Beyond Runtime Enforcement: Shield Synthesis as Defensibility Analysis for Adversarial Networks
Pith reviewed 2026-06-27 06:37 UTC · model grok-4.3
The pith
Shield synthesis serves as a design-time tool for producing defensibility verdicts on network topologies rather than runtime constraints on agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Shield synthesis applied to a constrained two-player safety game for network defense yields a defensibility verdict—a formal certificate that a topology-specification pair is or is not defensible—along with the associated winning region and shield; the verdict and derived attractor metrics, when combined with post-convergence reinforcement-learning behavior, form a defensibility fingerprint whose primary value lies in answering architectural questions about whether, where, and how a system can be defended.
What carries the argument
The asymmetric two-player safety game in which the defender specification defines the unsafe region of the game and the attacker specification restricts the adversary's legal actions during attractor computation.
If this is right
- Formal defensibility verdicts and operational effectiveness under adaptive reinforcement learning capture distinct aspects of security.
- Small architectural changes can produce large shifts in operational outcomes while leaving formal safety margins nearly unchanged.
- The winning region and shield supply structural information about where and how defense is possible within a given topology.
- The combination of attractor-derived metrics and post-convergence RL traces forms a defensibility fingerprint usable for design-time comparison of topology-specification pairs.
Where Pith is reading between the lines
- The separation of formal and operational metrics suggests that security evaluation benefits from running both analyses rather than relying on either alone.
- Designers could use the defensibility verdict to rank candidate topologies before committing to reinforcement-learning training.
- The same game-construction technique might be reused to compare alternative specifications on a fixed network without retraining agents.
Load-bearing premise
The assumption that the asymmetric game construction and its combination with post-convergence RL behavior produce metrics that meaningfully capture real-world defensibility.
What would settle it
A controlled experiment in which the formal defensibility verdict and fingerprint metrics fail to predict actual attack success rates under adaptive adversaries in a simulated network would falsify the claim that these outputs capture meaningful defensibility.
Figures

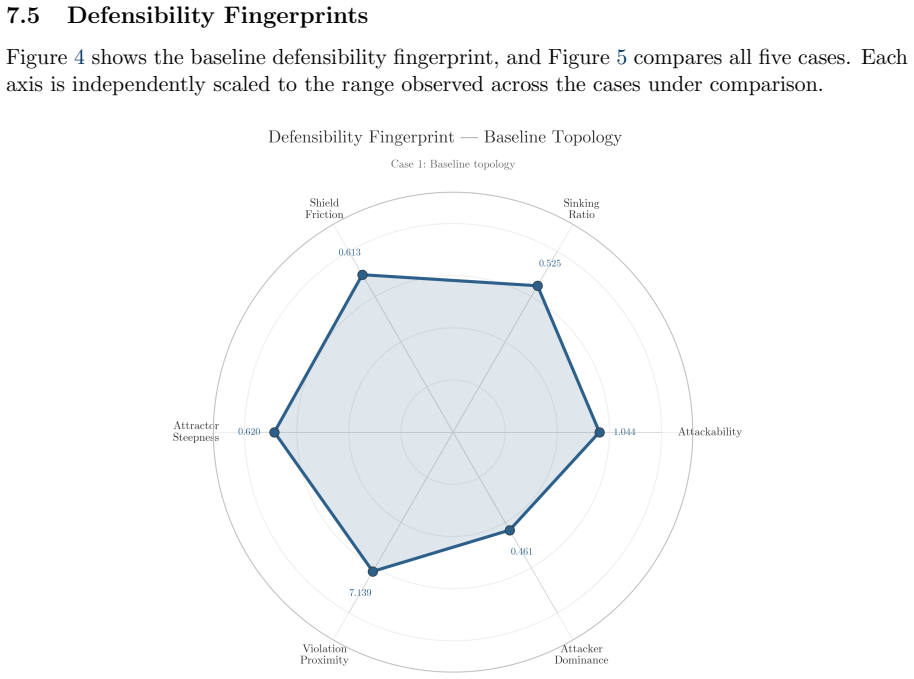
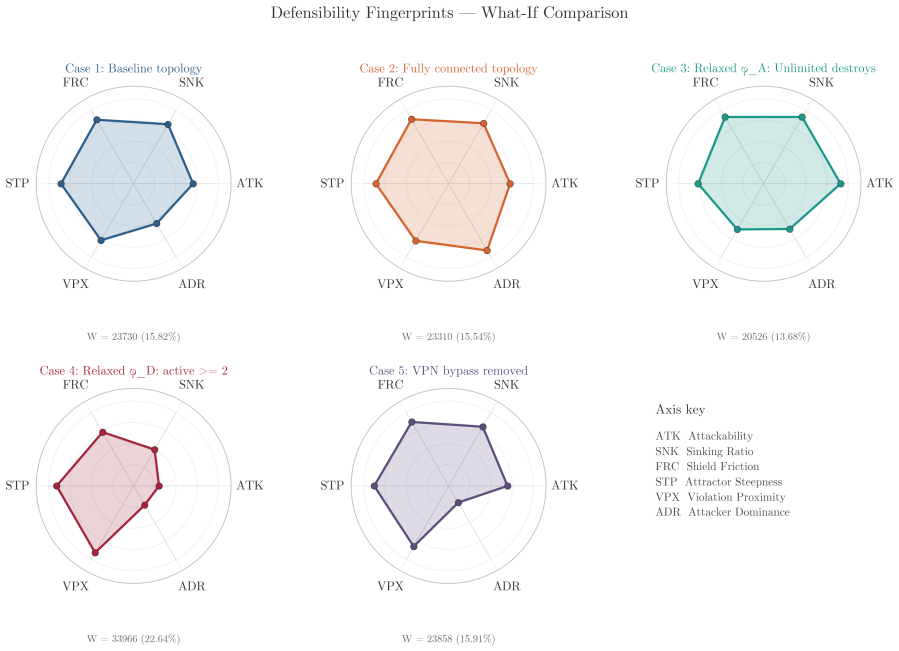
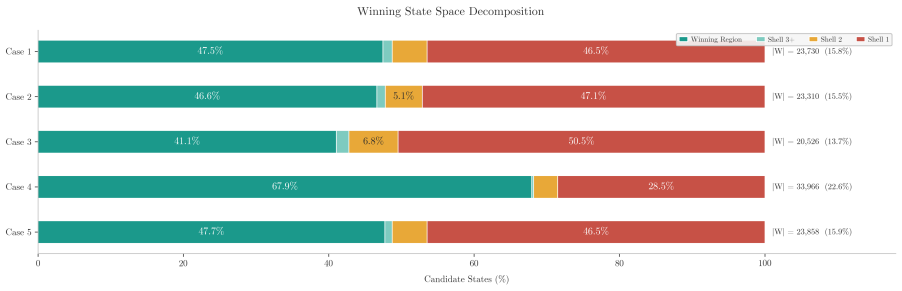
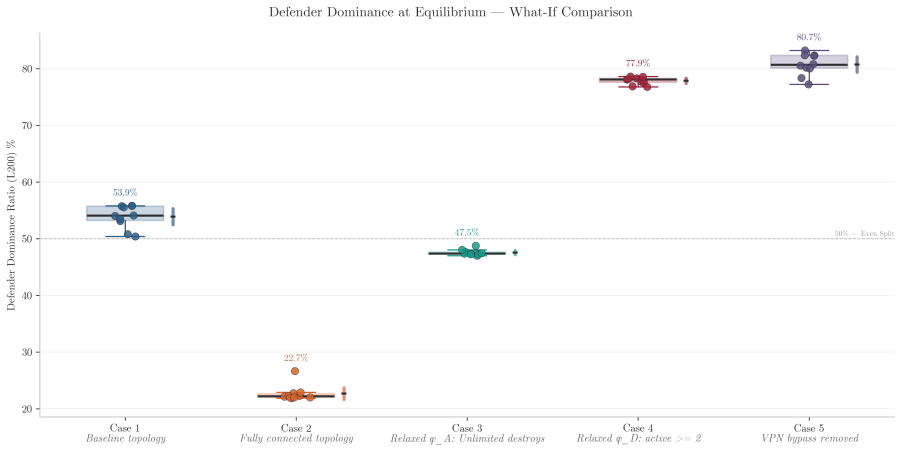
read the original abstract
Shielded reinforcement learning is typically presented as a runtime safety mechanism that compiles temporal-logic specifications into automata restricting an agent's actions. We argue this is the wrong product. The same automata-theoretic machinery -- specification compilation, product game construction, attractor computation, and winning-region extraction -- is better read as a design-time analytical instrument whose outputs are structural insights about a system rather than runtime constraints on a deployed agent. We instantiate this through a constrained two-player safety game for network defense. The two specifications are enforced asymmetrically: the defender specification defines the unsafe region of the game, whereas the attacker specification restricts the adversary's legal actions during attractor computation. Solving the game yields a defensibility verdict -- a formal certificate that a topology-specification pair is or is not defensible -- with the associated winning region and shield. Beyond the binary verdict, we derive topology-level metrics from the attractor structure and combine them with post-convergence behavior from shield-constrained adversarial multi-agent reinforcement learning. Together these form a defensibility fingerprint capturing both a network's formal safety properties and its operational behavior under adaptive play. A what-if analysis shows that formal defensibility and operational effectiveness capture distinct aspects of security: small architectural changes can produce large shifts in operational outcomes while leaving formal safety margins nearly unchanged. Shield synthesis is thus most valuable not as a deployment mechanism for safe agents, but as a framework for answering architectural questions about whether, where, and how a system can be defended. The defensibility verdict is the output, not the safe policy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that shield synthesis from temporal-logic specifications should be reinterpreted as a design-time analytical framework for defensibility analysis in adversarial networks, rather than primarily a runtime enforcement mechanism. It constructs an asymmetric two-player safety game in which the defender specification defines the unsafe region while the attacker specification restricts adversary actions during attractor computation; solving the game yields a binary defensibility verdict, winning region, and shield. Attractor-derived topology metrics are then combined with post-convergence behavior from shield-constrained multi-agent RL to produce a 'defensibility fingerprint' that captures both formal and operational aspects. A what-if analysis is presented to show that formal safety margins and operational effectiveness under adaptive play are distinct, with small architectural changes affecting the latter more than the former.
Significance. If the what-if results and metric derivations hold under scrutiny, the work provides a constructive way to leverage automata-theoretic machinery for architectural questions in network defense, moving beyond deployment-focused uses of shields. The explicit separation of formal verdict from operational fingerprint, grounded in standard game constructions plus RL, is a positive contribution that could inform design choices in adversarial multi-agent settings. The emphasis on the verdict itself as the primary output rather than the policy is a clear conceptual reframing.
major comments (2)
- [§4] §4 (Game Construction): The central claim that the asymmetric enforcement (defender unsafe region vs. attacker action restriction during attractor computation) produces a meaningful defensibility verdict rests on the adaptation of standard attractor algorithms. The manuscript must supply the precise modified attractor definition or pseudocode, because the standard fixed-point computation does not automatically accommodate action restrictions without additional choices that could affect the winning-region extraction.
- [§6] §6 (What-if Analysis): The divergence between formal margins and operational outcomes is load-bearing for the claim that the two capture distinct aspects. The specific network parameterizations, RL convergence criteria, and adversary models used in the experiments must be stated explicitly; without them it remains possible that the observed distinction is an artifact of the chosen modeling decisions rather than a general property of the fingerprint.
minor comments (2)
- [Abstract] The term 'defensibility fingerprint' is used repeatedly but never given an explicit equation or boxed definition; adding one would improve readability.
- [§3] Notation for the product game and winning regions should be cross-referenced to a standard reference (e.g., the exact attractor algorithm employed) to aid readers familiar with the literature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of the game construction and experimental details. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Game Construction): The central claim that the asymmetric enforcement (defender unsafe region vs. attacker action restriction during attractor computation) produces a meaningful defensibility verdict rests on the adaptation of standard attractor algorithms. The manuscript must supply the precise modified attractor definition or pseudocode, because the standard fixed-point computation does not automatically accommodate action restrictions without additional choices that could affect the winning-region extraction.
Authors: We agree that an explicit definition of the restricted attractor is required. Section 4 describes the asymmetry (defender unsafe region vs. attacker action restriction) but does not provide the modified fixed-point operator. In the revision we will insert the formal definition of the action-restricted attractor together with pseudocode for the fixed-point iteration, making clear that the restriction is applied uniformly at each predecessor step and does not introduce nondeterministic choices beyond the standard safety-game semantics. revision: yes
-
Referee: [§6] §6 (What-if Analysis): The divergence between formal margins and operational outcomes is load-bearing for the claim that the two capture distinct aspects. The specific network parameterizations, RL convergence criteria, and adversary models used in the experiments must be stated explicitly; without them it remains possible that the observed distinction is an artifact of the chosen modeling decisions rather than a general property of the fingerprint.
Authors: We accept that the experimental setup must be fully specified. The current manuscript gives only high-level descriptions of the networks and RL procedure. In the revision we will add a dedicated subsection (or appendix) listing the exact topologies, edge weights, RL hyperparameters, convergence criteria (episode count, reward threshold, and variance tolerance), and adversary action spaces. This will allow independent verification that the reported separation between formal and operational metrics is not an artifact of particular modeling choices. revision: yes
Circularity Check
No significant circularity; standard constructions reframed without reduction to inputs
full rationale
The paper reframes existing automata-theoretic machinery (specification compilation, product game construction, attractor computation, winning-region extraction) as a design-time analysis tool rather than a runtime enforcer. It constructs an asymmetric safety game where defender and attacker specifications are applied differently, derives topology metrics from the attractor, and combines them with post-convergence shield-constrained multi-agent RL behavior to form a defensibility fingerprint. The what-if analysis then shows divergence between formal margins and operational outcomes. No quoted equations or steps reduce the central claims to fitted parameters, self-definitions, or self-citation chains; the constructions rely on standard game theory and RL without the target verdict or fingerprint being presupposed in the inputs. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Temporal logic specifications can be compiled into automata that correctly define unsafe regions and action restrictions in a two-player game.
- domain assumption Attractor computation and winning-region extraction yield a meaningful defensibility verdict for network topologies.
Reference graph
Works this paper leans on
-
[1]
M. Alshiekh, R. Bloem, R. Ehlers, B. K¨ onighofer, S. Niekum, and U. Topcu. Safe reinforcement learning via shielding. InProc. AAAI, pp. 2669–2678, 2018. 23 doi:10.1609/aaai.v32i1.11797
-
[2]
R. Bloem, B. K¨ onighofer, R. K¨ onighofer, and C. Wang. Shield synthesis: Runtime enforce- ment for reactive systems. InProc. TACAS, LNCS vol. 9035, Springer, pp. 533–548, 2015. doi:10.1007/978-3-662-46681-0 51
-
[3]
B. K¨ onighofer, M. Alshiekh, R. Bloem, L. R. Humphrey, R. K¨ onighofer, U. Topcu, and C. Wang. Shield synthesis.Formal Methods in System Design, 51(2):332–361, 2017. doi:10.1007/s10703-017-0276-9
-
[4]
B. K¨ onighofer, R. Bloem, N. Jansen, S. Junges, and S. Pranger. Shields for safe reinforce- ment learning.Communications of the ACM, 68(11):80–90, 2025. doi:10.1145/3715958
-
[5]
N. Jansen, B. K¨ onighofer, S. Junges, A. Serban, and R. Bloem. Safe reinforcement learning using probabilistic shields. InProc. CONCUR, LIPIcs vol. 171, Schloss Dagstuhl–Leibniz- Zentrum f¨ ur Informatik, article 3, pp. 3:1–3:16, 2020. doi:10.4230/LIPIcs.CONCUR.2020.3
-
[6]
E. Hamel-De le Court, F. Belardinelli, and A. W. Goodall. Probabilistic shield- ing for safe reinforcement learning. InProc. AAAI, 39(15):16091–16099, 2025. doi:10.1609/aaai.v39i15.33767
-
[7]
S. Carr, N. Jansen, S. Junges, and U. Topcu. Safe reinforcement learning via shielding under partial observability. InProc. AAAI, pp. 14748–14756, 2023. doi:10.1609/aaai.v37i12.26723
-
[8]
Melcer, C
D. Melcer, C. Amato, and S. Tripakis. Shield decomposition for safe reinforcement learning in general partially observable multi-agent environments.Reinforcement Learning Journal, 4:1965–1994, 2024
1965
-
[9]
Tappler, S
M. Tappler, S. Pranger, B. K¨ onighofer, E. Muˇ skardin, R. Bloem, and K. G. Larsen. Au- tomata learning meets shielding. InProc. ISoLA, LNCS vol. 13701, Springer, pp. 335–359,
-
[10]
doi:10.1007/978-3-031-19849-6 20
-
[11]
Brunke, M
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning.Annual Review of Control, Robotics, and Autonomous Systems, 5:411–444, 2022
2022
-
[12]
E. Gr¨ adel, W. Thomas, and T. Wilke, editors.Automata, Logics, and Infinite Games: A Guide to Current Research. LNCS vol. 2500, Springer, 2002. doi:10.1007/3-540-36387-4
-
[13]
Baier and J.-P
C. Baier and J.-P. Katoen.Principles of Model Checking. MIT Press, 2008
2008
-
[14]
M. L. Littman. Markov games as a framework for multi-agent reinforcement learning. In Proc. ICML, pp. 157–163, Morgan Kaufmann, 1994
1994
-
[15]
M. L. Littman and C. Szepesv´ ari. A generalized reinforcement-learning model: Conver- gence and applications. InProc. ICML, pp. 310–318, 1996
1996
-
[16]
ElSayed-Aly, S
I. ElSayed-Aly, S. Bharadwaj, C. Amato, R. Ehlers, U. Topcu, and L. Feng. Safe multi- agent reinforcement learning via shielding. InProc. AAMAS, IFAAMAS, pp. 483–491, 2021
2021
-
[17]
W. Xiao, Y. Lyu, and J. M. Dolan. Model-based dynamic shielding for safe and efficient multi-agent reinforcement learning. arXiv:2304.06281, 2023
arXiv 2023
-
[18]
(eds.) Classifica- tion of Security Properties: (Part II: Net- work Security)
K. Chatterjee, T. A. Henzinger, and B. Jobstmann. Environment assumptions for synthesis. InProc. CONCUR, LNCS vol. 5201, Springer, pp. 147–161, 2008. doi:10.1007/978-3-540- 85361-9 14. 24
-
[19]
N. Piterman, A. Pnueli, and Y. Sa’ar. Synthesis of Reactive(1) designs. InProc. VMCAI, LNCS vol. 3855, Springer, pp. 364–380, 2006. doi:10.1007/11609773 24
-
[20]
CybORG: Cyber Operations Research Gym
CAGE Challenge. CybORG: Cyber Operations Research Gym. GitHub repository,https: //github.com/cage-challenge/CybORG, 2023
2023
-
[21]
M. Standen, M. Lucas, D. Bowman, T. J. Richer, J. Kim, and D. Marriott. CybORG: A gym for the development of autonomous cyber agents. arXiv:2108.09118, 2021
arXiv 2021
-
[22]
M. Kiely, M. Ahiskali, E. Borde, B. Bowman, D. Bowman, D. Van Bruggen, K. C. Cowan, P. Dasgupta, E. Devendorf, B. Edwards, A. Fitts, S. Fugate, R. Gabrys, W. Gould, H. H. Huang, J. Jacobs, R. Kerr, I. J. King, L. Li, L. Martinez, C. Moir, C. Murphy, O. Naish, C. Owens, M. Purchase, A. Ridley, A. Taylor, S. Farmer, W. J. Valentine, and Y. Zhang. CAGE chall...
-
[23]
P. K. Manadhata and J. M. Wing. Measuring a system’s attack surface. Technical Report CMU-CS-04-102, School of Computer Science, Carnegie Mellon University, 2004
2004
-
[24]
L. Wang, A. Singhal, and S. Jajodia. Measuring the overall security of network configura- tions using attack graphs. InProc. DBSec, LNCS vol. 4602, Springer, pp. 98–112, 2007. doi:10.1007/978-3-540-73538-0 9
-
[25]
J. Pamula, S. Jajodia, P. Ammann, and V. Swarup. A weakest-adversary security met- ric for network configuration security analysis. InProc. QoP, ACM, pp. 31–38, 2006. doi:10.1145/1179494.1179502
-
[26]
K. Zenitani. Attack graph analysis: An explanatory guide.Computers & Security, 126:103081, 2023. doi:10.1016/j.cose.2022.103081
-
[27]
L. Wang, T. Islam, T. Long, A. Singhal, and S. Jajodia. An attack graph-based probabilis- tic security metric. InData and Applications Security XXII, LNCS vol. 5094, Springer, pp. 283–296, 2008. doi:10.1007/978-3-540-70567-3 22
-
[28]
Klaˇ ska, A
D. Klaˇ ska, A. Kuˇ cera, V. Musil, and V.ˇReh´ ak. Regstar: Efficient strategy synthesis for adversarial patrolling games. InProc. UAI, PMLR vol. 161, pp. 471–481, 2021
2021
-
[29]
D. Shishika, Y. Guan, J. R. Marden, M. Dorothy, P. Tsiotras, and V. Kumar. Dynamic adversarial resource allocation: The dDAB game. arXiv:2304.02172, 2023
arXiv 2023
-
[30]
Batfish: An open source network configuration analysis tool.https://www.batfish.org, 2023
The Batfish Open Source Project. Batfish: An open source network configuration analysis tool.https://www.batfish.org, 2023
2023
-
[31]
Kazemian, G
P. Kazemian, G. Varghese, and N. McKeown. Header space analysis: Static checking for networks. InProc. NSDI, pp. 113–126, USENIX Association, 2012
2012
-
[32]
Kiekintveld, M
C. Kiekintveld, M. Jain, J. Tsai, J. Pita, F. Ord´ o˜ nez, and M. Tambe. Computing optimal randomized resource allocations for massive security games. InProc. AAMAS, IFAAMAS, pp. 689–696, 2009. A Empirical Correlation Structure of the Defensibility Metrics Section 5 introduces six conceptually distinct metrics. The empirical relationships among them, eval...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.