Multi-Bitwidth Quantization for LLMs Using Additive Codebooks
Pith reviewed 2026-06-27 07:27 UTC · model grok-4.3
The pith
LLM weights following a Gaussian distribution can be reconstructed with increasing fidelity at multiple bitwidths from one model via additive codebooks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
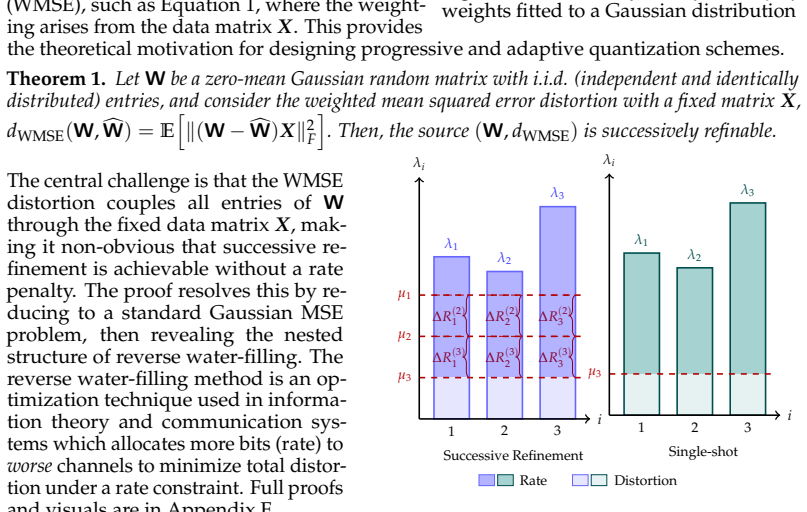
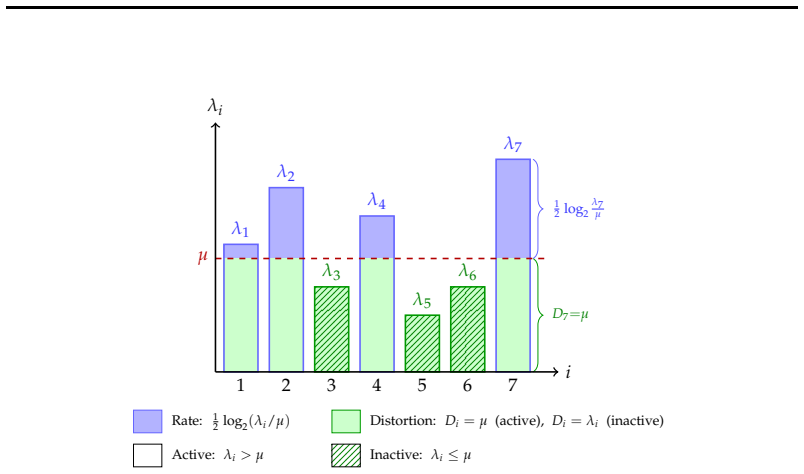
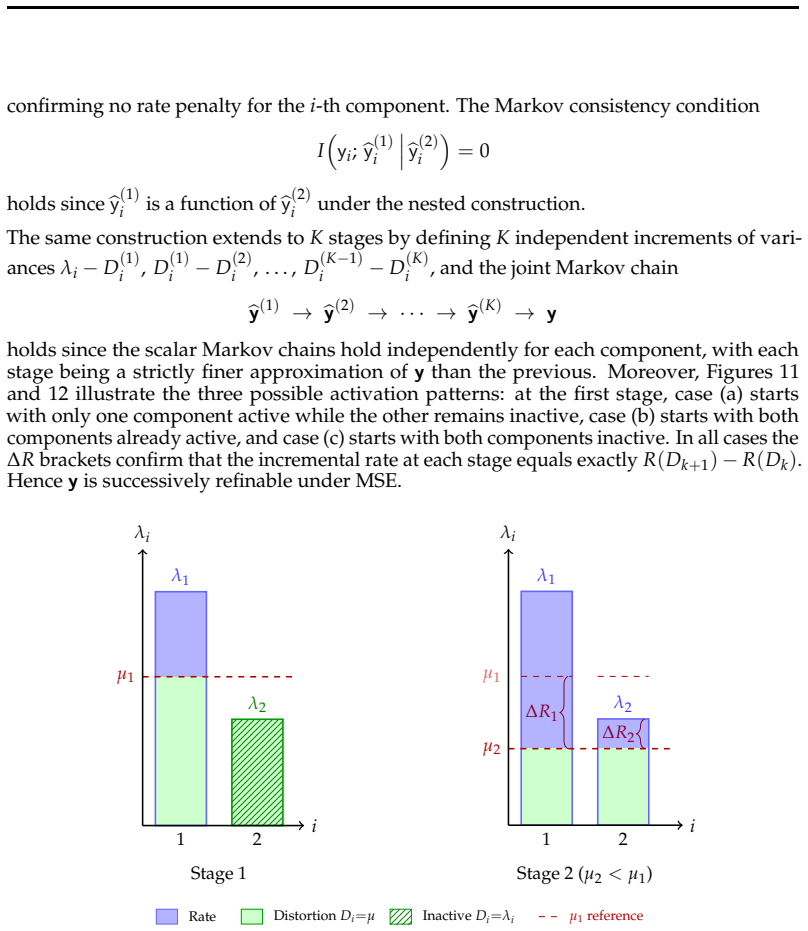
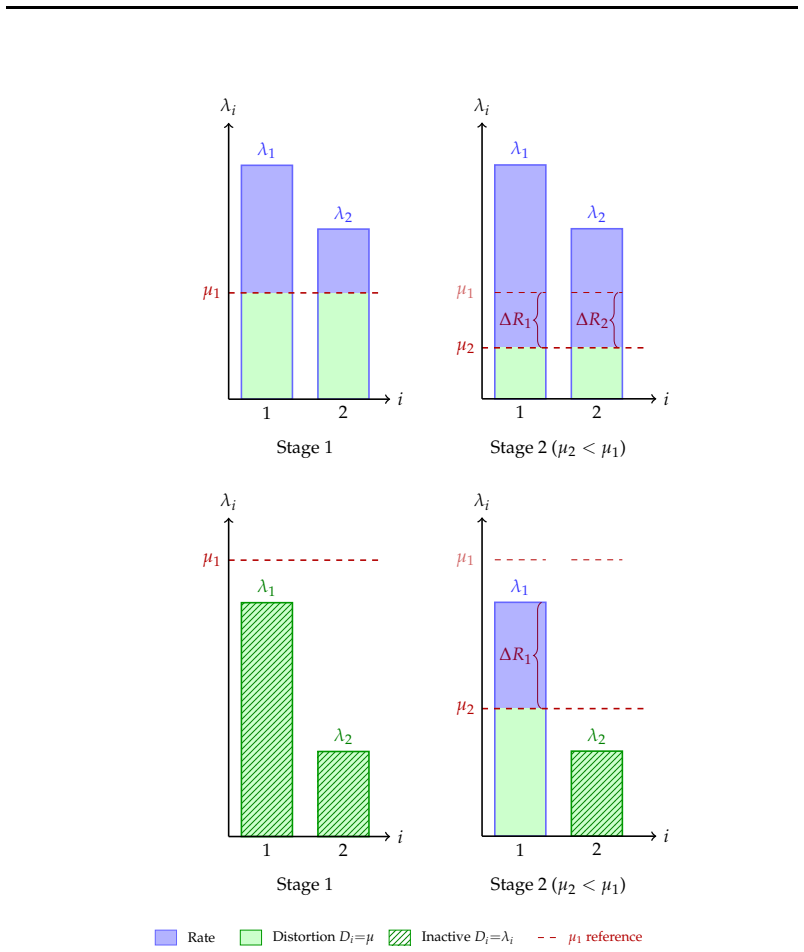
The paper establishes that LLM weights, which commonly follow a Gaussian distribution, can be optimally reconstructed with increasing fidelity as additional bits are incorporated under a weighted mean squared error distortion motivated by LLM loss functions. This is realized in practice through additive codebooks and Matryoshka-style supervision in the loss function, producing a single model where ordered subsets of codebooks yield accurate partial reconstructions at each precision level.
What carries the argument
Additive codebooks trained with Matryoshka-style supervision to realize successive refinement of Gaussian weight reconstructions under weighted MSE.
If this is right
- A single checkpoint can serve multiple bitwidths, eliminating the storage cost of separate quantized models.
- Inference-time selection of precision becomes possible without any retraining step.
- Competitive perplexity and downstream accuracy are retained on Qwen, LLaMA, Gemma, and Mistral architectures.
- Memory overhead during deployment drops because only one set of codebooks is stored.
Where Pith is reading between the lines
- The same additive structure might support on-the-fly bitwidth changes inside a single forward pass on heterogeneous hardware.
- If weight distributions deviate from Gaussian, the successive-refinement guarantee would require a different codebook design or distortion measure.
- Deployment pipelines could replace multiple quantized checkpoints with one model plus a small set of additive codebooks.
- The method opens a route to unified training that targets several hardware tiers simultaneously.
Load-bearing premise
LLM weights follow a Gaussian distribution and weighted mean squared error is the right distortion measure for measuring reconstruction quality.
What would settle it
Measuring whether adding successive codebooks produces a strictly decreasing reconstruction error that matches the information-theoretic bound for successive refinement of a Gaussian source under the chosen weighted MSE.
Figures




read the original abstract
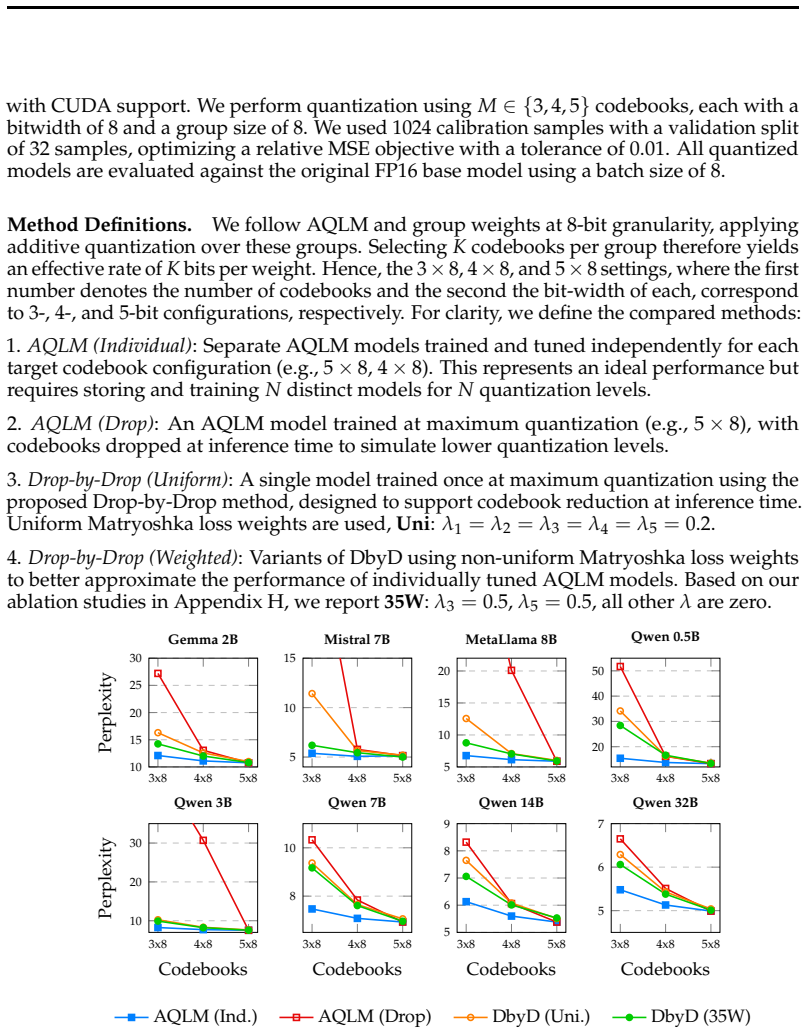
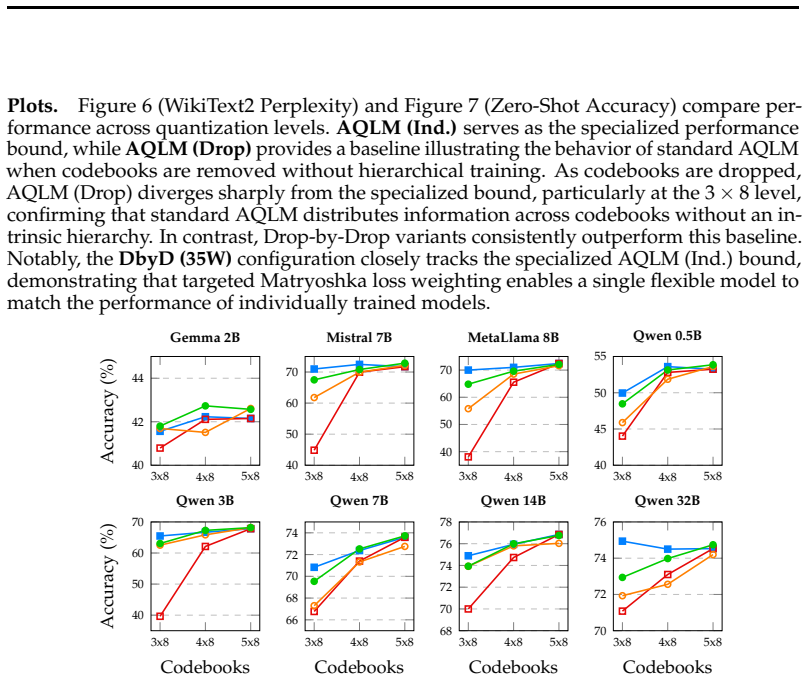
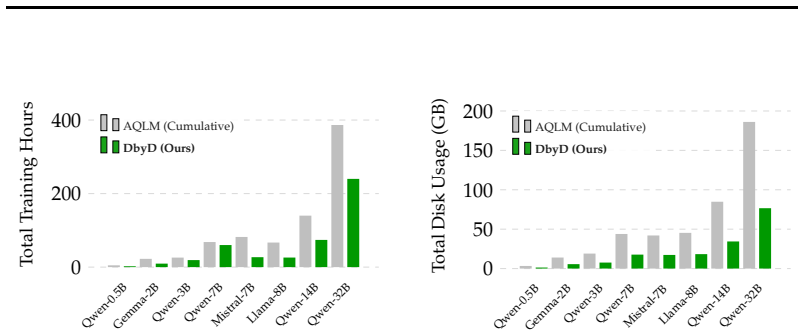
As large language models (LLMs) are increasingly deployed across heterogeneous hardware with varying resource constraints, the ability to adaptively manage the trade-off between performance and efficiency without retraining is critical. We propose Drop-by-Drop, a novel multi-bitwidth post-training quantization framework that enables inference-time precision control over LLM weights from a single trained model. Our method is theoretically grounded in information theory and successive refinement. We establish that LLM weights, which commonly follow a Gaussian distribution, can be optimally reconstructed with increasing fidelity as additional bits are incorporated, under a weighted mean squared error distortion motivated by LLM loss functions. To realize this in practice, Drop-by-Drop incorporates Matryoshka-style supervision into the loss function, exploiting the structure of additive codebooks. Drop-by-Drop produces a single model where ordered subsets of codebooks yield accurate partial reconstructions at each precision level. This approach significantly reduces storage and memory overhead by allowing a single checkpoint to serve multiple bitwidths, while maintaining competitive perplexity and accuracy across major architectures, such as Qwen, LLaMA, Gemma, and Mistral.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Drop-by-Drop, a post-training quantization framework for LLMs that uses additive codebooks combined with Matryoshka-style supervision to produce a single model supporting inference at multiple bitwidths. It claims this realizes information-theoretic successive refinement, allowing optimal reconstruction of Gaussian-distributed LLM weights with increasing fidelity under a weighted MSE distortion motivated by LLM loss functions, thereby reducing storage overhead while maintaining competitive perplexity and accuracy on models such as Qwen, LLaMA, Gemma, and Mistral.
Significance. If the successive-refinement optimality result holds and the empirical results generalize, the method would enable flexible multi-precision deployment from one checkpoint, addressing a practical deployment bottleneck for heterogeneous hardware without requiring separate models per bitwidth.
major comments (3)
- [Abstract] Abstract: The claim that LLM weights 'can be optimally reconstructed with increasing fidelity as additional bits are incorporated' under weighted MSE is presented as theoretically grounded in successive refinement, yet no derivation, rate-distortion analysis, or verification of the successive-refinability conditions for the chosen distortion is supplied; this is load-bearing for the central optimality assertion.
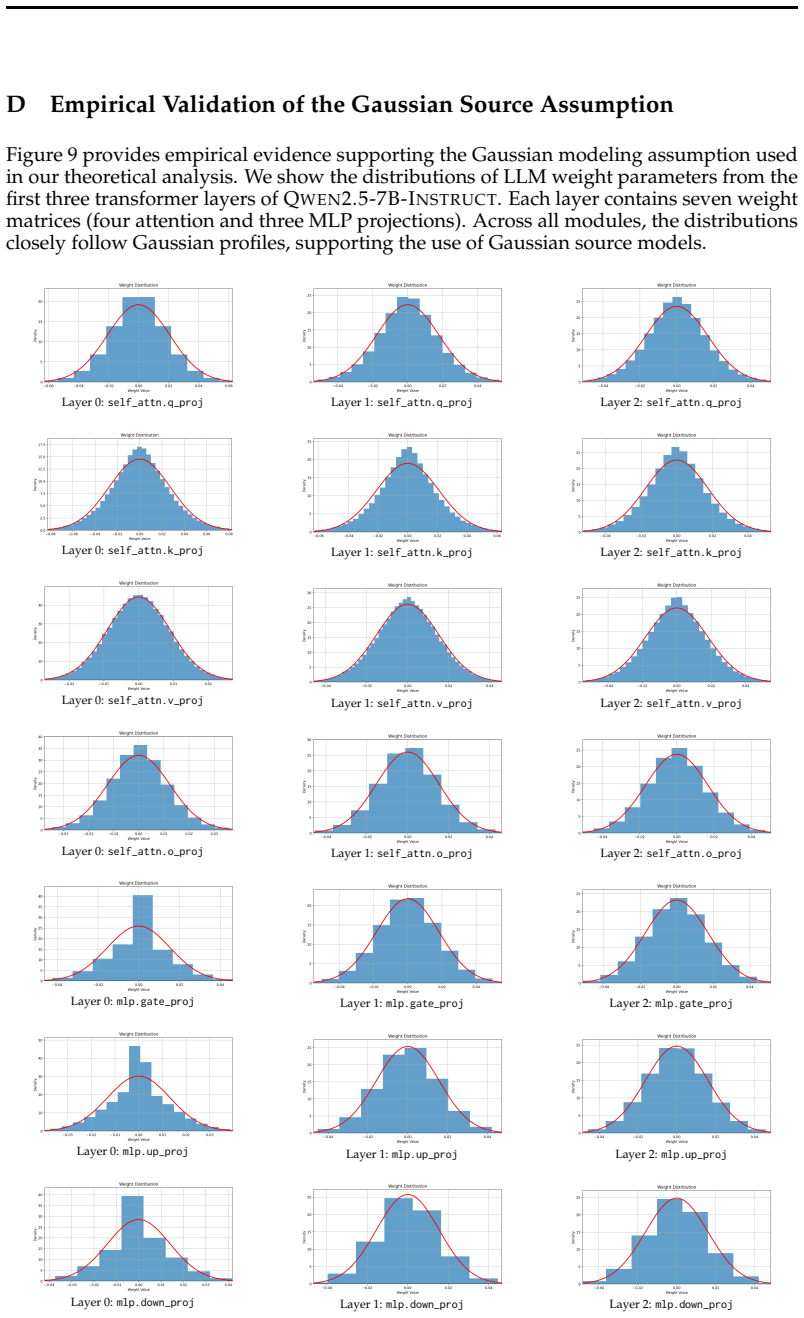
- [Abstract] Abstract: The Gaussian assumption on LLM weight distributions is invoked without any cited empirical verification, moment analysis, or reference to a specific section establishing its validity across the evaluated architectures; the optimality transfer from information theory to the additive-codebook construction depends on this premise.
- [Abstract] Abstract: The weighted MSE is described as 'motivated by LLM loss functions' but is not defined explicitly nor shown to align with actual downstream loss; without this link, the optimality claim risks circularity with post-hoc weighting choices.
minor comments (1)
- [Abstract] The abstract mentions 'ordered subsets of codebooks' but does not clarify how the additive structure interacts with the Matryoshka supervision in the loss; a brief equation or pseudocode would improve clarity.
Simulated Author's Rebuttal
We thank the referee for these precise comments on the abstract. Each point identifies a place where the presentation of the theoretical grounding can be strengthened. We will revise the manuscript to address them directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that LLM weights 'can be optimally reconstructed with increasing fidelity as additional bits are incorporated' under weighted MSE is presented as theoretically grounded in successive refinement, yet no derivation, rate-distortion analysis, or verification of the successive-refinability conditions for the chosen distortion is supplied; this is load-bearing for the central optimality assertion.
Authors: We agree the abstract states the optimality result without supplying the supporting derivation. The full manuscript develops the successive-refinement argument for additive codebooks under the weighted MSE, but the abstract itself does not reference the specific conditions or rate-distortion steps. In revision we will either (a) add a concise parenthetical outline of the key conditions or (b) point explicitly to the theorem establishing successive refinability, so the claim is no longer unsupported in the abstract. revision: yes
-
Referee: [Abstract] Abstract: The Gaussian assumption on LLM weight distributions is invoked without any cited empirical verification, moment analysis, or reference to a specific section establishing its validity across the evaluated architectures; the optimality transfer from information theory to the additive-codebook construction depends on this premise.
Authors: The manuscript states that LLM weights 'commonly follow a Gaussian distribution' but does not include the requested empirical checks or section reference in the abstract. We will add a short clause citing the relevant figure or appendix that reports weight histograms and moment statistics for the evaluated models (Qwen, LLaMA, Gemma, Mistral), thereby grounding the assumption. revision: yes
-
Referee: [Abstract] Abstract: The weighted MSE is described as 'motivated by LLM loss functions' but is not defined explicitly nor shown to align with actual downstream loss; without this link, the optimality claim risks circularity with post-hoc weighting choices.
Authors: The abstract uses the phrase 'motivated by LLM loss functions' without defining the weighting or demonstrating the link. We will revise the abstract to give the explicit form of the weighted MSE and add a one-sentence pointer to the section that derives the weighting from the LLM training objective, removing any appearance of circularity. revision: yes
Circularity Check
No significant circularity; derivation self-contained in information-theoretic claims
full rationale
The abstract presents the optimality result as established from information theory and successive refinement under a stated Gaussian assumption and a weighted MSE chosen to be motivated by (but not defined as identical to) LLM loss functions. No equations, self-citations, or fitted parameters are quoted that reduce the claimed reconstruction guarantee to a tautology or to the input data by construction. The Matryoshka supervision is described as a practical realization step rather than a definitional loop. The paper therefore remains self-contained against external benchmarks for its theoretical grounding.
Axiom & Free-Parameter Ledger
free parameters (1)
- codebook parameters and weighting in MSE
axioms (2)
- domain assumption LLM weights commonly follow a Gaussian distribution
- domain assumption Weighted mean squared error is the appropriate distortion measure motivated by LLM loss functions
Reference graph
Works this paper leans on
-
[1]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[3]
Advances in Neural Information Processing Systems , volume=
Matryoshka representation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
2025 International Joint Conference on Neural Networks (IJCNN) , pages=
Lsaq: Layer-specific adaptive quantization for large language model deployment , author=. 2025 International Joint Conference on Neural Networks (IJCNN) , pages=. 2025 , organization=
2025
-
[8]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive overview of large language models , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[13]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
2024 , howpublished =
Google , title =. 2024 , howpublished =
2024
-
[17]
arXiv preprint arXiv:2401.15347 , year=
A comprehensive survey of compression algorithms for language models , author=. arXiv preprint arXiv:2401.15347 , year=
-
[18]
A Simple and Effective Pruning Approach for Large Language Models
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter , author=. arXiv preprint arXiv:1910.01108 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[20]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[21]
Advances in Neural Information Processing Systems , volume=
Compressing large language models using low rank and low precision decomposition , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Albert: A lite bert for self-supervised learning of language representations , author=. arXiv preprint arXiv:1909.11942 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[23]
int8 (): 8-bit matrix multiplication for transformers at scale , author=
Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale , author=. Advances in neural information processing systems , volume=
-
[24]
Proceedings of machine learning and systems , volume=
Awq: Activation-aware weight quantization for on-device llm compression and acceleration , author=. Proceedings of machine learning and systems , volume=
-
[26]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Additive quantization for extreme vector compression , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Universally Slimmable Networks and Improved Training Techniques , year=
Yu, Jiahui and Huang, Thomas , booktitle=. Universally Slimmable Networks and Improved Training Techniques , year=
-
[28]
Advances in neural information processing systems , volume=
Dynamicvit: Efficient vision transformers with dynamic token sparsification , author=. Advances in neural information processing systems , volume=
-
[29]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Fastbert: a self-distilling bert with adaptive inference time , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[30]
Proceedings of the ACM SIGCOMM 2024 Conference , pages=
Cachegen: Kv cache compression and streaming for fast large language model serving , author=. Proceedings of the ACM SIGCOMM 2024 Conference , pages=
2024
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Adabits: Neural network quantization with adaptive bit-widths , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
Workshop on Machine Learning and Compression, NeurIPS 2024 , year =
AdaQuantLM: LLM Quantization with Adaptive Bit-Widths , author=. Workshop on Machine Learning and Compression, NeurIPS 2024 , year =
2024
-
[34]
International Conference on Machine Learning (ICML) , year=
Rethinking Lossy Compression: The Rate-Distortion-Perception Tradeoff , author=. International Conference on Machine Learning (ICML) , year=
-
[35]
Sensors , volume=
Approximate nearest neighbor search by residual vector quantization , author=. Sensors , volume=. 2010 , publisher=
2010
-
[36]
IEEE Transactions on information theory , volume=
Successive refinement of information , author=. IEEE Transactions on information theory , volume=. 1991 , publisher=
1991
-
[37]
2006 , publisher=
Elements of information theory , author=. 2006 , publisher=
2006
-
[38]
IEEE Transactions on Information Theory , volume=
All Sources Are Nearly Successively Refinable , author=. IEEE Transactions on Information Theory , volume=. 2001 , publisher=
2001
-
[39]
Elements of Information Theory , pages=
Rate distortion theory , author=. Elements of Information Theory , pages=
-
[40]
1989 , school=
Successive Refinement of Information , author=. 1989 , school=
1989
-
[41]
, title =
Sakrison, David J. , title =. IEEE Transactions on Information Theory , year =
-
[43]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[46]
Journal of Machine Learning Research , volume=
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer , author=. Journal of Machine Learning Research , volume=
-
[47]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[48]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[49]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[51]
2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW) , pages=
Learning multi-rate vector quantization for remote deep inference , author=. 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW) , pages=. 2023 , organization=
2023
-
[53]
2024 , howpublished =
Tianxiang Chu , title =. 2024 , howpublished =
2024
-
[54]
Advances in Neural Information Processing Systems , volume=
Matryoshka query transformer for large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Vptq: Extreme low-bit vector post-training quantization for large language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[56]
Proceedings of machine learning research , volume=
Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks , author=. Proceedings of machine learning research , volume=
-
[59]
Additive quantization for extreme vector compression
Artem Babenko and Victor Lempitsky. Additive quantization for extreme vector compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp.\ 931--938, 2014
2014
-
[60]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 7432--7439, 2020
2020
-
[61]
Adaquantlm: Llm quantization with adaptive bit-widths
Shuangyi Chen and Ashish J Khisti. Adaquantlm: Llm quantization with adaptive bit-widths. In Workshop on Machine Learning and Compression, NeurIPS 2024, 2024
2024
-
[62]
Approximate nearest neighbor search by residual vector quantization
Yongjian Chen, Tao Guan, and Cheng Wang. Approximate nearest neighbor search by residual vector quantization. Sensors, 10 0 (12): 0 11259--11273, 2010
2010
-
[63]
Quip‑for‑all: Unified quip implementation for llm quantization
Tianxiang Chu. Quip‑for‑all: Unified quip implementation for llm quantization. https://github.com/chu‑tianxiang/QuIP‑for‑all, 2024. Accessed: 2026
2024
-
[64]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[65]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas. Elements of information theory. John Wiley & Sons, 2 edition, 2006
2006
-
[66]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems, 35: 0 30318--30332, 2022
2022
-
[67]
Extreme compression of large language models via additive quantization
Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, and Dan Alistarh. Extreme compression of large language models via additive quantization. arXiv preprint arXiv:2401.06118, 2024
-
[68]
Successive Refinement of Information
William Howard Robinson Equitz. Successive Refinement of Information. PhD thesis, Stanford University, 1989
1989
-
[69]
Successive refinement of information
William HR Equitz and Thomas M Cover. Successive refinement of information. IEEE Transactions on information theory, 37 0 (2): 0 269--275, 1991
1991
-
[70]
Remote inference over dynamic links via adaptive rate deep task-oriented vector quantization
Eyal Fishel, May Malka, Shai Ginzach, and Nir Shlezinger. Remote inference over dynamic links via adaptive rate deep task-oriented vector quantization. arXiv preprint arXiv:2501.02521, 2025
-
[71]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[72]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Matryoshka query transformer for large vision-language models
Wenbo Hu, Zi-Yi Dou, Liunian Li, Amita Kamath, Nanyun Peng, and Kai-Wei Chang. Matryoshka query transformer for large vision-language models. Advances in Neural Information Processing Systems, 37: 0 50168--50188, 2024
2024
-
[74]
Residual quantization with implicit neural codebooks
Iris AM Huijben, Matthijs Douze, Matthew Muckley, Ruud JG Van Sloun, and Jakob Verbeek. Residual quantization with implicit neural codebooks. arXiv preprint arXiv:2401.14732, 2024
-
[75]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
Adabits: Neural network quantization with adaptive bit-widths
Qing Jin, Linjie Yang, and Zhenyu Liao. Adabits: Neural network quantization with adaptive bit-widths. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 2146--2156, 2020
2020
-
[77]
Matryoshka representation learning
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning. Advances in Neural Information Processing Systems, 35: 0 30233--30249, 2022
2022
-
[78]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Proceedings of machine learning and systems, 6: 0 87--100, 2024
2024
-
[79]
Fastbert: a self-distilling bert with adaptive inference time
Weijie Liu, Peng Zhou, Zhiruo Wang, Zhe Zhao, Haotang Deng, and Qi Ju. Fastbert: a self-distilling bert with adaptive inference time. In Proceedings of the 58th annual meeting of the association for computational linguistics, pp.\ 6035--6044, 2020
2020
-
[80]
Vptq: Extreme low-bit vector post-training quantization for large language models
Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, and Mao Yang. Vptq: Extreme low-bit vector post-training quantization for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 8181--8196, 2024 a
2024
-
[81]
Cachegen: Kv cache compression and streaming for fast large language model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. Cachegen: Kv cache compression and streaming for fast large language model serving. In Proceedings of the ACM SIGCOMM 2024 Conference, pp.\ 38--56, 2024 b
2024
-
[82]
Learning multi-rate vector quantization for remote deep inference
May Malka, Shai Ginzach, and Nir Shlezinger. Learning multi-rate vector quantization for remote deep inference. In 2023 IEEE International Conference on Acoustics, Speech, and Signal Processing Workshops (ICASSPW), pp.\ 1--5. IEEE, 2023
2023
-
[83]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[84]
Pranav Nair, Puranjay Datta, Jeff Dean, Prateek Jain, and Aditya Kusupati. Matryoshka quantization. arXiv preprint arXiv:2502.06786, 2025
-
[85]
A comprehensive overview of large language models
Humza Naveed, Asad Ullah Khan, Shi Qiu, Muhammad Saqib, Saeed Anwar, Muhammad Usman, Naveed Akhtar, Nick Barnes, and Ajmal Mian. A comprehensive overview of large language models. ACM Transactions on Intelligent Systems and Technology, 16 0 (5): 0 1--72, 2025
2025
-
[86]
Anybcq: Hardware efficient flexible binary-coded quantization for multi-precision llms
Gunho Park, Jeongin Bae, Beomseok Kwon, Byeongwook Kim, Se Jung Kwon, and Dongsoo Lee. Anybcq: Hardware efficient flexible binary-coded quantization for multi-precision llms. arXiv preprint arXiv:2510.10467, 2025
-
[87]
Any-precision llm: Low-cost deployment of multiple, different-sized llms
Yeonhong Park, Jake Hyun, SangLyul Cho, Bonggeun Sim, and Jae W Lee. Any-precision llm: Low-cost deployment of multiple, different-sized llms. arXiv preprint arXiv:2402.10517, 2024
-
[88]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21 0 (140): 0 1--67, 2020
2020
-
[89]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. Advances in neural information processing systems, 34: 0 13937--13949, 2021
2021
-
[90]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp.\ 8732--8740, 2020
2020
-
[91]
Sakrison
David J. Sakrison. The rate distortion function for a gaussian process with a weighted square error criterion. IEEE Transactions on Information Theory, 14 0 (5): 0 506–508, 1968
1968
-
[92]
Resq: Mixed-precision quantization of large language models with low-rank residuals
Utkarsh Saxena, Sayeh Sharify, Kaushik Roy, and Xin Wang. Resq: Mixed-precision quantization of large language models with low-rank residuals. arXiv preprint arXiv:2412.14363, 2024
-
[93]
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi \`e re, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[94]
Qwen Team. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[95]
Algorithmic progress in language models: A decomposition of perplexity
Nicholas Thompson, Enric Carr, Christopher Chiang, Johannes Erner, Maarten Hobbhahn, Sara Hooker, William Mann, David Wallace, and Jason Wei. Algorithmic progress in language models: A decomposition of perplexity. arXiv preprint arXiv:2505.04075, 2024
-
[96]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothee Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[97]
Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks
Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa. Quip\#: Even better llm quantization with hadamard incoherence and lattice codebooks. Proceedings of machine learning research, 235: 0 48630, 2024
2024
-
[98]
Qinco2: Vector compression and search with improved implicit neural codebooks
Th \'e ophane Vallaeys, Matthew Muckley, Jakob Verbeek, and Matthijs Douze. Qinco2: Vector compression and search with improved implicit neural codebooks. arXiv preprint arXiv:2501.03078, 2025
-
[99]
Are we there yet? a measurement study of efficiency for llm applications on mobile devices
Xiao Yan and Yi Ding. Are we there yet? a measurement study of efficiency for llm applications on mobile devices. arXiv preprint arXiv:2504.00002, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.