revision: yes
-
Referee: [Method (difficulty predictor)] Method section on the difficulty predictor: The learned predictor is load-bearing for the adaptive VRS benefit, yet no details are supplied on its training data, loss, architecture, inference overhead, or cross-benchmark hold-out accuracy; without these, it is impossible to verify that the predictor avoids systematic misallocation or adds negligible cost on a non-trivial fraction of inputs.
Authors: We acknowledge that more details are needed on the difficulty predictor. We will expand the method section in the revised manuscript to provide information on its training data, loss function, architecture, inference overhead, and cross-benchmark hold-out accuracy to allow proper verification. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes AVIS as combining training-free KDV pruning for VCS with a learned difficulty predictor for adaptive VRS, evaluated on external benchmarks. No equations, fitted parameters, or self-citations are presented that reduce the accuracy-compute improvement claim to a definition, renaming, or input by construction. The method is positioned as using an external predictor and compatible with existing VLMs, rendering the central claims self-contained against the reported evaluations without circular reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL Technical Report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
LLaV A-OneVision: Easy Visual Task Transfer.Transactions on Machine Learning Research, 2025
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. LLaV A-OneVision: Easy Visual Task Transfer.Transactions on Machine Learning Research, 2025
2025
-
[3]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[5]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models. In International Conference on Learning Representations (ICLR), 2026
2026
-
[6]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[7]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to Summarize with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2020. 10
2020
-
[8]
Evaluation of Best-of-N Sampling Strategies for Language Model Alignment.Transactions on Machine Learning Research, 2025
Yuki Ichihara, Yuu Jinnai, Tetsuro Morimura, Kaito Ariu, Kenshi Abe, Mitsuki Sakamoto, and Eiji Uchibe. Evaluation of Best-of-N Sampling Strategies for Language Model Alignment.Transactions on Machine Learning Research, 2025
2025
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In International Conference on Learning Representations (ICLR), 2023
2023
-
[10]
An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[11]
LLaV A-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. LLaV A-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
2025
-
[12]
Mohammadjavad Ahmadpour, Amirmahdi Meighani, Payam Taebi, Omid Ghahroodi, Amirmohammad Izadi, and Mahdieh Soleymani Baghshah. Limits and Gains of Test-Time Scaling in Vision-Language Reasoning.arXiv preprint arXiv:2512.11109, 2025
-
[13]
Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[14]
BLIP-2: Bootstrapping Language-Image Pre- training with Frozen Image Encoders and Large Language Models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language-Image Pre- training with Frozen Image Encoders and Large Language Models. InInternational Conference on Machine Learning, 2023
2023
-
[15]
LLaV A- NeXT: Improved Reasoning, OCR, and World Knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. LLaV A- NeXT: Improved Reasoning, OCR, and World Knowledge, January 2024
2024
-
[16]
LLaV A-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. LLaV A-CoT: Let Vision Language Models Reason Step-by-Step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098, 2025
2087
-
[17]
Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search
Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, and Dacheng Tao. Mulberry: Empowering MLLM with o1-like Reasoning and Reflection via Collective Monte Carlo Tree Search. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[18]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[19]
Puzzle Curriculum GRPO for Vision-Centric Reasoning.arXiv preprint arXiv:2512.14944, 2025
Ahmadreza Jeddi, Hakki Can Karaimer, Hue Nguyen, Zhongling Wang, Ke Zhao, Javad Rajabi, Ran Zhang, Raghav Goyal, Babak Taati, and Radek Grzeszczuk. Puzzle Curriculum GRPO for Vision-Centric Reasoning.arXiv preprint arXiv:2512.14944, 2025
-
[20]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization
Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[22]
Ahmadreza Jeddi, Kimia Shaban, Negin Baghbanzadeh, Natasha Sharan, Abhishek Moturu, Elham Dolatabadi, and Babak Taati. When Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains.arXiv preprint arXiv:2603.01301, 2026
-
[23]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V Le, Christopher Ré, and Azalia Mirhoseini. Large Language Monkeys: Scaling Inference Compute with Repeated Sampling.arXiv preprint arXiv:2407.21787, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Majority of the Bests: Improving Best-of-N via Bootstrapping
Amin Rakhsha, Kanika Madan, Tianyu Zhang, Amir massoud Farahmand, and Amir Khasahmadi. Majority of the Bests: Improving Best-of-N via Bootstrapping. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[26]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative Refinement with Self-Feedback. InAdvances in Neural Information Processing Sys...
2023
-
[27]
Let’s Verify Step by Step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s Verify Step by Step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[28]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[29]
s1: Simple Test-Time Scaling
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple Test-Time Scaling. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2025
2025
-
[30]
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
Zheng Li, Qingxiu Dong, Jingyuan Ma, Di Zhang, Kai Jia, and Zhifang Sui. SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning.arXiv preprint arXiv:2505.11274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Rohin Manvi, Anikait Singh, and Stefano Ermon. Adaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation.arXiv preprint arXiv:2410.02725, 2024
-
[32]
Scaling LLM Test-Time Compute Opti- mally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM Test-Time Compute Opti- mally can be More Effective than Scaling Model Parameters. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[33]
Learning How Hard to Think: Input-Adaptive Allocation of LM Computation
Mehul Damani, Idan Shenfeld, Andi Peng, Andreea Bobu, and Jacob Andreas. Learning How Hard to Think: Input-Adaptive Allocation of LM Computation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[34]
Jiahao Meng, Shuyang Sun, Yue Tan, Lu Qi, Yunhai Tong, Xiangtai Li, and Longyin Wen. CyberV: Cybernetics for Test-time Scaling in Video Understanding.arXiv preprint arXiv:2506.07971, 2025
-
[35]
Hongbo Jin, Jiayu Ding, Siyi Xie, Guibo Luo, and Ge Li. VISTA: Mitigating Semantic Inertia in Video- LLMs via Training-Free Dynamic Chain-of-Thought Routing.arXiv preprint arXiv:2505.11830, 2025
-
[36]
Learning Adaptive Reasoning Paths for Efficient Visual Reasoning
Yixu Huang, Tinghui Zhu, and Muhao Chen. Learning Adaptive Reasoning Paths for Efficient Visual Reasoning.arXiv preprint arXiv:2604.14568, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
ARES: Multimodal Adaptive Reasoning via Difficulty-Aware Token-Level Entropy Shaping
Shuang Chen, Yue Guo, Yimeng Ye, Shijue Huang, Wenbo Hu, Haoxi Li, Manyuan Zhang, Jiayu Chen, Song Guo, and Nanyun Peng. ARES: Multimodal Adaptive Reasoning via Difficulty-Aware Token-Level Entropy Shaping. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[38]
Efficient Test-Time Scaling for Small Vision-Language Models
Mehmet Onurcan Kaya, Desmond Elliott, and Dim P Papadopoulos. Efficient Test-Time Scaling for Small Vision-Language Models. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[39]
Improve Vision Language Model Chain-of-thought Reasoning
Ruohong Zhang, Bowen Zhang, Yanghao Li, Haotian Zhang, Zhiqing Sun, Zhe Gan, Yinfei Yang, Ruoming Pang, and Yiming Yang. Improve Vision Language Model Chain-of-thought Reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1631–1662, 2025
2025
-
[40]
Mingyuan Wu, Meitang Li, Jingcheng Yang, Jize Jiang, Kaizhuo Yan, Zhaoheng Li, Hanchao Yu, Minjia Zhang, and Klara Nahrstedt. Aha Moment Revisited: Are VLMs Truly Capable of Self Verification in Inference-time Scaling?arXiv preprint arXiv:2506.17417, 2025
-
[41]
Similarity-Aware Token Pruning: Your VLM but Faster.arXiv preprint arXiv:2503.11549, 2025
Ahmadreza Jeddi, Negin Baghbanzadeh, Elham Dolatabadi, and Babak Taati. Similarity-Aware Token Pruning: Your VLM but Faster.arXiv preprint arXiv:2503.11549, 2025. 12
-
[42]
PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, and Dahua Lin. PyramidDrop: Accelerating Your Large Vision-Language Models via Pyramid Visual Redundancy Reduction. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[43]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, and Shanghang Zhang. SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference. InInternational Conference on Machine Learning, 2025
2025
-
[44]
VisionZip: Longer is Better but Not Necessary in Vision Language Models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. VisionZip: Longer is Better but Not Necessary in Vision Language Models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19792–19802, 2025
2025
-
[45]
PruneVid: Visual Token Pruning for Efficient Video Large Language Models
Xiaohu Huang, Hao Zhou, and Kai Han. PruneVid: Visual Token Pruning for Efficient Video Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
2025
-
[46]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token Merging: Your ViT But Faster. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[47]
DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
2025
-
[48]
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[49]
Beyond Text-Visual Attention: Exploiting Visual Cues for Effective Token Pruning in VLMs
Qizhe Zhang, Aosong Cheng, Ming Lu, Renrui Zhang, Zhiyong Zhuo, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. Beyond Text-Visual Attention: Exploiting Visual Cues for Effective Token Pruning in VLMs. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[50]
TopV: Compatible Token Pruning with Inference Time Optimization for Fast and Low-Memory Multimodal Vision Language Model
Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Chendi Li, Jinghua Yan, Yu Bai, Ponnuswamy Sadayappan, Xia Hu, and Bo Yuan. TopV: Compatible Token Pruning with Inference Time Optimization for Fast and Low-Memory Multimodal Vision Language Model. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025
2025
-
[51]
CATP: Contextu- ally Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning
Yanshu Li, Jianjiang Yang, Zhennan Shen, Ligong Han, Haoyan Xu, and Ruixiang Tang. CATP: Contextu- ally Adaptive Token Pruning for Efficient and Enhanced Multimodal In-Context Learning. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[52]
FlashAttention: Fast and Memory- Efficient Exact Attention with IO-Awareness
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and Memory- Efficient Exact Attention with IO-Awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[53]
VScan: Rethinking Visual Token Reduction for Efficient Large Vision- Language Models.Transactions on Machine Learning Research, 2026
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hongming Zhang, Zhisong Zhang, Yaqi Xie, Katia Sycara, Haitao Mi, and Dong Yu. VScan: Rethinking Visual Token Reduction for Efficient Large Vision- Language Models.Transactions on Machine Learning Research, 2026
2026
-
[54]
KeyDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments
Junyoung Park, Dalton Jones, Matthew J Morse, Raghavv Goel, Mingu Lee, and Chris Lott. KeyDiff: Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[55]
VLMEvalKit: An Open-Source Toolkit for Evaluating Large Multi-Modality Models
Haodong Duan, Xinyu Fang, Junming Yang, Xiangyu Zhao, Yuxuan Qiao, Mo Li, Amit Agarwal, Zhe Chen, Lin Chen, Yuan Liu, Yubo Ma, Hailong Sun, Yifan Zhang, Shiyin Lu, Tack Hwa Wong, Weiyun Wang, Peiheng Zhou, Xiaozhe Li, Chaoyou Fu, Junbo Cui, Jixuan Chen, Enxin Song, Song Mao, Shengyuan Ding, Tianhao Liang, Zicheng Zhang, Xiaoyi Dong, Yuhang Zang, Pan Zhang...
2024
-
[56]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[57]
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems? InEuropean Conference on Computer Vision, 2024
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, and Hongsheng Li. MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems? InEuropean Conference on Computer Vision, 2024. 13
2024
-
[58]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset.Advances in Neural Information Processing Systems (NeurIPS), 37:95095–95169, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset.Advances in Neural Information Processing Systems (NeurIPS), 37:95095–95169, 2024
2024
-
[59]
DocVQA: A Dataset for VQA on Document Images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. DocVQA: A Dataset for VQA on Document Images. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2021
2021
-
[60]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15...
2025
-
[61]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[62]
Are We on the Right Way for Evaluating Large Vision-Language Models? InAdvances in Neural Information Processing Systems (NeurIPS), 2024
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are We on the Right Way for Evaluating Large Vision-Language Models? InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[63]
MMBench: Is Your Multi-modal Model an All-around Player? InEuropean Conference on Computer Vision, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is Your Multi-modal Model an All-around Player? InEuropean Conference on Computer Vision, 2024
2024
-
[64]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, and Saining Xie. Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[65]
Evaluating Object Hallucination in Large Vision-Language Models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating Object Hallucination in Large Vision-Language Models. InConference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[66]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal Large Language Models Can See but Not Perceive. InEuropean Conference on Computer Vision, 2024
2024
-
[67]
Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, Zhuochen Wang, and Zhaoxiang Zhang. Traceable Evidence Enhanced Visual Grounded Reasoning: Evaluation and Methodology. InInternational Conference on Learning Representations (ICLR), 2026
2026
-
[68]
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, Peixian Chen, Yanwei Li, Shaohui Lin, Sirui Zhao, Ke Li, Tong Xu, Xiawu Zheng, Enhong Chen, Caifeng Shan, Ran He, and Xing Sun. Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis. InP...
2025
-
[69]
TempCompass: Do Video LLMs Really Understand Videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
Yuanxin Liu, Shicheng Li, Yi Liu, Yuxiang Wang, Shuhuai Ren, Lei Li, Sishuo Chen, Xu Sun, and Lu Hou. TempCompass: Do Video LLMs Really Understand Videos? InFindings of the Association for Computational Linguistics: ACL 2024, pages 8731–8772, 2024
2024
-
[70]
Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding
Yuanhan Zhang, Yunice Chew, Yuhao Dong, Aria Leo, Bo Hu, and Ziwei Liu. Towards Video Thinking Test: A Holistic Benchmark for Advanced Video Reasoning and Understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[71]
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. MVBench: A Comprehensive Multi-modal Video Understanding Benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[72]
Q-Bench-Video: Benchmark the Video Quality Understanding of LMMs
Zicheng Zhang, Ziheng Jia, Haoning Wu, Chunyi Li, Zijian Chen, Yingjie Zhou, Wei Sun, Xiaohong Liu, Xiongkuo Min, Weisi Lin, and Guangtao Zhai. Q-Bench-Video: Benchmark the Video Quality Understanding of LMMs. InProceedings of the Computer Vision and Pattern Recognition Conference, 2025. 14
2025
-
[73]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Kairui Hu, Penghao Wu, Fanyi Pu, Wang Xiao, Yuanhan Zhang, Xiang Yue, Bo Li, and Ziwei Liu. Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos.arXiv preprint arXiv:2501.13826, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[75]
OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. OpenVLThinker: Complex Vision-Language Reasoning via Iterative SFT-RL Cycles. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[76]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational conference on machine learning, pages 4651–
-
[77]
LLaV A-Video: Video Instruction Tuning With Synthetic Data.Transactions on Machine Learning Research, 2025
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. LLaV A-Video: Video Instruction Tuning With Synthetic Data.Transactions on Machine Learning Research, 2025
2025
-
[78]
A- OKVQA: A Benchmark for Visual Question Answering using World Knowledge
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. A- OKVQA: A Benchmark for Visual Question Answering using World Knowledge. InEuropean Conference on Computer Vision, 2022
2022
-
[79]
A Diagram Is Worth A Dozen Images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A Diagram Is Worth A Dozen Images. InEuropean Conference on Computer Vision, 2016
2016
-
[80]
Are You Smarter Than a Sixth Grader? Textbook Question Answering for Multimodal Machine Comprehension
Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Hannaneh Ha- jishirzi. Are You Smarter Than a Sixth Grader? Textbook Question Answering for Multimodal Machine Comprehension. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.