Scaling Generative Foundation Models for Chest Radiography with Rectified Flow Transformers
Pith reviewed 2026-06-26 21:08 UTC · model grok-4.3
The pith
A 1.3-billion-parameter model trained on 1.2 million chest radiographs generates images that clinical experts cannot distinguish from real ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
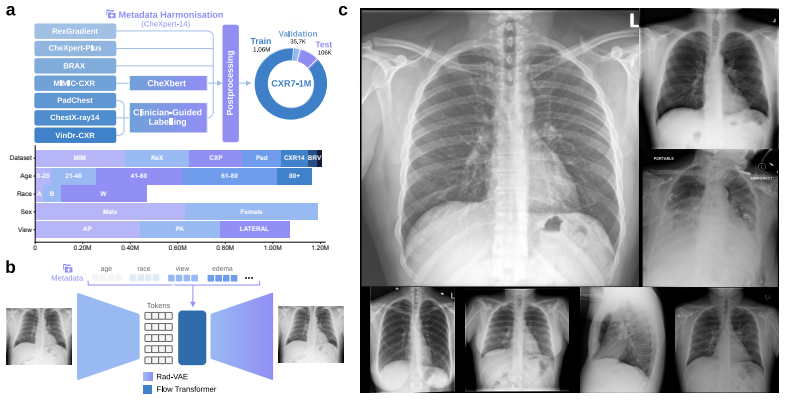
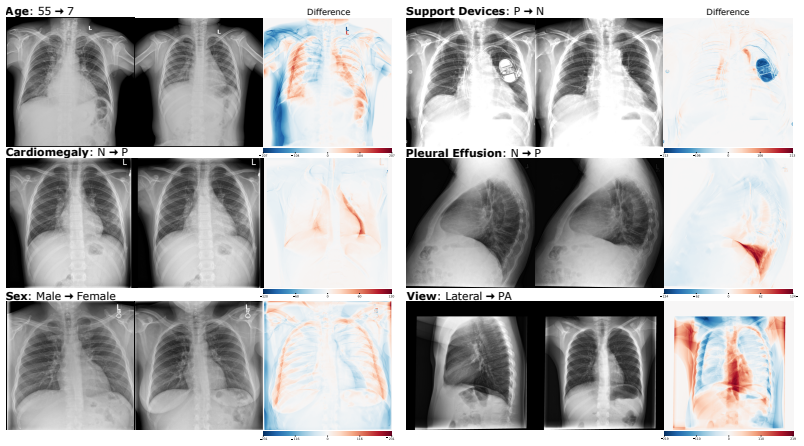
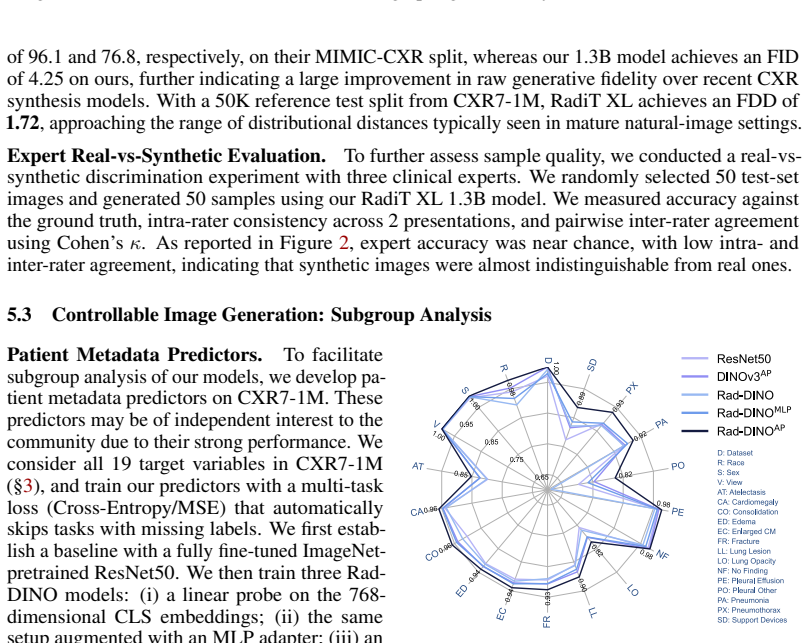
The authors introduce the first generative foundation model for chest radiograph synthesis trained from scratch at the billion-parameter scale, with over 1.3B parameters trained for 1.6T tokens on a curated dataset comprising 1.2M radiographs and clinical expert-guided metadata. The model supports controllable radiograph generation and editing across multiple demographic subgroups, acquisition views, and a dozen pathologies while advancing synthesis fidelity to the point that produced images are indistinguishable from real radiographs to clinical experts.
What carries the argument
A rectified flow transformer scaled to 1.3 billion parameters that performs the controlled synthesis and editing of chest radiographs.
If this is right
- Controlled synthesis becomes feasible across demographic subgroups, acquisition views, and multiple pathologies at previously unattained fidelity.
- Clinical datasets can be diversified with synthetic images to mitigate generalization failures in existing radiographic AI.
- Robustness testing of diagnostic models can incorporate generated examples that match real acquisition conditions.
- High-parameter-scale training from scratch is shown viable for specialist medical image domains.
Where Pith is reading between the lines
- If the indistinguishability holds under quantitative metrics, the model could serve as a data-augmentation engine to expand rare pathology examples without new patient recruitment.
- The same scaling recipe might transfer to other radiographic or cross-sectional modalities where data scarcity limits model robustness.
- Downstream utility could be tested by measuring whether diagnostic performance on real cases improves when training sets are augmented with the generated images.
Load-bearing premise
Expert visual indistinguishability serves as a sufficient proxy for high-fidelity synthesis and downstream clinical utility without additional quantitative validation or utility testing.
What would settle it
A blinded expert study in which clinicians identify the synthetic images at rates significantly above chance, or a controlled experiment showing that diagnostic models trained only on the generated images perform worse on real patient test sets than models trained on real data.
Figures
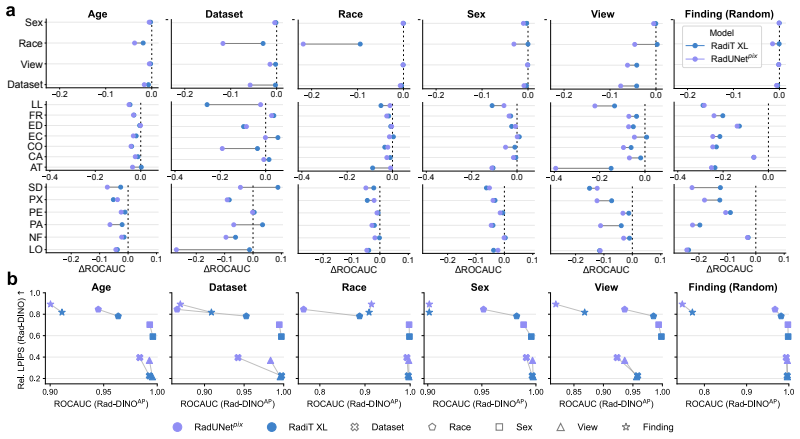

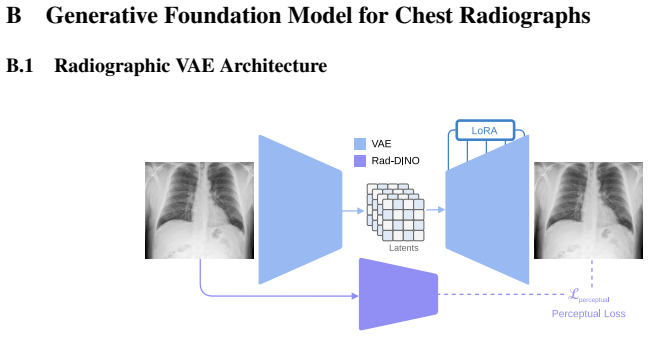
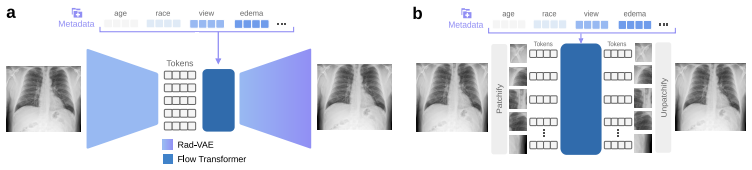
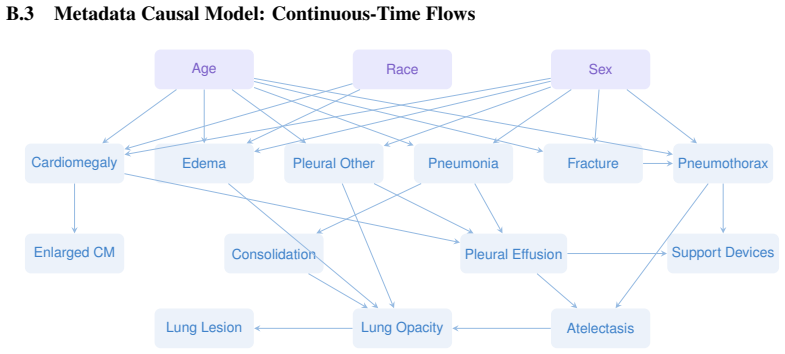
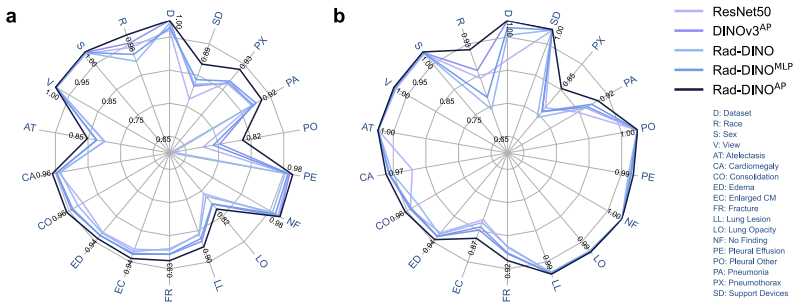

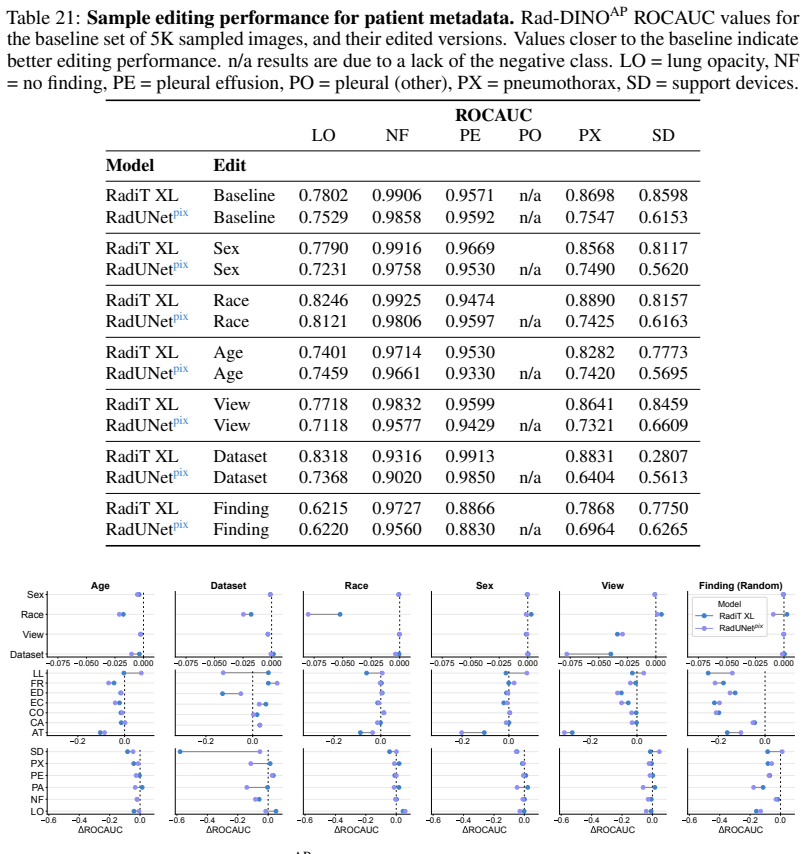
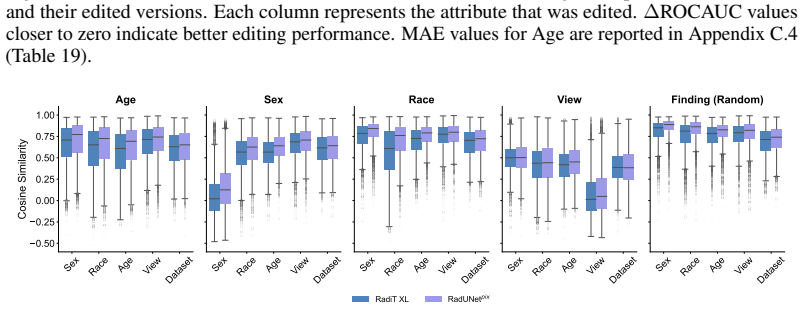
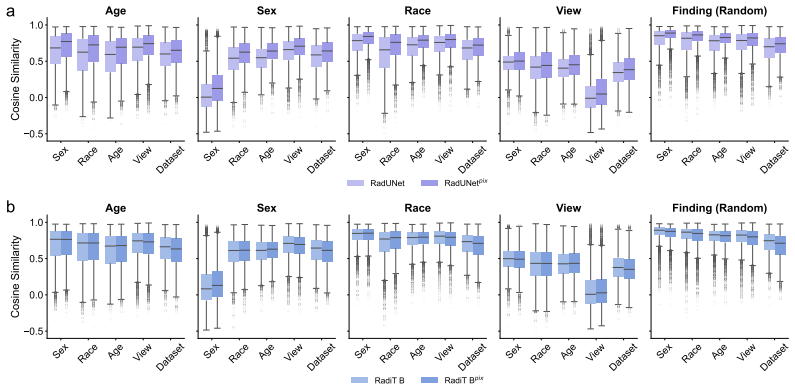
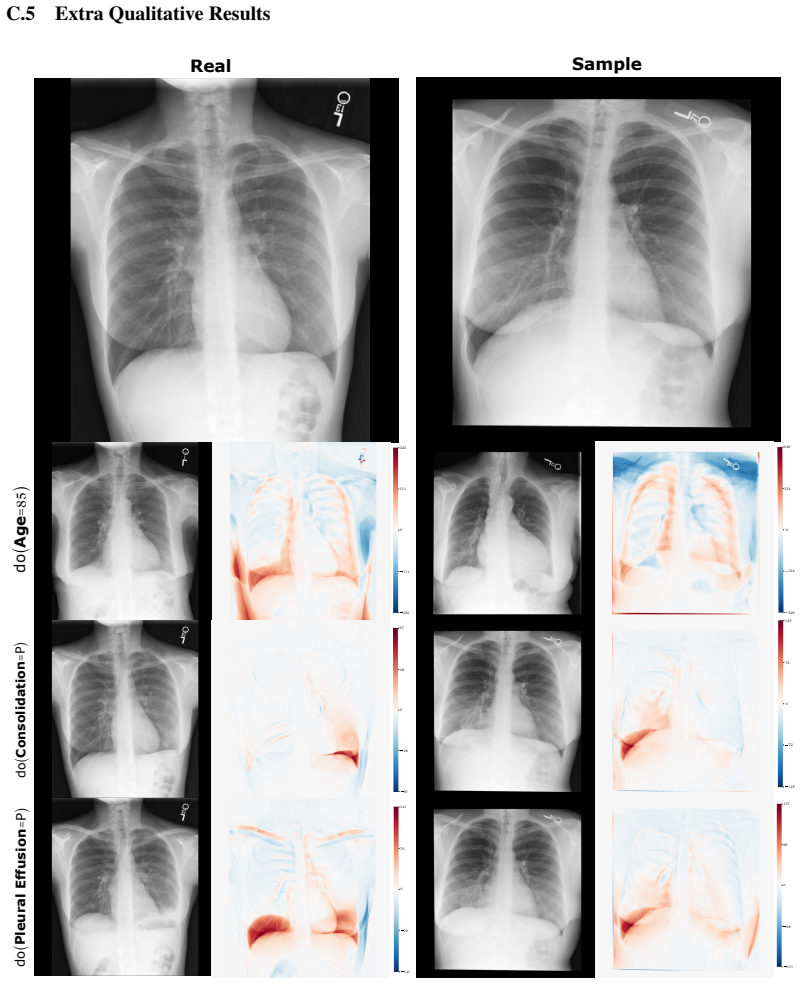
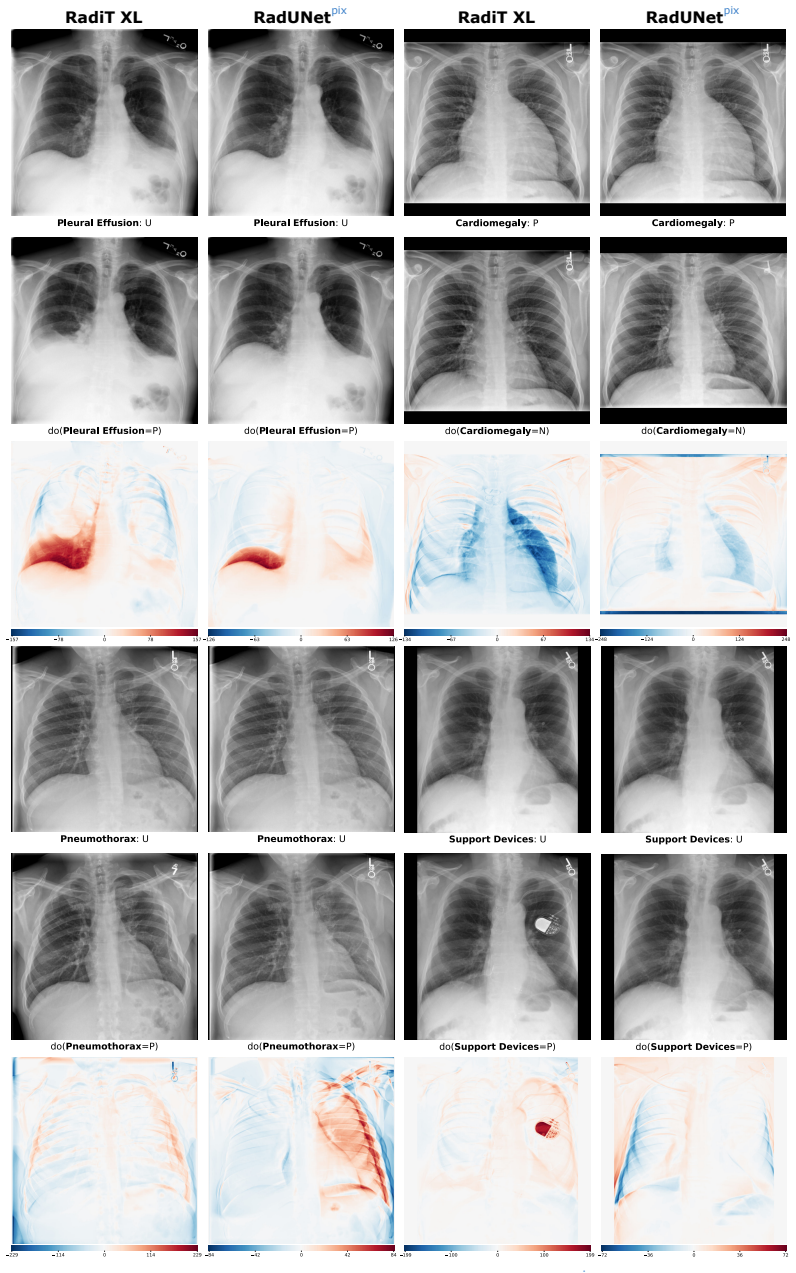
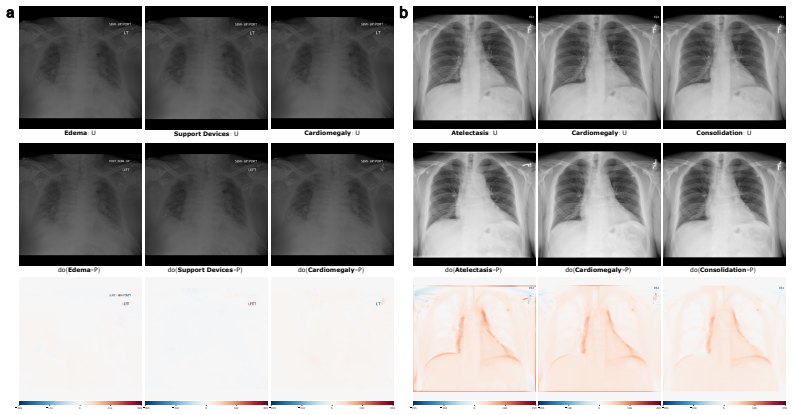
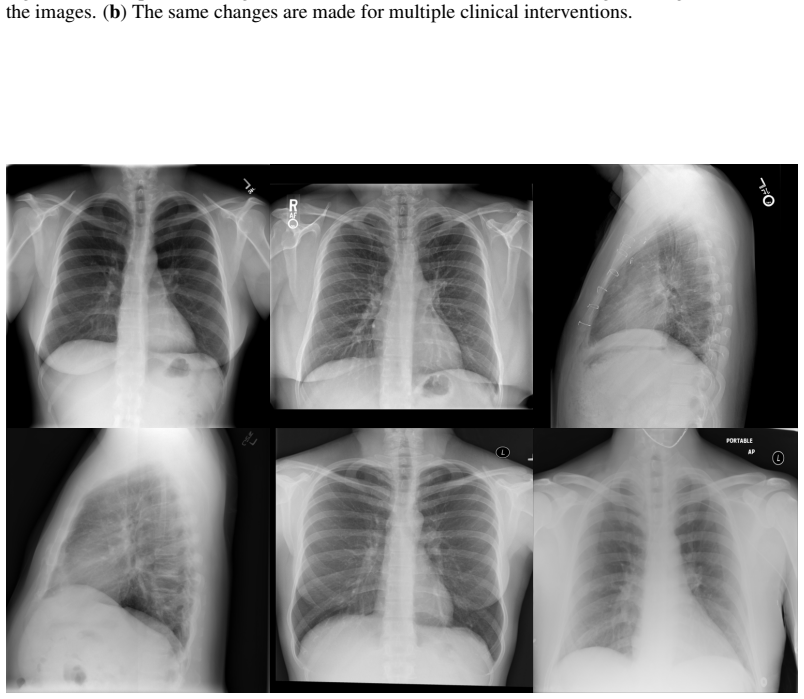
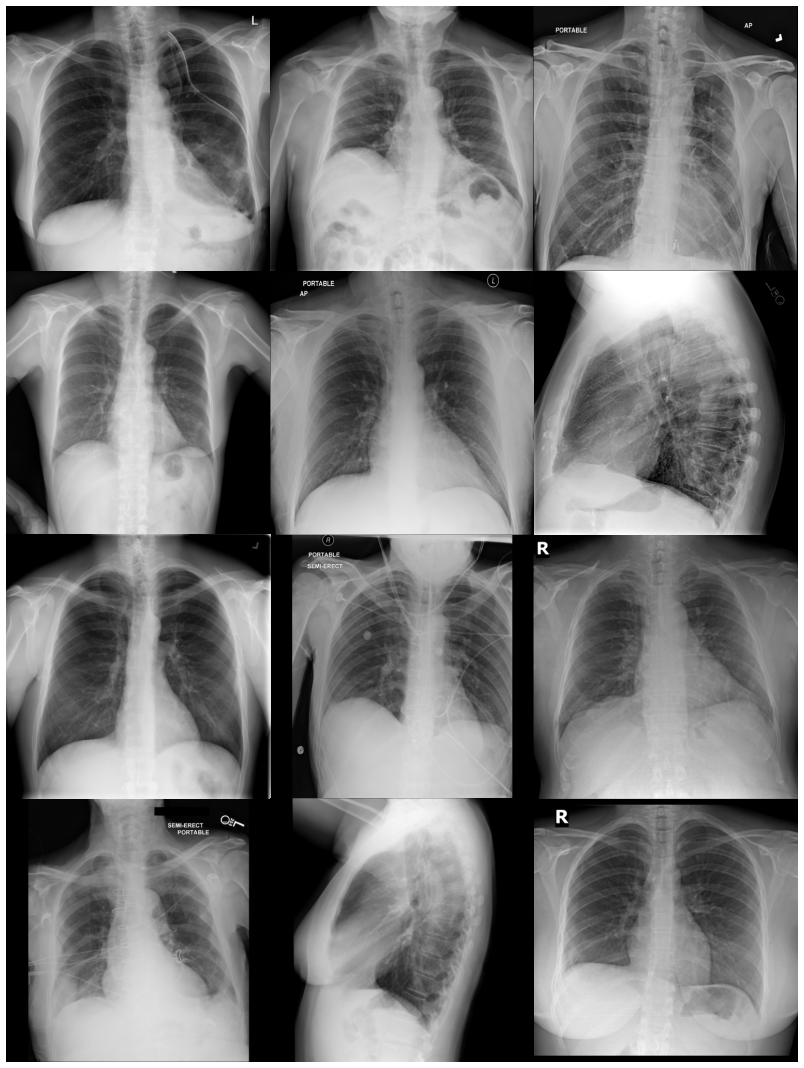
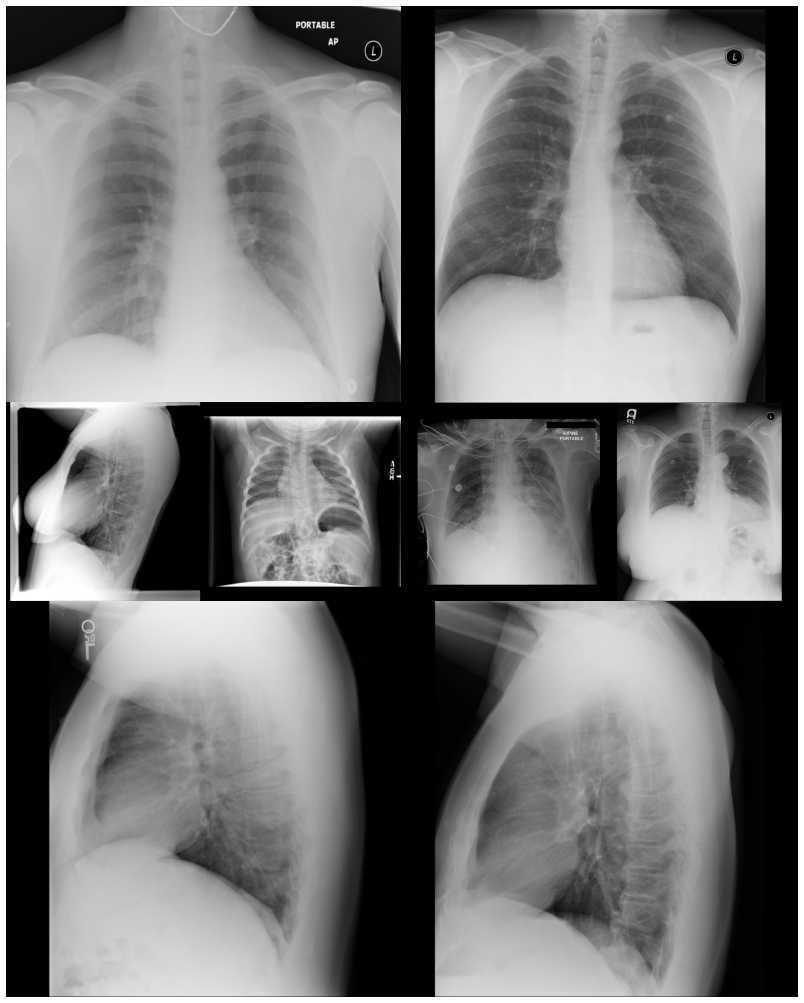
read the original abstract
We introduce the first generative foundation model for chest radiograph synthesis trained from scratch at the billion-parameter scale. Existing radiographic AI models often suffer from poor generalisation across patient subpopulations, institutions, and acquisition settings, resulting in limited real-world clinical utility. Controlled, high-fidelity synthesis of chest radiographs is a promising path toward diversifying clinical datasets and evaluating the robustness of diagnostic models. Therefore, we present the largest specialist generative foundation model for chest radiographs to date, with over 1.3B parameters, trained for 1.6T tokens on a curated, heterogeneous dataset comprising 1.2M radiographs and clinical expert-guided metadata. Our model supports controllable radiograph generation and editing across multiple demographic subgroups, acquisition views, and a dozen pathologies. Moreover, we significantly advance the state of the art in radiograph synthesis fidelity, producing images that are indistinguishable from real radiographs to clinical experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first generative foundation model for chest radiograph synthesis trained from scratch at the billion-parameter scale (over 1.3B parameters) using Rectified Flow Transformers. Trained for 1.6T tokens on a curated dataset of 1.2M radiographs with expert-guided metadata, the model supports controllable generation and editing across demographic subgroups, acquisition views, and a dozen pathologies. It claims to significantly advance the state of the art by producing images indistinguishable from real radiographs to clinical experts.
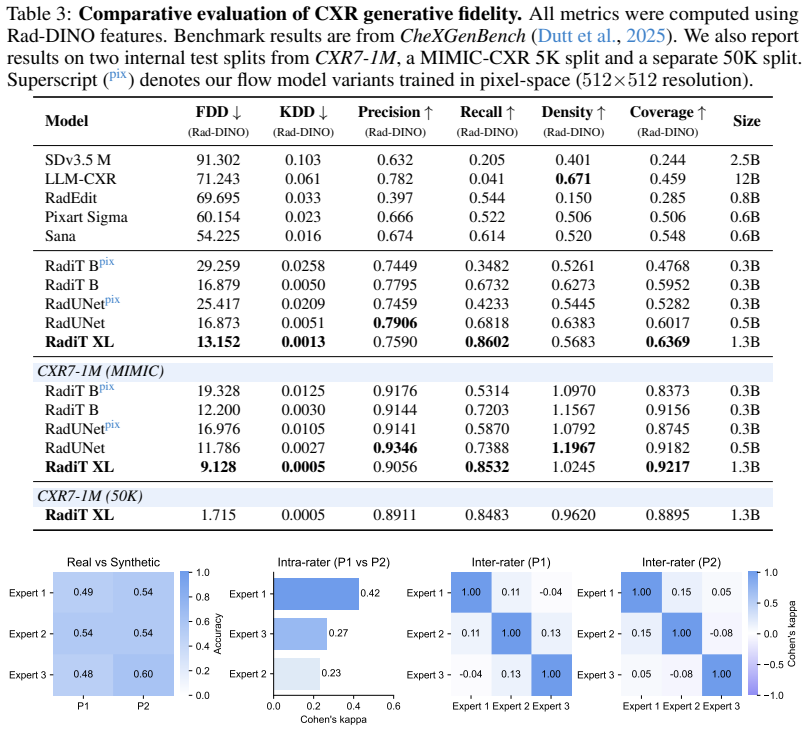
Significance. If the fidelity and controllability claims hold with proper validation, this would be a notable advance in scaling specialist generative models for medical imaging, offering potential for dataset diversification and robustness testing of diagnostic models. The reported training scale and heterogeneous data curation are strengths, but the absence of quantitative metrics or study details for the core indistinguishability claim limits the assessed significance.
major comments (2)
- [Abstract] Abstract: The claim that the model produces 'images that are indistinguishable from real radiographs to clinical experts' is presented without any information on the expert study design, including rater count, number of images per rater, blinding protocol, statistical tests for indistinguishability, inter-rater agreement, or power analysis. This is load-bearing for both the SOTA fidelity assertion and the overall utility argument.
- [Results] Results (and abstract): No quantitative synthesis metrics such as FID, KID, precision/recall, or pathology-specific detection performance are reported, nor any downstream tests of whether synthetic data improves classifier robustness or generalization. The expert judgment is the sole evidence offered for fidelity and clinical utility.
minor comments (1)
- [Abstract] Abstract: The parameter count (1.3B) and token count (1.6T) are stated without cross-reference to the model architecture section or training hyperparameters.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and the opportunity to clarify and strengthen our manuscript. Below we respond to the major comments point by point.
read point-by-point responses
-
Referee: The claim that the model produces 'images that are indistinguishable from real radiographs to clinical experts' is presented without any information on the expert study design, including rater count, number of images per rater, blinding protocol, statistical tests for indistinguishability, inter-rater agreement, or power analysis. This is load-bearing for both the SOTA fidelity assertion and the overall utility argument.
Authors: We agree that the abstract would benefit from a brief reference to the expert study design supporting the indistinguishability claim. The full manuscript describes the evaluation protocol in the results section, but we will revise the abstract to summarize key elements of the study (multiple clinical experts, blinded presentation, and statistical testing for equivalence). We will also verify that the methods and results sections provide complete information on rater numbers, image counts per rater, blinding, inter-rater agreement, and power analysis to make the claim fully transparent. revision: yes
-
Referee: No quantitative synthesis metrics such as FID, KID, precision/recall, or pathology-specific detection performance are reported, nor any downstream tests of whether synthetic data improves classifier robustness or generalization. The expert judgment is the sole evidence offered for fidelity and clinical utility.
Authors: Expert clinical judgment is the primary evidence presented because it directly assesses perceptual and diagnostic realism in a medical context, where standard generative metrics such as FID have known limitations in correlating with human perception for high-resolution radiographs. Nevertheless, we acknowledge the utility of reporting automated metrics for comparability with prior work. In the revised manuscript we will add FID, KID, and precision/recall computed on a held-out test set. Downstream experiments testing whether synthetic images improve classifier robustness were outside the scope of the present study, which focused on model development and fidelity validation; we will note this explicitly as a limitation and direction for future work. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents empirical results from training a large generative model on external data, with central claims resting on model scale (1.3B parameters, 1.6T tokens, 1.2M radiographs) and external expert visual assessment rather than any internal derivation, equation, or prediction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations are present in the provided text; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nature Medicine , volume=
Generative models improve fairness of medical classifiers under distribution shifts , author=. Nature Medicine , volume=. 2024 , publisher=
2024
-
[2]
NEJM AI , volume =
Yuanfeng Ji and Dan Lin and Xiyue Wang and Lu Zhang and Wenhui Zhou and Chongjian Ge and Ruihang Chu and Xiaoli Yang and Junhan Zhao and Junsong Chen and Xiangde Luo and Sen Yang and Jin Fang and Ping Luo and Ruijiang Li , title =. NEJM AI , volume =. 2026 , doi =
2026
-
[3]
arXiv preprint arXiv:2509.12818 , year=
Data Scaling Laws for Radiology Foundation Models , author=. arXiv preprint arXiv:2509.12818 , year=
-
[4]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[5]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[6]
Demystifying
Miko. Demystifying. International Conference on Learning Representations , year=
-
[7]
International conference on machine learning , pages=
Reliable fidelity and diversity metrics for generative models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[8]
GLU Variants Improve Transformer
Glu variants improve transformer , author=. arXiv preprint arXiv:2002.05202 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[9]
European Conference on Computer Vision , pages=
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[10]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[11]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Combining automatic labelers and expert annotations for accurate radiology report labeling using BERT , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[12]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[13]
2025 , url=
DINO Perceptual Loss , author=. 2025 , url=
2025
-
[14]
Nature Machine Intelligence , volume=
Exploring scalable medical image encoders beyond text supervision , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
2025
-
[15]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the training dynamics of diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[16]
Medical image analysis , volume=
Padchest: A large chest x-ray image dataset with multi-label annotated reports , author=. Medical image analysis , volume=. 2020 , publisher=
2020
-
[17]
arXiv preprint arXiv:2405.19538 , year=
Chexpert plus: Augmenting a large chest x-ray dataset with text radiology reports, patient demographics and additional image formats , author=. arXiv preprint arXiv:2405.19538 , year=
-
[18]
Scientific Data , volume=
BRAX, Brazilian labeled chest x-ray dataset , author=. Scientific Data , volume=. 2022 , publisher=
2022
-
[19]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[20]
Scientific Data , volume=
VinDr-CXR: An open dataset of chest X-rays with radiologist’s annotations , author=. Scientific Data , volume=. 2022 , publisher=
2022
-
[21]
arXiv preprint arXiv:2505.00228 , year=
Rexgradient-160k: A large-scale publicly available dataset of chest radiographs with free-text reports , author=. arXiv preprint arXiv:2505.00228 , year=
-
[22]
Proceedings of the AAAI conference on artificial intelligence , volume=
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[23]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
arXiv preprint arXiv:2504.19621 , year=
AI Alignment in Medical Imaging: Unveiling Hidden Biases Through Counterfactual Analysis , author=. arXiv preprint arXiv:2504.19621 , year=
-
[25]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[26]
Factored Classifier-Free Guidance
Decoupled classifier-free guidance for counterfactual diffusion models , author=. arXiv preprint arXiv:2506.14399 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
PLOS digital health , volume=
Bias in medical AI: implications for clinical decision-making , author=. PLOS digital health , volume=. 2024 , publisher=
2024
-
[28]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Counterfactual Identifiability via Dynamic Optimal Transport , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[29]
Radiology , volume=
The growing nationwide radiologist shortage: current opportunities and ongoing challenges for international medical graduate radiologists , author=. Radiology , volume=. 2025 , publisher=
2025
-
[30]
Advances in neural information processing systems , volume=
Variational diffusion models , author=. Advances in neural information processing systems , volume=
-
[31]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[32]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Karras, Tero and Aittala, Miika and Lehtinen, Jaakko and Hellsten, Janne and Aila, Timo and Laine, Samuli , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
2024
-
[34]
, author=
Estimation of non-normalized statistical models by score matching. , author=. Journal of Machine Learning Research , volume=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Generative Modeling by Estimating Gradients of the Data Distribution , volume =
Song, Yang and Ermon, Stefano , booktitle =. Generative Modeling by Estimating Gradients of the Data Distribution , volume =
-
[37]
International conference on machine learning , pages=
Improved denoising diffusion probabilistic models , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[38]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
-
[39]
Denoising Diffusion Probabilistic Models , volume =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , booktitle =. Denoising Diffusion Probabilistic Models , volume =
-
[40]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[41]
arXiv preprint arXiv:2505.10496 , year=
Chexgenbench: a unified benchmark for fidelity, privacy and utility of synthetic chest radiographs , author=. arXiv preprint arXiv:2505.10496 , year=
-
[42]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[43]
Nature Biomedical Engineering , volume=
A vision--language foundation model for the generation of realistic chest x-ray images , author=. Nature Biomedical Engineering , volume=. 2025 , publisher=
2025
-
[44]
European Conference on Computer Vision , pages=
Radedit: stress-testing biomedical vision models via diffusion image editing , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[45]
EBioMedicine , volume=
Synthetically enhanced: unveiling synthetic data's potential in medical imaging research , author=. EBioMedicine , volume=. 2024 , publisher=
2024
-
[46]
BIOCOMPUTING 2021: proceedings of the Pacific symposium , pages=
CheXclusion: Fairness gaps in deep chest X-ray classifiers , author=. BIOCOMPUTING 2021: proceedings of the Pacific symposium , pages=. 2020 , organization=
2021
-
[47]
Computational and structural biotechnology journal , volume=
Synthetic data generation methods in healthcare: A review on open-source tools and methods , author=. Computational and structural biotechnology journal , volume=. 2024 , publisher=
2024
-
[48]
NPJ Digital Medicine , volume=
Bias recognition and mitigation strategies in artificial intelligence healthcare applications , author=. NPJ Digital Medicine , volume=. 2025 , publisher=
2025
-
[49]
Nature medicine , volume=
The value of standards for health datasets in artificial intelligence-based applications , author=. Nature medicine , volume=. 2023 , publisher=
2023
-
[50]
NPJ digital medicine , volume=
The future of digital health with federated learning , author=. NPJ digital medicine , volume=. 2020 , publisher=
2020
-
[51]
Journal of Medical Internet Research , author =
Facilitators and. Journal of Medical Internet Research , author =. 2025 , pages =. doi:10.2196/63649 , abstract =
-
[52]
arXiv preprint arXiv:2508.16783 , year=
Improving Performance, Robustness, and Fairness of Radiographic AI Models with Finely-Controllable Synthetic Data , author=. arXiv preprint arXiv:2508.16783 , year=
-
[53]
Robust image representations with counterfactual contrastive learning , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.media.2025.103668 , author =
-
[54]
Journal of Machine Learning Research , volume=
Underspecification presents challenges for credibility in modern machine learning , author=. Journal of Machine Learning Research , volume=
-
[55]
Bridging the chasm between. The Lancet , author =. 2022 , pmid =. doi:10.1016/S0140-6736(22)00235-5 , language =
-
[56]
High-performance medicine: The convergence of human and artificial intelligence
High-performance medicine: the convergence of human and artificial intelligence , volume =. Nature Medicine , author =. 2019 , note =. doi:10.1038/s41591-018-0300-7 , language =
-
[57]
Nature Machine Intelligence , author =
A causal perspective on dataset bias in machine learning for medical imaging , copyright =. Nature Machine Intelligence , author =. 2024 , note =. doi:10.1038/s42256-024-00797-8 , language =
-
[58]
2009 , publisher =
Causality , author =. 2009 , publisher =
2009
-
[59]
2017 , publisher =
Elements of causal inference: foundations and learning algorithms , author =. 2017 , publisher =
2017
-
[60]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Probabilistic and Causal Inference: The Works of Judea Pearl , pages =
Pearl, Judea and Bareinboim, Elias , title =. Probabilistic and Causal Inference: The Works of Judea Pearl , pages =. 2022 , isbn =
2022
-
[62]
The Fourth Blogpost Track at ICLR 2025 , year =
Diffusion Models and Gaussian Flow Matching: Two Sides of the Same Coin , author =. The Fourth Blogpost Track at ICLR 2025 , year =
2025
-
[63]
arXiv preprint arXiv:2506.05526 , year =
On Fitting Flow Models with Large Sinkhorn Couplings , author =. arXiv preprint arXiv:2506.05526 , year =
-
[64]
arXiv preprint arXiv:2509.25519 , year =
Flow Matching with Semidiscrete Couplings , author =. arXiv preprint arXiv:2509.25519 , year =
-
[65]
Identification and Estimation of Local Average Treatment Effects , volume =
Imbens, Guido W and Angrist, Joshua D , journal =. Identification and Estimation of Local Average Treatment Effects , volume =
-
[66]
ECAI 2024 , pages =
Causal Diffusion Autoencoders: Toward counterfactual generation via diffusion probabilistic models , author =. ECAI 2024 , pages =. 2024 , publisher =
2024
-
[67]
Forty-second International Conference on Machine Learning , year =
Diffusion Counterfactual Generation with Semantic Abduction , author =. Forty-second International Conference on Machine Learning , year =
-
[68]
Advances in neural information processing systems , volume =
Diffusion models beat gans on image synthesis , author =. Advances in neural information processing systems , volume =
-
[69]
Computer Vision -- ECCV 2024 , publisher =
RadEdit: Stress-Testing Biomedical Vision Models via Diffusion Image Editing , author =. Computer Vision -- ECCV 2024 , publisher =
2024
-
[70]
Scientific data , volume =
MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports , author =. Scientific data , volume =. 2019 , publisher =
2019
-
[71]
arXiv preprint arXiv:2301.09031 , year =
Counterfactual non-identifiability of learned structural causal models , author =. arXiv preprint arXiv:2301.09031 , year =
-
[72]
MICCAI Workshop on Deep Generative Models , pages =
What is healthy? generative counterfactual diffusion for lesion localization , author =. MICCAI Workshop on Deep Generative Models , pages =. 2022 , organization =
2022
-
[73]
IEEE transactions on pattern analysis and machine intelligence , volume =
Representation learning: A review and new perspectives , author =. IEEE transactions on pattern analysis and machine intelligence , volume =. 2013 , publisher =
2013
-
[74]
Journal of Machine Learning Research , volume =
POT: Python Optimal Transport , author =. Journal of Machine Learning Research , volume =
-
[75]
Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , pages =
Pearl, Judea , title =. Proceedings of the Seventeenth Conference on Uncertainty in Artificial Intelligence , pages =. 2001 , isbn =
2001
-
[76]
Causal Diagrams for Empirical Research , volume =
Pearl, Judea , journal =. Causal Diagrams for Empirical Research , volume =
-
[77]
Transactions on Machine Learning Research , issn =
Deep End-to-end Causal Inference , author =. Transactions on Machine Learning Research , issn =
-
[78]
International Conference on Machine Learning , pages =
Deep IV: A flexible approach for counterfactual prediction , author =. International Conference on Machine Learning , pages =. 2017 , organization =
2017
-
[79]
Advances in Neural Information Processing Systems , volume =
The causal-neural connection: Expressiveness, learnability, and inference , author =. Advances in Neural Information Processing Systems , volume =
-
[80]
International Conference on Machine Learning , pages =
Counterfactual Image Editing , author =. International Conference on Machine Learning , pages =. 2024 , organization =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.