FlowMaps: Modeling Long-Term Multimodal Object Dynamics with Flow Matching
Pith reviewed 2026-06-26 17:03 UTC · model grok-4.3
The pith
FlowMaps models future object locations in homes as continuous multimodal distributions using flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowMaps is a latent flow matching model for estimating multimodal distributions over the future locations of dynamic objects in a continuous 3D space. By learning the implicit dependencies among objects and their temporal evolution, it predicts likely changes in object locations conditioned on past human interactions while supporting generalization across previously unseen environments that share similar object routines.
What carries the argument
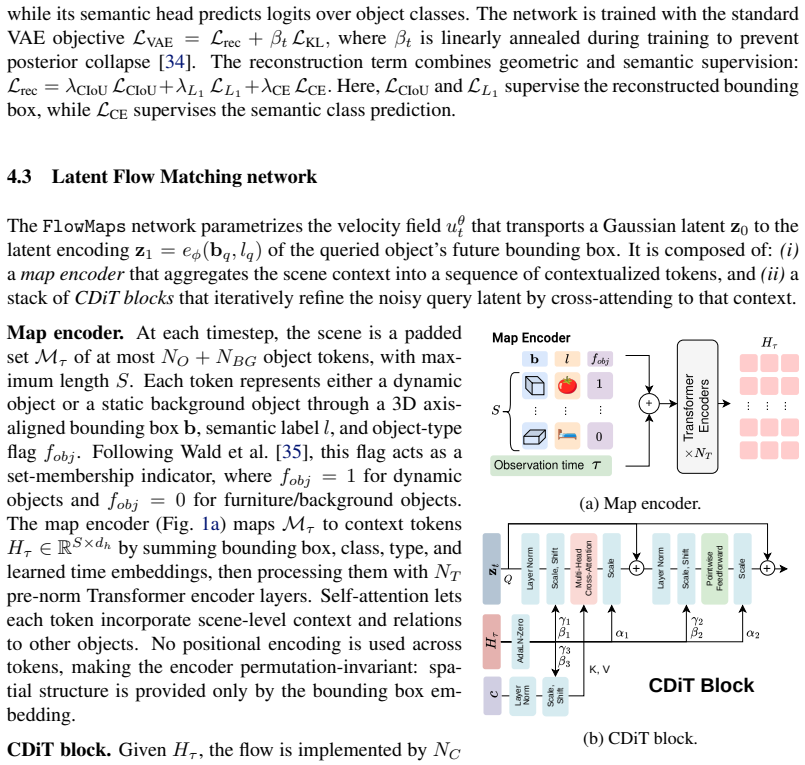
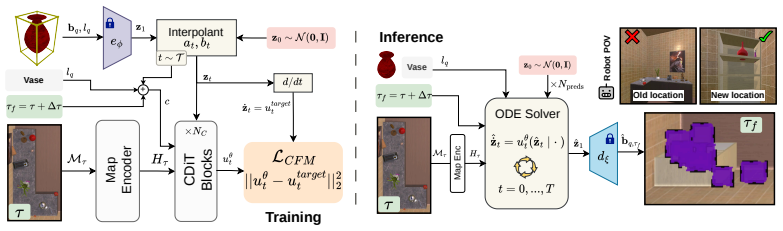
A latent flow matching model that generates continuous multimodal spatio-temporal distributions of object positions from learned object dependencies and temporal patterns.
If this is right
- Robots can use the predicted distributions to plan searches that account for multiple possible object positions rather than fixed locations.
- Conditioning on past interactions allows the model to adapt predictions to observed human behavior in a given setting.
- Generalization to unseen environments occurs when those environments follow comparable daily routines.
- Continuous modeling supports navigation tasks that require reasoning over extended time periods in changing scenes.
Where Pith is reading between the lines
- The same distribution-based forecasts could be tested for predicting object states in non-household settings such as offices or retail spaces that have their own recurring patterns.
- Integrating the flow matching outputs with short-term physics models might extend reliable predictions to longer horizons than the current training data covers.
- If the learned distributions prove robust, they could serve as priors for other perception modules that must handle uncertainty in object identity across time.
Load-bearing premise
Human habits and routines produce spatio-temporally consistent patterns in object locations that can be learned from data and that transfer to new environments with similar routines.
What would settle it
Measure whether performance gains disappear when the model is deployed in an environment whose object placement routines differ markedly from those in the training data.
Figures








read the original abstract
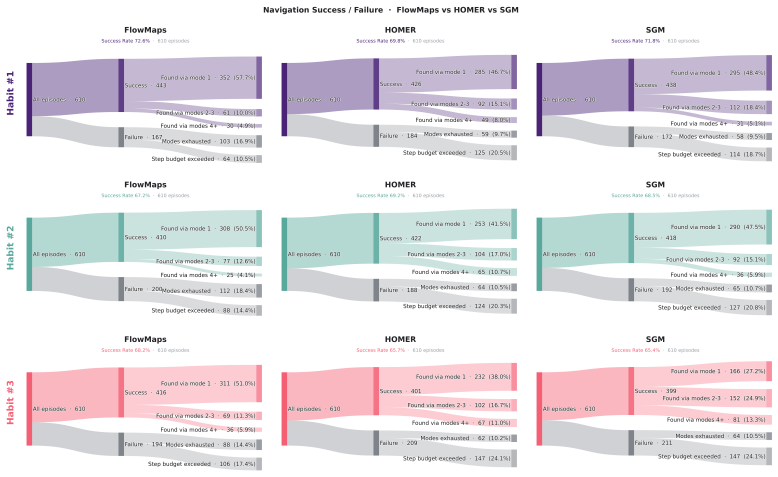
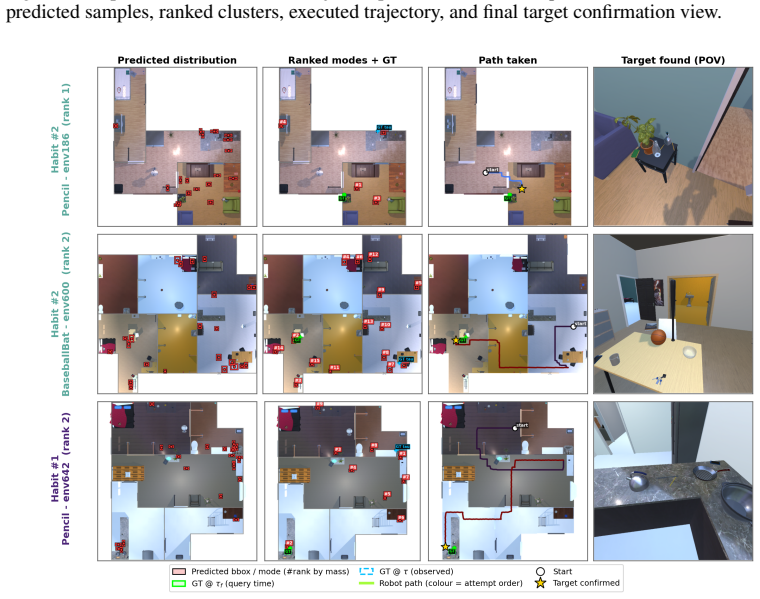
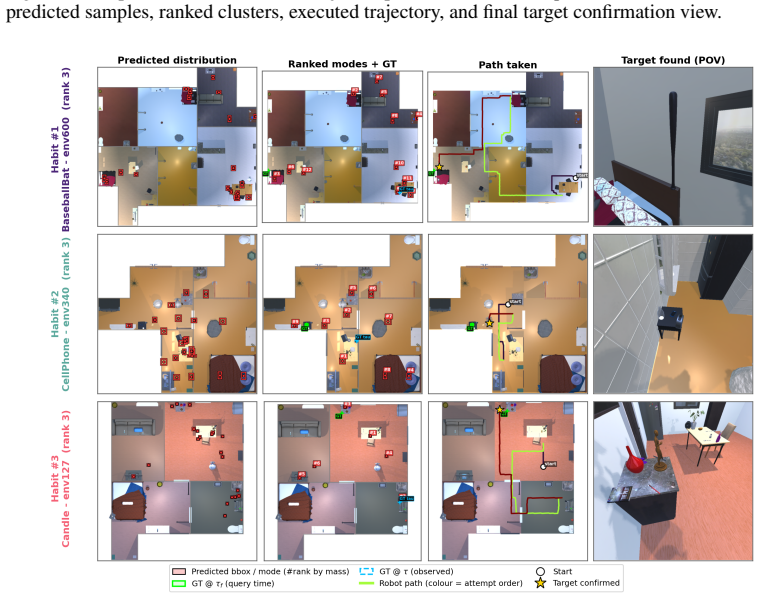
Joint spatial and temporal understanding of 3D scenes is a crucial requirement for robots deployed in everyday household environments. Such agents must not only comprehend and navigate spatial layouts, but also reason about how these spaces evolve over time. In particular, humans interact with objects daily, causing them to change position throughout the environment and making it difficult for robots to reliably associate current observations with previously seen objects. However, these interactions are not random: human habits and routines induce spatio-temporally consistent patterns in object locations, which robotic agents can potentially learn and then exploit for downstream tasks such as navigation. To this end, we introduce FlowMaps, a latent flow matching model for estimating multimodal distributions over the future locations of dynamic objects in a continuous 3D space. By learning the implicit dependencies among objects and their temporal evolution, FlowMaps predicts likely changes in object locations conditioned on past human interactions, while supporting generalization across previously unseen environments that share similar object routines. To demonstrate the utility of this method, we deploy FlowMaps in a downstream dynamic Object Navigation task in both simulated and real-world environments. Across more than 600 episodes, FlowMaps outperforms state-of-the-art approaches, showing that modeling object dynamics through continuous, multimodal spatio-temporal distributions improves robotic search and navigation in changing household environments. Code and additional material is available at https://fra-tsuna.github.io/flowmaps/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowMaps, a latent flow matching model for estimating multimodal distributions over future locations of dynamic objects in continuous 3D space. Conditioned on past human interactions, it learns implicit object dependencies and temporal evolution to predict location changes, with claimed generalization to unseen environments sharing similar routines. The method is evaluated on a downstream dynamic Object Navigation task, reporting outperformance over state-of-the-art approaches across more than 600 episodes in simulated and real-world household settings. Code is made available.
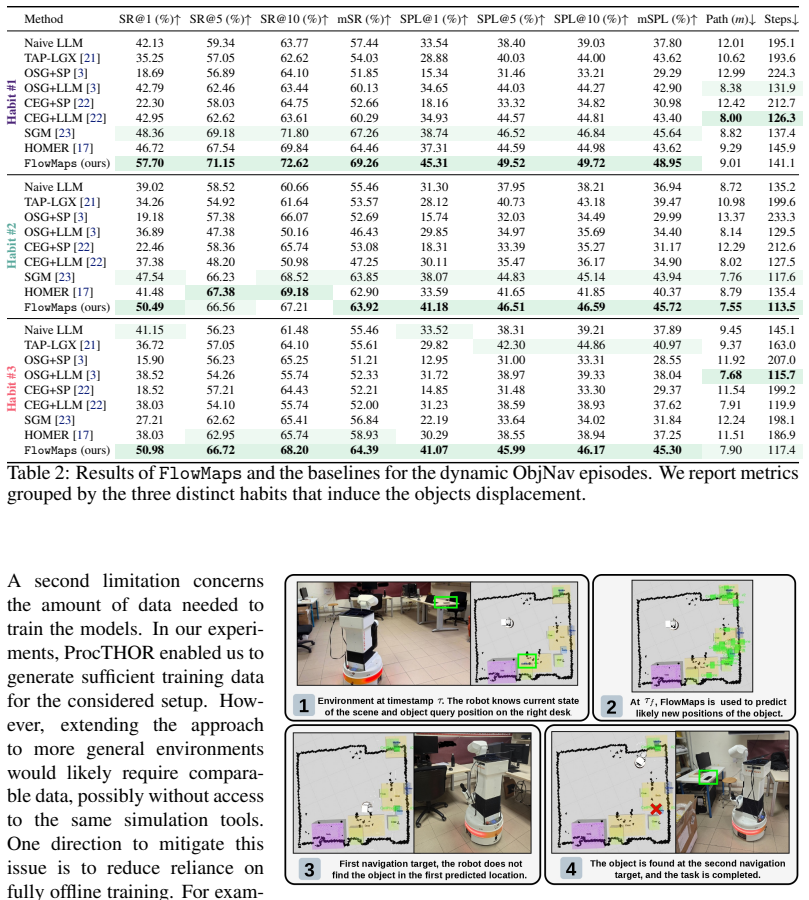
Significance. If the empirical results and modeling approach hold under scrutiny, the work offers a continuous multimodal formulation for long-term spatio-temporal object dynamics via flow matching, which could improve robotic navigation in dynamic household scenes. The scale of the evaluation (>600 episodes, sim+real) and public code release are strengths that support reproducibility and allow direct assessment of the generalization premise based on human routine patterns.
minor comments (2)
- [Abstract] Abstract: the outperformance claim would be strengthened by including at least one quantitative metric (e.g., success rate delta or SPL) rather than the qualitative statement alone.
- [Abstract] The generalization claim in the abstract rests on the premise that environments share similar routines; a brief discussion of how this is operationalized (e.g., via conditioning features) would clarify the scope.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work, recognition of the evaluation scale (>600 episodes across sim and real), and recommendation for minor revision. We appreciate the acknowledgment of the public code release supporting reproducibility.
Circularity Check
No significant circularity; model is data-driven with external validation
full rationale
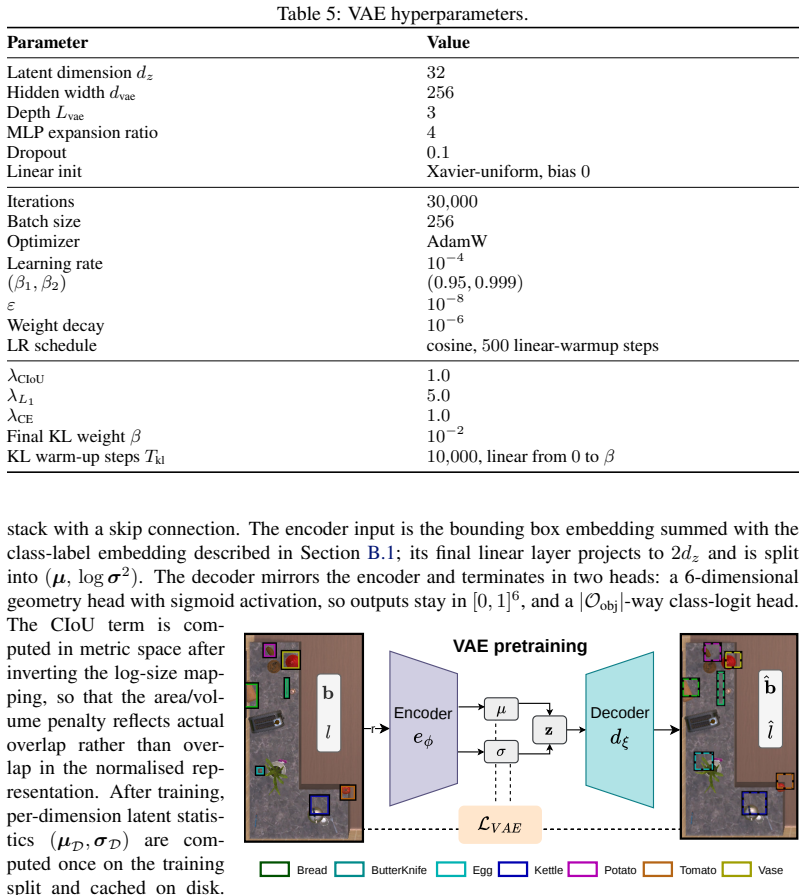
The paper introduces a latent flow-matching model trained on observed human-object interaction data to predict multimodal spatio-temporal distributions. No equations, derivations, or self-citations are presented in the provided text that reduce predictions to inputs by construction. Performance claims rest on empirical results across >600 episodes in simulated and real environments, not on fitted parameters renamed as predictions or self-referential assumptions. The core premise (human routines induce learnable patterns) is an external modeling assumption, not a tautology internal to any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mois and J
G. Mois and J. M. Beer. The role of healthcare robotics in providing support to older adults: a socio-ecological perspective.Current Geriatrics Reports, 9(2):82–89, 2020
2020
-
[2]
R. J. L ´opez-Sastre, M. Baptista-R ´ıos, F. J. Acevedo-Rodr ´ıguez, S. Pacheco-da Costa, S. Maldonado-Basc ´on, and S. Lafuente-Arroyo. A low-cost assistive robot for children with neurodevelopmental disorders to aid in daily living activities.International Journal of Envi- ronmental Research and Public Health, 18(8):3974, 2021
2021
-
[3]
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions,
S. Rudra, S. Goel, A. Santara, C. Gentile, L. Perron, F. Xia, V . Sindhwani, C. Parada, and G. Aggarwal. A contextual bandit approach for learning to plan in environments with proba- bilistic goal configurations. In2023 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 5645–5652, 2023. doi:10.1109/ICRA48891.2023.10160473
-
[4]
N. F. Troje. Retrieving information from human movement patterns.Understanding events: From perception to action, 4:308–334, 2008
2008
-
[5]
Schmid, J
L. Schmid, J. Delmerico, J. L. Sch¨onberger, J. Nieto, M. Pollefeys, R. Siegwart, and C. Cadena. Panoptic multi-tsdfs: a flexible representation for online multi-resolution volumetric mapping and long-term dynamic scene consistency. In2022 International Conference on Robotics and Automation (ICRA), pages 8018–8024. IEEE, 2022
2022
- [6]
-
[7]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[8]
Deitke, E
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, J. Salvador, K. Ehsani, W. Han, E. Kolve, A. Farhadi, A. Kembhavi, and R. Mottaghi. ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. InNeurIPS, 2022. Outstanding Paper Award
2022
-
[9]
Li and M
K. Li and M. Q.-H. Meng. Personalizing a service robot by learning human habits from be- havioral footprints.Engineering, 1(1):079–084, 2015
2015
-
[10]
Irfan, A
B. Irfan, A. Ramachandran, S. Spaulding, D. F. Glas, I. Leite, and K. L. Koay. Personalization in long-term human-robot interaction. In2019 14th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 685–686. IEEE, 2019
2019
-
[11]
J. Sung, C. Ponce, B. Selman, and A. Saxena. Unstructured human activity detection from rgbd images. In2012 IEEE international conference on robotics and automation, pages 842–849. IEEE, 2012
2012
-
[12]
H. S. Koppula and A. Saxena. Anticipating human activities using object affordances for reactive robotic response.IEEE transactions on pattern analysis and machine intelligence, 38 (1):14–29, 2015
2015
-
[13]
Baraglia, M
J. Baraglia, M. Cakmak, Y . Nagai, R. P. Rao, and M. Asada. Efficient human-robot collabora- tion: when should a robot take initiative?The International Journal of Robotics Research, 36 (5-7):563–579, 2017
2017
-
[14]
Hoffman and C
G. Hoffman and C. Breazeal. Effects of anticipatory action on human-robot teamwork ef- ficiency, fluency, and perception of team. InProceedings of the ACM/IEEE international conference on Human-robot interaction, pages 1–8, 2007
2007
-
[15]
Buyukgoz, J
S. Buyukgoz, J. Grosinger, M. Chetouani, and A. Saffiotti. Two ways to make your robot proactive: Reasoning about human intentions or reasoning about possible futures.Frontiers in Robotics and AI, 9:929267, 2022. 26
2022
-
[16]
M. K. van Den Broek and T. B. Moeslund. What is proactive human-robot interaction?-a re- view of a progressive field and its definitions.ACM Transactions on Human-Robot Interaction, 13(4):1–30, 2024
2024
-
[17]
Patel and S
M. Patel and S. Chernova. Proactive robot assistance via spatio-temporal object modeling. In K. Liu, D. Kulic, and J. Ichnowski, editors,Proceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 881–891. PMLR, 14–18 Dec 2023. URLhttps://proceedings.mlr.press/v205/patel23a.html
2023
-
[18]
cat-shaped mug
V . S. Dorbala, J. F. Mullen, and D. Manocha. Can an embodied agent find your “cat-shaped mug”? llm-based zero-shot object navigation.IEEE Robotics and Automation Letters, 9(5): 4083–4090, 2023
2023
-
[19]
Rajvanshi, K
A. Rajvanshi, K. Sikka, X. Lin, B. Lee, H.-P. Chiu, and A. Velasquez. Saynav: Grounding large language models for dynamic planning to navigation in new environments. InProceedings of the International Conference on Automated Planning and Scheduling, volume 34, pages 464– 474, 2024
2024
-
[20]
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In2017 IEEE interna- tional conference on robotics and automation (ICRA), pages 3357–3364. ieee, 2017
2017
-
[21]
V . S. Dorbala, B. Patel, A. S. Bedi, and D. Manocha. Personalized embodied navigation for portable object finding, 2026. URLhttps://arxiv.org/abs/2403.09905
Pith/arXiv arXiv 2026
-
[22]
C. Wang, X. Li, D. Wang, H. Liu, et al. Dynamic scene generation for embodied navigation benchmark. InRSS 2024 Workshop: Data Generation for Robotics, 2024
2024
-
[23]
Kurenkov, M
A. Kurenkov, M. Lingelbach, T. Agarwal, E. Jin, C. Li, R. Zhang, L. Fei-Fei, J. Wu, S. Savarese, and R. Martın-Martın. Modeling dynamic environments with scene graph mem- ory. InInternational Conference on Machine Learning, pages 17976–17993. PMLR, 2023
2023
-
[24]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[25]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
2024
-
[26]
Z. Hou, T. Zhang, Y . Xiong, H. Pu, C. Zhao, R. Tong, Y . Qiao, J. Dai, and Y . Chen. Diffusion transformer policy.arXiv preprint arXiv:2410.15959, 2024
arXiv 2024
-
[27]
Chisari, N
E. Chisari, N. Heppert, M. Argus, T. Welschehold, T. Brox, and A. Valada. Learning robotic manipulation policies from point clouds with conditional flow matching. InConference on Robot Learning, 2025
2025
-
[28]
F. Zhang and M. Gienger. Affordance-based robot manipulation with flow matching.arXiv preprint arXiv:2409.01083, 2024
arXiv 2024
-
[29]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. pi0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[30]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning, pages 2679–2713. PMLR, 2025. 27
2025
-
[31]
Y . Lipman, M. Havasi, P. Holderrieth, N. Shaul, M. Le, B. Karrer, R. T. Q. Chen, D. Lopez- Paz, H. Ben-Hamu, and I. Gat. Flow matching guide and code, 2024. URLhttps://arxiv. org/abs/2412.06264
Pith/arXiv arXiv 2024
-
[32]
Holderrieth and E
P. Holderrieth and E. Erives. Introduction to flow matching and diffusion models, 2026. URL https://diffusion.csail.mit.edu/
2026
-
[33]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation world models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15791–15801, 2025
2025
-
[34]
Bowman, L
S. Bowman, L. Vilnis, O. Vinyals, A. Dai, R. Jozefowicz, and S. Bengio. Generating sentences from a continuous space. InProceedings of the 20th SIGNLL conference on computational natural language learning, pages 10–21, 2016
2016
-
[35]
J. Wald, H. Dhamo, N. Navab, and F. Tombari. Learning 3d semantic scene graphs from 3d indoor reconstructions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3961–3970, 2020
2020
-
[36]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[37]
A. Tong, K. FATRAS, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio. Improving and generalizing flow-based generative models with minibatch opti- mal transport.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URL https://openreview.net/forum?id=CD9Snc73AW. Expert Certification
2024
-
[38]
Pooladian, H
A.-A. Pooladian, H. Ben-Hamu, C. Domingo-Enrich, B. Amos, Y . Lipman, and R. T. Q. Chen. Multisample flow matching: Straightening flows with minibatch couplings. In A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, editors,Pro- ceedings of the 40th International Conference on Machine Learning, volume 202 ofPro- ceedings of Machin...
2023
-
[39]
Gupta, J
A. Gupta, J. Johnson, L. Fei-Fei, S. Savarese, and A. Alahi. Social gan: Socially acceptable trajectories with generative adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2255–2264, 2018
2018
-
[40]
M. F. Naeem, S. J. Oh, Y . Uh, Y . Choi, and J. Yoo. Reliable fidelity and diversity metrics for generative models. In H. D. III and A. Singh, editors,Proceedings of the 37th Interna- tional Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 7176–7185. PMLR, 13–18 Jul 2020. URLhttps://proceedings.mlr. press/v119/n...
2020
-
[41]
Kolve, R
E. Kolve, R. Mottaghi, W. Han, E. VanderBilt, L. Weihs, A. Herrasti, D. Gordon, Y . Zhu, A. Gupta, and A. Farhadi. AI2-THOR: An Interactive 3D Environment for Visual AI.arXiv, 2017
2017
-
[42]
Ester, H.-P
M. Ester, H.-P. Kriegel, J. Sander, and X. Xu. A density-based algorithm for discovering clusters in large spatial databases with noise. InProceedings of the Second International Conference on Knowledge Discovery and Data Mining, KDD’96, page 226–231. AAAI Press, 1996
1996
-
[43]
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Ma- lik, R. Mottaghi, M. Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018. 28
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.