On the QUEST for Uncertainty Quantification via Highest Density Regions
Pith reviewed 2026-06-26 20:48 UTC · model grok-4.3
The pith
QUEST quantifies regression uncertainty by the volume of highest-density regions rather than pointwise predictive risk.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proposes QUEST as a framework in which uncertainty is characterised by the volume of the highest-density region of a distribution's support at robustness parameter alpha. Unlike popular alternatives based on proper scoring rules, the QUEST measures of epistemic and aleatoric uncertainty satisfy axioms including monotonicity under distributional spread and invariance to location shifts. The authors establish connections between these measures and classical statistics from information theory and economics, and selective prediction benchmarks confirm favourable performance relative to variance and differential entropy.
What carries the argument
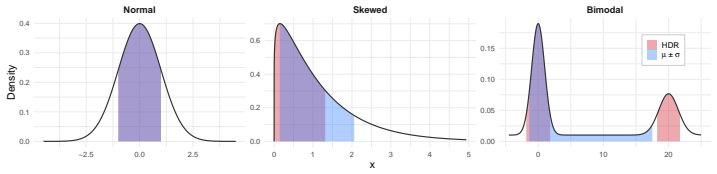
The volume of the highest-density region at robustness parameter alpha, which summarises the concentration of Lebesgue measure at the distribution's peak(s).
If this is right
- Uncertainty measures become invariant under location shifts of the predictive distribution.
- Uncertainty increases monotonically as the distribution spreads.
- Separate epistemic and aleatoric measures can be extracted that both meet the stated axioms.
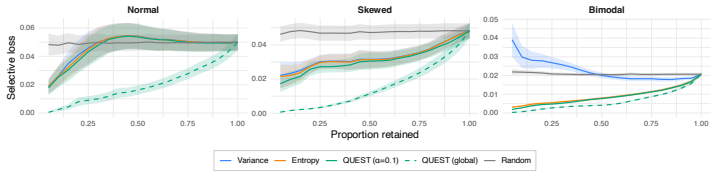
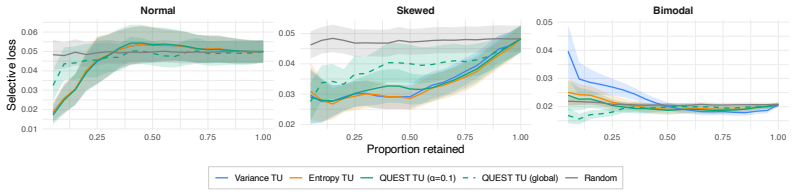
- Selective prediction decisions can be based on HDR volume rather than variance or entropy.
Where Pith is reading between the lines
- The approach could be tested on target statistics other than the mean, such as quantiles or modes.
- The links to economic statistics might allow direct transfer of inequality indices to UQ tasks.
- In safety-critical pipelines, HDR volume could replace variance as the default uncertainty input to downstream decision rules.
Load-bearing premise
The volume of the highest-density region at parameter alpha is a faithful scalar summary of uncertainty even when the target statistic is not the conditional expectation.
What would settle it
A family of distributions in which increasing spread decreases the HDR volume at the chosen alpha, or a selective prediction benchmark in which QUEST underperforms variance.
Figures

read the original abstract
Uncertainty quantification (UQ) is essential for reliable decision-making in safety-critical applications in probabilistic machine learning. For regression problems, dominant scalar UQ approaches - notably, those based on proper scoring rules - measure uncertainty via pointwise predictive risk. This can lead to counterintuitive results when the target statistic is not the conditional expectation. We propose an alternative framework, in which uncertainty is characterised by the volume of the most probable subset of a distribution's support. QUEST (Quantifying Uncertainty via highest dEnSiTy regions) is a novel approach to UQ based on the concentration of Lebesgue measure at a distribution's peak(s), evaluated at one or more values of a robustness parameter $\alpha$. We establish connections between our measures and classical statistics from information theory and economics. We show that, unlike popular alternatives based on proper scoring rules, QUEST measures of epistemic and aleatoric uncertainty satisfy a set of axioms adapted from the UQ literature, including monotonicity under distributional spread and invariance to location shifts. Selective prediction benchmarks confirm that QUEST performs favourably against standard measures such as variance and differential entropy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QUEST (Quantifying Uncertainty via highest dEnSiTy regions), a framework for scalar uncertainty quantification in regression that defines epistemic and aleatoric measures via the Lebesgue volume of the highest-density region of a predictive distribution at one or more values of a robustness parameter α. It claims connections to information-theoretic and economic statistics, shows that the resulting measures satisfy a set of adapted UQ axioms (including monotonicity under distributional spread and invariance to location shifts) while avoiding pathologies of proper-scoring-rule approaches when the target is not the conditional expectation, and reports favorable selective-prediction benchmark results against variance and differential entropy.
Significance. If the axiomatic derivations and benchmark comparisons hold, the work supplies a concrete, axiomatically grounded alternative to variance and entropy that remains well-behaved for non-mean targets. The explicit separation of epistemic and aleatoric variants and the location-shift invariance property are potentially useful for safety-critical applications. No machine-checked proofs or fully parameter-free derivations are present, but the benchmark setup is reproducible in principle.
major comments (3)
- [§3] §3 (Definition of QUEST measures): The central claim that Lebesgue volume of the HDR is the canonical functional for both epistemic and aleatoric uncertainty is introduced by contrast with proper scoring rules rather than derived from the listed axioms themselves. No argument is given showing why volume (as opposed to, e.g., differential entropy, inter-quantile range, or another concentration measure) is the unique or preferred summary that satisfies the axioms while remaining faithful when the target statistic differs from the conditional expectation.
- [§4] §4 (Axiom verification): The paper states that the epistemic and aleatoric QUEST variants satisfy monotonicity under spread and location-shift invariance, but supplies no explicit proof steps or counter-example checks for the specific functional form chosen. Without these derivations it is impossible to confirm that the properties follow from the HDR volume construction rather than from auxiliary assumptions on the predictive distributions.
- [§5] §5 (Selective prediction benchmarks): The reported favorable performance lacks error bars, dataset sizes, and hyper-parameter details for the competing methods. This makes it impossible to assess whether the observed advantage over variance and differential entropy is statistically reliable or sensitive to the choice of α.
minor comments (2)
- [Abstract / §2] Notation for the robustness parameter α is introduced without an explicit range or default value in the abstract and early sections; a short clarifying sentence would help readers.
- [§3] The abstract claims “connections to classical statistics from information theory and economics” but the main text does not cite the specific classical results being referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive report and the recommendation for major revision. We address each major comment below. Where the manuscript is incomplete or lacks detail, we agree to revise; where the comment concerns interpretive framing, we provide clarification while preserving the original technical claims.
read point-by-point responses
-
Referee: [§3] §3 (Definition of QUEST measures): The central claim that Lebesgue volume of the HDR is the canonical functional for both epistemic and aleatoric uncertainty is introduced by contrast with proper scoring rules rather than derived from the listed axioms themselves. No argument is given showing why volume (as opposed to, e.g., differential entropy, inter-quantile range, or another concentration measure) is the unique or preferred summary that satisfies the axioms while remaining faithful when the target statistic differs from the conditional expectation.
Authors: We do not claim that HDR volume is the unique functional satisfying the axioms; the manuscript presents it as a concrete choice that satisfies them while also possessing location-shift invariance and a direct interpretation as the smallest set containing probability mass 1-α. The motivation is drawn from the statistical literature on highest-density regions (e.g., Hyndman 1996) and from the desire to remain well-behaved when the target is not the conditional mean. We agree that §3 would benefit from an explicit paragraph contrasting volume with inter-quantile range and differential entropy on the listed axioms and on faithfulness for non-mean targets. We will add this comparison and a short justification based on the minimality property of HDRs. revision: partial
-
Referee: [§4] §4 (Axiom verification): The paper states that the epistemic and aleatoric QUEST variants satisfy monotonicity under spread and location-shift invariance, but supplies no explicit proof steps or counter-example checks for the specific functional form chosen. Without these derivations it is impossible to confirm that the properties follow from the HDR volume construction rather than from auxiliary assumptions on the predictive distributions.
Authors: The referee is correct that explicit derivations are missing. The properties follow from the definition of the HDR volume (the Lebesgue measure of the smallest set with probability 1-α) together with the monotonicity of Lebesgue measure under set inclusion and the translation invariance of Lebesgue measure. In the revision we will insert short proof sketches for both monotonicity under spread and location-shift invariance, together with a brief note that the same arguments hold for both the epistemic and aleatoric variants. revision: yes
-
Referee: [§5] §5 (Selective prediction benchmarks): The reported favorable performance lacks error bars, dataset sizes, and hyper-parameter details for the competing methods. This makes it impossible to assess whether the observed advantage over variance and differential entropy is statistically reliable or sensitive to the choice of α.
Authors: We agree that the experimental section is under-specified. In the revised manuscript and supplementary material we will report: (i) dataset sizes and train/test splits, (ii) standard deviations over five random seeds for all methods, (iii) the exact hyper-parameter grids used for variance, differential entropy, and QUEST (including the discrete set of α values tested), and (iv) a sensitivity plot of selective-prediction AUC versus α. These additions will allow readers to judge statistical reliability and robustness to α. revision: yes
Circularity Check
QUEST volume-based measures derived from HDR definition and verified against adapted axioms without reduction to inputs
full rationale
The paper defines QUEST explicitly as the Lebesgue volume of the highest-density region(s) at robustness level α, then separately establishes links to information theory/economics and verifies satisfaction of the listed UQ axioms (monotonicity under spread, location-shift invariance) directly from that construction. No equations reduce the claimed properties to a fitted parameter, self-citation chain, or renamed input; the central contrast with proper scoring rules is presented as motivation rather than a load-bearing derivation step. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- robustness parameter alpha
axioms (2)
- domain assumption Monotonicity under distributional spread
- domain assumption Invariance to location shifts
invented entities (1)
-
QUEST measure (epistemic and aleatoric variants)
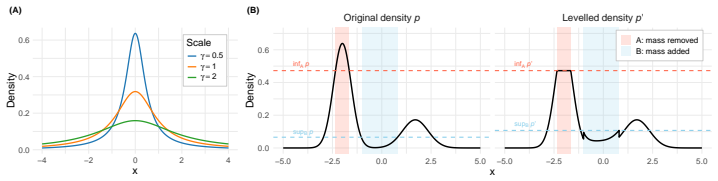
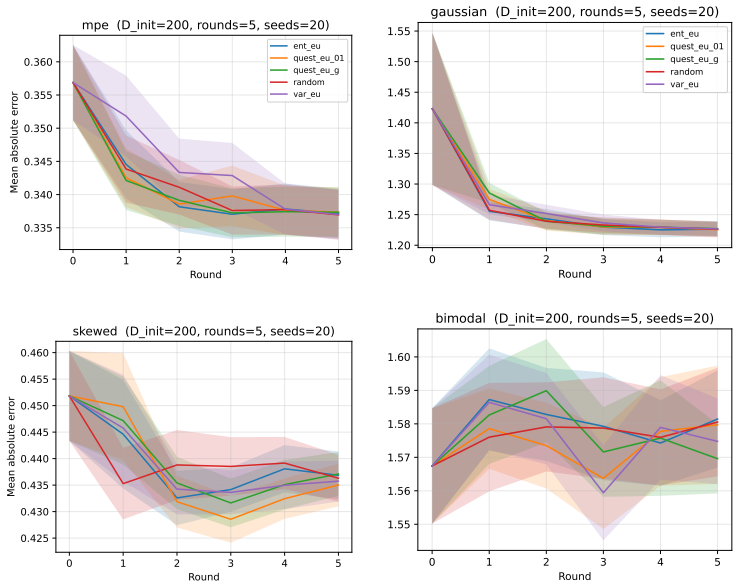
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deep Eviden- tial Regression
Alexander Amini, Wilko Schwarting, Ava Soleimany, and Daniela Rus. Deep Eviden- tial Regression. InAdvances in Neural Information Processing Systems, volume 33, pages 14927–14937, 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/hash/ aab085461de182608ee9f607f3f7d18f-Abstract.html
2020
-
[2]
Epistemic Uncertainty Estimation in Regression Ensemble Models with Pairwise Epistemic Estimators.Advances in Neural Information Processing Systems, 38:64503– 64536, April 2026
Lucas Berry and David Meger. Epistemic Uncertainty Estimation in Regression Ensemble Models with Pairwise Epistemic Estimators.Advances in Neural Information Processing Systems, 38:64503– 64536, April 2026. URL https://proceedings.neurips.cc/paper_files/paper/2025/hash/ 5d45a97ec44d8232bf718e92aab99a47-Abstract-Conference.html
2026
-
[3]
Lawrence D. Brown, George Casella, and J. T. Gene Hwang. Optimal Confidence Sets, Bioequi- valence, and the Limaçon of Pascal.Journal of the American Statistical Association, 90(431): 880–889, September 1995. ISSN 0162-1459. doi: 10.1080/01621459.1995.10476587. URL https://doi.org/10.1080/01621459.1995.10476587. Publisher: ASA Website _eprint: ht- tps://d...
-
[4]
Uncertainty Quantification for Regression: A Unified Framework based on kernel scores, October 2025
Christopher Bülte, Yusuf Sale, Gitta Kutyniok, and Eyke Hüllermeier. Uncertainty Quantification for Regression: A Unified Framework based on kernel scores, October 2025. URL http://arxiv.org/ abs/2510.25599. arXiv:2510.25599 [cs]
arXiv 2025
-
[5]
An Axiomatic Assessment of Entropy- and Variance-based Uncertainty Quantification in Regression, May
Christopher Bülte, Yusuf Sale, Timo Löhr, Paul Hofman, Gitta Kutyniok, and Eyke Hüllermeier. An Axiomatic Assessment of Entropy- and Variance-based Uncertainty Quantification in Regression, May
- [6]
-
[7]
Conformalized Credal Regions for Classifica- tion with Ambiguous Ground Truth.Transactions on Machine Learning Research, November 2024
Michele Caprio, David Stutz, Shuo Li, and Arnaud Doucet. Conformalized Credal Regions for Classifica- tion with Ambiguous Ground Truth.Transactions on Machine Learning Research, November 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=L7sQ8CW2FY. 4www.safeandtrustedai.org. 10
2024
-
[8]
Conformal prediction regions are imprecise highest density regions
Michele Caprio, Yusuf Sale, and Eyke Hüllermeier. Conformal prediction regions are imprecise highest density regions. InProceedings of the Fourteenth International Symposium on Imprecise Probabilities: Theories and Applications, pages 47–59. PMLR, May 2025. URL https://proceedings.mlr.press/ v290/caprio25b.html
2025
-
[9]
Disentangling Epistemic and Aleatoric Uncertainty in Reinforcement Learning
Harrison Charpentier, Ransalu Senanayake, Mykel Kochenderfer, and Stephan Günnemann. Disentangling Epistemic and Aleatoric Uncertainty in Reinforcement Learning. InICML 2022 Workshop on Distribution- Free Uncertainty Quantification, 2022. URLhttp://arxiv.org/abs/2206.01558
arXiv 2022
-
[10]
Cover and Joy A
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. John Wiley & Sons, Hoboken, NJ, second edition, 2006
2006
-
[11]
Cowell.Measuring Inequality
Frank A. Cowell.Measuring Inequality. Oxford University Press, Oxford, third edition, 2011
2011
-
[12]
Yunlong Feng, Xiaolin Huang, Lei Shi, Yuning Yang, and Johan A.K. Suykens. Learning with the maximum correntropy criterion induced losses for regression.Journal of Machine Learning Research, 16 (30):993–1034, 2015
2015
-
[13]
Uncertainty Quantification for Regression using Proper Scoring Rules, September 2025
Alexander Fishkov, Kajetan Schweighofer, Mykyta Ielanskyi, Nikita Kotelevskii, Mohsen Guizani, and Maxim Panov. Uncertainty Quantification for Regression using Proper Scoring Rules, September 2025. URLhttp://arxiv.org/abs/2509.26610. arXiv:2509.26610 [cs]
arXiv 2025
-
[14]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of The 33rd International Conference on Machine Learning, pages 1050–1059, 2016
2016
-
[15]
On the Relation Among Shortest Confidence Intervals of Different Types
Jayanta Kumar Ghosh. On the Relation Among Shortest Confidence Intervals of Different Types. Calcutta Statistical Association Bulletin, 10(4):147–152, September 1961. ISSN 0008-0683, 2456-
1961
-
[16]
URL https://journals.sagepub.com/doi/10.1177/ 0008068319610404
doi: 10.1177/0008068319610404. URL https://journals.sagepub.com/doi/10.1177/ 0008068319610404
-
[17]
Journal of the American Statistical Association 102, 359–378
Tilmann Gneiting and Adrian E Raftery. Strictly Proper Scoring Rules, Prediction, and Estimation. Journal of the American Statistical Association, 102(477):359–378, March 2007. ISSN 0162-1459, 1537- 274X. doi: 10.1198/016214506000001437. URL http://www.tandfonline.com/doi/abs/10.1198/ 016214506000001437
-
[18]
Quantification of Credal Uncertainty: A Distance-Based Approach, March 2026
Xabier Gonzalez-Garcia, Siu Lun Chau, Julian Rodemann, Michele Caprio, Krikamol Muandet, Humberto Bustince, Sébastien Destercke, Eyke Hüllermeier, and Yusuf Sale. Quantification of Credal Uncertainty: A Distance-Based Approach, March 2026. URLhttp://arxiv.org/abs/2603.27270. arXiv:2603.27270 [cs]
arXiv 2026
-
[19]
Misgina Tsighe Hagos and Claes Lundstrom. Performance of Conformal Prediction in Capturing Aleatoric Uncertainty. In2026 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2954–2963, Los Alamitos, CA, USA, March 2026. IEEE Computer Society. doi: 10.1109/W ACV61042. 2026.00289. URLhttps://doi.ieeecomputersociety.org/10.1109/WACV610...
work page doi:10.1109/w 2026
-
[20]
Charles R. Harris, K. Jarrod Millman, Stéfan J. van der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J. Smith, Robert Kern, Matti Picus, Stephan Hoyer, Marten H. van Kerkwijk, Matthew Brett, Allan Haldane, Jaime Fernández del Río, Mark Wiebe, Pearu Peterson, Pierre Gérard-Marchant, Kevin Shepp...
-
[21]
Heinrich
C. Heinrich. The mode functional is not elicitable.Biometrika, 101(1):245–251, 2014
2014
-
[22]
Quantifying Aleatoric and Epistemic Uncertainty: A Credal Approach
Paul Hofman, Yusuf Sale, and Eyke Hüllermeier. Quantifying Aleatoric and Epistemic Uncertainty: A Credal Approach. InICML 2024 Workshop on Structured Probabilistic Inference & Generative Modeling, July 2024. URLhttps://openreview.net/forum?id=MhLnSoWp3p
2024
-
[23]
Bayesian Active Learning for Classification and Preference Learning, December 2011
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian Active Learning for Classification and Preference Learning, December 2011. URL http://arxiv.org/abs/1112.5745. arXiv:1112.5745 [cs, stat]
Pith/arXiv arXiv 2011
-
[24]
Wiley & Sons, New York, Second edition, 2009
Peter Huber and Elvezio Ronchetti.Robust Statistics. Wiley & Sons, New York, Second edition, 2009
2009
-
[25]
J. D. Hunter. Matplotlib: A 2d graphics environment.Computing in Science & Engineering, 9(3):90–95,
-
[26]
doi: 10.1109/MCSE.2007.55. 11
-
[27]
Rob J. Hyndman. Computing and Graphing Highest Density Regions.The American Statistician, 50(2):120– 126, 1996. ISSN 0003-1305. doi: 10.2307/2684423. URL https://www.jstor.org/stable/2684423. Publisher: [American Statistical Association, Taylor & Francis, Ltd.]
-
[28]
Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods.Machine Learning, 110(3):457–506, 2021
Eyke Hüllermeier and Willem Waegeman. Aleatoric and epistemic uncertainty in machine learning: an introduction to concepts and methods.Machine Learning, 110(3):457–506, 2021
2021
-
[29]
Jacobs, Michael I
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3(1):79–87, 1991
1991
-
[30]
Conformalized Credal Set Predictors.Ad- vances in Neural Information Processing Systems, 37:116987–117014, December 2024
Alireza Javanmardi, David Stutz, and Eyke Hüllermeier. Conformalized Credal Set Predictors.Ad- vances in Neural Information Processing Systems, 37:116987–117014, December 2024. doi: 10. 52202/079017-3714. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ d42a8bf2f40555d4a5120300f98c88f6-Abstract-Conference.html
2024
-
[31]
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?, October 2017
Alex Kendall and Yarin Gal. What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?, October 2017. URLhttp://arxiv.org/abs/1703.04977. arXiv:1703.04977 [cs]
Pith/arXiv arXiv 2017
-
[32]
Advances in neural information processing systems, 35:28458–28473
King’s College London. King’s Computational Research, Engineering and Technology Environment (CREATE), 2022. URLhttps://doi.org/10.18742/rnvf-m076. Retrieved March 2, 2022
-
[33]
From Risk to Uncertainty: Generating Predictive Uncertainty Measures via Bayesian Es- timation.International Conference on Learning Representations, 2025:92468–92504, May 2025
Nikita Kotelevskii, Vladimir Kondratyev, Martin Taká ˇc, Eric Moulines, and Maxim Panov. From Risk to Uncertainty: Generating Predictive Uncertainty Measures via Bayesian Es- timation.International Conference on Learning Representations, 2025:92468–92504, May 2025. URL https://proceedings.iclr.cc/paper_files/paper/2025/hash/ e6f32e64b9c27d153b46c94f0fe22b...
2025
-
[34]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://proceedings.neurips.cc/paper_files/ paper/2017/hash/9ef2ed4b7fd2c810847ffa5fa85bce38-Abstract.html
2017
-
[35]
Lehmann and Joseph P
E.L. Lehmann and Joseph P. Romano.Testing Statistical Hypotheses. Springer, New York, Third edition, 2005
2005
-
[36]
Regression Prior Networks, December 2020
Andrey Malinin, Sergey Chervontsev, Ivan Provilkov, and Mark Gales. Regression Prior Networks, December 2020. URLhttp://arxiv.org/abs/2006.11590. arXiv:2006.11590 [cs]
arXiv 2020
-
[37]
Marshall, Ingram Olkin, and Barry C
Albert W. Marshall, Ingram Olkin, and Barry C. Arnold.Inequalities: Theory of Majorization and Its Applications. Springer Series in Statistics. Springer, New York, second edition, 2011
2011
-
[38]
Multivariate Deep Evidential Regression, February 2022
Nis Meinert and Alexander Lavin. Multivariate Deep Evidential Regression, February 2022. URL http://arxiv.org/abs/2104.06135. arXiv:2104.06135 [cs]
arXiv 2022
-
[39]
Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
2015
-
[40]
Murphy.Probabilistic Machine Learning: An introduction
Kevin P. Murphy.Probabilistic Machine Learning: An introduction. The MIT Press, Cambridge, 2022
2022
-
[41]
Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshmin- arayanan. Normalizing flows for probabilistic modeling and inference.Journal of Machine Learning Research, 22(57):1–64, 2021
2021
-
[42]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Z. Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-perfo...
Pith/arXiv arXiv 1912
-
[43]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[44]
Cambridge University Press, 2025
Yury Polyanskiy and Yihong Wu.Information Theory: From Coding to Learning. Cambridge University Press, 2025
2025
-
[45]
John W. Pratt. Shorter Confidence Intervals for the Mean of a Normal Distribution with Known Variance. The Annals of Mathematical Statistics, 34(2):574–586, 1963. ISSN 0003-4851. URL https://www. jstor.org/stable/2238404. 12
arXiv 1963
-
[46]
Is the volume of a credal set a good measure for epistemic uncertainty? InProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, pages 1795–1804
Yusuf Sale, Michele Caprio, and Eyke Höllermeier. Is the volume of a credal set a good measure for epistemic uncertainty? InProceedings of the Thirty-Ninth Conference on Uncertainty in Artificial Intelligence, pages 1795–1804. PMLR, July 2023. URL https://proceedings.mlr.press/v216/ sale23a.html
2023
-
[47]
Second-order uncertainty quantification: A distance-based approach
Yusuf Sale, Viktor Bengs, Michele Caprio, and Eyke Hüllermeier. Second-order uncertainty quantification: A distance-based approach. InForty-first International Conference on Machine Learning, 2024
2024
-
[48]
Aleatoric and Epistemic Uncertainty in Conformal Prediction
Yusuf Sale, Alireza Javanmardi, and Eyke Hüllermeier. Aleatoric and Epistemic Uncertainty in Conformal Prediction. InProceedings of the Fourteenth Symposium on Conformal and Probabilistic Prediction with Applications, pages 784–786. PMLR, August 2025. URL https://proceedings.mlr.press/v266/ sale25a.html
2025
-
[49]
Introducing an Im- proved Information-Theoretic Measure of Predictive Uncertainty
Kajetan Schweighofer, Lukas Aichberger, Mykyta Ielanskyi, and Sepp Hochreiter. Introducing an Im- proved Information-Theoretic Measure of Predictive Uncertainty. InNeurIPS 2023 Workshop on Math- ematics of Modern Machine Learning, November 2023. URL https://openreview.net/forum?id= c71B6zW70d
2023
-
[50]
On information- theoretic measures of predictive uncertainty
Kajetan Schweighofer, Lukas Aichberger, Mykyta Ielanskyi, and Sepp Hochreiter. On information- theoretic measures of predictive uncertainty. InProceedings of the Forty-First Conference on Uncertainty in Artificial Intelligence, 2025
2025
-
[51]
Clarendon Press, Oxford, 1997
Amartya Sen.On Economic Inequality. Clarendon Press, Oxford, 1997
1997
-
[52]
Sliced score matching: A scalable approach to density and score estimation
Yang Song, Sahaj Garg, Jiaxin Shi, and Stefano Ermon. Sliced score matching: A scalable approach to density and score estimation. InProceedings of The 35th Uncertainty in Artificial Intelligence Conference, pages 574–584, 2020
2020
-
[53]
Pettingzoo: Gym for multi- agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032–15043, 2021
J Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Pettingzoo: Gym for multi- agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032–15043, 2021
2021
-
[54]
Roadsaw: A large-scale dataset for camera- based road surface and wetness estimation,
Matias Valdenegro-Toro and Daniel Saromo Mori. A Deeper Look into Aleatoric and Epistemic Uncertainty Disentanglement. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1508–1516, June 2022. doi: 10.1109/CVPRW56347.2022.00157. URL https:// ieeexplore.ieee.org/abstract/document/9857056. ISSN: 2160-7516
-
[55]
Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, Matthew Brett, Joshua Wilson, K. Jarrod Millman, Nikolay Mayorov, Andrew R. J. Nelson, Eric Jones, Robert Kern, Eric Larson, C J Carey, ˙Ilhan Polat, Yu Feng, Eric W. M...
-
[56]
2005.Algorithmic Learning in a Random World
V . V ovk, A. Gammerman, and G. Shafer.Algorithmic Learning in a Random World. Springer-Verlag, New York, 2005. ISBN 978-0-387-00152-4. doi: 10.1007/b106715. URL http://link.springer.com/10. 1007/b106715
-
[57]
London ; New York : Chapman and Hall, 1991
Peter Walley.Statistical reasoning with imprecise probabilities. London ; New York : Chapman and Hall, 1991. ISBN 978-0-412-28660-5. URL http://archive.org/details/ statisticalreaso0000wall
1991
-
[58]
Manchingal, Keivan Shariatmadar, David Moens, and Hans Hallez
Kaizheng Wang, Fabio Cuzzolin, Shireen K. Manchingal, Keivan Shariatmadar, David Moens, and Hans Hallez. Credal Deep Ensembles for Uncertainty Quantification.Advances in Neural Information Processing Systems, 37:79540–79572, December 2024. doi: 10. 52202/079017-2525. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/ 911fc798523e7d4c2e9587129...
2024
-
[59]
Lisa Wimmer, Yusuf Sale, Paul Hofman, Bernd Bischl, and Eyke Hüllermeier. Quantifying aleatoric and epistemic uncertainty in machine learning: Are conditional entropy and mutual information appropriate measures? InProceedings of the 39th Conference on Uncertainty in Artificial Intelligence, pages 2282– 2292, 2023. 13 A Proofs In this section, we include p...
2023
-
[60]
Train the model onD L
-
[61]
Compute acquisition scoresa(x)onx∈ D U using a chosen uncertainty measure
-
[62]
spread” should track “distance-to-uniformity
Select the top-kpoints bya(x)and add them (with labels) toD L. Performance is tracked on a fixed test set after each acquisition round. Unless otherwise stated: initial labelled size= 200, batch sizek= 200, and number of rounds= 200, giving a final pool size|D L|= 1200. As with the selective prediction experiment we repeat each experiment 20 times, averag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.