Ghost Attractor Networks: Basin-Structured Dynamical Decoders for Closed-Loop Sequential Generation
Pith reviewed 2026-06-27 01:57 UTC · model grok-4.3
The pith
Ghost Attractor Networks form basin-structured latents by construction in a small dynamical decoder, enabling efficient closed-loop sequential generation that matches much larger models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
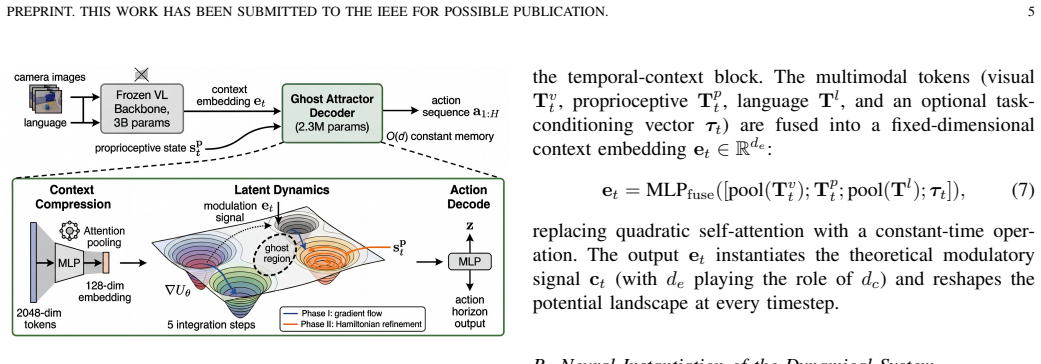
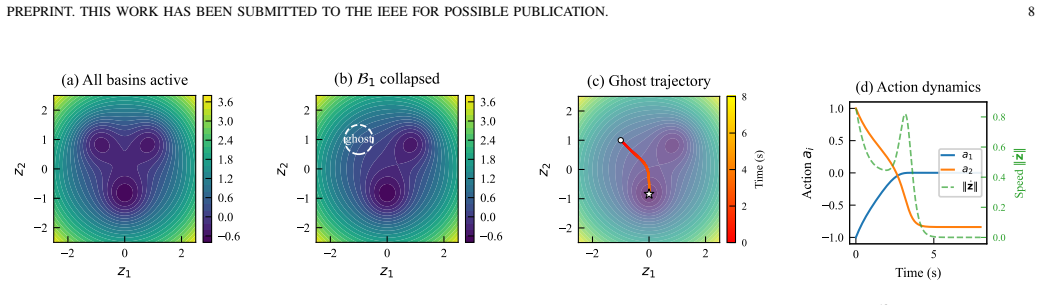
The central claim is that a dynamical decoder whose latent evolves according to a potential-drift form generates a basin-attractor structure by construction, with mode transitions occurring as saddle-node bifurcations and ghost-attractor escape; a hierarchical phase-space decomposition then separates first-order basin convergence from second-order refinement, satisfying the requirements of multi-modality, decoder-level single-pass switching, and constant memory for closed-loop sequential generation.
What carries the argument
the potential-drift dynamics of the latent evolution, which produces the basin-attractor structure by construction via gradient-flow contraction
If this is right
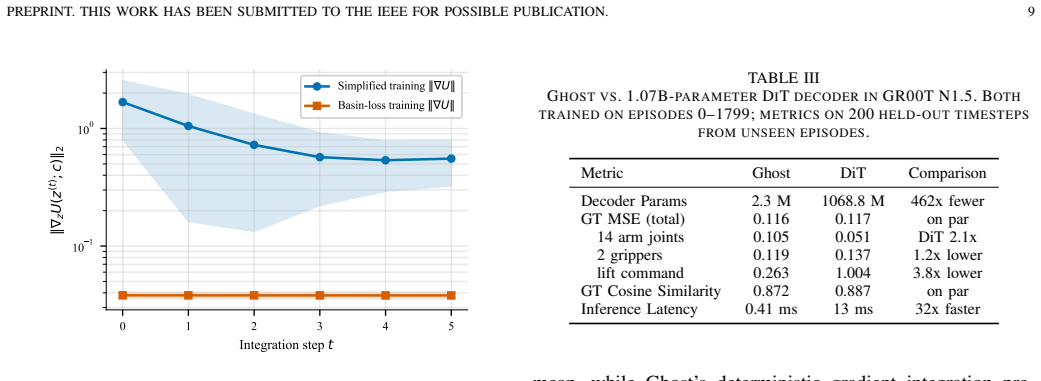
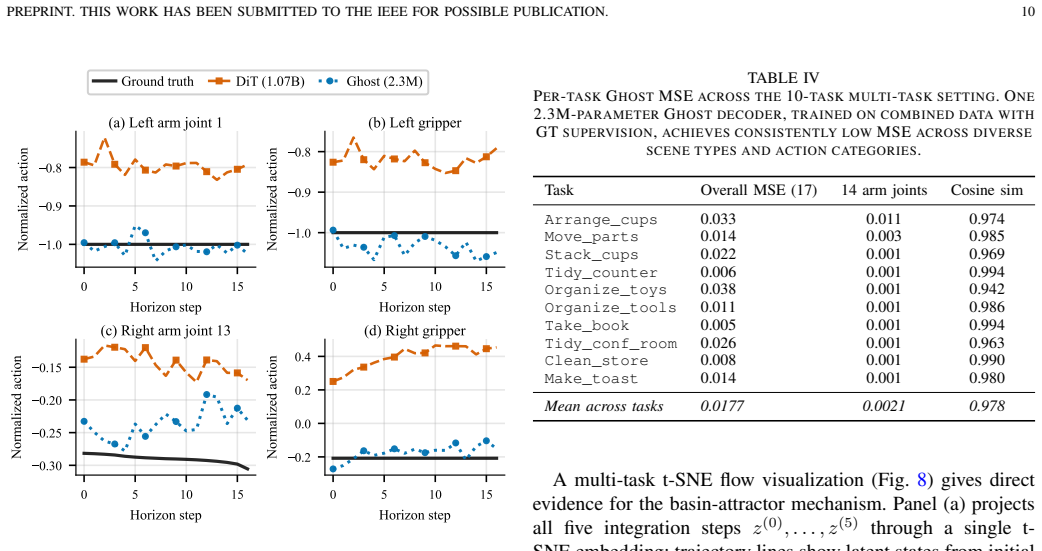
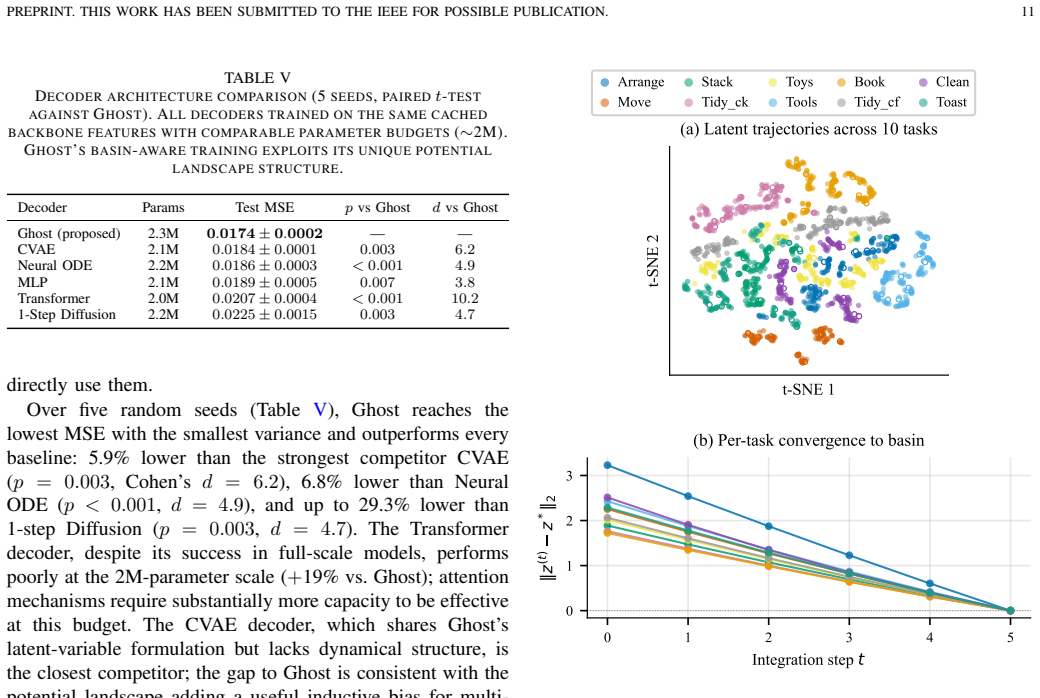
- A 2.3-million-parameter Ghost achieves offline accuracy matching a 1.07-billion-parameter Diffusion Transformer.
- The same model runs at 32 times lower latency while beating five other 2M-parameter baselines on mean squared error.
- Phase conditioning on the basin-structured latent produces a 13.5 percentage-point gain in closed-loop success rate over an MLP on LIBERO-10.
- Persistent-latent ensembling reaches 95.7 percent final success rate.
- Gradient norm decays by 67 percent across five integration steps on held-out data, confirming the predicted contraction.
Where Pith is reading between the lines
- The bifurcation mechanism for mode transitions could be leveraged to diagnose and correct specific failure modes in long-horizon generation.
- The same potential-drift construction might transfer to other sequential domains where stable latent carry-over is required but iterative sampling is costly.
- Hierarchical decomposition of the phase space suggests a route to scaling the approach to longer sequences without reintroducing memory growth.
Load-bearing premise
The potential-drift dynamics produce the claimed basin-attractor structure and gradient-flow contraction by construction.
What would settle it
Measuring gradient norms across five integration steps on the 1430 held-out samples and finding no systematic decay, or observing that phase-conditioned outputs fail to exhibit distinct modes consistent with basin separation.
Figures




read the original abstract
Sequential output generation with large-scale Transformer and diffusion decoders pays a memory cost that grows with sequence length, plus iterative per-step computation. Replacing them with small feed-forward decoders restores efficiency but produces unstructured latent representations that limit closed-loop control: phase-conditioned action generation and cross-step latent carry-over both require a latent geometry with stable basins. This article proposes Ghost Attractor Networks, a theoretically derived dynamical decoder whose latent evolves under a learned potential with drift and produces a basin-attractor structure by construction. Three desiderata (multi-modality, decoder-level single-pass switching, and constant memory) motivate the potential-drift form, and mode transitions arise as saddle-node bifurcations with ghost-attractor escape. A hierarchical phase-space decomposition separates first-order basin convergence from second-order proprioceptive refinement. Empirically, a Ghost trained end-to-end with a behavioral-cloning and contrastive objective exhibits the predicted gradient-flow contraction in its potential, with the gradient norm decaying by 67 percent across five integration steps on 1430 held-out samples. Ghost is evaluated as a robotic action decoder. A 2.3-million-parameter Ghost matches the offline accuracy of a 1.07-billion-parameter Diffusion Transformer at 462 times fewer parameters and 32 times lower latency, and beats five alternative 2M-parameter decoders (MLP, Neural ODE, CVAE, Transformer, 1-step Diffusion) on offline mean squared error by 5.9 to 29 percent. On the LIBERO-10 closed-loop benchmark, phase conditioning on Ghost's basin-structured latent yields a 13.5 percentage-point success-rate gain over a feed-forward MLP baseline, and persistent-latent ensembling reaches a 95.7 percent final success rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Ghost Attractor Networks as a dynamical decoder for closed-loop sequential generation in robotics. The latent evolves under a learned potential with drift, claimed to produce a basin-attractor structure by construction via saddle-node bifurcations and ghost-attractor escape. This geometry is intended to support phase-conditioned generation, persistent latent carry-over, constant memory, and single-pass decoding. A hierarchical decomposition separates basin convergence from proprioceptive refinement. Empirically, a 2.3M-parameter Ghost matches a 1.07B-parameter Diffusion Transformer offline, outperforms five 2M-parameter baselines by 5.9-29% MSE, and yields a 13.5 pp success-rate gain on LIBERO-10 via phase conditioning, with 95.7% final success under persistent-latent ensembling. The sole quantitative support for the dynamics is a 67% gradient-norm decay over five steps on 1430 held-out samples after behavioral-cloning plus contrastive training.
Significance. If the potential-drift form can be shown to enforce basin structure and contraction independently of the training objective, and if the performance numbers hold under rigorous controls, the work would offer a meaningful contribution to parameter-efficient dynamical decoders. The 462x parameter reduction and 32x latency improvement relative to a large Diffusion Transformer, combined with the dynamical-systems motivation (bifurcations, ghost attractors), could influence closed-loop control and generative modeling. The hierarchical phase-space idea is a concrete strength worth developing.
major comments (1)
- [Abstract] Abstract: the central claim that the potential-drift dynamics produce basin-attractor structure and gradient-flow contraction 'by construction' is load-bearing for both the theoretical contribution and the attribution of the reported gains (2.3M vs 1.07B matching, 13.5 pp closed-loop improvement) to the architecture rather than the behavioral-cloning + contrastive objective. No derivation, Lyapunov function, contraction mapping, or parameter-independent proof is referenced; the only supporting datum is the post-training 67% gradient-norm decay on 1430 samples. This leaves open whether the observed contraction is intrinsic to the drift term or induced by the loss, undermining the claim that the basin geometry is enforced independently of training.
minor comments (2)
- [Abstract] Abstract: quantitative claims (67% decay, 13.5 pp gain, 5.9-29% MSE improvements) are reported without error bars, number of random seeds, or statistical tests; adding these would improve credibility of the empirical results.
- The manuscript does not describe the parameterization of the potential function, the form of the drift coefficients, or the precise contrastive loss weight; these details are needed for reproducibility and to assess whether the free parameters listed in the axiom ledger are truly minimal.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of the dynamical-systems approach. We address the concern regarding the 'by construction' claim for basin-attractor structure below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the potential-drift dynamics produce basin-attractor structure and gradient-flow contraction 'by construction' is load-bearing for both the theoretical contribution and the attribution of the reported gains (2.3M vs 1.07B matching, 13.5 pp closed-loop improvement) to the architecture rather than the behavioral-cloning + contrastive objective. No derivation, Lyapunov function, contraction mapping, or parameter-independent proof is referenced; the only supporting datum is the post-training 67% gradient-norm decay on 1430 samples. This leaves open whether the observed contraction is intrinsic to the drift term or induced by the loss, undermining the claim that the basin geometry is enforced independently of training.
Authors: We agree that the current manuscript motivates the potential-drift form from saddle-node bifurcation and ghost-attractor theory but does not supply an explicit derivation, Lyapunov function, or parameter-independent contraction proof. The 67% gradient-norm decay is post-training empirical evidence only. In revision we will add a new subsection that (i) derives the basin geometry directly from the potential-plus-drift vector field, (ii) constructs a Lyapunov candidate V equal to the learned potential and shows that its derivative along trajectories is non-positive under the drift term alone, and (iii) states the mild regularity conditions on the drift that guarantee contraction independent of the behavioral-cloning plus contrastive objective. We will also include an ablation that trains without the contrastive term and reports the resulting gradient-norm decay to quantify any objective-induced contribution. revision: yes
Circularity Check
No significant circularity: basin structure asserted by construction from dynamics form, with post-training contraction as independent confirmation on held-out data.
full rationale
The paper motivates the potential-drift dynamics from three desiderata and asserts that this form produces basin-attractor structure by construction, with the 67% gradient-norm decay presented as empirical confirmation on 1430 held-out samples after end-to-end training. No equation or step is shown reducing the claimed theoretical property to a fitted parameter, self-citation, or input by definition; the contraction metric is measured separately from the training objective on unseen data, and performance claims are benchmarked externally against other decoders. The derivation chain remains self-contained without load-bearing reduction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (3)
- potential function parameters
- drift coefficients
- contrastive loss weight
axioms (2)
- domain assumption Latent state evolves under a learned potential with drift
- domain assumption Mode transitions occur via saddle-node bifurcations with ghost-attractor escape
invented entities (1)
-
Ghost attractor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choroman- skiet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorcket al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[5]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Robotics: Science and Systems (RSS), 2023
2023
-
[6]
J., Hansen, S., Filos, A., Brooks, E., et al
M. Laskin, L. Wang, J. Oh, E. Parisotto, S. Spencer, R. Steiger- wald, H. Strathmann, S. Singh, C. Paduraru, A. Fidjelandet al., “In-context reinforcement learning with algorithm distillation,”arXiv preprint arXiv:2210.14215, 2022
-
[7]
Computation through neural population dynamics,
S. Vyas, M. D. Golub, D. Sussillo, and K. V . Shenoy, “Computation through neural population dynamics,”Annual Review of Neuroscience, vol. 43, pp. 249–275, 2020
2020
-
[8]
Neural population dynamics during reaching,
M. M. Churchland, J. P. Cunningham, M. T. Kaufman, J. D. Foster, P. Nuyujukian, S. I. Ryu, and K. V . Shenoy, “Neural population dynamics during reaching,”Nature, vol. 487, no. 7405, pp. 51–56, 2012
2012
-
[9]
Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks,
D. Sussillo and O. Barak, “Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks,”Neural Com- putation, vol. 25, no. 3, pp. 626–649, 2013
2013
-
[10]
S. H. Strogatz,Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering, 2nd ed. Westview Press, 2015
2015
-
[11]
Neural ordinary differential equations,
R. T. Chen, Y . Rubanova, J. Bettencourt, and D. K. Duvenaud, “Neural ordinary differential equations,”Advances in Neural Information Pro- cessing Systems, vol. 31, 2018
2018
-
[12]
Hopfield Networks is All You Need
H. Ramsauer, B. Sch ¨afl, J. Lehner, P. Seidl, M. Widrich, T. Adler, L. Gruber, M. Holzleitner, M. Pavlovi ´c, G. K. Sandveet al., “Hopfield networks is all you need,”arXiv preprint arXiv:2008.02217, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2008
-
[13]
Hamiltonian neural net- works,
S. Greydanus, M. Dzamba, and J. Yosinski, “Hamiltonian neural net- works,” inAdvances in Neural Information Processing Systems, vol. 32, 2019
2019
-
[14]
Noise-induced stabilization of saddle-node ghosts,
J. Sardany ´es, C. Raich, and T. Alarc ´on, “Noise-induced stabilization of saddle-node ghosts,”New Journal of Physics, vol. 22, no. 9, p. 093064, 2020
2020
-
[15]
What neuroscience can tell AI about learning in continuously changing environments,
D. Durstewitz, B. Averbeck, and G. Koppe, “What neuroscience can tell AI about learning in continuously changing environments,”Nature Machine Intelligence, vol. 7, pp. 1897–1912, 2025
1912
-
[16]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational Conference on Machine Learning. PMLR, 2017, pp. 1126–1135
2017
-
[17]
Promp: Proximal meta-policy search,
J. Rothfuss, D. Lee, I. Clavera, T. Asfour, and P. Abbeel, “Promp: Proximal meta-policy search,”arXiv preprint arXiv:1810.06784, 2019
-
[18]
Supervised pretraining can learn in-context reinforcement learning,
J. N. Lee, A. Xie, A. Pacchiano, Y . Chandak, C. Finn, O. Nachum, and E. Brunskill, “Supervised pretraining can learn in-context reinforcement learning,”Advances in Neural Information Processing Systems, vol. 36, 2024
2024
-
[19]
RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
Y . Duan, J. Schulman, X. Chen, P. L. Bartlett, I. Sutskever, and P. Abbeel, “Rl 2: Fast reinforcement learning via slow reinforcement learning,”arXiv preprint arXiv:1611.02779, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Imitating human behaviour with diffusion models,
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Momennejad, K. Hofmannet al., “Imitating human behaviour with diffusion models,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[21]
Flow matching for generative modeling,
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[22]
Consistency models,
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever, “Consistency models,” inInternational Conference on Machine Learning (ICML), 2023
2023
-
[23]
Consistency policy: Accelerated visuomotor policies via consistency distillation,
A. Prasad, K. Lin, P. Isolaet al., “Consistency policy: Accelerated visuomotor policies via consistency distillation,” inRobotics: Science and Systems (RSS), 2024
2024
-
[24]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
S. Liu, L. Wu, B. Liet al., “Rdt-1b: a diffusion foundation model for bimanual manipulation,”arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
RoLD: Robot latent diffu- sion for multi-task policy modeling,
W. Tan, B. Liu, J. Zhang, R. Song, and J. Fu, “RoLD: Robot latent diffu- sion for multi-task policy modeling,”arXiv preprint arXiv:2403.07312, 2024
-
[26]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn et al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xuet al., “Octo: An open-source generalist robot policy,”arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finnet al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
M. J. Kim, C. Finn, and P. Liang, “Fine-tuning vision-language- action models: Optimizing speed and success,”arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
J. Ye, S. Gong, J. Gao, J. Fan, S. Wu, W. Bi, H. Bai, L. Shang, and L. Kong, “Dream-vl and dream-vla: Open vision-language and vision- language-action models with diffusion language model backbone,”arXiv preprint arXiv:2512.22615, 2025
-
[31]
Neural networks and physical systems with emergent collective computational abilities,
J. J. Hopfield, “Neural networks and physical systems with emergent collective computational abilities,”Proceedings of the National Academy of Sciences, vol. 79, no. 8, pp. 2554–2558, 1982
1982
-
[32]
Dynamic movement primitives – a framework for motor control in humans and humanoid robotics,
S. Schaal, “Dynamic movement primitives – a framework for motor control in humans and humanoid robotics,”Adaptive Motion of Animals and Machines, pp. 261–280, 2006
2006
-
[33]
Dynamical movement primitives: learning attractor models for motor behaviors,
A. J. Ijspeert, J. Nakanishi, H. Hoffmann, P. Pastor, and S. Schaal, “Dynamical movement primitives: learning attractor models for motor behaviors,”Neural Computation, vol. 25, no. 2, pp. 328–373, 2013
2013
-
[34]
Learning stable nonlinear dy- namical systems with gaussian mixture models,
S. M. Khansari-Zadeh and A. Billard, “Learning stable nonlinear dy- namical systems with gaussian mixture models,”IEEE Transactions on Robotics, vol. 27, no. 5, pp. 943–957, 2011
2011
-
[35]
Geometric singular perturbation theory for ordinary dif- ferential equations,
N. Fenichel, “Geometric singular perturbation theory for ordinary dif- ferential equations,”Journal of Differential Equations, vol. 31, no. 1, pp. 53–98, 1979
1979
-
[36]
Shadmehr and S
R. Shadmehr and S. P. Wise,The Computational Neurobiology of Reaching and Pointing: A Foundation for Motor Learning. MIT Press, 2005
2005
-
[37]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” inInternational Conference on Machine Learning, 2020, pp. 1597–1607
2020
-
[38]
LIBERO: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “LIBERO: Benchmarking knowledge transfer for lifelong robot learning,” inAd- vances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[39]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRobotics: Science and Systems, 2023. PREPRINT. THIS WORK HAS BEEN SUBMITTED TO THE IEEE FOR POSSIBLE PUBLICATION. 16
2023
-
[40]
Deep learning model compression with rank reduction in tensor decomposition,
W. Dai, J. Fan, Y . Miao, and K. Hwang, “Deep learning model compression with rank reduction in tensor decomposition,”IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 12, pp. 18 293–18 307, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.