Finetuning Vision-Language-Action Models Requires Fewer Layers Than You Think
Pith reviewed 2026-06-26 16:57 UTC · model grok-4.3
The pith
Vision-language-action models contain enough layer redundancy to allow permanent 50% depth compression while preserving or improving fine-tuning performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
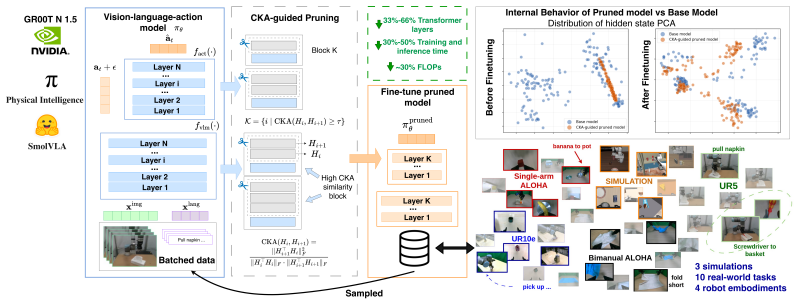
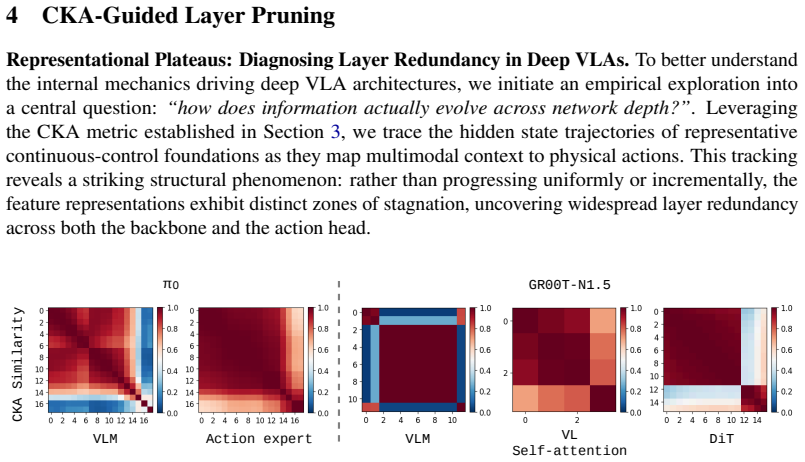
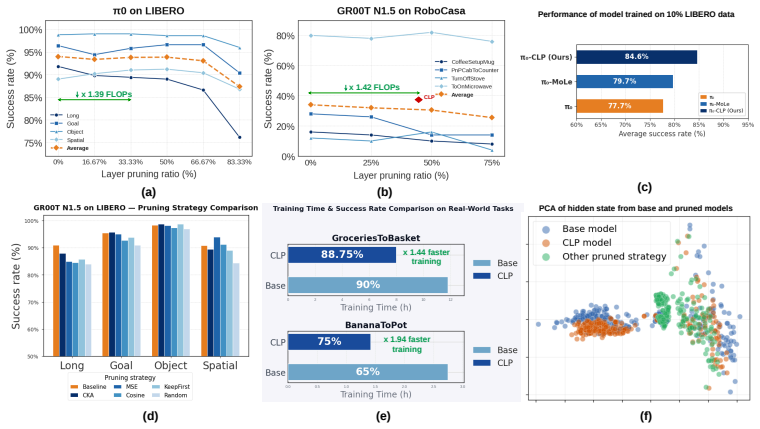
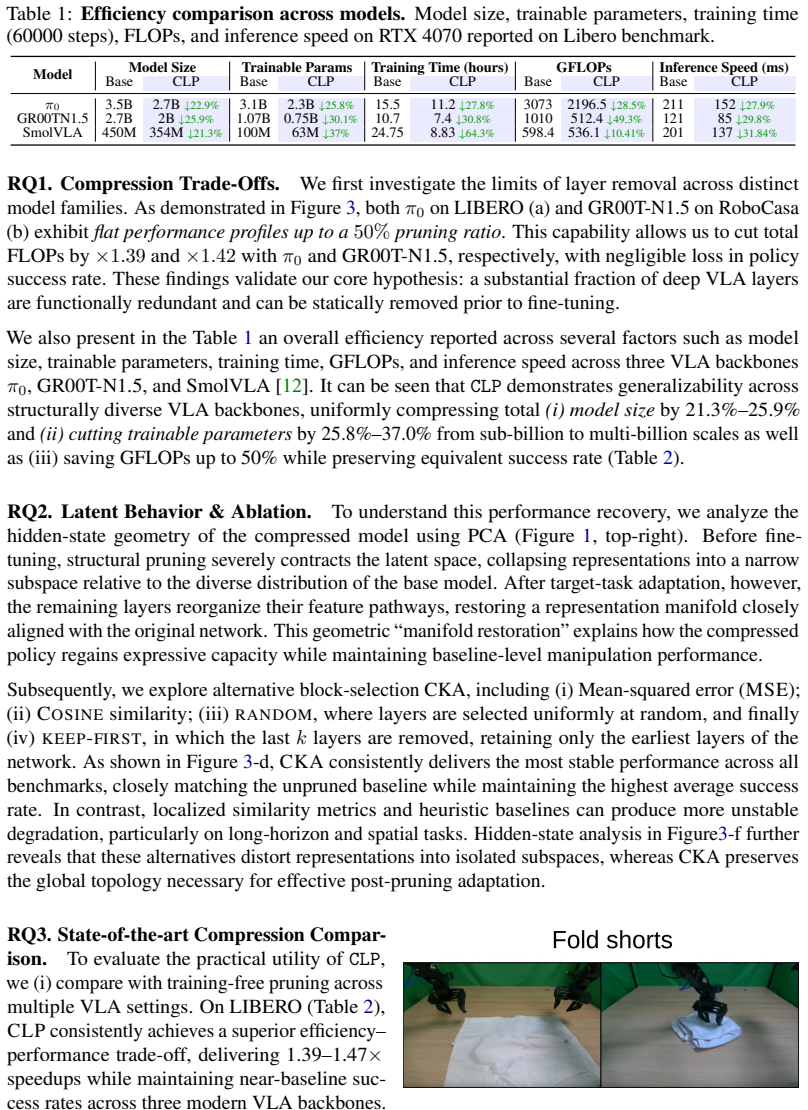
Despite training on massive and varied physical trajectories, current VLA policies exhibit severe layer-wise representational redundancy. Measuring pairwise layer similarity with Centered Kernel Alignment on one forward pass reveals pairs of nearly duplicate layers; permanently excising one member of each pair compresses model depth by up to 50% in both the VLM backbone and the policy head. The resulting architecture, when fine-tuned, matches or exceeds the task performance of the original full-depth model while delivering 40-50% faster training and up to 30% faster real-time inference.
What carries the argument
Centered Kernel Alignment (CKA) applied to a single forward pass to detect and remove twin redundant layers across the VLM backbone and continuous control policy head.
If this is right
- Model depth can be halved permanently before any fine-tuning begins.
- Downstream training time drops 40-50% while task success stays the same or rises.
- Real-time inference runs up to 30% faster on the same hardware.
- The same compression works on both the vision-language backbone and the action head.
- The benefit holds across simulation benchmarks and real robots with four different embodiments.
Where Pith is reading between the lines
- Pre-training on video-robot data may routinely produce over-parameterized layers whose features are not task-specific.
- A similar one-pass redundancy scan could be tested on other large control or multimodal models outside robotics.
- If the redundancy pattern is stable, the method could let researchers train and deploy capable VLAs on hardware with half the memory or compute budget.
Load-bearing premise
The layer pairs found to be redundant by one forward pass of CKA stay redundant for any later task, robot body, or fine-tuning run.
What would settle it
Fine-tune the 50%-compressed model on a previously unseen task or embodiment and measure whether success rate falls more than a few percent below the full-depth baseline.
Figures


read the original abstract
Vision-Language-Action (VLA) models pre-trained on massive video-robot datasets have revolutionized robotic manipulation, yet their multi-billion parameter architectures impose prohibitive computational burdens during downstream fine-tuning and real-time inference. In this work, we reveal a highly non-trivial architectural characteristic of these continuous control foundation policies (e.g., pi_0, GR00T-N1.5): despite being trained on diverse physical trajectories, they exhibit severe layer-wise representational redundancy. To exploit this, we introduce a structural compression pipeline that is entirely training-free, bypassing the need of existing methods to load full-scale models to learn optimized token reductions or dynamic layer selectors. Instead, using only a single forward pass via Centered Kernel Alignment to identify redundant layer features, we remove twin layers to permanently compress the model depth by up to 50% across both the VLM backbone and the continuous control policy head. Downstream fine-tuning of this streamlined architecture yields a dual acceleration benefit: a 40-50% reduction in training time and up to 30% faster real-time inference, while matching or exceeding full-scale base model performance. We comprehensively validate our method across three simulation benchmarks (LIBERO, RoboCasa, SimplerEnv) and 10 diverse real-world manipulation tasks across 4 unique robotic embodiments. These results prove that advanced VLAs require significantly fewer layers than previously assumed, offering a highly compute-efficient paradigm for scalable robot learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pre-trained VLA models (e.g., pi_0, GR00T-N1.5) exhibit severe layer-wise representational redundancy despite training on diverse trajectories; a single forward pass with Centered Kernel Alignment (CKA) identifies 'twin' layers that can be removed in a training-free manner to permanently compress both the VLM backbone and policy head by up to 50%, after which fine-tuning yields 40-50% faster training, up to 30% faster inference, and performance matching or exceeding the original model. Validation is asserted across LIBERO, RoboCasa, SimplerEnv and 10 real-world tasks on 4 embodiments.
Significance. If the central claim holds, the work would demonstrate that advanced VLAs can be structurally compressed without task-specific retraining for the compression step itself, offering substantial practical gains in fine-tuning cost and deployment speed for robotic manipulation. The training-free identification step is a clear methodological strength relative to learned token or layer selectors.
major comments (3)
- [§4] §4 (Experimental validation): the abstract asserts 'comprehensive validation' and 'matching or exceeding' performance across three simulation benchmarks and 10 real-world tasks, yet no details are supplied on number of random seeds, error bars, statistical tests, or how embodiment/task selection was performed; without these the claim that compression preserves capacity cannot be assessed as load-bearing evidence.
- [Method] Method section (CKA identification procedure): the load-bearing assumption that layer pairs identified as redundant by CKA on a single forward pass remain redundant under the distribution shift of downstream fine-tuning trajectories is stated but not tested via cross-distribution CKA comparisons or ablation on held-out embodiments; if similarity matrices change with new physical trajectories the removed layers could reduce capacity, undermining the 'permanent' and 'general' compression pipeline.
- [Abstract and §3] Abstract and §3 (single forward pass): the input data distribution used for the CKA forward pass is not specified (e.g., whether it is a subset of pre-training data, a generic robot trajectory set, or task-specific); this choice directly determines which layers are declared 'twins' and is therefore central to the generalizability claim across the reported 4 embodiments.
minor comments (2)
- Notation for the policy head compression is introduced without an explicit equation or diagram showing which layers are paired and removed; a small schematic would clarify the 50% depth reduction claim.
- The title uses 'Fewer Layers Than You Think' which is informal; a more precise phrasing would better match the technical contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [§4] §4 (Experimental validation): the abstract asserts 'comprehensive validation' and 'matching or exceeding' performance across three simulation benchmarks and 10 real-world tasks, yet no details are supplied on number of random seeds, error bars, statistical tests, or how embodiment/task selection was performed; without these the claim that compression preserves capacity cannot be assessed as load-bearing evidence.
Authors: We agree that these experimental details are necessary for rigorous assessment. In the revised manuscript we will report all results as means over 3 random seeds with standard deviations, include paired statistical tests (e.g., Wilcoxon) for performance comparisons, and describe the task/embodiment selection criteria used to ensure coverage of diverse manipulation scenarios across the four platforms. These additions will make the evidence for preserved capacity explicit. revision: yes
-
Referee: [Method] Method section (CKA identification procedure): the load-bearing assumption that layer pairs identified as redundant by CKA on a single forward pass remain redundant under the distribution shift of downstream fine-tuning trajectories is stated but not tested via cross-distribution CKA comparisons or ablation on held-out embodiments; if similarity matrices change with new physical trajectories the removed layers could reduce capacity, undermining the 'permanent' and 'general' compression pipeline.
Authors: This is a fair methodological concern. While the successful transfer of the compressed models to four distinct embodiments provides supporting evidence that the identified redundancies are not brittle, we did not perform explicit cross-distribution CKA ablations. In revision we will add a targeted analysis comparing CKA similarity matrices computed on pre-training-style trajectories versus held-out fine-tuning trajectories from each embodiment to directly test stability of the twin-layer identifications. revision: partial
-
Referee: [Abstract and §3] Abstract and §3 (single forward pass): the input data distribution used for the CKA forward pass is not specified (e.g., whether it is a subset of pre-training data, a generic robot trajectory set, or task-specific); this choice directly determines which layers are declared 'twins' and is therefore central to the generalizability claim across the reported 4 embodiments.
Authors: We will revise §3 and the method section to explicitly state that the single forward pass uses a generic collection of robot trajectories sampled from a broad distribution matching the pre-training corpus but deliberately independent of the downstream task data. This choice was made precisely to support the generalizability claim; the clarification will remove ambiguity. revision: yes
Circularity Check
No circularity; method uses external CKA metric on forward passes
full rationale
The paper identifies redundant layers via Centered Kernel Alignment (CKA) computed on a single forward pass, an independent external similarity measure unrelated to any fitted parameters or self-derived quantities within the work. Layer removal is a direct structural edit based on this measurement, followed by standard downstream fine-tuning on the compressed model. No equations or steps reduce by construction to the inputs (no self-definitional mappings, no fitted inputs renamed as predictions, no load-bearing self-citations, and no uniqueness theorems imported from prior author work). The derivation chain is empirically grounded in an off-the-shelf metric and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[2]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.Conference on Neural Information Processing Systems (NeurIPS), 2024
2024
-
[7]
Driess, J
D. Driess, J. Springenberg, B. Ichter, L. Yu, A. Li-Bell, K. Pertsch, A. Ren, H. Walke, Q. Vuong, L. X. Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.Advances in Neural Information Processing Systems, 38:102867–102888, 2026
2026
-
[8]
Y . Yang, Y . Wang, Z. Wen, L. Zhongwei, C. Zou, Z. Zhang, C. Wen, and L. Zhang. Efficientvla: Training-free acceleration and compression for vision-language-action models.Advances in Neural Information Processing Systems, 38:40891–40914, 2026. 9
2026
-
[9]
H. Wang, J. Xu, Y . Xiang, J. Pan, Y . Zhou, Y .-L. Li, and G. Dai. Specprune-vla: Accelerat- ing vision-language-action models via action-aware self-speculative pruning.International Conference on Machine Learning, 2026
2026
-
[10]
J. Liu, M. Liu, Z. Wang, P. An, X. Li, K. Zhou, S. Yang, R. Zhang, Y . Guo, and S. Zhang. Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation. Advances in Neural Information Processing Systems, 37:40085–40110, 2024
2024
-
[11]
Reuss, H
M. Reuss, H. Zhou, M. R¨uhle, ¨O. E. Ya˘gmurlu, F. Otto, and R. Lioutikov. Flower: Democratizing generalist robot policies with efficient vision-language-action flow policies.Conference on Robot Learning (CoRL), 2025
2025
-
[12]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
C.-Y . Hung, Q. Sun, P. Hong, A. Zadeh, C. Li, U. Tan, N. Majumder, S. Poria, et al. Nora: A small open-sourced generalist vision language action model for embodied tasks.arXiv preprint arXiv:2504.19854, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Y . Yue, Y . Wang, B. Kang, Y . Han, S. Wang, S. Song, J. Feng, and G. Huang. Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
2024
-
[15]
Zhang, M
R. Zhang, M. Dong, Y . Zhang, L. Heng, X. Chi, G. Dai, L. Du, D. Wang, Y . Du, and S. Zhang. Mole-vla: Dynamic layer-skipping vision language action model via mixture-of-layers for efficient robot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18764–18772, 2026
2026
-
[16]
S. Xu, Y . Wang, C. Xia, D. Zhu, T. Huang, and C. Xu. Vla-cache: Efficient vision-language- action manipulation via adaptive token caching.Advances in Neural Information Processing Systems, 38:164448–164473, 2026
2026
-
[17]
D. M. Nguyen, N. T. Diep, B. G. Nguyen, T.-B. Ho, D. Le, T. Nguyen, T.-L. Ha, T. Nhiem, B. Thach, N. Tran, T. A. Tran, A. Habuda, P. L. Moeller, T. N. Le, D. Sonntag, M. Niepert, K. Doan, V . Duong, H. Ngo, M. Vu, D. M. Nguyen, A. Le, and V . Ngo. Foca: Future- oriented conditioning for data-efficient vision-language-action adaptation. InProceedings of th...
2026
-
[18]
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. Hamlet: Switch your vision- language-action model into a history-aware policy.International Conference on Learning Representations (ICLR), 2025
2025
-
[19]
Kornblith, M
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of neural network representations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019
2019
-
[20]
Cortes, M
C. Cortes, M. Mohri, and A. Rostamizadeh. Algorithms for learning kernels based on centered alignment. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 301–309, 2012
2012
-
[21]
Nguyen, M
T. Nguyen, M. Raghu, and S. Kornblith. Do wide and deep networks learn the same things? uncovering how neural network representations vary with width and depth. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[22]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023. 10
2023
-
[23]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[24]
X. Li, K. Gao, H. Zhou, A. Yu, Y . Zhu, H. Ku, S. Tao, J. Gu, S. Ha, X. Peng, and H. Su. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning (CoRL), 2024
2024
-
[25]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
K. P. Hawkins. Analytic inverse kinematics for the universal robots UR-5/UR-10 arms. Technical report, Georgia Institute of Technology, 2013
2013
-
[27]
Universal Robots A/S, Odense, Denmark, 2013
Universal Robots UR5/UR10 User Manual. Universal Robots A/S, Odense, Denmark, 2013. Available athttps://www.universal-robots.com
2013
-
[28]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
B. Xiao, H. Wu, W. Xu, X. Dai, H. Hu, Y . Lu, M. Zeng, C. Liu, and L. Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4818–4829, 2024
2024
-
[30]
Q. Team. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
S. Ge, Y . Zhang, L. Liu, M. Zhang, J. Han, and J. Gao. Model tells you what to discard: Adaptive kv cache compression for llms. InInternational Conference on Learning Representations, volume 2024, pages 22975–22988, 2024
2024
- [32]
-
[33]
X. Pei, Y . Chen, S. Xu, Y . Wang, Y . Shi, and C. Xu. Action-aware dynamic pruning for efficient vision-language-action manipulation.The Fourteenth International Conference on Learning Representations (ICLR), 2026
2026
- [34]
-
[35]
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Balakr- ishna, N. Batchelor, A. Bewley, J. Bingham, et al. Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer.arXiv preprint arXiv:2510.03342, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Huang, Y .-H
C.-P. Huang, Y .-H. Wu, M.-H. Chen, F. Wang, and F.-E. Yang. Thinkact: Vision-language-action reasoning via reinforced visual latent planning.Advances in Neural Information Processing Systems, 38:82782–82802, 2026
2026
-
[37]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge. Advances in Neural Information Processing Systems, 38:24195–24228, 2026
2026
-
[38]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
- [39]
-
[40]
X. Men, M. Xu, Q. Zhang, Q. Yuan, B. Wang, H. Lin, Y . Lu, X. Han, and W. Chen. Shortgpt: Layers in large language models are more redundant than you expect. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20192–20204, 2025
2025
- [41]
-
[42]
L. Chen, H. Zhao, T. Liu, S. Bai, J. Lin, C. Zhou, and B. Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In European Conference on Computer Vision, pages 19–35. Springer, 2024
2024
-
[43]
S. R. Alvar, G. Singh, M. Akbari, and Y . Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
2025
-
[44]
S. Wang, R. Yu, Z. Yuan, C. Yu, F. Gao, Y . Wang, and D. F. Wong. Spec-vla: speculative decoding for vision-language-action models with relaxed acceptance. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 26916–26928, 2025. 12 Supplement to ”Finetuning Vision-Language-Action Models Requires Fewer Layers Than ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.