Vision-language models for chest radiography do not always need the image
Pith reviewed 2026-06-27 01:33 UTC · model grok-4.3
The pith
Many vision-language models for chest X-rays reach high accuracy by ignoring the image and using text priors instead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
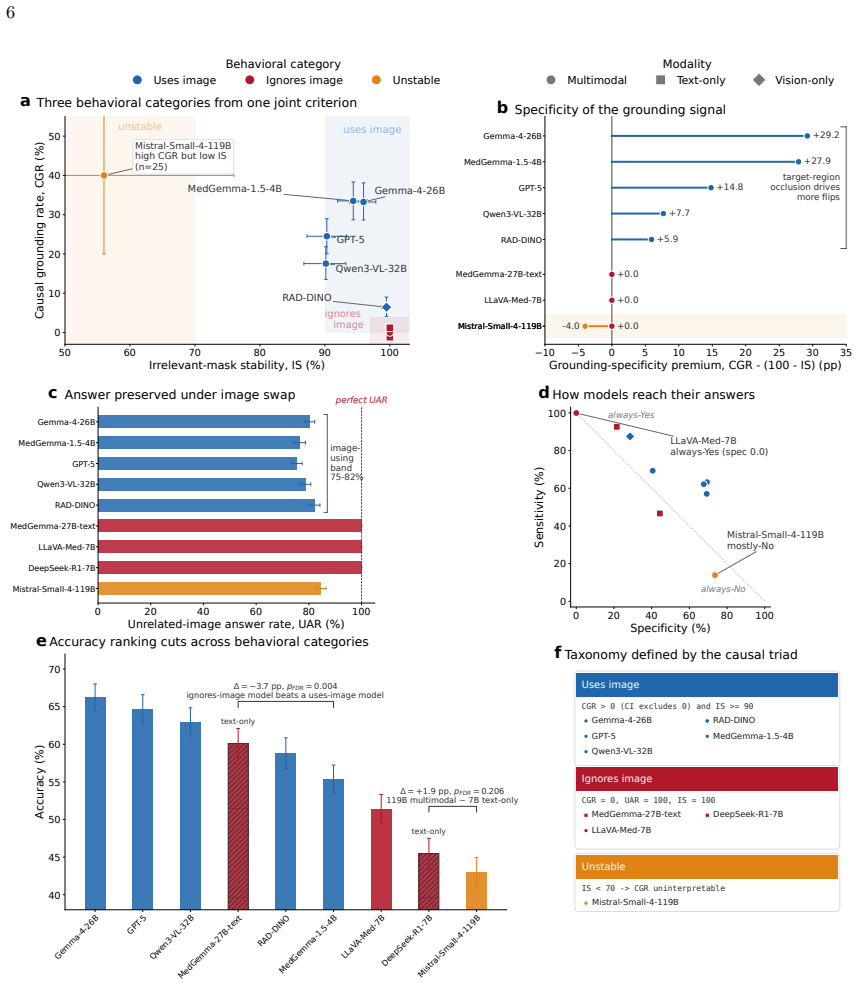
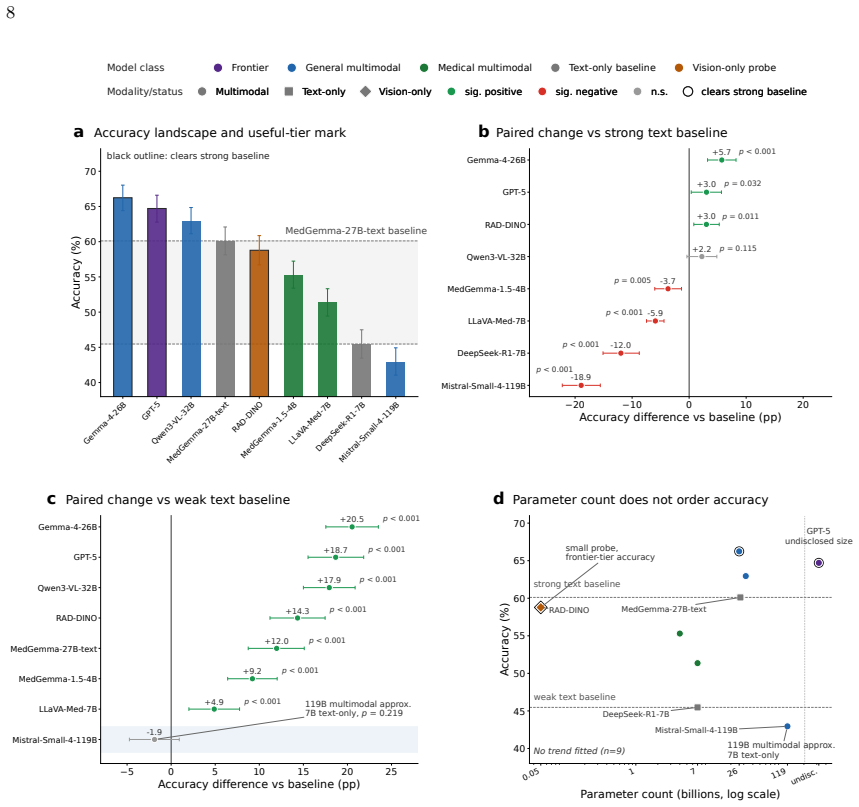
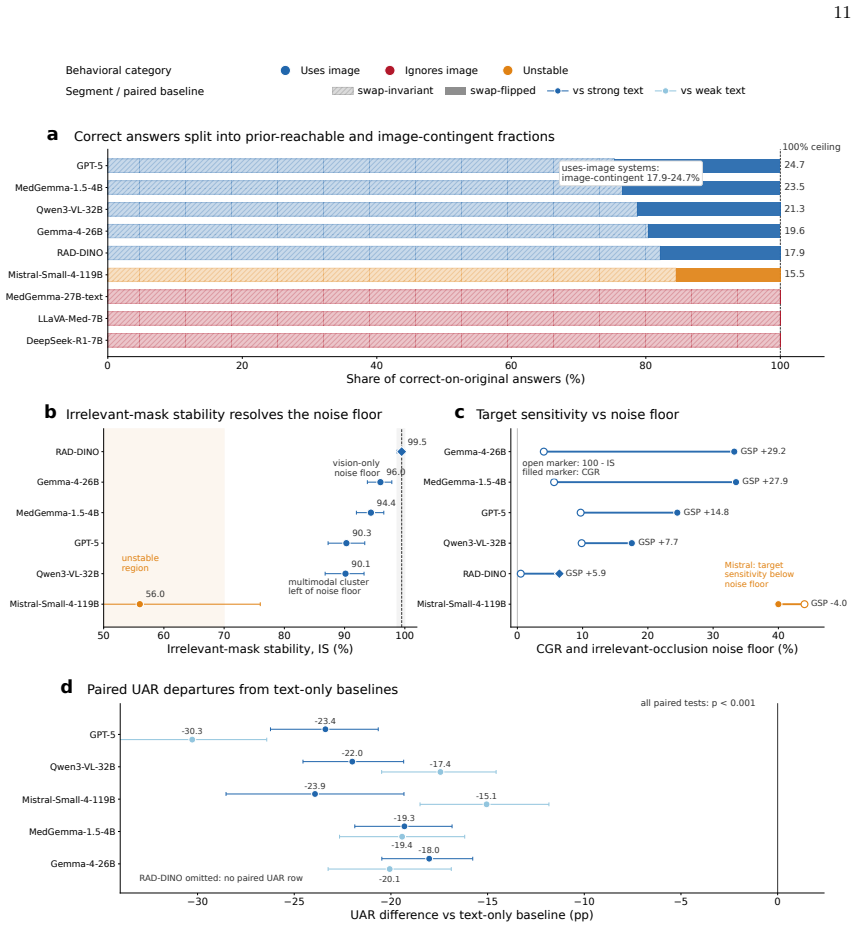
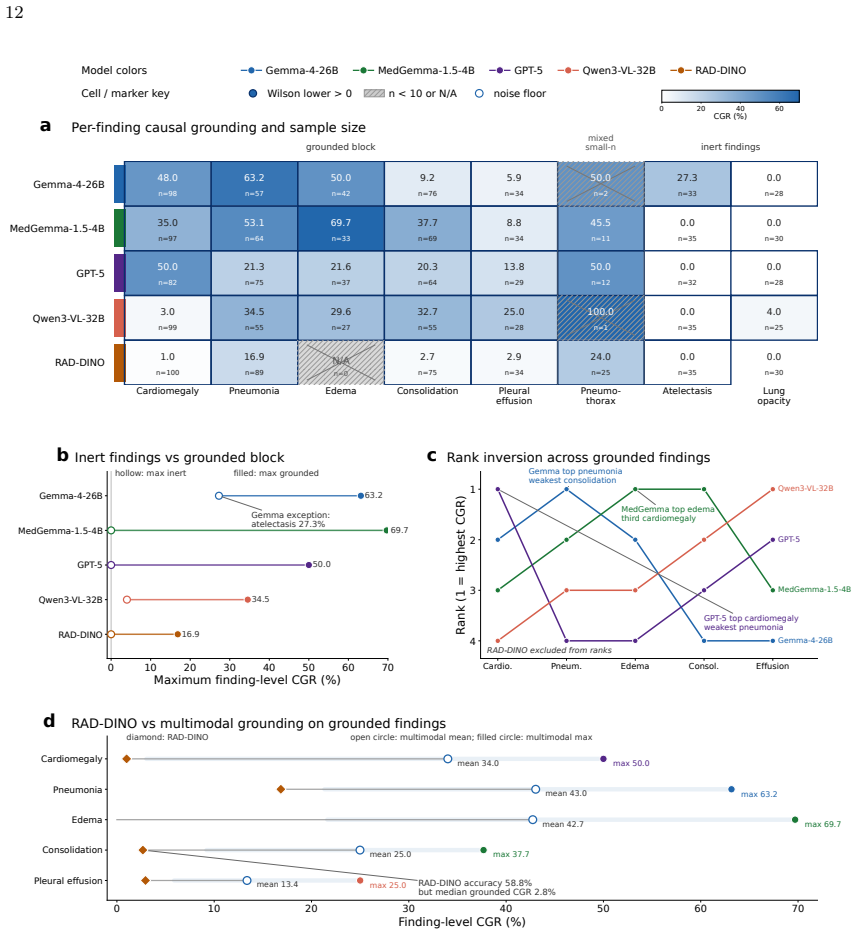
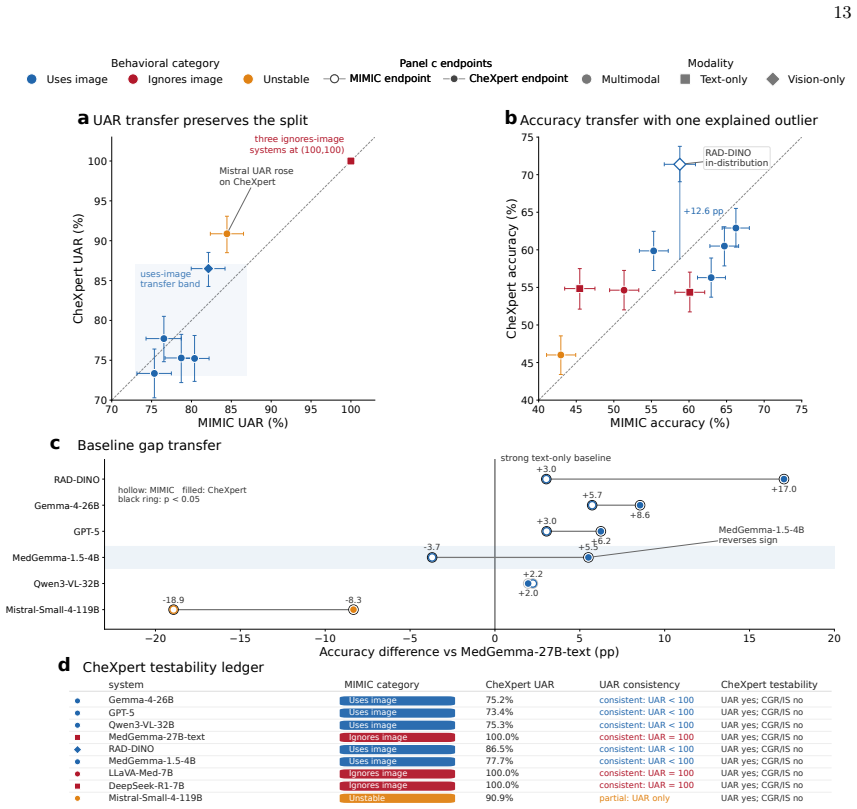
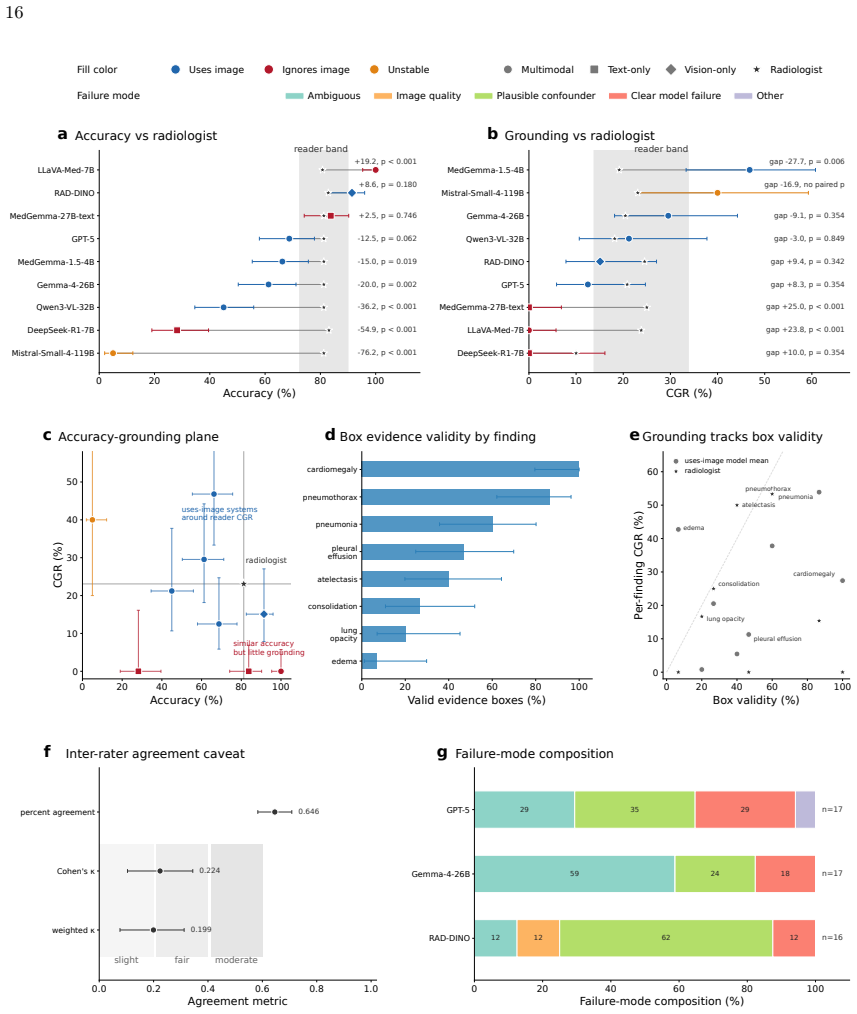
Across nine systems a text-only model reaches within 5.7 accuracy points of the best multimodal one and a 119B multimodal model is statistically indistinguishable from a 7B text-only baseline. The causal audit splits the systems into three that ignore the image, one unstable, and five that use it selectively for a subset of findings; the split holds on a second dataset, at different resolutions, and under varied prompt phrasing. Against board-certified radiologists a text-only model is statistically indistinguishable on accuracy yet grounds at zero, while image-using models ground at radiologist-comparable rates and only those models have confidence scores that flag ungrounded answers.
What carries the argument
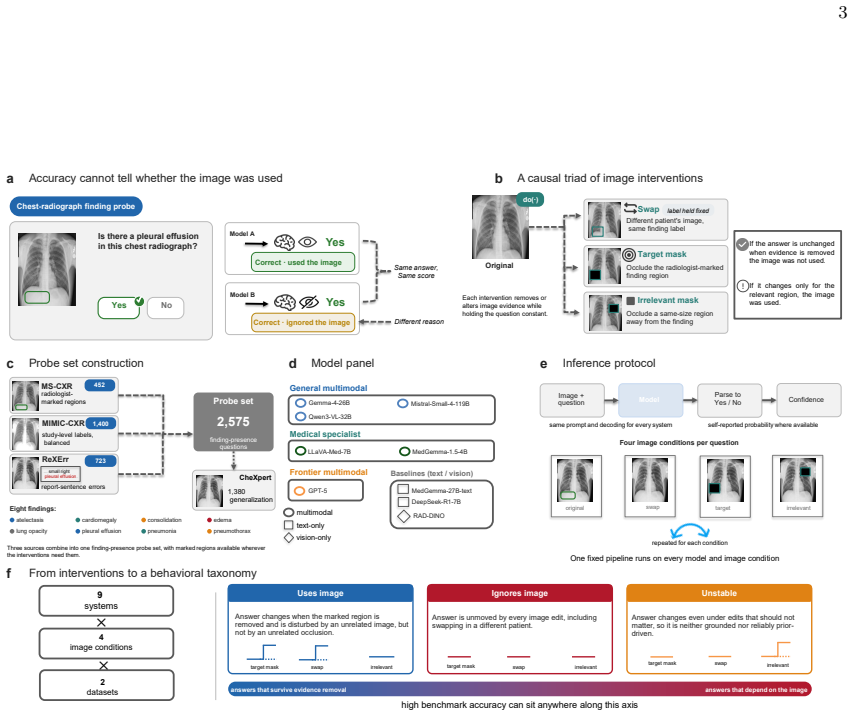
The causal audit, which intervenes on the image through occlusion of relevant or irrelevant regions and swapping same-label scans from other patients, then combines three behavioral metrics to measure whether correct answers depend on image content rather than label-name priors.
If this is right
- Accuracy alone cannot be used to claim that a model reads the radiograph.
- Three of the nine tested systems ignore the image entirely.
- Grounding rates, not raw accuracy, separate models that use the image from those that do not.
- Reported model confidence is informative only for systems that actually use the image.
- Grounding audits rather than accuracy benchmarks should determine clinical deployment readiness.
Where Pith is reading between the lines
- Current public benchmarks for these tasks likely overestimate visual capability.
- Similar text-prior shortcuts may affect vision-language models in other medical imaging domains.
- Model developers could add explicit grounding checks during training to reduce reliance on priors.
- Deployment policies might require passing a grounding audit before accuracy thresholds are considered.
Load-bearing premise
The chosen image interventions and behavioral metrics together reliably isolate whether a correct answer depends on the image rather than non-visual cues.
What would settle it
If occluding the relevant anatomical region produces no accuracy drop for a model the audit classified as image-using, that classification is incorrect.
Figures
read the original abstract
Medical vision-language models report strong chest radiograph accuracy, and this is increasingly read as evidence that they use the image. That inference is unsafe: a model exploiting finding-name priors scores like one that reads the scan, and no standard benchmark separates them. We introduce a causal audit that intervenes on the image, occluding the relevant region, occluding an irrelevant one, and swapping in another patient's same-label scan, and combines three behavioral metrics to test whether a correct answer depends on the image. Across nine systems, a text-only model with no image access reaches within 5.7 accuracy points of the best multimodal one, and a 119-billion-parameter multimodal model is statistically indistinguishable from a 7-billion text-only baseline. The audit splits the cohort into three models that ignore the image, one that is unstable, and five that use it selectively, for a subset of findings; the categories hold across a second dataset, resolution, and prompt phrasing. Against board-certified radiologists, a text-only model is statistically indistinguishable from a radiologist's accuracy while grounding at zero, whereas the image-using models ground at radiologist-comparable rates. Reported confidence flags ungrounded answers only when a model uses the image. Grounding audits, not accuracy, should gate clinical deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that vision-language models (VLMs) for chest radiography frequently do not rely on image content for their predictions. It introduces a causal audit using three image interventions (occluding the relevant region, occluding an irrelevant region, and swapping in another patient's same-label scan) plus three behavioral metrics to classify nine systems into ignore-image (3 models), unstable (1), and selective-use (5) categories. Key results include a text-only model reaching within 5.7 accuracy points of the best multimodal system, a 119B multimodal model being statistically indistinguishable from a 7B text-only baseline, and text-only performance matching radiologists while image-using models show comparable grounding rates. The categories are robust to a second dataset, resolution changes, and prompt variations; the paper concludes that grounding audits, not accuracy alone, should gate clinical deployment.
Significance. If the audit methodology is validated, the work provides a concrete empirical demonstration that high VLM accuracy on chest X-rays can be driven by non-visual priors, with direct implications for medical AI evaluation and deployment. Strengths include the multi-model, multi-dataset design and the explicit comparison to radiologist performance and grounding behavior. The intervention-based classification offers a falsifiable way to separate visual from textual reliance that goes beyond standard benchmarks.
major comments (2)
- [Methods / causal audit procedure] Abstract and Methods (causal audit description): The classification into ignore-image vs. selective-use models is load-bearing for the central claim, yet the selection of the 'relevant region' for occlusion is not shown to match the actual visual features each VLM conditions on. If the annotated or detected region omits diffuse findings, texture cues, or correlated anatomy outside the box, an image-using model could be misclassified as ignoring the image. The paper should provide explicit validation (e.g., agreement with model attention maps or ablation on region choice) or sensitivity analysis.
- [Abstract / intervention details] Abstract (swap intervention): The swap of same-label scans assumes that any performance drop isolates diagnostically relevant visual content, but scanner-specific statistics or acquisition artifacts could survive the swap and provide non-semantic shortcuts. This assumption needs explicit testing or discussion of controls (e.g., matching on scanner metadata) to ensure the behavioral metrics isolate image dependence rather than label-name or acquisition priors.
minor comments (2)
- [Abstract] Abstract: exact metric definitions, statistical test details (e.g., p-values for indistinguishability claims), and full cohort sizes are absent; these should be stated concisely even in the abstract for reproducibility.
- [Results / radiologist comparison] The paper should clarify how 'grounding' is operationalized in the radiologist comparison and whether the three behavioral metrics are combined via a pre-specified rule or post-hoc.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the causal audit.
read point-by-point responses
-
Referee: [Methods / causal audit procedure] Abstract and Methods (causal audit description): The classification into ignore-image vs. selective-use models is load-bearing for the central claim, yet the selection of the 'relevant region' for occlusion is not shown to match the actual visual features each VLM conditions on. If the annotated or detected region omits diffuse findings, texture cues, or correlated anatomy outside the box, an image-using model could be misclassified as ignoring the image. The paper should provide explicit validation (e.g., agreement with model attention maps or ablation on region choice) or sensitivity analysis.
Authors: We agree that the relevant-region definition is critical for the validity of the ignore-image classification. The regions are taken from expert-annotated bounding boxes for the primary radiographic finding (Methods). To strengthen the claim we will add a sensitivity analysis that (i) varies box size and location and (ii) reports classification stability under these perturbations. Where attention maps are publicly available we will also quantify spatial overlap; for closed models we will note the limitation. These results will appear in a new appendix. revision: yes
-
Referee: [Abstract / intervention details] Abstract (swap intervention): The swap of same-label scans assumes that any performance drop isolates diagnostically relevant visual content, but scanner-specific statistics or acquisition artifacts could survive the swap and provide non-semantic shortcuts. This assumption needs explicit testing or discussion of controls (e.g., matching on scanner metadata) to ensure the behavioral metrics isolate image dependence rather than label-name or acquisition priors.
Authors: We acknowledge the possibility that scanner-specific artifacts could remain after a same-label swap. The current manuscript already shows that the three-intervention classification is stable across two datasets and prompt variations, which indirectly limits the role of acquisition shortcuts. In revision we will (i) add an explicit Limitations paragraph discussing this confound and (ii) report an auxiliary control that swaps only within acquisition-protocol subgroups where metadata permit. Because full scanner metadata are not released with the public datasets, a complete metadata-matched ablation is not feasible; we will therefore treat the multi-metric requirement (occlusion + swap) as the primary safeguard. revision: partial
Circularity Check
No circularity: empirical intervention study with direct behavioral measurements
full rationale
The paper conducts an empirical causal audit by applying image occlusions and swaps to nine VLMs and measuring behavioral changes via three metrics. No equations, fitted parameters, or derivations are present; model classifications (ignore-image, unstable, selective) follow directly from observed accuracy drops rather than reducing to self-defined inputs or self-citations. The central claim that text-only performance is close rests on these external interventions and comparisons to radiologists, which are falsifiable outside any internal construction. No load-bearing self-citation chains or ansatzes appear.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Model responses under controlled image interventions reflect dependence on visual input rather than non-visual cues such as label priors.
Reference graph
Works this paper leans on
-
[1]
In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023),https: //openreview.net/forum?id=GSuP99u2kR
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: LLaVA- med: Training a large language-and-vision assistant for biomedicine in one day. In: Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2023),https: //openreview.net/forum?id=GSuP99u2kR
2023
-
[3]
OpenAI, Achiam, J., Adler, S., et al.: Gpt-4 technical report (2024),https://arxiv.org/abs/2303.0 8774
2024
-
[4]
arXiv preprint arXiv:2312.11805 (2023)
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
Pith/arXiv arXiv 2023
-
[5]
In: Bio- computing 2026: Proceedings of the Pacific Symposium
Pal, A., Lee, J.O., Zhang, X., Sankarasubbu, M., Roh, S., Kim, W.J., Lee, M., Rajpurkar, P.: Rexvqa: A large-scale visual question answering benchmark for generalist chest x-ray understanding. In: Bio- computing 2026: Proceedings of the Pacific Symposium. pp. 251–264. World Scientific (2025)
2026
-
[6]
Nature medicine29(8), 1930–1940 (2023)
Thirunavukarasu, A.J., Ting, D.S.J., Elangovan, K., Gutierrez, L., Tan, T.F., Ting, D.S.W.: Large language models in medicine. Nature medicine29(8), 1930–1940 (2023)
1930
-
[7]
Nature616(7956), 259–265 (2023)
Moor, M., Banerjee, O., Abad, Z.S.H., Krumholz, H.M., Leskovec, J., Topol, E.J., Rajpurkar, P.: Foundation models for generalist medical artificial intelligence. Nature616(7956), 259–265 (2023)
2023
-
[8]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Yan, Q., He, X., Yue, X., Wang, X.E.: Worse than random? an embarrassingly simple probing evaluation of large multimodal models in medical VQA. In: Findings of the Association for Com- putational Linguistics: ACL 2025. pp. 19188–19205. Association for Computational Linguistics, Vi- enna, Austria (Jul 2025).https://doi.org/10.18653/v1/2025.findings- acl.98...
-
[9]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id= H9UnNgdq0g
Sepehri, M.S., Fabian, Z., Soltanolkotabi, M., Soltanolkotabi, M.: Mediconfusion: Can you trust your AI radiologist? probing the reliability of multimodal medical foundation models. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id= H9UnNgdq0g
2025
-
[10]
PLoS medicine15(11), e1002683 (2018) 26
Zech, J.R., Badgeley, M.A., Liu, M., Costa, A.B., Titano, J.J., Oermann, E.K.: Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study. PLoS medicine15(11), e1002683 (2018) 26
2018
-
[11]
The Lancet Digital Health4(6), e406–e414 (2022)
Gichoya,J.W.,Banerjee,I.,Bhimireddy,A.R.,Burns,J.L.,Celi,L.A.,Chen,L.C.,Correa,R.,Dullerud, N., Ghassemi, M., Huang, S.C., et al.: Ai recognition of patient race in medical imaging: a modelling study. The Lancet Digital Health4(6), e406–e414 (2022)
2022
-
[12]
Nature Machine Intelligence3(7), 610–619 (2021)
DeGrave, A.J., Janizek, J.D., Lee, S.I.: Ai for radiographic covid-19 detection selects shortcuts over signal. Nature Machine Intelligence3(7), 610–619 (2021)
2021
-
[13]
Nature Machine Intelligence2(11), 665–673 (2020)
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine Intelligence2(11), 665–673 (2020)
2020
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcom- ings of multimodal llms. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9568–9578 (2024)
2024
-
[15]
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual expla- nations from deep networks via gradient-based localization. In: 2017 IEEE International Conference on Computer Vision (ICCV). pp. 618–626 (2017).https://doi.org/10.1109/ICCV.2017.74
-
[16]
Advances in neural information processing systems31(2018)
Adebayo, J., Gilmer, J., Muelly, M., Goodfellow, I., Hardt, M., Kim, B.: Sanity checks for saliency maps. Advances in neural information processing systems31(2018)
2018
-
[17]
Wiegreffe, S., Pinter, Y.: Attention is not not explanation. In: Proceedings of the 2019 Confer- ence on Empirical Methods in Natural Language Processing and the 9th International Joint Con- ference on Natural Language Processing (EMNLP-IJCNLP). pp. 11–20. Association for Computa- tional Linguistics, Hong Kong, China (2019).https://doi.org/10.18653/v1/D19...
-
[18]
Neuberg, L.G.: Causality: models, reasoning, and inference, by judea pearl, cambridge university press,
-
[19]
Econometric Theory19(4), 675–685 (2003)
2003
-
[20]
In: European conference on computer vision
Boecking, B., Usuyama, N., Bannur, S., Castro, D.C., Schwaighofer, A., Hyland, S., Wetscherek, M., Naumann, T., Nori, A., Alvarez-Valle, J., et al.: Making the most of text semantics to improve biomed- ical vision–language processing. In: European conference on computer vision. pp. 1–21. Springer (2022)
2022
-
[21]
Nature Machine Intelligence7(1), 119–130 (2025)
Pérez-García, F., Sharma, H., Bond-Taylor, S., Bouzid, K., Salvatelli, V., Ilse, M., Bannur, S., Castro, D.C., Schwaighofer, A., Lungren, M.P., et al.: Exploring scalable medical image encoders beyond text supervision. Nature Machine Intelligence7(1), 119–130 (2025)
2025
-
[22]
Scientific data6(1), 317 (2019)
Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free- text reports. Scientific data6(1), 317 (2019)
2019
-
[23]
In: Biocomputing 2025: Proceedings of the Pacific Sym- posium
Rao, V.M., Zhang, S., Acosta, J.N., Adithan, S., Rajpurkar, P.: Rexerr: Synthesizing clinically mean- ingful errors in diagnostic radiology reports. In: Biocomputing 2025: Proceedings of the Pacific Sym- posium. pp. 70–81. World Scientific (2024)
2025
-
[24]
In: Proceedings of the AAAI conference on artificial intelligence
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
2019
-
[25]
Chapman and Hall/CRC (1994)
Efron, B., Tibshirani, R.J.: An introduction to the bootstrap. Chapman and Hall/CRC (1994)
1994
-
[26]
Journal of the Amer- ican Statistical Association22(158), 209–212 (1927)
Wilson, E.B.: Probable inference, the law of succession, and statistical inference. Journal of the Amer- ican Statistical Association22(158), 209–212 (1927)
1927
-
[27]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Li, C., Wong, C., Zhang, S., Usuyama, N., Liu, H., Yang, J., Naumann, T., Poon, H., Gao, J.: Llava- med: training a large language-and-vision assistant for biomedicine in one day. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NeurIPS 2023, Curran Associates Inc., Red Hook, NY, USA (2023)
2023
-
[28]
Sellergren, A., Kazemzadeh, S., Jaroensri, T., et al.: Medgemma technical report (2026),https: //arxiv.org/abs/2507.05201
Pith/arXiv arXiv 2026
-
[29]
Nature645(8081), 633–638 (2025)
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645(8081), 633–638 (2025)
2025
-
[30]
arXiv preprint arXiv:2403.08295 (2024) 27
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M.S., Love, J., et al.: Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 (2024) 27
Pith/arXiv arXiv 2024
-
[31]
Singh, A., Fry, A., Perelman, A., et al.: Openai gpt-5 system card (2026),https://arxiv.org/abs/ 2601.03267
Pith/arXiv arXiv 2026
-
[32]
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond (2024),https://op enreview.net/forum?id=qrGjFJVl3m
2024
-
[33]
arXiv preprint arXiv:2511.21631 (2025)
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
Pith/arXiv arXiv 2025
-
[34]
Journal of the Royal statistical society: series B (Methodological)57(1), 289–300 (1995)
Benjamini, Y., Hochberg, Y.: Controlling the false discovery rate: a practical and powerful approach to multiple testing. Journal of the Royal statistical society: series B (Methodological)57(1), 289–300 (1995)
1995
-
[35]
American Journal of Roentgenology 196(6_supplement), S45–S61 (2011)
Asrani, A., Kaewlai, R., Digumarthy, S., Gilman, M., Shepard, J.A.O.: Urgent findings on portable chest radiography: What the radiologist should know. American Journal of Roentgenology 196(6_supplement), S45–S61 (2011)
2011
-
[36]
In: Inter- national conference on machine learning
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: Inter- national conference on machine learning. pp. 1321–1330. PMLR (2017)
2017
-
[37]
Nature communications10(1), 1096 (2019)
Lapuschkin, S., Wäldchen, S., Binder, A., Montavon, G., Samek, W., Müller, K.R.: Unmasking clever hans predictors and assessing what machines really learn. Nature communications10(1), 1096 (2019)
2019
-
[38]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6904–6913 (2017)
2017
-
[39]
Wind, S., Nguyen, T.T., Sopa, J., Lotfinia, M., Bickelhaup, S., Uder, M., Köstler, H., Wellein, G., Nebelung, S., Truhn, D., Maier, A., Arasteh, S.T.: Safety and accuracy follow different scaling laws in clinical large language models (2026),https://arxiv.org/abs/2605.04039
Pith/arXiv arXiv 2026
-
[40]
NPJ digital medicine5(1), 48 (2022)
Varoquaux, G., Cheplygina, V.: Machine learning for medical imaging: methodological failures and recommendations for the future. NPJ digital medicine5(1), 48 (2022)
2022
-
[41]
In: International con- ference on machine learning
Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al.: Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In: International con- ference on machine learning. pp. 2668–2677. PMLR (2018)
2018
-
[42]
Jeanneret, G., Simon, L., Jurie, F.: Adversarial Counterfactual Visual Explanations . In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16425–16435. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2023).https://doi.org/10.1109/CVPR52729.2023 .01576,https://doi.ieeecomputersociety.org/10.1109/CVPR52729.2023.01576
-
[43]
Scientific data8(1), 92 (2021)
Karargyris, A., Kashyap, S., Lourentzou, I., Wu, J.T., Sharma, A., Tong, M., Abedin, S., Beymer, D., Mukherjee, V., Krupinski, E.A., et al.: Creation and validation of a chest x-ray dataset with eye-tracking and report dictation for ai development. Scientific data8(1), 92 (2021)
2021
-
[44]
Radiology: Artificial Intelligence7(4), e240476 (2025)
Tayebi Arasteh, S., Lotfinia, M., Bressem, K., Siepmann, R., Adams, L., Ferber, D., Kuhl, C., Kather, J.N., Nebelung, S., Truhn, D.: Radiorag: online retrieval–augmented generation for radiology question answering. Radiology: Artificial Intelligence7(4), e240476 (2025)
2025
-
[45]
npj Digital Medicine8, 790 (2025)
Wind, S., Sopa, J., Truhn, D., Lotfinia, M., Nguyen, T.T., Bressem, K., Adams, L., Rusu, M., Köstler, H., Wellein, G., et al.: Multi-step retrieval and reasoning improves radiology question answering with large language models. npj Digital Medicine8, 790 (2025)
2025
-
[46]
In: Proceedings of the 26th International Joint Conference on Artificial Intelligence
Ross, A.S., Hughes, M.C., Doshi-Velez, F.: Right for the right reasons: training differentiable models by constraining their explanations. In: Proceedings of the 26th International Joint Conference on Artificial Intelligence. p. 2662–2670. IJCAI’17, AAAI Press (2017)
2017
-
[47]
Chambon, P., Delbrouck, J.B., Sounack, T., Huang, S.C., Chen, Z., Varma, M., Truong, S.Q., Chuong, C.T., Langlotz, C.P.: Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats (2024),https://arxiv.org/abs/2405.1 9538
2024
-
[48]
Springer (2005)
Good, P.: Permutation, parametric and bootstrap tests of hypotheses. Springer (2005)
2005
-
[49]
Monthly weather review 78(1), 1–3 (1950)
Glenn, W.B., et al.: Verification of forecasts expressed in terms of probability. Monthly weather review 78(1), 1–3 (1950)
1950
-
[50]
Educational and psychological measurement 20(1), 37–46 (1960)
Cohen, J.: A coefficient of agreement for nominal scales. Educational and psychological measurement 20(1), 37–46 (1960)
1960
-
[51]
[error_sentence]
Cohen, J.: Weighted kappa: Nominal scale agreement provision for scaled disagreement or partial credit. Psychological bulletin70(4), 213 (1968) 28 Supplementary information Supplementary Note 1: Full prompt text for the three phrasings used in the prompt-sensitivity probe. Default phrasing(MS-CXR and MIMIC-CXR finding-presence questions): Is [display] pre...
1968
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.