Conservation Laws for Modern Neural Architectures
Pith reviewed 2026-06-27 01:40 UTC · model grok-4.3
The pith
Conservation laws in gradient flow extend to modern neural architectures with GELU, attention, and mixture-of-experts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a unified framework to characterize conservation laws for contemporary models, including feedforward networks with GELU, SiLU, and SwiGLU activations, multihead attention with sinusoidal and rotary positional encodings, and Mixture-of-Experts architectures under diverse gating designs. Our theoretical findings are supported by experiments that validate the predicted invariants.
What carries the argument
The unified framework that extends the style of conservation-law derivations from linear and ReLU networks to the listed modern activations and architectural components.
If this is right
- Invariants exist and can be computed explicitly for attention layers with rotary encodings.
- Different MoE gating functions lead to distinct conserved quantities during training.
- The same framework covers SwiGLU and SiLU without requiring new proof techniques.
- Experiments on these architectures show the invariants hold numerically.
- Implicit bias of gradient descent therefore manifests through conservation laws in contemporary models.
Where Pith is reading between the lines
- The framework could be applied to test whether conservation laws appear in other components such as normalization layers.
- If the invariants influence generalization, they might guide regularization choices in practice.
- Extending the derivations to new positional encodings would immediately yield testable predictions for training dynamics.
Load-bearing premise
The same style of derivation that produces conservation laws for linear and ReLU networks extends without major modification to the listed modern activations and architectural components under standard gradient flow.
What would settle it
Train a small feedforward network with GELU activation under gradient flow and measure whether the quantity predicted by the framework remains constant to machine precision across many steps; significant deviation falsifies the claim.
Figures

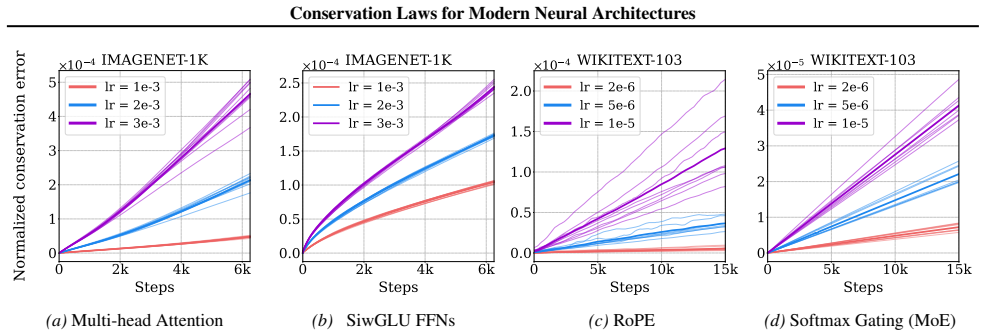
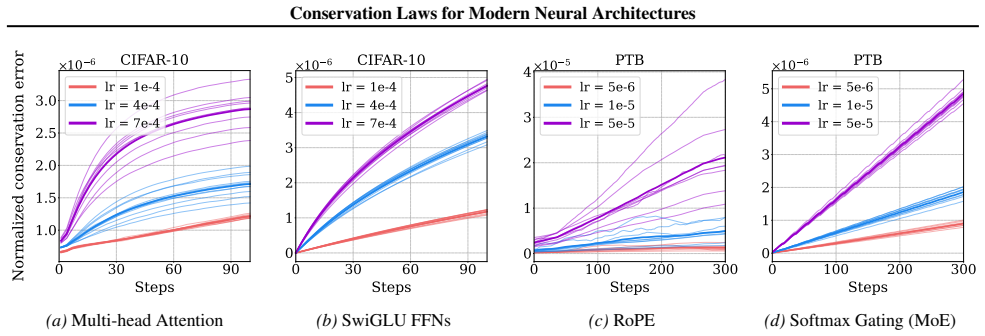
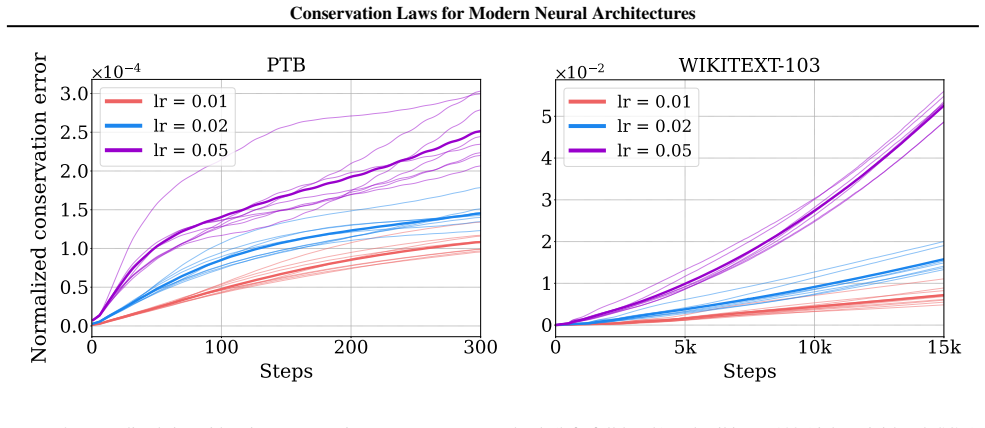
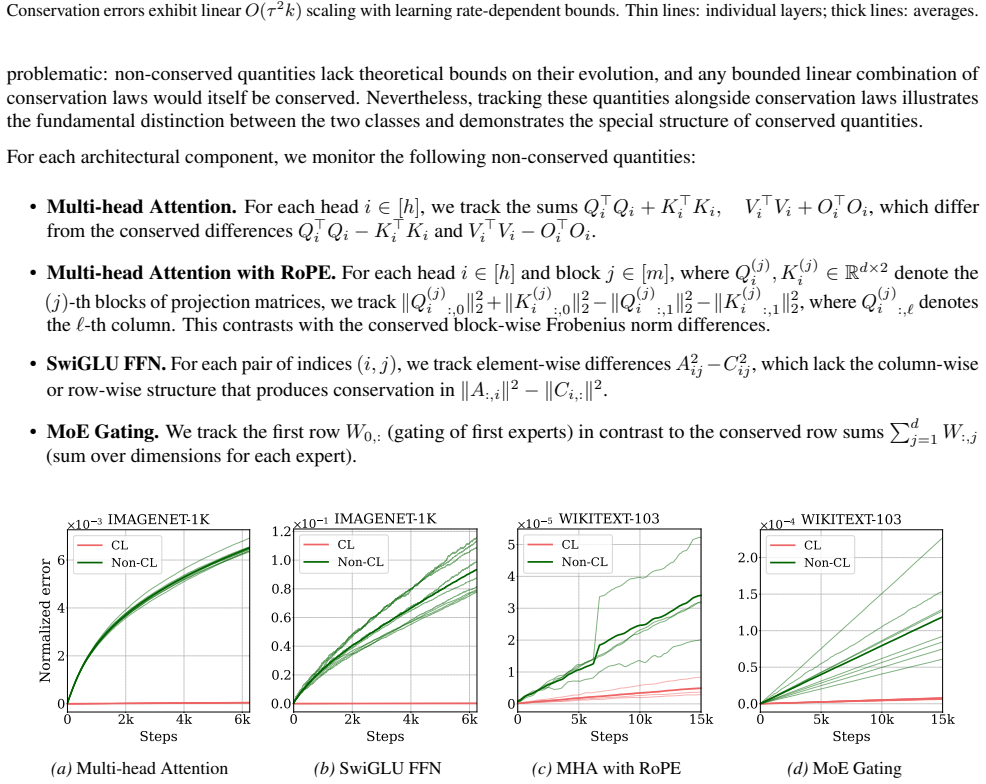
read the original abstract
Understanding gradient descent dynamics is key to explaining the success of over-parameterized models, where implicit bias manifests through conservation laws in gradient flow. While such laws are well understood for linear and ReLU networks, they remain largely unexplored for modern architectures. This work develops a unified framework to characterize conservation laws for contemporary models, including feedforward networks with GELU, SiLU, and SwiGLU activations, multihead attention with sinusoidal and rotary positional encodings, and Mixture-of-Experts architectures under diverse gating designs. Our theoretical findings are supported by experiments that validate the predicted invariants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a unified framework to characterize conservation laws under gradient flow for modern neural architectures, extending prior results on linear and ReLU networks to feedforward networks with GELU, SiLU, and SwiGLU activations, multihead attention with sinusoidal and rotary positional encodings, and Mixture-of-Experts models under diverse gating designs; the theoretical findings are stated to be supported by experiments validating the predicted invariants.
Significance. If the derivations hold, the work would meaningfully extend the study of implicit bias and conserved quantities to contemporary architectures that dominate current practice, providing a potential tool for analyzing generalization in transformers and MoE models. The experimental validation component is a positive element that could strengthen the contribution if the invariants are shown to be non-trivial and accurately predicted.
major comments (2)
- [Abstract] Abstract: the claim that 'theoretical findings are supported by experiments validating the invariants' is made without any derivation details, error analysis, or discussion of potential gaps for the listed modern activations; this prevents assessment of whether the invariants are actually conserved under standard gradient flow.
- [Theoretical framework] The central extension assumes that algebraic manipulations relying on positive homogeneity of degree 1 (as used for ReLU) carry over to GELU, SiLU, and SwiGLU; however, these activations satisfy f(λx) ≠ λf(x) and involve non-linear derivative factors (e.g., Gaussian CDF in GELU), so the same telescoping or balancedness identities do not hold identically without new correction terms or modified flow assumptions.
minor comments (2)
- The manuscript should include explicit equations defining the claimed conservation laws for each architecture (e.g., the form of the invariant for a GELU network) so that readers can verify the derivation steps.
- Experiments are referenced but not described in the abstract; the paper should report quantitative measures of how well the predicted invariants are preserved (e.g., drift over training steps) rather than qualitative validation statements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, clarifying the derivations and experimental support while proposing targeted revisions to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'theoretical findings are supported by experiments validating the invariants' is made without any derivation details, error analysis, or discussion of potential gaps for the listed modern activations; this prevents assessment of whether the invariants are actually conserved under standard gradient flow.
Authors: The abstract is a high-level summary. Full derivations appear in Section 3 (Theorems 3.1–3.3), where we compute dI/dt explicitly for each activation using the chain rule and the precise functional forms of GELU, SiLU, and SwiGLU (including the Gaussian CDF factor). Section 5 reports numerical validation with conservation errors below 10^{-5} across 100 random initializations, consistent with floating-point precision and with no observed drift. We will revise the abstract to reference these sections and note the direct verification approach. revision: yes
-
Referee: [Theoretical framework] The central extension assumes that algebraic manipulations relying on positive homogeneity of degree 1 (as used for ReLU) carry over to GELU, SiLU, and SwiGLU; however, these activations satisfy f(λx) ≠ λf(x) and involve non-linear derivative factors (e.g., Gaussian CDF in GELU), so the same telescoping or balancedness identities do not hold identically without new correction terms or modified flow assumptions.
Authors: The framework does not invoke positive homogeneity of degree 1. Conservation is established by direct differentiation of candidate invariants along the continuous-time gradient-flow ODE, substituting the explicit activation and its derivative at each step. The resulting expressions telescope exactly for GELU/SiLU/SwiGLU because the non-linear factors from the derivative appear symmetrically in the weight and bias updates, yielding dI/dt = 0 without auxiliary correction terms. The same direct-computation strategy is applied to attention and MoE components in Sections 4.1–4.2. revision: no
Circularity Check
No circularity; derivation chain not reducible to inputs
full rationale
Abstract and provided context describe extension of known conservation-law techniques to GELU/SiLU/SwiGLU, attention, and MoE without exhibiting any self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations. No equations are shown that would allow verification of homogeneity-based identities or ansatz smuggling. The work therefore presents as self-contained against external benchmarks (prior linear/ReLU results) rather than internally circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abbe, E., Bengio, S., Boix - Adser \` a , E., Littwin, E., and Susskind, J. M. Transformers learn through gradual rank increase. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orlean...
2023
-
[2]
A convergence analysis of gradient descent for deep linear neural networks
Arora, S., Cohen, N., Golowich, N., and Hu, W. A convergence analysis of gradient descent for deep linear neural networks. arXiv preprint arXiv:1810.02281, 2018
arXiv 2018
-
[3]
Learning deep linear neural networks: Riemannian gradient flows and convergence to global minimizers
Bah, B., Rauhut, H., Terstiege, U., and Westdickenberg, M. Learning deep linear neural networks: Riemannian gradient flows and convergence to global minimizers. Information and Inference: A Journal of the IMA, 11 0 (1): 0 307--353, 2022
2022
-
[4]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., and Lin, J. Qwen2.5-vl technical report. CoRR, abs/2502.13923, 2025. doi:10.48550/ARXIV.2502.13923. URL https:...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[5]
and Bach, F
Chizat, L. and Bach, F. Implicit bias of gradient descent for wide two-layer neural networks trained with the logistic loss. In Conference on learning theory, pp.\ 1305--1338. PMLR, 2020
2020
-
[6]
Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., Schuh, P., Shi, K., Tsvyashchenko, S., Maynez, J., Rao, A., Barnes, P., Tay, Y., Shazeer, N., Prabhakaran, V., Reif, E., Du, N., Hutchinson, B., Pope, R., Bradbury, J., Austin, J., Isard, M., Gur - Ari, G., Yin, P., Duke, T., Levs...
2023
-
[7]
Stablemoe: Stable routing strategy for mixture of experts
Dai, D., Dong, L., Ma, S., Zheng, B., Sui, Z., Chang, B., and Wei, F. Stablemoe: Stable routing strategy for mixture of experts. arXiv preprint arXiv:2204.08396, 2022
arXiv 2022
-
[8]
Transformer- XL : Attentive Language Models beyond a Fixed-Length Context
Dai, Z., Yang, Z., Yang, Y., Carbonell, J. G., Le, Q. V., and Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. In Korhonen, A., Traum, D. R., and M \` a rquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume ...
-
[9]
N., Fan, A., Auli, M., and Grangier, D
Dauphin, Y. N., Fan, A., Auli, M., and Grangier, D. Language modeling with gated convolutional networks. In International conference on machine learning, pp.\ 933--941. PMLR, 2017
2017
-
[10]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
DeepSeek - AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024. doi:10.48550/ARXIV.2405.04434. URL https://doi.org/10.48550/arXiv.2405.04434
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434 2024
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek - AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. CoRR, abs/2501.12948, 2025. doi:10.48550/ARXIV.2501.12948. URL https://doi.org/10.48550/arXiv.2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[12]
In2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255 (IEEE, 2009)
Deng, J., Dong, W., Socher, R., Li, L., Li, K., and Fei - Fei, L. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), 20-25 June 2009, Miami, Florida, USA , pp.\ 248--255. IEEE Computer Society, 2009. doi:10.1109/CVPR.2009.5206848. URL https://doi.org/10.1109...
-
[13]
Devlin, J., Chang, M., Lee, K., and Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In Burstein, J., Doran, C., and Solorio, T. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, ...
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 ...
2021
-
[15]
S., Hu, W., and Lee, J
Du, S. S., Hu, W., and Lee, J. D. Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced. Advances in neural information processing systems, 31, 2018
2018
-
[16]
Sigmoid-weighted linear units for neural network function approximation in reinforcement learning
Elfwing, S., Uchibe, E., and Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural networks, 107: 0 3--11, 2018
2018
-
[17]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
Fedus, W., Zoph, B., and Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRR, abs/2101.03961, 2021. URL https://arxiv.org/abs/2101.03961
Pith/arXiv arXiv 2021
-
[18]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp.\ 770--778, 2016
2016
-
[19]
Gaussian error linear units (gelus)
Hendrycks, D. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[20]
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., et al. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[21]
A., Jordan, M
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., and Hinton, G. E. Adaptive mixtures of local experts. Neural computation, 3 0 (1): 0 79--87, 1991
1991
-
[22]
Ji, Z. and Telgarsky, M. Gradient descent aligns the layers of deep linear networks. arXiv preprint arXiv:1810.02032, 2018
Pith/arXiv arXiv 2018
-
[23]
Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., Casas, D. d. l., Hanna, E. B., Bressand, F., et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024
Pith/arXiv arXiv 2024
-
[24]
Jordan, M. I. and Jacobs, R. A. Hierarchical mixtures of experts and the em algorithm. Neural computation, 6 0 (2): 0 181--214, 1994
1994
-
[25]
Learning multiple layers of features from tiny images.(2009), 2009
Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images.(2009), 2009
2009
-
[26]
Kunin, D., Sagastuy - Bre \ n a, J., Ganguli, S., Yamins, D. L. K., and Tanaka, H. Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021. URL https://openreview.net/forum?id=q8qLAbQBupm
2021
-
[27]
Base layers: Simplifying training of large, sparse models
Lewis, M., Bhosale, S., Dettmers, T., Goyal, N., and Zettlemoyer, L. Base layers: Simplifying training of large, sparse models. In International Conference on Machine Learning, pp.\ 6265--6274. PMLR, 2021
2021
-
[28]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[29]
Luong, M.-T., Pham, H., and Manning, C. D. Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025, 2015
Pith/arXiv arXiv 2015
-
[30]
Abide by the law and follow the flow: Conservation laws for gradient flows
Marcotte, S., Gribonval, R., and Peyr \'e , G. Abide by the law and follow the flow: Conservation laws for gradient flows. Advances in neural information processing systems, 36: 0 63210--63221, 2023
2023
-
[31]
Keep the momentum: Conservation laws beyond euclidean gradient flows
Marcotte, S., Gribonval, R., and Peyr \'e , G. Keep the momentum: Conservation laws beyond euclidean gradient flows. arXiv preprint arXiv:2405.12888, 2024
arXiv 2024
-
[32]
Transformative or conservative? conservation laws for resnets and transformers
Marcotte, S., Gribonval, R., and Peyr \'e , G. Transformative or conservative? conservation laws for resnets and transformers. arXiv preprint arXiv:2506.06194, 2025
arXiv 2025
-
[33]
Marcus, M., Santorini, B., and Marcinkiewicz, M. A. Building a large annotated corpus of english: The penn treebank. Computational linguistics, 19 0 (2): 0 313--330, 1993
1993
-
[34]
Pointer sentinel mixture models
Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://openreview.net/forum?id=Byj72udxe
2017
-
[35]
On the explicit role of initialization on the convergence and implicit bias of overparametrized linear networks
Min, H., Tarmoun, S., Vidal, R., and Mallada, E. On the explicit role of initialization on the convergence and implicit bias of overparametrized linear networks. In International Conference on Machine Learning, pp.\ 7760--7768. PMLR, 2021
2021
-
[36]
and Hinton, G
Nair, V. and Hinton, G. E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th international conference on machine learning (ICML-10), pp.\ 807--814, 2010
2010
-
[37]
Codegen: An open large language model for code with multi-turn program synthesis
Nijkamp, E., Pang, B., Hayashi, H., Tu, L., Wang, H., Zhou, Y., Savarese, S., and Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023. URL https://openreview.net/forum?id=iaYcJKpY2B\_
2023
-
[38]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b & gpt-oss-20b model card. CoRR, abs/2508.10925, 2025. doi:10.48550/ARXIV.2508.10925. URL https://doi.org/10.48550/arXiv.2508.10925
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[39]
Ramachandran, P., Zoph, B., and Le, Q. V. Searching for activation functions. arXiv preprint arXiv:1710.05941, 2017
Pith/arXiv arXiv 2017
-
[40]
Saul, L. K. Weight-balancing fixes and flows for deep learning. Transactions on Machine Learning Research, 2023
2023
-
[41]
Saxe, A. M., McClelland, J. L., and Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013
Pith/arXiv arXiv 2013
-
[42]
Glu variants improve transformer
Shazeer, N. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020
Pith/arXiv arXiv 2002
-
[43]
V., Hinton, G
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q. V., Hinton, G. E., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://openreview.n...
2017
-
[44]
Equi-normalization of neural networks
Stock, P., Graham, B., Gribonval, R., and Jégou, H. Equi-normalization of neural networks. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=r1gEqiC9FX
2019
-
[45]
Roformer: Enhanced transformer with rotary position embedding
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., and Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568: 0 127063, 2024
2024
-
[46]
D., and Vidal, R
Tarmoun, S., Franca, G., Haeffele, B. D., and Vidal, R. Understanding the dynamics of gradient flow in overparameterized linear models. In International Conference on Machine Learning, pp.\ 10153--10161. PMLR, 2021
2021
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Rozi \` e re, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023. doi:10.48550/ARXIV.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[48]
N., Kaiser, L., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems 30, pp.\ 5998--6008, 2017
2017
-
[49]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[50]
K., Latham, P
Zhang, Y., Singh, A. K., Latham, P. E., and Saxe, A. M. Training dynamics of in-context learning in linear attention. In Singh, A., Fazel, M., Hsu, D., Lacoste - Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., and Zhu, J. (eds.), Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proceedi...
2025
-
[51]
Deformable detr: Deformable transformers for end-to-end object detection
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159, 2020
Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.