Entropy-Gated Latent Recursion
Pith reviewed 2026-07-01 07:43 UTC · model grok-4.3
The pith
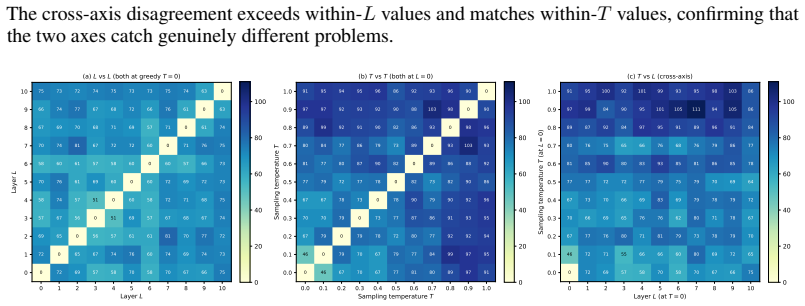
Varying the layer span at high-entropy tokens supplies a deterministic complement to temperature sampling that raises joint oracle accuracy on math reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
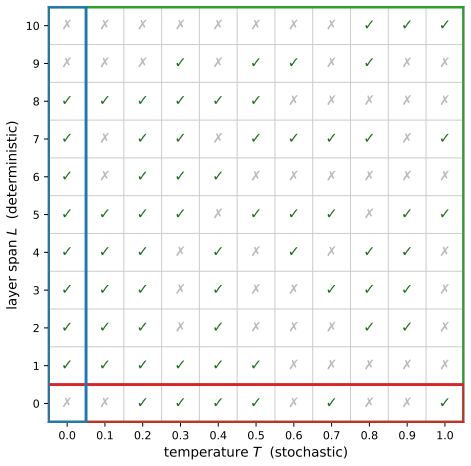
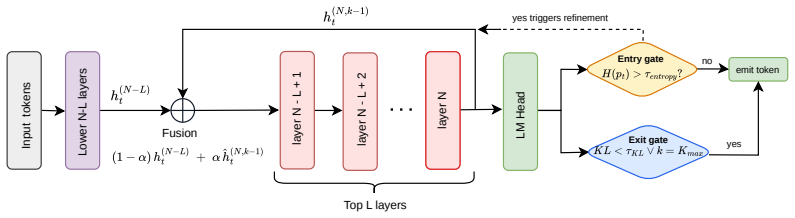
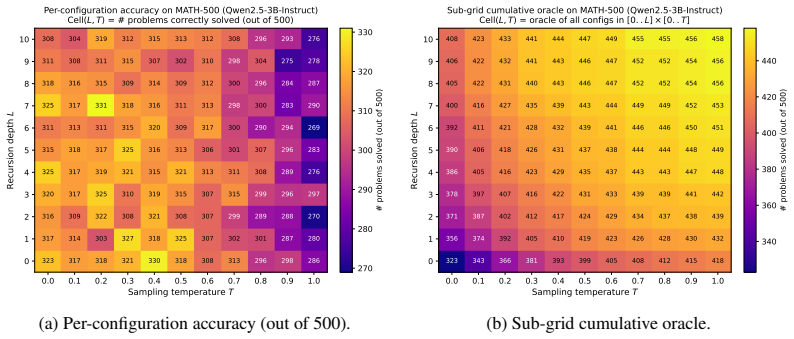
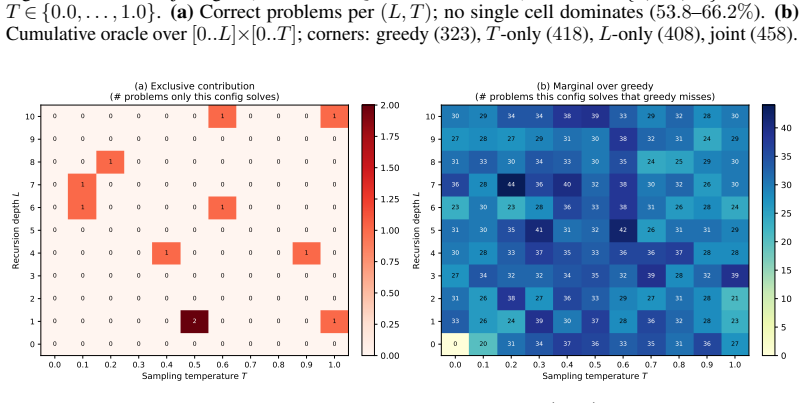
Entropy-Gated Latent Recursion re-applies the top-L decoder layers for at most K_max iterations at tokens whose entropy exceeds a threshold until the next-token distribution converges; different fixed choices of L generate deterministic rollouts whose solved problem sets differ from those obtained by varying temperature alone. On MATH-500 with Qwen2.5-3B-Instruct the joint L×T oracle reaches 91.6 percent, 8.2 points above the temperature-only oracle and 10.4 points above the layer-only oracle; the same pattern of additive gains holds across eight instruction-tuned models and six math benchmarks.
What carries the argument
Entropy-Gated Latent Recursion (EGLR), the deterministic procedure that selects high-entropy tokens and recurses the top-L layers until distributional convergence.
If this is right
- Any rollout-consuming procedure (self-consistency, best-of-N, GRPO) receives a larger and more diverse candidate set at nearly the same per-rollout cost.
- Inference-time scaling can be performed without increasing reliance on stochastic noise.
- The method requires no additional training and applies to any frozen instruction-tuned model.
- The two axes remain complementary across at least eight models and six math benchmarks.
Where Pith is reading between the lines
- The same gating idea could be applied to other internal states besides layer span, such as attention-head subsets or KV-cache compression levels.
- If convergence speed correlates with problem difficulty, early stopping on L could serve as an implicit difficulty signal for routing.
- The Cartesian product structure suggests that further deterministic axes could be stacked without interfering with temperature sampling.
Load-bearing premise
Different fixed layer spans at entropy-gated tokens produce rollouts whose solution sets differ sufficiently from temperature-sampled rollouts to produce additive oracle gains.
What would settle it
A replication in which the L×T joint oracle accuracy never exceeds the maximum of the separate L-only and T-only oracles on any model or benchmark would falsify the claim of complementarity.
Figures
read the original abstract
Inference-time scaling has become the dominant lever for improving language-model reasoning, but existing methods derive rollout diversity from a single source: stochastic token-level sampling. We argue that this single-axis sampling space is fundamentally limiting, and identify a second, fully deterministic and complementary axis: the layer span $L$ at which a frozen model's top decoder layers are recursively re-applied at high-uncertainty tokens. Different choices of $L$ produce distinct rollouts that solve different subsets of problems, with no stochasticity. We instantiate this axis through Entropy-Gated Latent Recursion (EGLR), a training-free decoding procedure that re-applies the top-$L$ layers for at most $K_{\max}$ iterations until the next-token distribution converges. Combined with $T$ temperature samples, EGLR turns a single-axis stochastic rollout pool into an $L\times T$ Cartesian sampling space at almost the same per-rollout cost. We characterize this space across $8$ instruction-tuned models and $6$ math reasoning benchmarks, and show that the $L$-axis is genuinely complementary to temperature: on MATH-500 with Qwen2.5-3B-Instruct, the joint $L\times T$ oracle reaches $91.6\%$, $+8.2$ percentage points beyond the temperature-only oracle ($83.4\%$) and $+10.4$ points beyond the layer-only oracle ($81.2\%$), confirming that the two axes capture genuinely complementary problems. The expanded rollout pool provides richer per-prompt candidates for any downstream procedure that consumes rollouts, including self-consistency, best-of-$N$ with verifiers, and group-relative RL training (GRPO), opening a new direction for inference-time scaling that does not rely on stochastic noise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Entropy-Gated Latent Recursion (EGLR), a training-free decoding procedure that recursively re-applies the top-L decoder layers of a frozen LLM only at high-entropy tokens until the next-token distribution converges (at most K_max iterations). It claims this deterministic L-axis is complementary to temperature sampling T, turning single-axis rollouts into an L×T Cartesian product at comparable cost, and supports the claim with oracle accuracy results across 8 models and 6 math benchmarks, including a joint oracle of 91.6% on MATH-500 with Qwen2.5-3B-Instruct that exceeds the temperature-only oracle by 8.2 points.
Significance. If the complementarity result holds under a fully specified protocol, the work supplies a concrete, deterministic source of rollout diversity that is additive to stochastic sampling. The scale of the evaluation (8 models, 6 benchmarks) and the direct oracle-gap evidence for non-overlapping problem coverage are strengths; the training-free nature and potential downstream uses in self-consistency or GRPO are also noted.
major comments (2)
- [§3] §3 (EGLR procedure): the entropy threshold that triggers recursion and the precise convergence criterion for the next-token distribution are not defined, rendering the reported L×T oracle numbers (e.g., 91.6% on MATH-500) non-reproducible and leaving the complementarity claim without a verifiable experimental foundation.
- [§5] §5 (Experiments): no variance estimates, multiple random seeds, or statistical significance tests accompany the oracle accuracies or the +8.2 / +10.4 point gains, so it is impossible to assess whether the observed complementarity exceeds sampling noise.
minor comments (2)
- [§3] The claim that EGLR operates at 'almost the same per-rollout cost' as standard sampling lacks a supporting FLOPs or latency breakdown.
- [§4] Notation for the free parameters L and K_max is introduced without an explicit sensitivity table showing how oracle performance varies with their values.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important issues of reproducibility and statistical rigor. We address each major comment below and will incorporate the necessary clarifications and additions in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (EGLR procedure): the entropy threshold that triggers recursion and the precise convergence criterion for the next-token distribution are not defined, rendering the reported L×T oracle numbers (e.g., 91.6% on MATH-500) non-reproducible and leaving the complementarity claim without a verifiable experimental foundation.
Authors: We agree that the specific entropy threshold and convergence criterion were not stated explicitly in §3. This is an oversight in the original submission. The revised manuscript will define these parameters precisely as implemented in our experiments, enabling full reproduction of the L×T oracle results and providing a verifiable basis for the complementarity analysis. revision: yes
-
Referee: [§5] §5 (Experiments): no variance estimates, multiple random seeds, or statistical significance tests accompany the oracle accuracies or the +8.2 / +10.4 point gains, so it is impossible to assess whether the observed complementarity exceeds sampling noise.
Authors: We acknowledge the absence of variance reporting and statistical tests. While the L-axis is deterministic, temperature sampling introduces stochasticity. In the revision we will add results over multiple random seeds with standard deviations for the key oracle metrics on MATH-500 and the other benchmarks. This will permit evaluation of whether the reported gains exceed sampling variability. The core complementarity evidence—distinct problem coverage across the two axes—remains independent of seed choice. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper reports direct empirical measurements of oracle accuracies on held-out benchmarks (e.g., MATH-500 with Qwen2.5-3B-Instruct yielding 91.6% for joint L×T vs. 83.4% temperature-only and 81.2% layer-only). These quantities are computed from observed rollout correctness and do not reduce to any fitted parameter, self-citation chain, or definitional equivalence. The complementarity claim follows immediately from the measured gap between joint and single-axis oracles, with no load-bearing derivation or ansatz that collapses to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- L (layer span)
- K_max (maximum iterations)
axioms (1)
- domain assumption Repeated application of the top-L layers on a high-entropy token produces a convergent next-token distribution within K_max steps.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URL https://arxiv.org/abs/2510.04871. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Association for Computational Linguistics. ISBN 979-8-89176-380-7. doi: 10.18653/v1/2026.eacl-long.235. URLhttps://aclanthology.org/2026.eacl-long.235/. 10 Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume,...
-
[7]
ISSN 1095-9203. doi: 10.1126/science.abq1158. URLhttp://dx.doi.org/10.1126/science.abq1158. Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations (ICLR),
-
[8]
AIME and AMC math competition prob- lem sets
Mathematical Association of America. AIME and AMC math competition prob- lem sets. https://artofproblemsolving.com/wiki/index.php/AMC_Problems_and_ Solutions, 2023–2025. OpenAI. OpenAI o1 system card. https://openai.com/index/openai-o1-system-card/ ,
2023
-
[9]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv.org/abs/ 2506.21734. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR),
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jian- hong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2.5-Math technical report: Toward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
We highlight two illustrative settings
11 A Practical Implications of the Cartesian Rollout Space The L×T Cartesian rollout pool established in Section 3.5 has implications beyond inference-time accuracy alone. We highlight two illustrative settings. (a) Test-time best-of-M at fixed compute.Where standard self-consistency must increase the sample count linearly to expand the candidate pool, th...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.