Motion-Focused Latent Action Enables Cross-Embodiment VLA Training from Human EgoVideos
Pith reviewed 2026-07-03 23:42 UTC · model grok-4.3
The pith
Latent actions from unlabeled human videos let VLA models adapt to robots using only 50 trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
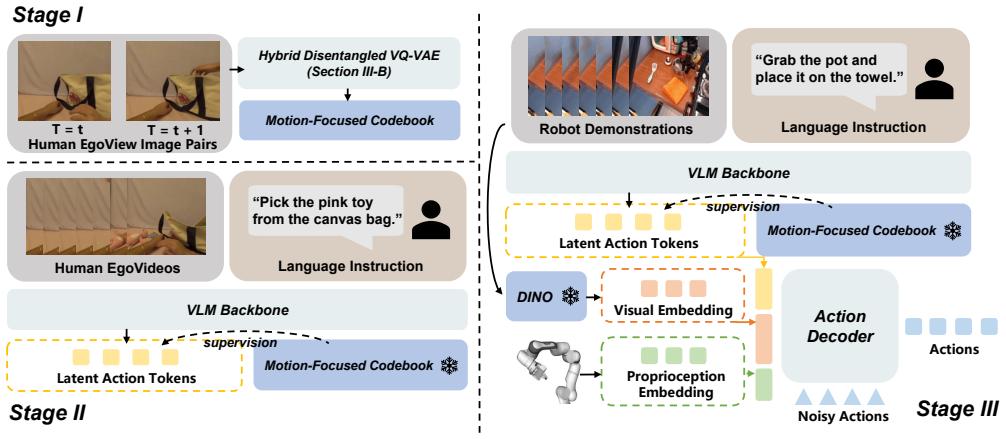
By pre-training exclusively on unlabeled human videos with a cross-embodiment action codebook derived from a Hybrid Disentangled VQ-VAE that decouples motion from backgrounds via physical masks, followed by intent-perception decoupling at adaptation time, the method produces VLA models that perform competitively with state-of-the-art models trained on massive annotated datasets while requiring only 50 trajectories for downstream adaptation.
What carries the argument
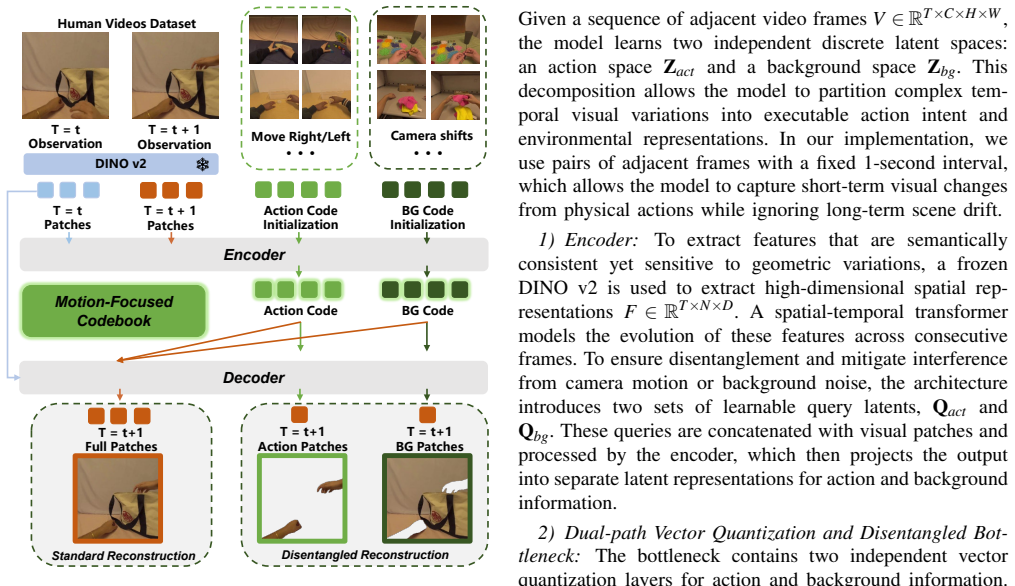
Hybrid Disentangled VQ-VAE that decouples motion dynamics from environmental backgrounds through physical masks to construct a cross-embodiment action codebook, together with the intent-perception decoupling strategy used at adaptation.
If this is right
- Pre-training on human videos transfers general action priors to new robot embodiments without any robot data.
- Downstream adaptation succeeds with only 50 trajectories while matching models trained on far larger annotated sets.
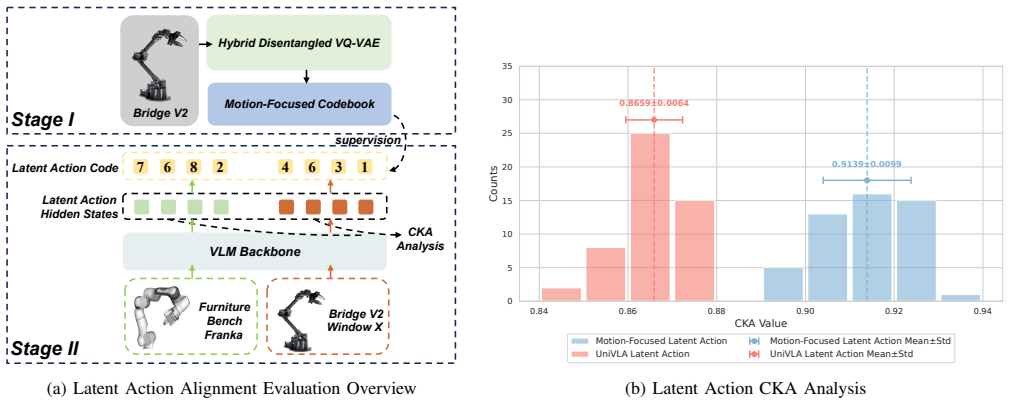
- Intent-perception decoupling reduces action hallucinations during embodiment-specific use.
- The approach works in both simulation and real-world environments.
- Abundant unlabeled egocentric human videos become usable for VLA model training.
Where Pith is reading between the lines
- This could lower the data-collection cost for generalist robot policies by shifting most learning to existing human video archives.
- Similar motion-focused latent extraction might be tested on instructional or demonstration videos from other sources.
- Relaxing the physical-mask requirement could broaden applicability if stronger disentanglement techniques emerge.
- Latent action codes may prove useful for bridging human and robot action spaces in additional multimodal tasks.
Load-bearing premise
The Hybrid Disentangled VQ-VAE can effectively decouple motion dynamics from environmental backgrounds through physical masks to construct a cross-embodiment action codebook.
What would settle it
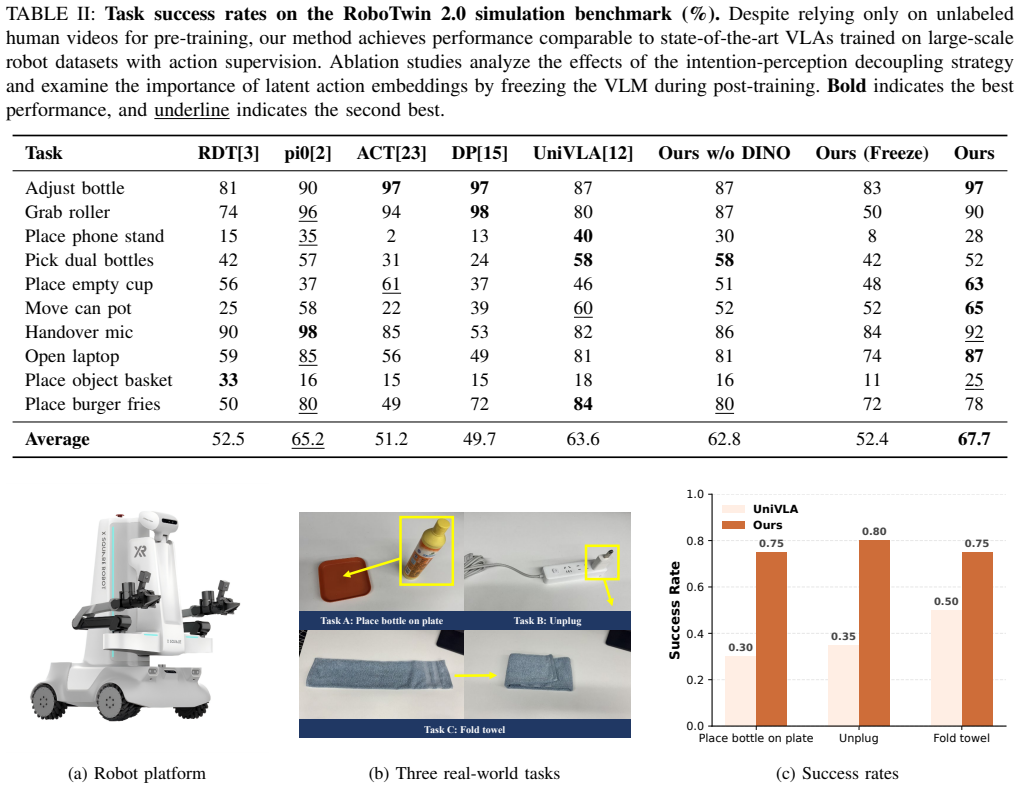
If a model pre-trained only on the human videos requires substantially more than 50 trajectories or fails to reach comparable performance to annotated-data baselines in the reported simulation and real-world tasks, the central claim would be falsified.
Figures

read the original abstract
Training generalist Vision-Language-Action(VLA) models typically requires massive, diverse robotic datasets with high-fidelity action annotations. While egocentric human manipulation videos are abundant and capture significant environmental diversity, the absence of action labels makes them difficult to use in conventional training paradigms. To address this, we propose a latent-action-based framework designed to extract general action priors from unlabeled human videos. The architecture features a Hybrid Disentangled VQ-VAE that decouples motion dynamics from environmental backgrounds through physical masks, enabling the construction of a cross-embodiment action codebook. By pre-training on human videos with the codebook, the VLM backbone learns deep representations of action intent. For adaptation to specific embodiments, we introduce an intent-perception decoupling strategy where the VLM predicts the action intent while a separate frozen visual encoder provides state-specific features to the action expert, thereby reducing action hallucinations. Results in simulation and real-world environments show that our method, pre-trained exclusively on unlabeled human videos, performs competitively with state-of-the-art VLA models trained on massive annotated datasets, requiring only 50 trajectories for downstream adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a latent-action framework for Vision-Language-Action (VLA) models that pre-trains exclusively on unlabeled human egocentric videos. A Hybrid Disentangled VQ-VAE decouples motion dynamics from backgrounds using physical masks to build a cross-embodiment action codebook; the VLM backbone learns action-intent representations from this codebook. An intent-perception decoupling strategy (VLM predicts intent while a frozen visual encoder supplies embodiment-specific features) is introduced for downstream adaptation. The central empirical claim is that this pipeline, after pre-training on human videos, achieves competitive performance with SOTA VLA models (trained on large annotated robotic datasets) using only 50 trajectories for adaptation in both simulation and real-world environments.
Significance. If the reported results hold, the work would be significant because it demonstrates a pathway to leverage abundant unlabeled human video data for robotic policy learning, substantially lowering the data-collection barrier for generalist VLA models. The approach directly targets the scarcity of high-quality annotated robot trajectories by transferring general action priors across embodiments.
major comments (2)
- [Abstract] Abstract: the assertion that the method 'performs competitively with state-of-the-art VLA models trained on massive annotated datasets' using only 50 trajectories is presented without any quantitative metrics, baselines, error bars, or experimental details. This claim is load-bearing for the paper's central contribution yet cannot be evaluated from the supplied text.
- [Methods (Hybrid Disentangled VQ-VAE)] Hybrid Disentangled VQ-VAE description: the claim that physical masks enable effective decoupling of motion dynamics from environmental backgrounds to produce a transferable cross-embodiment action codebook is central to the pre-training pipeline, but no ablation studies, reconstruction metrics, or codebook analysis are referenced to substantiate that the disentanglement succeeds.
minor comments (1)
- [Abstract] Abstract: the acronym 'VLA' is used before its expansion ('Vision-Language-Action') is given.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'performs competitively with state-of-the-art VLA models trained on massive annotated datasets' using only 50 trajectories is presented without any quantitative metrics, baselines, error bars, or experimental details. This claim is load-bearing for the paper's central contribution yet cannot be evaluated from the supplied text.
Authors: We agree that the abstract would benefit from explicit quantitative support for this central claim. The detailed results, including success rates, baselines, and error bars from both simulation and real-world experiments with 50 trajectories, appear in the Experiments section. We have revised the abstract to include key quantitative metrics and baseline comparisons to make the claim self-contained. revision: yes
-
Referee: [Methods (Hybrid Disentangled VQ-VAE)] Hybrid Disentangled VQ-VAE description: the claim that physical masks enable effective decoupling of motion dynamics from environmental backgrounds to produce a transferable cross-embodiment action codebook is central to the pre-training pipeline, but no ablation studies, reconstruction metrics, or codebook analysis are referenced to substantiate that the disentanglement succeeds.
Authors: We acknowledge that the manuscript would be strengthened by direct empirical validation of the physical masks' contribution to disentanglement. The current text emphasizes the architectural motivation and end-to-end results. We have added ablation studies (with/without masks), reconstruction metrics, and codebook analysis to the Methods and Experiments sections of the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript describes an empirical ML pipeline: a Hybrid Disentangled VQ-VAE is trained on unlabeled ego-videos to build an action codebook, followed by VLM pre-training and a downstream adaptation stage that uses 50 trajectories. No first-principles derivation, uniqueness theorem, or parameter-free prediction is asserted; all performance claims rest on reported simulation and real-robot metrics rather than any reduction of outputs to fitted inputs or self-citations. The architecture choices (physical masks, intent-perception split) are presented as engineering decisions whose value is measured externally, leaving the central claim self-contained against the provided experimental results.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Hybrid Disentangled VQ-VAE
no independent evidence
-
intent-perception decoupling strategy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “pi 0: A vision- language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu, “Rdt-1b: a diffusion foundation model for bimanual manipulation,”arXiv preprint arXiv:2410.07864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[5]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huanget al., “Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems,”arXiv preprint arXiv:2503.06669, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Egomimic: Scaling imitation learning via egocentric video,
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu, “Egomimic: Scaling imitation learning via egocentric video,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 13 226–13 233
2025
-
[7]
Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies,
C. Yuan, R. Zhou, M. Liu, Y . Hu, S. Wang, L. Yi, C. Wen, S. Zhang, and Y . Gao, “Motiontrans: Human vr data enable motion-level learning for robotic manipulation policies,”arXiv preprint arXiv:2509.17759, 2025
-
[8]
H-rdt: Human manipulation enhanced bimanual robotic manipulation,
H. Bi, L. Wu, T. Lin, H. Tan, Z. Su, H. Su, and J. Zhu, “H-rdt: Human manipulation enhanced bimanual robotic manipulation,”arXiv preprint arXiv:2507.23523, 2025
-
[9]
Latent Action Pretraining from Videos
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Linet al., “Latent action pretraining from videos,” arXiv preprint arXiv:2410.11758, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
X. Chen, J. Guo, T. He, C. Zhang, P. Zhang, D. C. Yang, L. Zhao, and J. Bian, “Igor: Image-goal representations are the atomic con- trol units for foundation models in embodied ai,”arXiv preprint arXiv:2411.00785, 2024
-
[11]
What do latent action models actually learn?
C. Zhang, T. Pearce, P. Zhang, K. Wang, X. Chen, W. Shen, L. Zhao, and J. Bian, “What do latent action models actually learn?” 2025. [Online]. Available: https://arxiv.org/abs/2506.15691
-
[12]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li, “Univla: Learning to act anywhere with task-centric latent actions,” arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
OpenVLA: An Open-Source Vision-Language-Action Model
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
NVIDIA, :, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[16]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” 2023. [Online]. Available: https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
X. Chen, H. Wei, P. Zhang, C. Zhang, K. Wang, Y . Guo, R. Yang, Y . Wang, X. Xiao, L. Zhaoet al., “Villa-x: enhancing latent action modeling in vision-language-action models,”arXiv preprint arXiv:2507.23682, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[19]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll ´ar, and R. Gir- shick, “Segment anything,”arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Prismatic vlms: Investigating the design space of visually- conditioned language models,
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh, “Prismatic vlms: Investigating the design space of visually- conditioned language models,” inForty-first International Conference on Machine Learning, 2024
2024
-
[21]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wanget al., “Spatialvla: Exploring spatial representations for visual-language-action model,”arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong, O. Mees, C. Finn, and S. Levine, “Fast: Efficient action tokenization for vision-language-action models,”arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Bridgedata v2: A dataset for robot learning at scale,
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V . Myers, K. Fang, C. Finn, and S. Levine, “Bridgedata v2: A dataset for robot learning at scale,” in Conference on Robot Learning (CoRL), 2023
2023
-
[25]
Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “Libero: Benchmarking knowledge transfer for lifelong robot learn- ing,”Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[26]
C. Yuan, S. Joshi, S. Zhu, H. Su, H. Zhao, and Y . Gao, “Roboengine: Plug-and-play robot data augmentation with semantic robot segmen- tation and background generation,”arXiv preprint arXiv:2503.18738, 2025
-
[27]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Guet al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang, “Egodex: Learning dexterous manipulation from large-scale egocentric video,” 2025. [Online]. Available: https://arxiv.org/abs/2505.11709
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,
M. Heo, Y . Lee, D. Lee, and J. J. Lim, “Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,” in Robotics: Science and Systems, 2023
2023
-
[30]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inInternational conference on machine learning. PMlR, 2019, pp. 3519–3529
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.