TextHOI-3D: Text-to-3D Hand-Object Interaction via Discrete Multi-View Generation and Joint Mesh Optimization
Pith reviewed 2026-06-27 09:58 UTC · model grok-4.3
The pith
Multi-view visual tokens predicted from text enable joint optimization that produces accurate 3D hand-object meshes with low penetration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
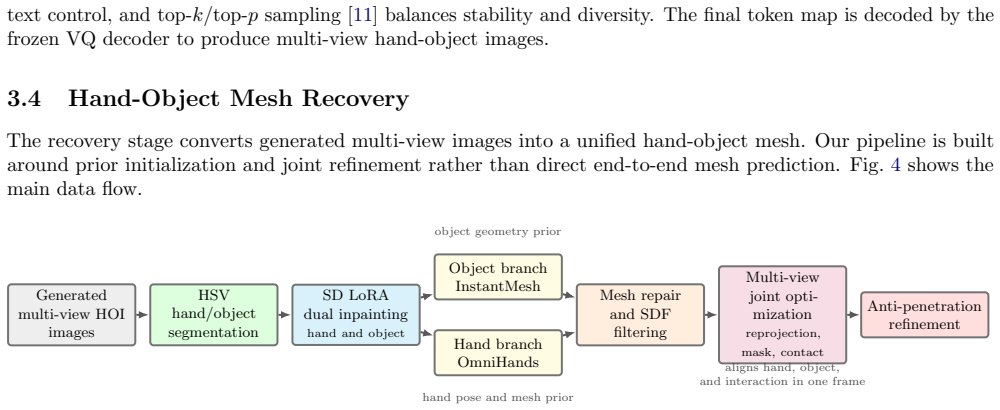
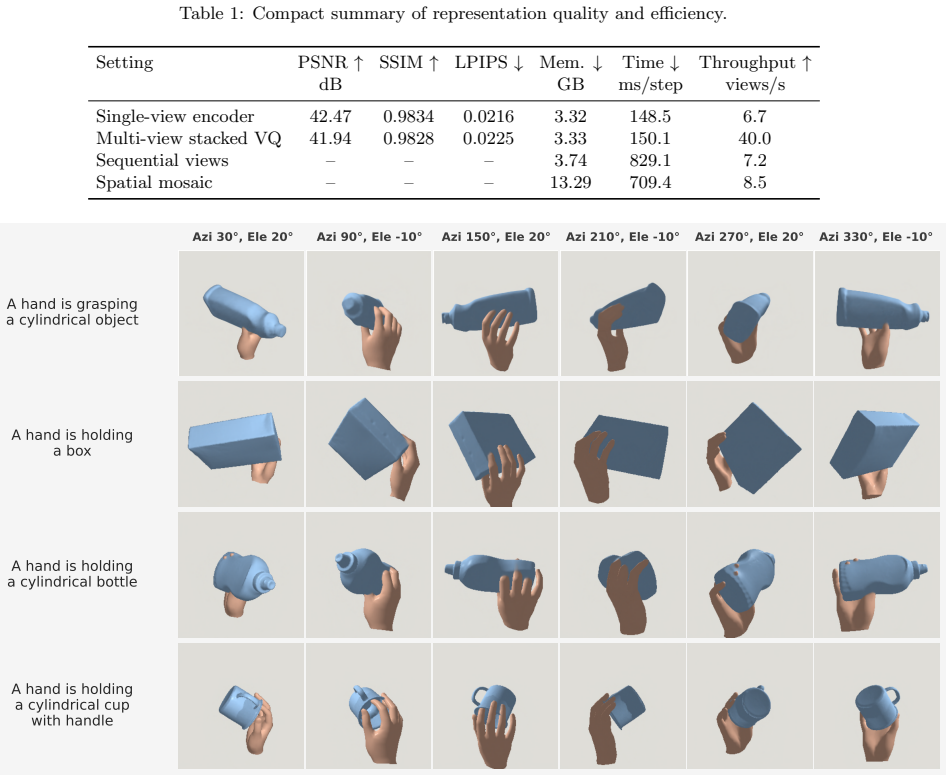
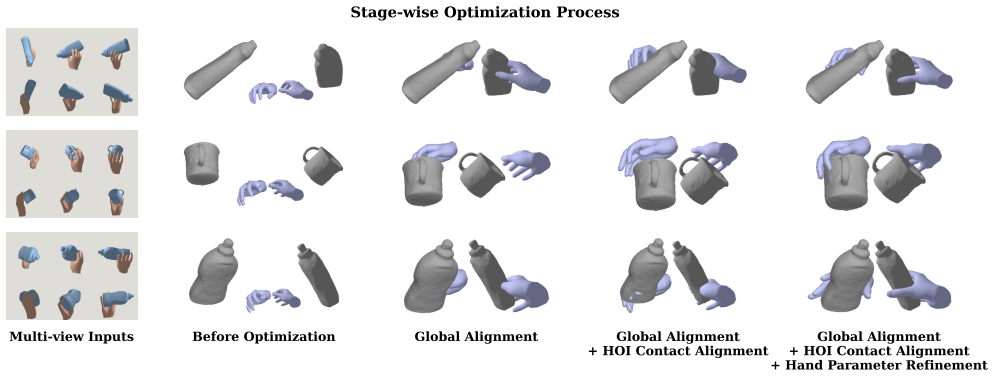
TextHOI-3D learns a compact VQ token space for fixed-camera hand-object observations, predicts multi-view visual tokens from text with a CLIP-conditioned visual autoregressive model, and recovers a unified hand-object mesh through prior initialization, multi-view joint optimization, and anti-penetration refinement. The design separates semantic generation from geometric recovery while keeping both stages connected by a discrete multi-view representation.
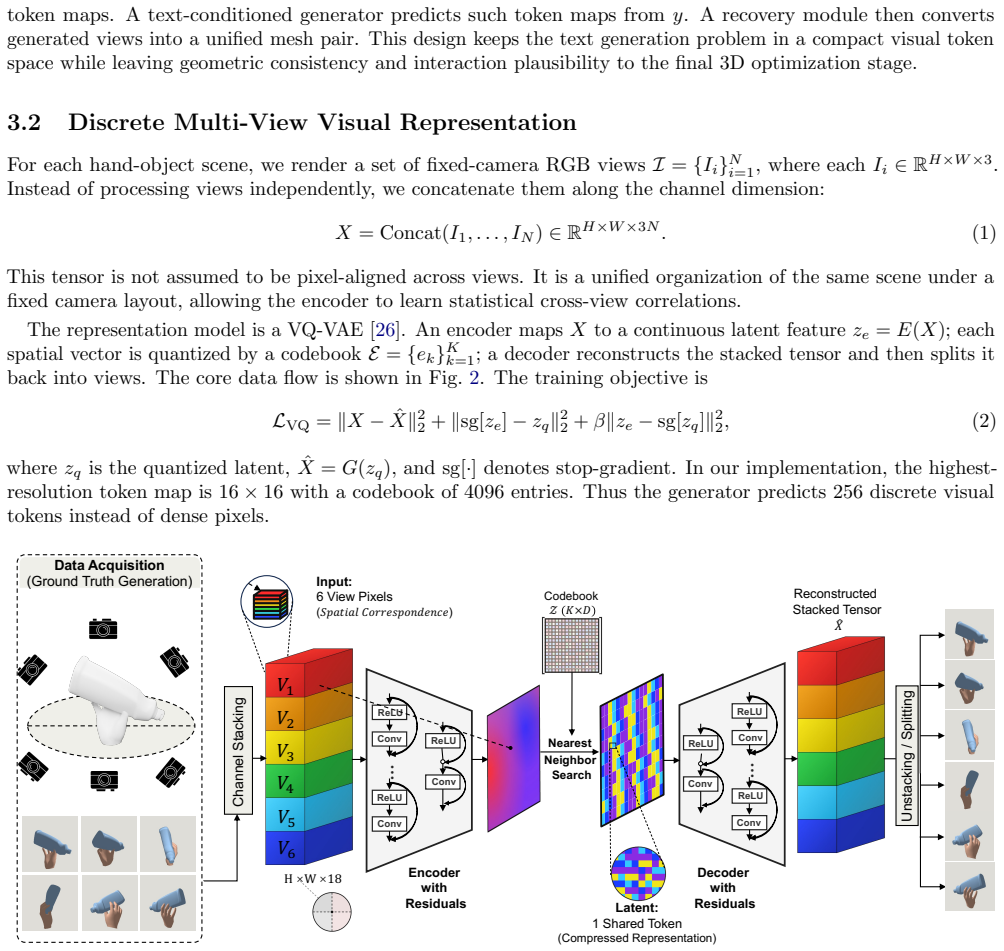
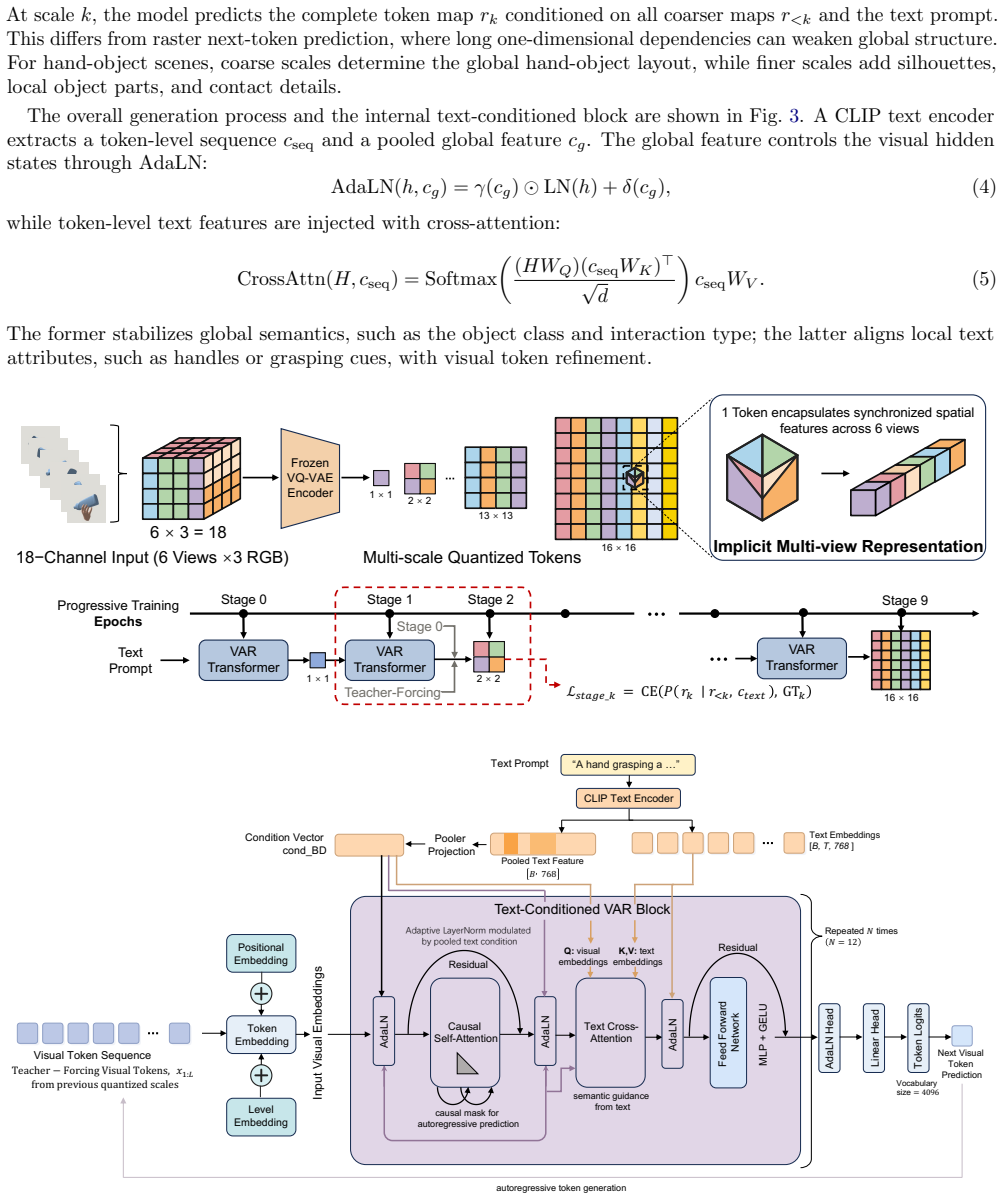
What carries the argument
Discrete multi-view VQ token space that acts as the explicit interface between text-conditioned autoregressive prediction and subsequent joint mesh optimization.
If this is right
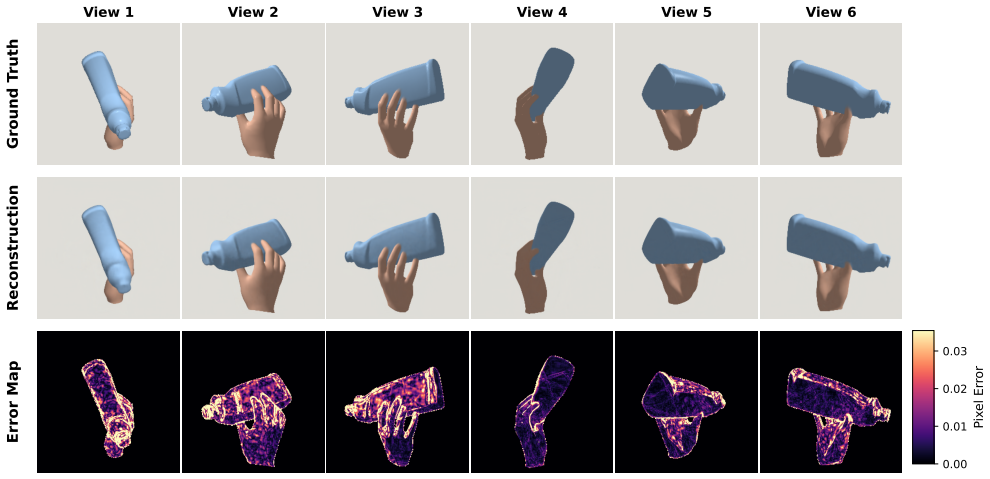
- Multi-view token prediction reduces object chamfer distance from 17.26 mm to 4.92 mm compared with single-view generation.
- Multi-view token prediction reduces penetration volume from 5.3721 cm³ to 0.2193 cm³ compared with single-view generation.
- Multi-view token prediction improves hand pose errors and surface F-scores relative to the single-view counterpart.
- Multi-view visual tokens function as an effective intermediate representation that connects text semantics to geometry-aware mesh recovery.
Where Pith is reading between the lines
- The same token-prediction-plus-optimization pattern could be tested on text descriptions that involve multiple objects or full-body interactions if the VQ vocabulary is expanded.
- If the autoregressive model can be conditioned on additional signals such as object category labels, the framework might reduce the need for large numbers of fixed-camera training views.
- The staged separation suggests that improvements in discrete visual token prediction alone could translate directly into better final meshes without retraining the optimizer.
Load-bearing premise
The compact VQ token space learned from fixed-camera observations supplies enough cross-view consistent information when generated from text to support accurate initialization and optimization without losing semantic or geometric fidelity.
What would settle it
Generate meshes from text prompts describing hand-object contacts absent from the training views; measure whether the optimized surfaces still exhibit high penetration volume or semantic mismatch despite the multi-view token input.
Figures


read the original abstract
Text-conditioned 3D generation has progressed rapidly for images and isolated objects, but producing a hand-object mesh remains challenging: the output must preserve language semantics, cross-view consistency, object geometry, articulated hand shape, and physically plausible contact. We present TextHOI-3D, a staged framework that uses generated multi-view observations as an explicit interface between text-conditioned visual generation and geometry-aware hand-object recovery. TextHOI-3D learns a compact VQ token space for fixed-camera hand-object observations, predicts multi-view visual tokens from text with a CLIP-conditioned visual autoregressive model, and recovers a unified hand-object mesh through prior initialization, multi-view joint optimization, and anti-penetration refinement. The design separates semantic generation from geometric recovery while keeping both stages connected by a discrete multi-view representation. On HO3D-derived evaluations, the multi-view setting reduces object CD from 17.26 mm to 4.92 mm and penetration volume from 5.3721 cm^3 to 0.2193 cm^3 compared with a single-view counterpart, while improving hand errors and surface F-scores. These results support multi-view visual tokens as an effective intermediate representation for text-driven 3D hand-object mesh creation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TextHOI-3D, a staged pipeline for text-to-3D hand-object interaction generation. It first learns a compact VQ token space over fixed-camera hand-object observations, then uses a CLIP-conditioned autoregressive model to predict multi-view visual tokens from text, and finally recovers a unified hand-object mesh via prior initialization, multi-view joint optimization, and anti-penetration refinement. On HO3D-derived evaluations the multi-view setting is reported to reduce object Chamfer distance from 17.26 mm to 4.92 mm and penetration volume from 5.3721 cm³ to 0.2193 cm³ relative to a single-view counterpart, with accompanying gains in hand errors and surface F-scores.
Significance. If the multi-view token predictions indeed supply cross-view geometric consistency sufficient for the subsequent optimization stage, the separation of semantic token generation from geometry-aware mesh recovery could provide a useful intermediate representation for text-driven articulated 3D content. The reported metric deltas are large enough that, if reproducible and properly controlled, they would constitute a meaningful empirical advance for the sub-problem of physically plausible hand-object contact.
major comments (2)
- [Abstract] Abstract (results paragraph): the headline quantitative claims (object CD 17.26 mm → 4.92 mm; penetration 5.3721 cm³ → 0.2193 cm³) are presented without any description of baseline implementations, experimental controls, error bars, data selection criteria, or statistical testing. Because these details are load-bearing for attributing the gains to the multi-view design rather than implementation differences, the central empirical claim cannot be evaluated from the given information.
- [Abstract] Abstract (method description): the framework assumes that CLIP-conditioned autoregressive prediction of VQ tokens from the fixed-camera codebook produces outputs whose implied 3D geometry remains sufficiently consistent across views to allow accurate prior initialization and joint mesh optimization. No quantitative check (per-view token reconstruction error, 3D point variance across views, or ablation of any consistency regularizer) is reported for text inputs outside the training distribution; without such evidence the large metric improvements could be artifacts of the anti-penetration term masking view-inconsistent predictions rather than genuine semantic recovery.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and the importance of validating cross-view consistency. We address each point below with clarifications from the full manuscript and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (results paragraph): the headline quantitative claims (object CD 17.26 mm → 4.92 mm; penetration 5.3721 cm³ → 0.2193 cm³) are presented without any description of baseline implementations, experimental controls, error bars, data selection criteria, or statistical testing. Because these details are load-bearing for attributing the gains to the multi-view design rather than implementation differences, the central empirical claim cannot be evaluated from the given information.
Authors: The abstract is length-constrained, but the full manuscript provides the requested details: the single-view baseline is implemented identically except for using one view (Section 4.2), the dataset is derived from HO3D with the same train/test split and 100 text prompts (Section 3.1 and 5.1), error bars (standard deviations) appear in Table 2, and data selection follows the standard HO3D protocol. No formal statistical hypothesis testing was performed. We will revise the abstract to briefly note the baseline and data source for improved self-containment while preserving the headline numbers. revision: yes
-
Referee: [Abstract] Abstract (method description): the framework assumes that CLIP-conditioned autoregressive prediction of VQ tokens from the fixed-camera codebook produces outputs whose implied 3D geometry remains sufficiently consistent across views to allow accurate prior initialization and joint mesh optimization. No quantitative check (per-view token reconstruction error, 3D point variance across views, or ablation of any consistency regularizer) is reported for text inputs outside the training distribution; without such evidence the large metric improvements could be artifacts of the anti-penetration term masking view-inconsistent predictions rather than genuine semantic recovery.
Authors: The manuscript validates multi-view consistency indirectly via the large gains in object CD, penetration volume, and F-scores when moving from single- to multi-view (Table 2 and ablation in Section 5.3), plus qualitative mesh results. However, we did not include explicit per-view token reconstruction error or 3D point variance metrics on out-of-distribution text. This is a fair observation; the anti-penetration term is applied after initialization, so view inconsistency could in principle be masked. We will add a quantitative consistency analysis (e.g., 3D variance across generated views) on held-out text prompts in the revision, either in the main text or supplementary material. revision: yes
Circularity Check
No significant circularity; empirical gains presented as direct outcomes
full rationale
The paper describes a staged pipeline (VQ token learning, CLIP-conditioned autoregressive prediction, prior initialization + joint mesh optimization) whose central claims are supported by direct HO3D-derived metric comparisons (multi-view vs. single-view CD and penetration reductions). No equations, derivations, or self-citations are exhibited that reduce these reported improvements to quantities defined by construction from fitted parameters or prior author results. The multi-view token representation is introduced as an explicit design choice whose effectiveness is measured externally rather than tautologically assumed. This is the common case of a self-contained empirical framework.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Reconstructing hand-object interactions in the wild
Zhe Cao, Ilija Radosavovic, Angjoo Kanazawa, and Jitendra Malik. Reconstructing hand-object interactions in the wild. InProceedings of the IEEE/CVF international conference on computer vision, pages 12417–12426, 2021
2021
-
[2]
Text2hoi: Text-guided 3d motion generation for hand-object interaction
Junuk Cha, Jihyeon Kim, Jae Shin Yoon, and Seungryul Baek. Text2hoi: Text-guided 3d motion generation for hand-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1577–1585, 2024
2024
-
[3]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
2020
-
[4]
Alignsdf: Pose-aligned signed distance fields for hand-object reconstruction
Zerui Chen, Yana Hasson, Cordelia Schmid, and Ivan Laptev. Alignsdf: Pose-aligned signed distance fields for hand-object reconstruction. InEuropean conference on computer vision, pages 231–248. Springer, 2022
2022
-
[5]
gsdf: Geometry-driven signed distance functions for 3d hand-object reconstruction
Zerui Chen, Shizhe Chen, Cordelia Schmid, and Ivan Laptev. gsdf: Geometry-driven signed distance functions for 3d hand-object reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12890–12900, 2023
2023
-
[6]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[7]
Honnotate: A method for 3d annotation of hand and object poses
Shreyas Hampali, Mahdi Rad, Markus Oberweger, and Vincent Lepetit. Honnotate: A method for 3d annotation of hand and object poses. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3196–3206, 2020
2020
-
[8]
Learning joint reconstruction of hands and manipulated objects
Yana Hasson, Gul Varol, Dimitrios Tzionas, Igor Kalevatykh, Michael J Black, Ivan Laptev, and Cordelia Schmid. Learning joint reconstruction of hands and manipulated objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11807–11816, 2019
2019
-
[9]
Leveraging photometric consistency over time for sparsely supervised hand-object reconstruction
Yana Hasson, Bugra Tekin, Federica Bogo, Ivan Laptev, Marc Pollefeys, and Cordelia Schmid. Leveraging photometric consistency over time for sparsely supervised hand-object reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 571–580, 2020
2020
-
[10]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration. arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[12]
LRM: Large Reconstruction Model for Single Image to 3D
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. Lrm: Large reconstruction model for single image to 3d.arXiv preprint arXiv:2311.04400, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023
2023
-
[14]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Reconstructing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Reconstructing hands in 3d with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9826–9836, 2024
2024
-
[16]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 10
2021
-
[18]
Accelerating 3D Deep Learning with PyTorch3D
Nikhila Ravi, Jeremy Reizenstein, David Novotny, Taylor Gordon, Wan-Yen Lo, Justin Johnson, and Georgia Gkioxari. Accelerating 3d deep learning with pytorch3d.arXiv preprint arXiv:2007.08501, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2007
-
[19]
Generating diverse high-fidelity images with vq-vae-2
Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with vq-vae-2. Advances in neural information processing systems, 32, 2019
2019
-
[20]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[21]
Javier Romero, Dimitrios Tzionas, and Michael J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics, 36(6):245:1–245:17, 2017
2017
-
[22]
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Shitao Tang, Fuayng Zhang, Jiacheng Chen, Peng Wang, and Furukawa Yasutaka. Mvdiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion.arXiv preprint 2307.01097, 2023
-
[24]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
2024
-
[25]
Pixel recurrent neural networks
A¨ aron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. In International conference on machine learning, pages 1747–1756. PMLR, 2016
2016
-
[26]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[27]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[28]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models.arXiv preprint arXiv:2404.07191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
What’s in your hands? 3d reconstruction of generic objects in hands
Yufei Ye, Abhinav Gupta, and Shubham Tulsiani. What’s in your hands? 3d reconstruction of generic objects in hands. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3895–3905, 2022
2022
-
[30]
Moho: Learning single-view hand-held object reconstruction with multi-view occlusion-aware supervision
Chenyangguang Zhang, Guanlong Jiao, Yan Di, Gu Wang, Ziqin Huang, Ruida Zhang, Fabian Manhardt, Bowen Fu, Federico Tombari, and Xiangyang Ji. Moho: Learning single-view hand-held object reconstruction with multi-view occlusion-aware supervision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9992–10002, 2024
2024
-
[31]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 11
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.